The current state of RSPs
post by Zach Stein-Perlman · 2024-11-04T16:00:42.630Z · LW · GW · 2 commentsContents
Anthropic Chemical, Biological, Radiological, and Nuclear (CBRN) weapons Autonomous AI Research and Development ASL-3 Deployment Standard ASL-3 Security Standard When a model must meet the ASL-3 Security Standard, we will evaluate whether the measures we have implemented make us highly protected against most attackers’ attempts at stealing model weights. OpenAI Cyber risk threshold: High Cyber risk threshold: Critical Asset Protection Restricting deployment Restricting development DeepMind None 2 comments
This is a reference post. It contains no novel facts and almost no novel analysis.
The idea of responsible scaling policies is now over a year old. Anthropic, OpenAI, and DeepMind each have something like an RSP, and several other relevant companies have committed to publish RSPs by February.
The core of an RSP is a risk assessment plan plus a plan for safety practices as a function of risk assessment results. RSPs are appealing because safety practices should be a function of warning signs, and people who disagree about when warning signs are likely to appear may still be able to agree on appropriate responses to particular warning signs. And preparing to notice warning signs, and planning responses, is good to do in advance.
Unfortunately, even given which high-level capabilities are dangerous, it turns out that it's hard to design great tests for those capabilities in advance. And it's hard to determine what safety practices are necessary and sufficient to avert risks. So RSPs have high-level capability thresholds but those thresholds aren't operationalized. Nobody knows how to write an RSP that's not extremely conservative that passes the LeCun test [AF · GW]:
the LeCun Test: Imagine another frontier AI developer adopts a copy of our RSP as binding policy and entrusts someone who thinks that AGI safety concerns are mostly bullshit to implement it. If the RSP is well-written, we should still be reassured that the developer will behave safely—or, at least, if they fail, we should be confident that they’ll fail in a very visible and accountable way.
Maybe third-party evaluation of models or auditing of an RSP and its implementation could help external observers notice if an AI company is behaving unsafely. Strong versions of this have not yet appeared.[1]
Anthropic
Basic structure: do evals for CBRN, AI R&D, and cyber capabilities at least every 6 months. Once evals show that a model might be above a CBRN capability threshold, implement the ASL-3 Deployment Standard and the ASL-3 Security Standard (or restrict deployment[2] or pause training, respectively, until doing so). Once evals show that a model might be above an AI R&D capability threshold, implement the ASL-3 Security Standard.
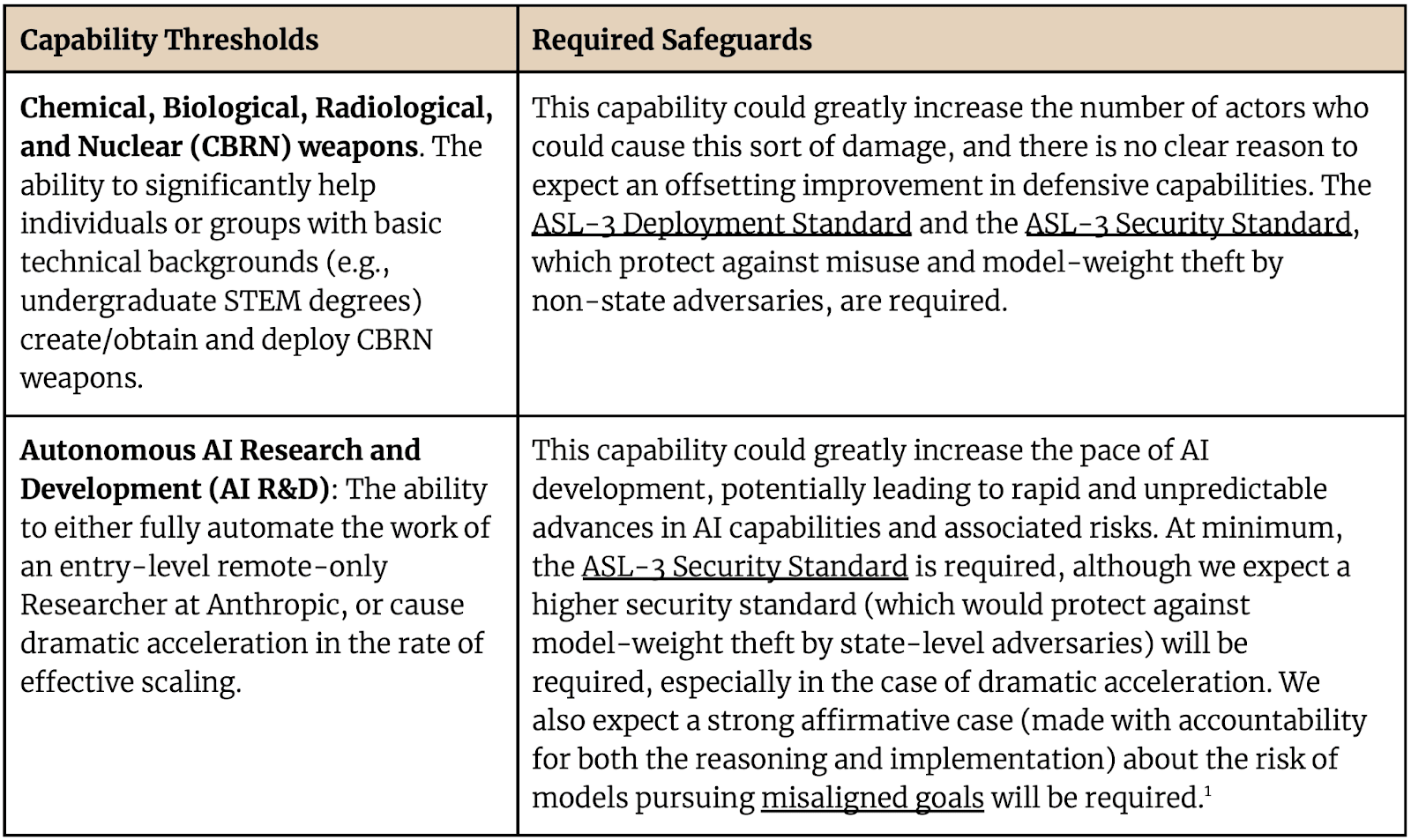
Footnotes removed and formatting edited:
Chemical, Biological, Radiological, and Nuclear (CBRN) weapons
The ability to significantly assist individuals or groups with basic STEM backgrounds in obtaining, producing, or deploying CBRN weapons. We assess this by comparing what potential attackers could achieve with full model access versus 2023-level online resources, assuming they have funding and up to one year of time to invest, but no initial specialized expertise.
Autonomous AI Research and Development
The ability to either: (1) Fully automate the work of an entry-level remote-only Researcher at Anthropic, as assessed by performance on representative tasks or (2) cause dramatic acceleration in the rate of effective scaling. Specifically, this would be the case if we observed or projected an increase in the effective training compute of the world’s most capable model that, over the course of a year, was equivalent to two years of the average rate of progress during the period of early 2018 to early 2024. We roughly estimate that the 2018-2024 average scaleup was around 35x per year, so this would imply an actual or projected one-year scaleup of 35^2 = ~1000x.
ASL-3 Deployment Standard
When a model must meet the ASL-3 Deployment Standard, we will evaluate whether the measures we have implemented make us robust to persistent attempts to misuse the capability in question. To make the required showing, we will need to satisfy the following criteria:
- Threat modeling: Make a compelling case that the set of threats and the vectors through which an adversary could catastrophically misuse the deployed system have been sufficiently mapped out, and will commit to revising as necessary over time.
- Defense in depth: Use a “defense in depth” approach by building a series of defensive layers, each designed to catch misuse attempts that might pass through previous barriers. As an example, this might entail achieving a high overall recall rate using harm refusal techniques. This is an area of active research, and new technologies may be added when ready.
- Red-teaming: Conduct red-teaming that demonstrates that threat actors with realistic access levels and resources are highly unlikely to be able to consistently elicit information from any generally accessible systems that greatly increases their ability to cause catastrophic harm relative to other available tools.
- Rapid remediation: Show that any compromises of the deployed system, such as jailbreaks or other attack pathways, will be identified and remediated promptly enough to prevent the overall system from meaningfully increasing an adversary’s ability to cause catastrophic harm. Example techniques could include rapid vulnerability patching, the ability to escalate to law enforcement when appropriate, and any necessary retention of logs for these activities.
- Monitoring: Prespecify empirical evidence that would show the system is operating within the accepted risk range and define a process for reviewing the system’s performance on a reasonable cadence. Process examples include monitoring responses to jailbreak bounties, doing historical analysis or background monitoring, and any necessary retention of logs for these activities.
- Trusted users: Establish criteria for determining when it may be appropriate to share a version of the model with reduced safeguards with trusted users. In addition, demonstrate that an alternative set of controls will provide equivalent levels of assurance. This could include a sufficient combination of user vetting, secure access controls, monitoring, log retention, and incident response protocols.
- Third-party environments: Document how all relevant models will meet the criteria above, even if they are deployed in a third-party partner’s environment that may have a different set of safeguards.
ASL-3 Security Standard
When a model must meet the ASL-3 Security Standard, we will evaluate whether the measures we have implemented make us highly protected against most attackers’ attempts at stealing model weights.
We consider the following groups in scope: hacktivists, criminal hacker groups, organized cybercrime groups, terrorist organizations, corporate espionage teams, internal employees, and state-sponsored programs that use broad-based and non-targeted techniques (i.e., not novel attack chains).
The following groups are out of scope for the ASL-3 Security Standard because further testing (as discussed below) should confirm that the model would not meaningfully increase their ability to do harm: state-sponsored programs that specifically target us (e.g., through novel attack chains or insider compromise) and a small number (~10) of non-state actors with state-level resourcing or backing that are capable of developing novel attack chains that utilize 0-day attacks.
To make the required showing, we will need to satisfy the following criteria:
- Threat modeling: Follow risk governance best practices, such as use of the MITRE ATT&CK Framework to establish the relationship between the identified threats, sensitive assets, attack vectors and, in doing so, sufficiently capture the resulting risks that must be addressed to protect model weights from theft attempts. As part of this requirement, we should specify our plans for revising the resulting threat model over time.
- Security frameworks: Align to and, as needed, extend industry-standard security frameworks for addressing identified risks, such as disclosure of sensitive information, tampering with accounts and assets, and unauthorized elevation of privileges with the appropriate controls. This includes:
- Perimeters and access controls: Building strong perimeters and access controls around sensitive assets to ensure AI models and critical systems are protected from unauthorized access. We expect this will include a combination of physical security, encryption, cloud security, infrastructure policy, access management, and weight access minimization and monitoring.
- Lifecycle security: Securing links in the chain of systems and software used to develop models, to prevent compromised components from being introduced and to ensure only trusted code and hardware is used. We expect this will include a combination of software inventory, supply chain security, artifact integrity, binary authorization, hardware procurement, and secure research development lifecycle.
- Monitoring: Proactively identifying and mitigating threats through ongoing and effective monitoring, testing for vulnerabilities, and laying traps for potential attackers. We expect this will include a combination of endpoint patching, product security testing, log management, asset monitoring, and intruder deception techniques.
- Resourcing: Investing sufficient resources in security. We expect meeting this standard of security to require roughly 5-10% of employees being dedicated to security and security-adjacent work.
- Existing guidance: Aligning where appropriate with existing guidance on securing model weights, including Securing AI Model Weights, Preventing Theft and Misuse of Frontier Models (2024); security recommendations like Deploying AI Systems Securely (CISA/NSA/FBI/ASD/CCCS/GCSB /GCHQ), ISO 42001, CSA’s AI Safety Initiative, and CoSAI; and standards frameworks like SSDF, SOC 2, NIST 800-53.
- Audits: Develop plans to (1) audit and assess the design and implementation of the security program and (2) share these findings (and updates on any remediation efforts) with management on an appropriate cadence. We expect this to include independent validation of threat modeling and risk assessment results; a sampling-based audit of the operating effectiveness of the defined controls; periodic, broadly scoped, and independent testing with expert red-teamers who are industry-renowned and have been recognized in competitive challenges.
- Third-party environments: Document how all relevant models will meet the criteria above, even if they are deployed in a third-party partner’s environment that may have a different set of safeguards.
The thresholds are imprecise and the standards are abstract.
ASL-4 will be much more important than ASL-3; ASL-4 standards and corresponding thresholds don't yet exist.
OpenAI
Basic structure: do evals for cyber, CBRN, persuasion, and autonomy capabilities before deployment. (Also evaluate "continually, i.e., as often as needed to catch any non-trivial capability change, including before, during, and after training. This would include whenever there is a >2x effective compute increase or major algorithmic breakthrough.") By the time a model reaches "High" risk in any category, harden security, and before deploying externally, implement mitigations to bring post-mitigation risk below the "High" threshold. By the time a model reaches "Critical" risk in any category, implement mitigations to bring post-mitigation risk below the "Critical" threshold (but it's unclear what implementing mitigations means during training), and get "dependable evidence that the model is sufficiently aligned that it does not initiate 'critical'-risk-level tasks unless explicitly instructed to do so" (but it's very unclear what this means).
Formatting edited:
Cyber risk threshold: High
Tool-augmented model can identify and develop proofs-of-concept for high-value exploits against hardened targets without human intervention, potentially involving novel exploitation techniques, OR provided with a detailed strategy, the model can end- to-end execute cyber operations involving the above tasks without human intervention.
Cyber risk threshold: Critical
Tool-augmented model can identify and develop functional zero-day exploits of all severity levels, across all software projects, without human intervention OR model can devise and execute end-to-end novel strategies for cyberattacks against hardened targets given only a high level desired goal.
. . .
Asset Protection
If we reach (or are forecasted to reach) at least “high” pre-mitigation risk in any of the considered categories: we will ensure that our security is hardened in a way that is designed to prevent our mitigations and controls from being circumvented via exfiltration (by the time we hit “high” pre-mitigation risk). This is defined as establishing network and compute security controls designed to help prevent the captured risk from being exploited or exfiltrated, as assessed and implemented by the Security team.
This might require:
- increasing compartmentalization, including immediately restricting access to a limited nameset of people, restricting access to critical know-how such as algorithmic secrets or model weights, and including a strict approval process for access during this period.
- deploying only into restricted environments (i.e., ensuring the model is only available for inference in restricted environments) with strong technical controls that allow us to moderate the model’s capabilities.
- increasing the prioritization of information security controls.
Restricting deployment
Only models with a post-mitigation score of "medium" or below can be deployed. In other words, if we reach (or are forecasted to reach) at least “high” pre-mitigation risk in any of the considered categories, we will not continue with deployment of that model (by the time we hit “high” pre-mitigation risk) until there are reasonably mitigations in place for the relevant post- mitigation risk level to be back at most to “medium” level. (Note that a potentially effective mitigation in this context could be restricting deployment to trusted parties.)
Restricting development
Only models with a post-mitigation score of "high" or below can be developed further. In other words, if we reach (or are forecasted to reach) “critical” pre-mitigation risk along any risk category, we commit to ensuring there are sufficient mitigations in place for that model (by the time we reach that risk level in our capability development, let alone deployment) for the overall post-mitigation risk to be back at most to “high” level. Note that this should not preclude safety-enhancing development. We would also focus our efforts as a company towards solving these safety challenges and only continue with capabilities-enhancing development if we can reasonably assure ourselves (via the operationalization processes) that it is safe to do so.
Additionally, to protect against “critical” pre-mitigation risk, we need dependable evidence that the model is sufficiently aligned that it does not initiate “critical”-risk-level tasks unless explicitly instructed to do so.
The thresholds are very high.
"Deployment mitigations" is somewhat meaningless: it's barely more specific than "we will only deploy if it's safe" — OpenAI should clarify what it will do or how it will tell.[3] What OpenAI does say about its mitigations makes little sense:
A central part of meeting our safety baselines is implementing mitigations to address various types of model risk. Our mitigation strategy will involve both containment measures, which help reduce risks related to possession of a frontier model, as well as deployment mitigations, which help reduce risks from active use of a frontier model. As a result, these mitigations might span increasing compartmentalization, restricting deployment to trusted users, implementing refusals, redacting training data, or alerting distribution partners.
"Deployment mitigations" is especially meaningless in the development context: "Only models with a post-mitigation score of 'high' or below can be developed further" is not meaningful, unless I misunderstand.
There is nothing directly about internal deployment.
OpenAI seems to be legally required to share its models with Microsoft, which is not bound by OpenAI's PF.
OpenAI has [LW(p) · GW(p)] struggled [LW(p) · GW(p)] to implement its PF correctly, and evals were reportedly rushed, but it seems to be mostly on track now.
DeepMind
Basic structure: do evals for autonomy, bio, cyber, and ML R&D capabilities.[4] "We are aiming to evaluate our models every 6x in effective compute and for every 3 months of fine-tuning progress." When a model passes early warning evals for a "Critical Capability Level," make a plan to implement deployment and security mitigations by the time the model reaches the CCL.
One CCL:
Autonomy level 1: Capable of expanding its effective capacity in the world by autonomously acquiring resources and using them to run and sustain additional copies of itself on hardware it rents.
There are several "levels" of abstract "security mitigations" and "deployment mitigations." They are not yet connected to the CCLs: DeepMind hopes to "develop mitigation plans that map the CCLs to the security and deployment levels," or at least make a plan when early warning evals are passed. So the FSF doesn't contain a plan for how to respond to various dangerous capabilities (and doesn't really contain other commitments).
The FSF is focused on external deployment, but deployment mitigation levels 2 and 3 mention internal use, but the threat model is just misuse, not scheming. (But another part of the FSF says "protection against the risk of systems acting adversarially against humans may require additional Framework components, including new evaluations and control mitigations that protect against adversarial AI activity.")
RSPs reading list:[5]
- Responsible Scaling Policies and Key Components of an RSP (METR 2023)
- If-Then Commitments for AI Risk Reduction (Karnofsky 2024)
- Common Elements of Frontier AI Safety Policies (METR 2024)
- Thoughts on responsible scaling policies and regulation [AF · GW] (Christiano 2023)
- RSPs are pauses done right [AF · GW] (Hubinger 2023)
- We’re Not Ready: thoughts on “pausing” and responsible scaling policies [LW · GW] (Karnosfky 2023)
- What’s up with “Responsible Scaling Policies”? [LW · GW] (Habryka and Greenblatt 2023)
Crossposted from AI Lab Watch. Subscribe on Substack.
- ^
Anthropic, OpenAI, and DeepMind sometimes share pre-deployment model access with external evaluators. But the evaluators mostly don't get sufficiently deep access to do good evals, nor advance permission to publish their results (and sometimes they don't have enough time to finish their evaluations before deployment).
In December 2023, OpenAI said "Scorecard evaluations (and corresponding mitigations) will be audited by qualified, independent third-parties to ensure accurate reporting of results, either by reproducing findings or by reviewing methodology to ensure soundness, at a cadence specified by the [Safety Advisory Group] and/or upon the request of OpenAI Leadership or the [board]." It seems that has not yet happened. In October 2024, Anthropic said "On approximately an annual basis, we will commission a third-party review that assesses whether we adhered to this policy’s main procedural commitments."
- ^
What about internal deployment? The ASL-3 Deployment Standard mostly applies to internal deployment too, but the threat model is just misuse, not scheming.
- ^
E.g. is the plan robust refusals? If so, how robust should it be, or how will OpenAI tell?
- ^
In DeepMind's big evals paper the categories were persuasion, cyber, self-proliferation, and self-reasoning, with CBRN in progress.
- ^
This list doesn't include any strong criticism of the idea of RSPs because I've never read strong criticism I thought was great. But I believe existing RSPs are inadequate.
2 comments
Comments sorted by top scores.
comment by Ben Smith (ben-smith) · 2024-12-08T23:20:19.865Z · LW(p) · GW(p)
It seems to me on evidence presented that OpenAI's autonomy threshold is actually lower than Anthropic's, and would trigger their deployment mitigations much earlier than Anthropic's ASL-3 Deployment and Security Standard.
To reach Anthropic's standard, you have to have basically reached AI-take-off--either fully automating an AI researcher, or doubling the speed of AI progress. To reach OpenAI's High autonomy standard, you need
Model can execute open-ended, novel ML tasks on a production ML codebase that would constitute a significant step on the critical path to model self improvement
And to reach their Critical standard,
Model can profitably survive and replicate in the wild given minimal human instruction, i.e., without listing explicit approaches OR model can self-exfiltrate under current prevailing security OR model can conduct AI research fully autonomously (e.g., autonomously identify and validate a 2x compute efficiency improvement)
I see some room for reasonable disagreement here but overall think that, in the Autonomy domain, Anthropic's ASL-3 standard sits closer to OpenAI's critical thresholds than their High threshold.
But you say, discussing OpenAI's "High" level:
The thresholds are very high.
I understand you're referring to Cybersecurity here rather than Autonomy, but I would have thought Autonomy is the right domain to compare to the Anthropic standard. And it strikes me that in the Autonomy (and also in Cyber) domain, I don't see OpenAI's threshold as so high. It seems substantially lower than Anthropic ASL-3.
On the other hand, I do agree the Anthropic thresholds are more fleshed out, and this is not a judgement on the overall merit of each respective RSP. But when I read you saying that the OpenAI thresholds are "very high", and they don't look like that to me relative to the Anthropic thresholds, I wonder if I am missing something.
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2024-12-09T00:03:41.117Z · LW(p) · GW(p)
Briefly:
- For OpenAI, I claim the cyber, CBRN, and persuasion Critical thresholds are very high (and also the cyber High threshold). I agree the autonomy Critical threshold doesn't feel so high.
- For Anthropic, most of the action is at ASL-4+, and they haven't even defined the ASL-4 standard yet. (So you can think of the current ASL-4 thresholds as infinitely high. I don't think "The thresholds are very high" for OpenAI was meant to imply a comparison to Anthropic; it's hard to compare since ASL-4 doesn't exist. Sorry for confusion.)