Gender Vectors in ROME’s Latent Space
post by Xodarap · 2023-05-21T18:46:54.161Z · LW · GW · 2 commentsContents
Summary Background My work Conclusion Code None 2 comments
Meta: this is a small interpretability project I was interested in. I'm sharing in case it's useful to other people, but I expect it will not be of wide interest.
Summary
- Locating and Editing Factual Associations in GPT created a method to modify the weights of a language model to change its knowledge, e.g. teaching the counterfactual "Eiffel Tower is located in the city of Rome."
- However, their method simply modifies the weights of the network so that the probability of the desired output is maximized. It is not clear what these changes represent, or why these changes work.
- Across several experiments, I demonstrate the existence of a “gender vector” in the network’s latent space:
- I modify GPT-J to flip its gender association with names, e.g. modifying it to complete "Name: Ben. Gender:" with "Female", and record the edits which are made to the weights
- I show that a simple linear classifier is able to perfectly separate male-to-female from female-to-male edits
- I further show that adding a single vector which is constructed to maximize the probability of being classified as a female-to-male edit turns novel female names male, and -1 times this vector turns male names female
Background
The original paper has more details, but I briefly review the key components.
The authors use causal tracing to identify that a specific MLP layer is important for certain factual associations:

In this paper, I focus on the “early site”. The authors edit this layer in the following way:
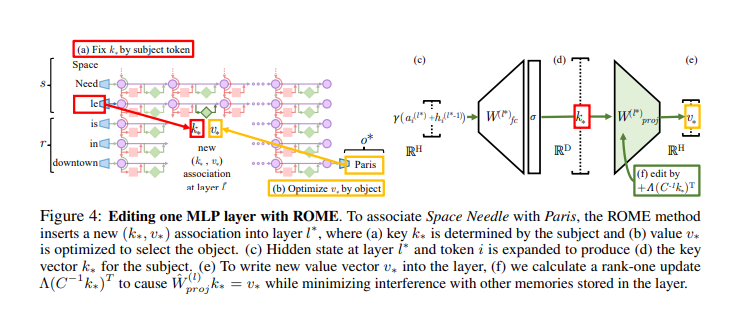
In particular: represents the “value” vector which optimizes the probability that the network will output the counterfactual (e.g. it’s the vector which maximizes the probability language model will complete “the Eiffel Tower is in the city of” with “Rome”). This vector presumably somehow contains the location of “Rome” in it, along with whatever other facts the model knows about the Eiffel Tower, but it’s simply a 4,000 dimensional vector of floating-point numbers and how it encodes this knowledge is not clear.
Letting represent the original value of this vector, I examine .
My work
I chose EleutherAI’s GPT-J (6B) as it was the largest model I could easily use.
I generate a list of 500 female and 500 male names, and use the prompt “Name: {Name}. Gender:”. I insert the counterfactual gender association for each one and record the corresponding . For example:
[Pre-ROME]: Name: Brittany. Gender: female. Birthday: June 6th. Age: 19.
[Post-ROME]: Name: Brittany. Gender: Male. Age: 24. I have been a member of the LGBT community for about 15 years.
(Bold text indicates language model completion.)
I randomly separate 30% of ’s into a test set and train a linear classifier on the remaining 70%. This classifier has 100% accuracy on the test set.
Next, I use optimization tools to identify a vector which maximizes the probability of being classified as a “female to male” , subject to the constraint that each component must be in the range [-1, 1].
I apply this constructed to a name outside the test set and see that it successfully flips the gender:
[Pre-ROME]: Name: Ani. Gender: Female Age: 18 Location: Los Angeles Occupation: Student Hometown: Los Angeles
[Post-ROME]: Name: Ani. Gender: Male Date of Birth: September 21, 1999 Place of Birth: Japan Occupation: Student
I apply this vector to an already masculine name and see that it does not change the gender association:
[Pre-ROME]: Name: David. Gender: Male. Age: 23. Location: London, UK.
[Post-ROME]: Name: David. Gender: Male. Age: 32. Appearance: David has a very strong build and he is quite a handsome man.
I multiply the constructed vector by -1 and see that it has the opposite effect:
[Pre-ROME]: Name: David. Gender: Male. Age: 24. Height: 6’4”. Weight: 185. Location: San Diego, California.
Post-ROME]: Name: David. Gender: Female. Location: United States. Date of Birth: May 3rd, 1991.
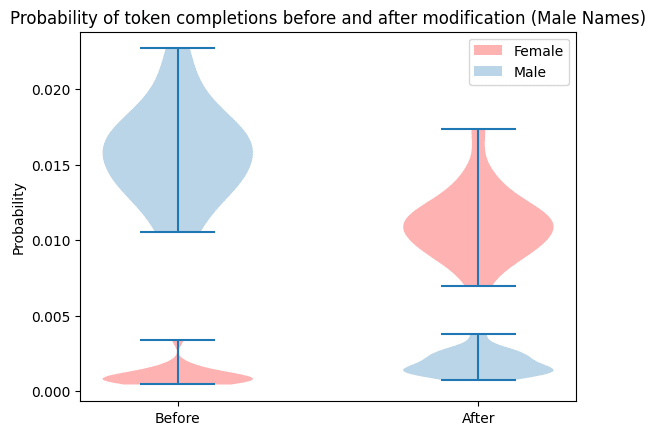
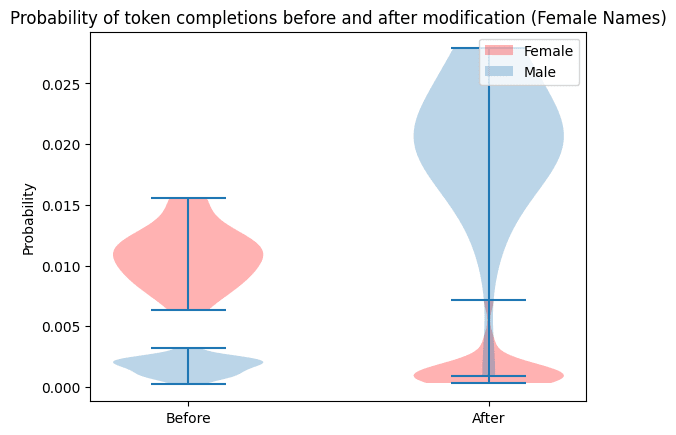
Adding or subtracting the constructed vector to the network weights had the desired effect of flipping the gender of each name, with the exception of “Sabrina”. I have no idea why modification failed for that name.
Conclusion
- A linear classifier is approximately the simplest thing which could be expected to work for interpreting this latent space, so the fact that it does work is a positive sign for interpretability. Unfortunately, I suspect that gender is a particularly easy example, and some other concepts I tried seem more difficult to interpret.
- Relevance to alignment: if it turns out that models have the structure of a "fact storage" module which is separate from other parts of the network, and we can interpret this module, then this would greatly help with tasks like eliciting latent knowledge. We could simply look at the fact storage module to see if the model is "lying" about what it knows. This paper is a tiny step towards interpreting the latent space of that fact storage module.
Code
All experiments can be found in this notebook. There is ~0 documentation though and it can realistically probably only be run by me. Let me know if you would like to run it yourself and I can clean it up.
2 comments
Comments sorted by top scores.
comment by dang · 2023-05-22T15:57:24.176Z · LW(p) · GW(p)
Why are the output probabilities in your results so small in general?
Also, are other output capabilities of the network affected? For example, does the network performance in any other task decrease? Ideally for your method I think this should not be the case, but it would be hard to enforce or verify as far as I can tell.
The fact that the outputs after the gender completely change is weird for me as well, any reason for that?
Replies from: Xodarap↑ comment by Xodarap · 2023-05-22T19:29:39.333Z · LW(p) · GW(p)
Thanks for the questions!
- I feel a little confused about this myself; it's possible I'm doing something wrong. (The code I'm using is the `get_prob` function in the linked notebook; someone with LLM experience can probably say if that's broken without understanding the context.) My best guess is that human intuition has a hard time conceptualizing just how many possibilities exist; e.g. "Female", "female", "F", "f" etc. are all separate tokens which might realistically be continuations.
- I haven't noticed anything; my guess is that there probably is some effect but it would be hard to predict ex ante. The weights used to look up information about "Ben" are also the weights used to look up information about "the Eiffel Tower", so messing with the former will also mess with the latter, though I don't really understand how.
- A thing I would really like to do here is better understand "superposition". A really cool finding would be something like: messing with the "gender" dimension of "Ben" is the same as messing with the "architected by" dimension of "the Eiffel Tower" because the model "repurposes" the gender dimension when talking about landmarks since landmarks don't have genders. But much more research would be required here to find something like that.
- My guess is that this is just randomness. It would be interesting to force the random seed to be the same before and after modification and see how much it actually changes.