Rugby & Regression Towards the Mean
post by Bucky · 2019-10-30T16:36:00.287Z · LW · GW · 1 commentsContents
Introduction Method Results First half vs second half Improved performance when losing at half time Overall performance Further exploration Footnote None 1 comment
With the rugby world cup final approaching this Saturday I figured I'd publish this which I wrote towards the end of last year but never submitted.
Introduction
A couple of weeks ago England played New Zealand in Rugby Union. For those who don’t follow the sport New Zealand (the All Blacks) are comfortably the best team in the world. They have been top of the world rankings since 2009. They win 92% of their matches. With a population of 4.8m, it’s fair to say that New Zealand’s national rugby affiliation must be off the charts.
At half time England were 15-10 up. An interesting statistic was rolled out. Since their World Cup win in 2011 they have only lost 4 out of 20 of the matches in which they were behind at half time. At the end of the match the All Blacks had turned it around again, winning 16-15, making it 4/21 losses.
This sounds very impressive but I wondered how much of this effect could be put down to regression towards the mean. After all, a team that wins 92% of their matches might well be good enough to win 81% of matches when they are losing at half time without postulating an extra performance boost in such circumstances.
I thought it would be fun to investigate.
Method
I gathered all of their results and corresponding half time scores since the 2011 World Cup. I only included data from teams who could realistically win a half against the All Blacks in order not to bias the results with high scores against weaker teams. I included Argentina, Australia, England, France, Ireland, Scotland, South Africa and Wales. This gave 85 results.
If anything, this will be biased towards having more wins when losing at half time. Losing at half time would imply that the opposition is more likely to be towards the top end of performance. However the predicted second half performance is based on all matches involving the relevant teams. So the calculation isn’t perfect but I couldn’t think of a better way to do it without reducing my dataset which would reduce experimental power.
The dataset isn’t big enough to allow for lowering my p-value threshold much by multiple hypothesis testing. I have two formal p-values:
Do New Zealand generally perform better in the second half than the first?
Do New Zealand perform better than normal in the second half when they are losing at half time?
I’m looking for p<0.025 for these 2. I calculate other p-values they are labelled as exploratory.
Results
First half vs second half
Analysing first half vs second half in all games, the mean and standard error of the All Blacks’ points difference over the opposition were:
First half:
Second half:
This difference in relative performance is significant (p=0.012) – the All Blacks perform better in the second half than the first half. This matches the commonly held impression that the All Blacks’ fitness is better than most teams so they can outperform them in the second half. This is important for future calculations.
With those first half numbers and a normal distribution, we would expect the All Blacks to lose 28% of their first halves – i.e. 23.6/85. The fact that they have only lost 21 is slightly better than this but not significantly (p=0.082, exploratory).
Improved performance when losing at half time
Combining the actual data for the amount that they were down at half time in those 21 matches with a normal distribution for their average performance in the 2nd half would predict 7.4/21 losses. Their actual performance (4 losses) is better than this but not significantly (p=0.068).
Certainly regression towards the mean explains a big fraction of the extra comebacks.
Naively it seems like you should make a comeback in fewer than half the matches that you are losing at half time. Even if we optimistically say 10/21 comebacks are expected then we can explain away 3.6 additional comebacks by appealing to RttM and there are only 3.4 comebacks left to be explained by improved performance.
However those 3.4 extra comebacks are still quite impressive - the All Blacks lost 46% fewer games when behind at half time than you would expect even accounting for RttM - but the sample size is too small for it to confidently imply an actual improved performance.
Overall performance
If I combine the normal distributions from the two halves I get a predicted win rate of 83% - not as good as the 92% achieved. This is significant (p=0.016) but I'm not counting it as it was exploratory.
Further exploration
So the All Blacks’ performance in second halves where they were losing at half time is better than their average but there is insufficient data to conclude that this is not just coincidence.
I put together a graph showing the points difference between the All Blacks and their opponents to investigate.
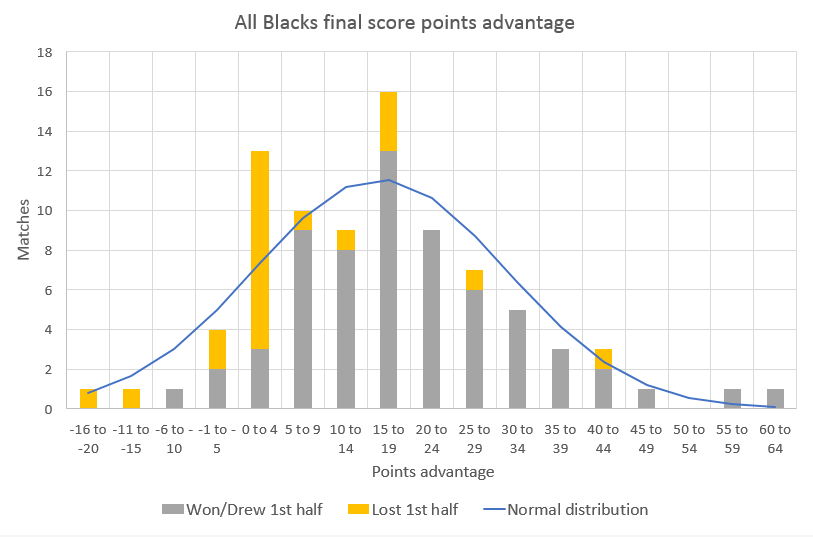
What stands out is the large spike in games which the All Blacks finished with a points advantage of 0-4 after having lost the first half. Of the 21 lost first halves, the All Blacks drew/won the match by a small amount 10 times.
These extra matches won more than explain the increase in comebacks above the expected level. They also explain nearly all of the difference between overall expected win percentage based on normal distributions and actual win percentage.
It appears that the All Blacks have won a lot of games by a tight margin over the last 8 years. Is this a coincidence? If not, do they win tight matches because they are great or are they great because they win tight matches?
Footnote
Looking back at this now, I wasn't harsh enough on the 2nd question. This wasn't a randomly selected question, it was a statistic specifically chosen by the commentator because it sounds impressive.
If the null hypothesis is true, p-values should be uniformly distributed between 0 and 1. Assuming there were 10 such statistics which the commentator could have used, it wouldn't be surprising that the most juicy-looking one had p<0.10 even if none of the purported effects were real. Therefore p=0.068 is really thoroughly unimpressive and I would conclude more strongly against the second question being confirmed by the data.
None of this applies to the first question (better in second half than first half in general) as this wasn't a cherry-picked question - I only asked it because it was important for the second question. It also has a reasonable causal mechanism (relative fitness levels) so I'd be inclined to believe it.
1 comments
Comments sorted by top scores.