Introduction to Choice set Misspecification in Reward Inference
post by Rahul Chand (rahul-chand) · 2024-10-29T22:57:34.310Z · LW · GW · 0 commentsContents
Inverse Reinforcement Learning Choice set misspecification Experiments to study misspecification categories Understanding Results B2 vs B3. Bad vs Worse Connection to Alignment None No comments
In classical RL, we have an agent with a set of States (S), a set of action (A), and given some reward function (R), the aim is to find out the optimal policy (pi) which maximizes the following. This is the cummulative rewards we get by sampling actions using our policy (here we assume discount factor is 1)
The problem with this approach is that rewards do not always map to the correct set of actions or policies we want. For example, assume a game of football where I have specialized agents playing together, the reward for the defender is based on if the team concedes a goal or not, the agent could maximize this reward function by hoofing the ball out of play every time and thus ending up at a degenerate solution where it doesn't learn to play the sport. There are many such examples from existing literatures
- Reward Hacking[1]: Assume you have a cleaning robot that gets a reward every time it cleans something, the robot figures out it can keep maximizing rewards by making a mess itself by pushing down objects and then cleaning them.[2]
- Degenerate solutions: If I have a robot that needs to survive in a dangerous environemnt and gets a negative reward whenever it takes damage, it can figure out a way to keep its score at 0 is to just shut down at the start.
- There are other examples like "Wireheading Problem" and the "Boat Racing problem"
Inverse Reinforcement Learning
To solve these issues rather than learning from some specified reward we can learn from demonstrations of desired behaviour and then figure out an appropriate reward function using them (this is knowns as Inverse-RL[3]). Therefore, in our above example about football, rather than having "don't concede goal = +10" as reward, we would have videos of a human playing as a defender and then we find out which reward function explains the demonstrations the best. The final reward using IRL might look like don't concede goal = +2, foul = -1, pass to midfielder = +0.5, pass back to keeper = -0.1 .... This reward function is more nuanced and captures our task better.
Since IRL depend on human demonstrations they suffer from the issue of human bias (humans are biased over some actions even if they are not optimal), human limitation (for a number of task human's usually stick to a small set of ways to do it without much deviation), and ambiguity (seeing a human perform something it might not be clear why it performed it). One way to capture misspecification (especially the final axis of ambiguity) between human and robots is as a misalignment between the real human and the robot’s assumptions about the human. Formally, you have a set C_H which is the set of choices the human's could have considered during demonstration and C_R which is the robot's assumption about what C_H is. Since its not possible to know C_H or sometimes even match C_R with C_H[4] we end up with choice set misspecification.

Choice set misspecification
We study choice set misspecification in the framework of RRiC (reward-rational implicit choice) which is a framework where we figure out the reward we are trying to maximize based on demonstrations and the assumption that the agent we are observing (often a human) is acting in a rational manner[5]. Formally, we have
C = choice set, ξ = trajectory, Ξ = all possible trajectories, ψ = grounding function
The grounding function maps us from a choice to a distribution over the trajectories
ψ : C → (Ξ → [0, 1])
For example, if we are cleaning the house and our choice set is to only stick to dry cleaning (maybe because the human doesn't want to get water on his clothes) then this choice leads to a distribution over what trajectories are possible (e.g. the value for the trajectory that leads to the sink might becomes 0 because we are only doing dry cleaning). We also assume that our choices have some rational
In normal boltzman learning we have a human who given a rationality parameter and a utility function of each action decides a choice using the above function. In the above function our utility is the reward we get from our trajectory E[ξ∼ψ(c)[rθ(ξ)]. In our case, we already have observations c and we want to update our posterior about using them, so with bayesian inference we get,
To study the affect of choice set misspefification, we first classify the misspeification into categories. If c* is the optimal action, we make some assumptions, first, we don't consider cases where . This is because if our robot sees something that its just not capable of (a human jump on a table to clean the top racks), the robot knows its not possible for it do this, so it reverts to a baseline safe policy.
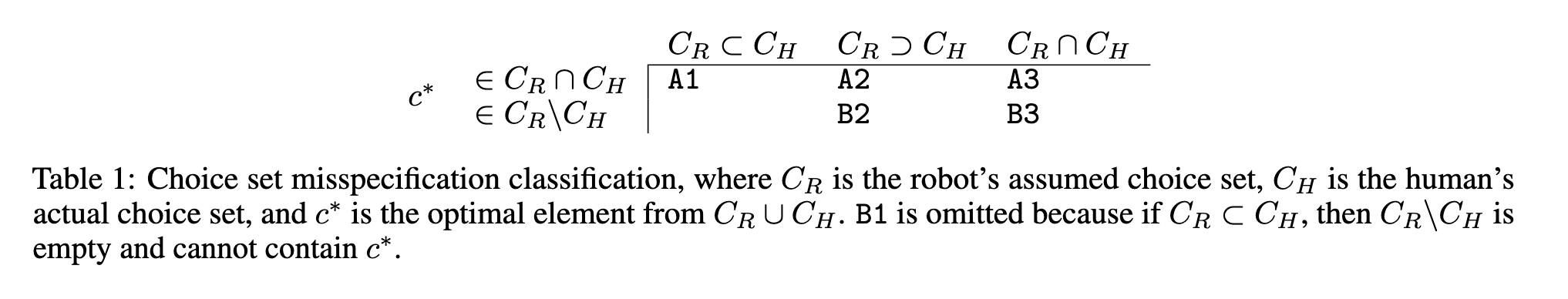
Experiments to study misspecification categories
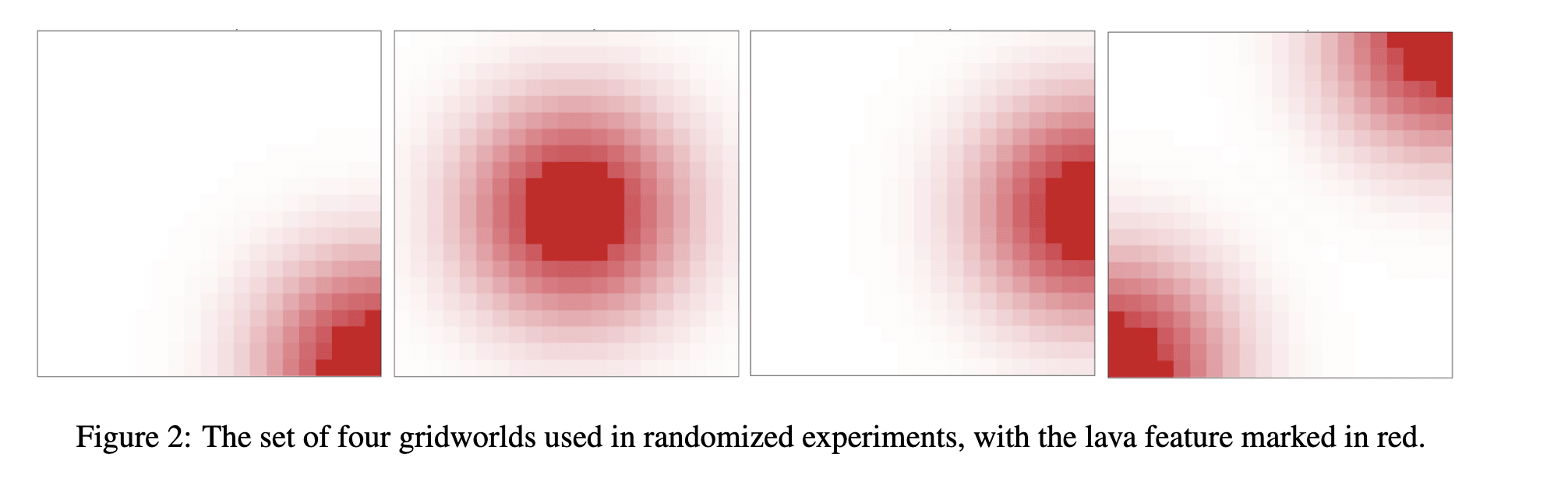
The paper runs a set of experiments on a 20x20 grid, where each cell has a value of lava between [0,1] and it gets 3 rewards (w_lava (mostly negative) reward for coming in contact with lava, (w_alive reward for staying alive and w_goal=2.0 for reaching the final goal). The true reward is a linear combination of these. Here the exhaustive choice set is all the paths that you can take in 35 time-steps (this is an arbitary cutoff for the experiment).
We can then generate artificial C_R and C_H as some subsets of this exhaustive choice set based on which category of misspecification we want to study (see above table). For example, we might restrict our to have no diagonal paths and to have both diagonal and non-diagonal paths, therefore putting us in the class B2.
In the experiment, we first simulate human choice sets by playing out trajectories using the true reward function (and the corresponding optimal policy that the MDP results in). Only the simulated human knows the exact values of w_lava and w_alive, our robot doesn't know it and our job is to use the demonstrations to learn them (as discussed at the start our main job is to learn true reward from demonstrations). We then pick the best trajectory (based on the true reward) and the robot updates its posterior about w_lava and w_alive using and . Formally, we end up learning two different rewards
&
We measure the difference between and using
- Entropy : Which measures how certain or uncertain our model is about the \theta it ended up at. By "certain" what we mean is the result of our experiment would be probability distribution over
w_lavaand overw_aliveif these distributions are sharp (concetrated at one point then it's more certain). More uncertainty = more spread out distribution = higher entropy. So if ∆H > 0 it means that the robot's choice set made it more confident than it should have. And if ∆H < 0 it means that the robot's choice set made it less confident than it should have. Why can both be bad? In certain situation, we want the robot to be really confident of what it is doing and and its utility depends on it, I don't want a medical robot whose reward function is uncertain about what to do during surgery, its reward function should be very clear about which equipment to use and what part of the body to operate on. It shouldn't be like 50% of my reward function says that removing the liver is good the other 50% says it's not. On the other hand, a robot that is tasked with serving customers can get away with a reward function which is more spread out. The robot can be unsure about what exact meal to serve, but still get away with it since serving a pizza over pasta is not as disastrous as operating on the wrong body part. Infact, for such a robot, a more spread out probability distribution might result in better experience. - Regret[6]: . After we find the two reward functions, we can find the optimal trajectories using value iteration[7]. We then evaluate these two trajectories using the real reward function. So Regret>0 means the true reward we get is less due to choice set misspecification.
Understanding Results
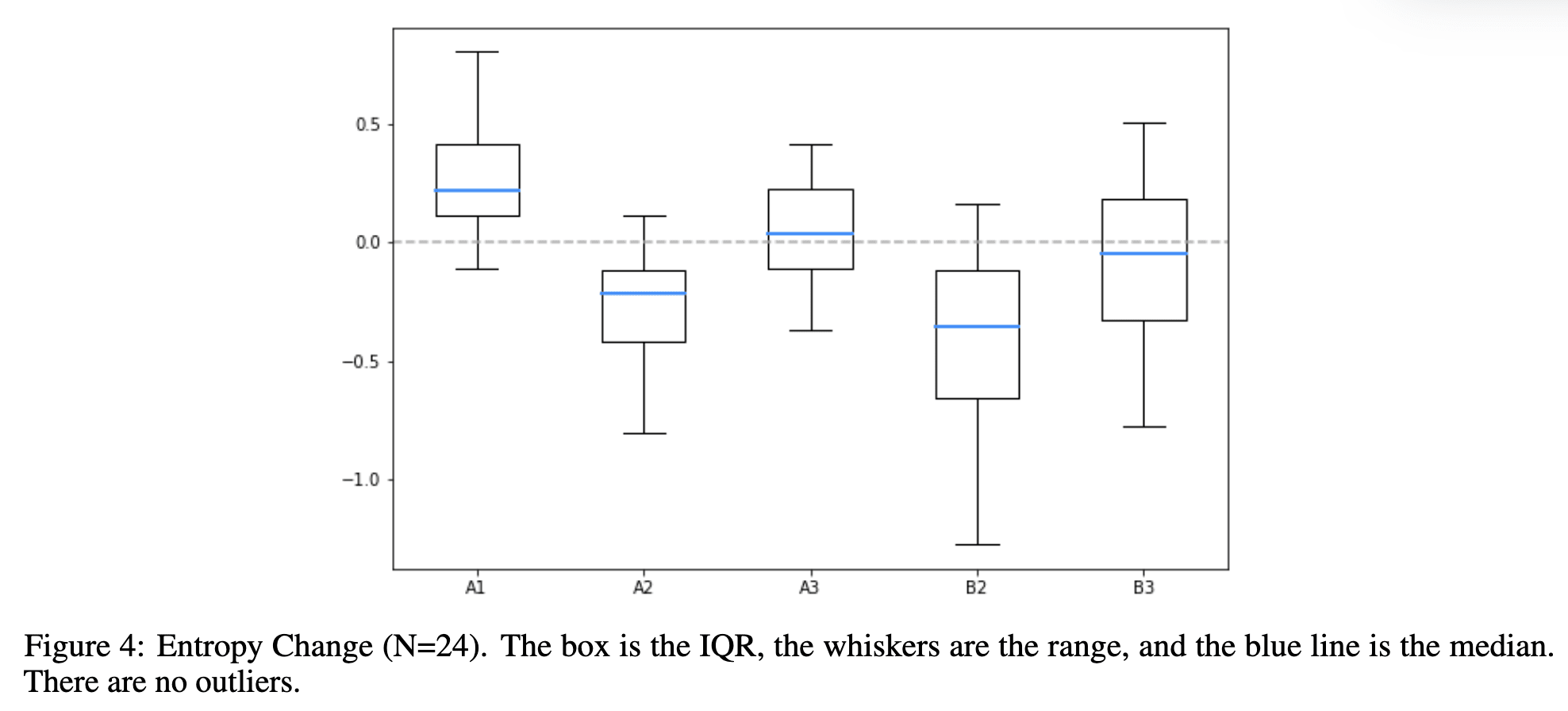
Observations about entropy
- A1 and A2 are symmetric about the mean. Why is A1>0 and A2<0. To me intuitively this is because in A1 the choice set of robots is smaller than the human, it then observes the optical choice come in that set and gets more confident (because it doesn't have access to lot of other choices in C_H since C_R is smaller than C_H). For A2, C_R is larger than C_H which means after seeing the opitmal choice it is NOT as confident as it should be (because in the robot's mind there are so many other choices which it considers that the human doesn't since C_H > C_R).
- A1 and A3 did not overlap with the IQR (interquartile ranges) of A2 and B2 and both A3 & B3 have less distinctive changes.
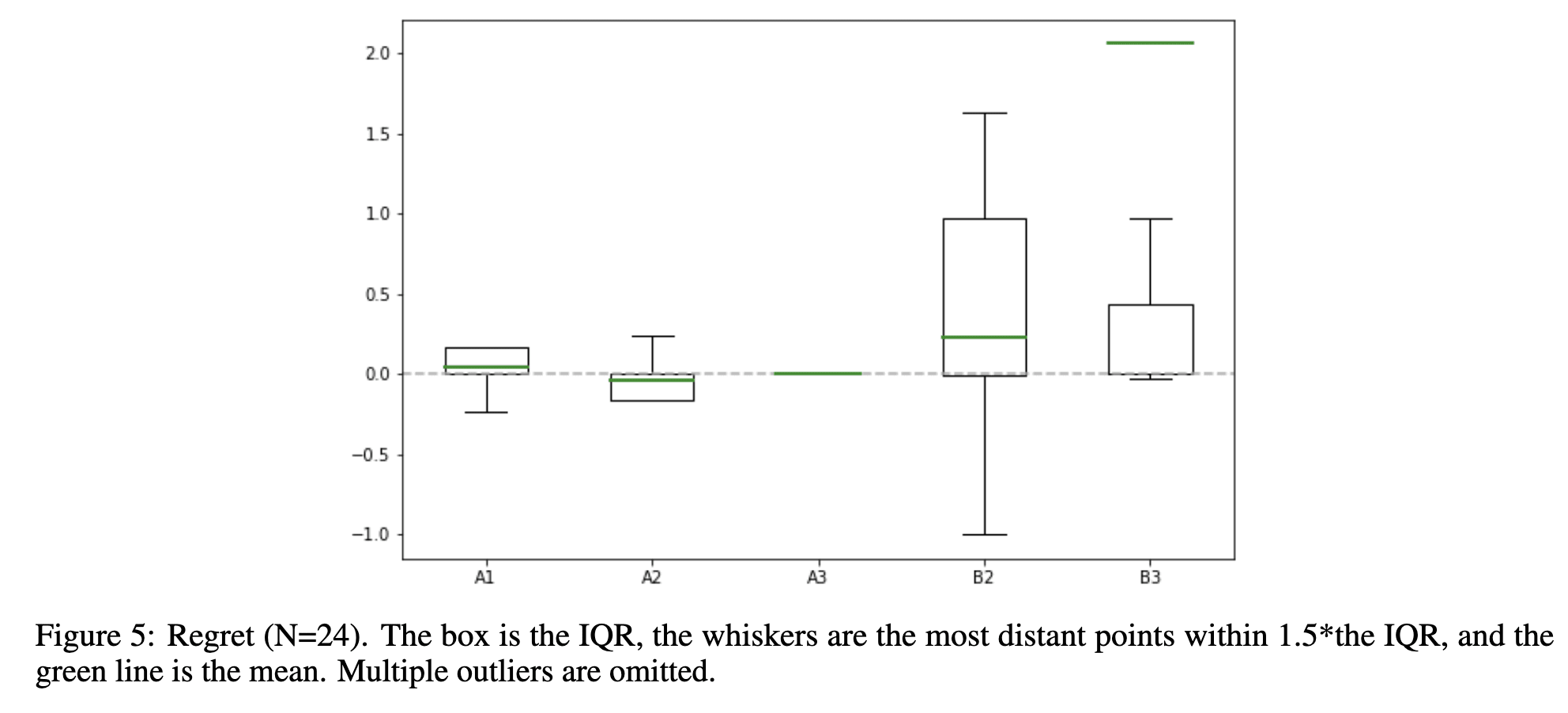
Observations about Regret
- As a whole, regret has less deviation than entropy. Suggesting that the reward function we end up with human choice set and the robot choice set are often close enough.
- Similar to entropy, A1 and A2 are symmetric. This is because if we switch the contents of and in an instance of class A1 misspecification, we get an instance of class A2 with exactly the opposite performance characteristics. Thus, if a pair in A1 is harmful, then the analogous pair in A2 must be helpful.
- B3 has a lot of outliers suggesting the reward function we get from the robot choice set is very deviated away from the true reward. This is because, B3 is the only example where the human choice can actually be the worst example in C_R. This can't happen in B2 because the worse example in C_H will also be the worse example in C_R. Remember in "B", the c* is not present in C_H. A more thorough explanation is provided in the paper which I can explain in detail below
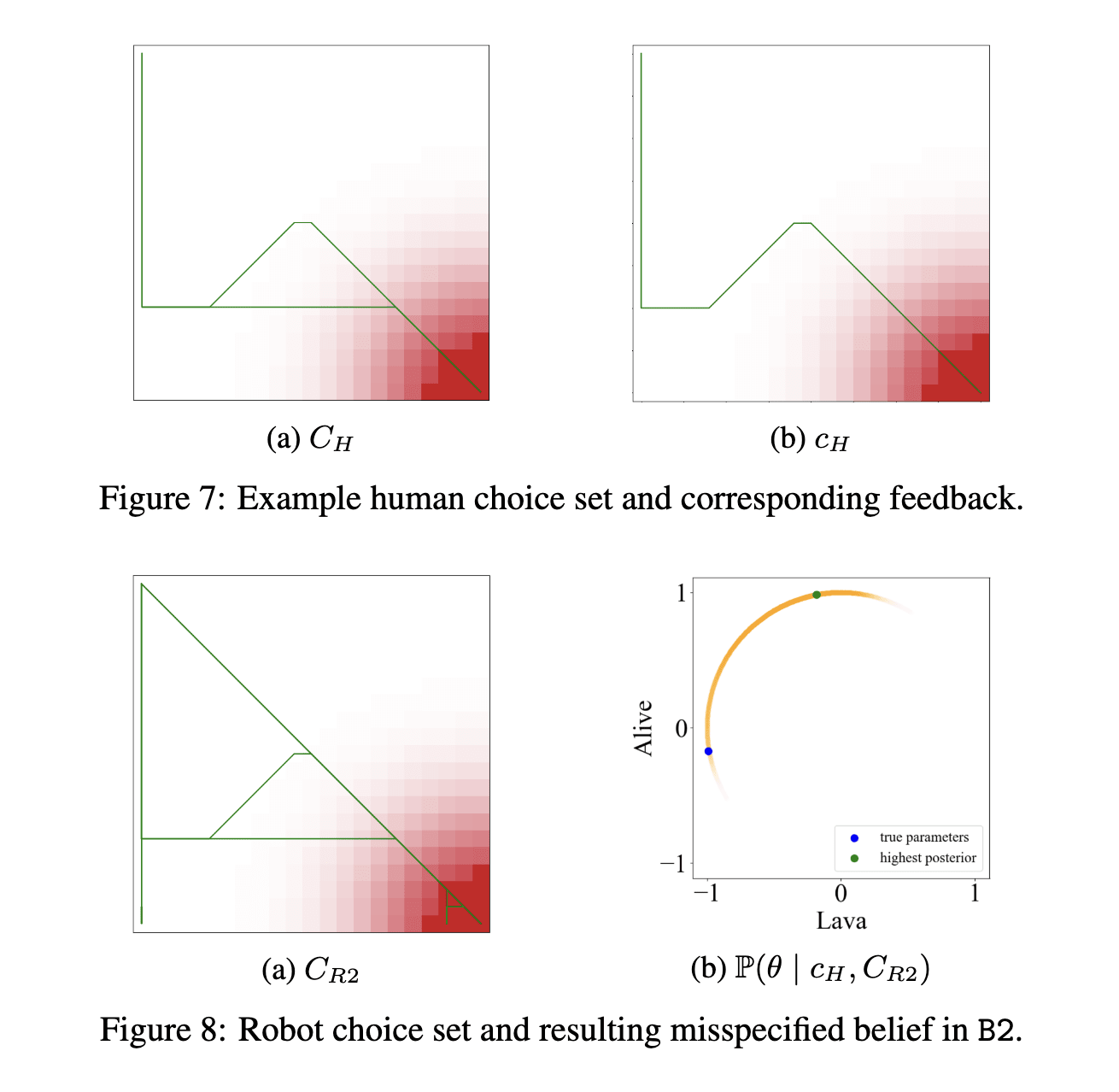
B2 vs B3. Bad vs Worse
First, lets assume we have two choices in the C_H, (the two green lines in Figure 7a). Both are bad choices since they take unnecessary long paths, but the the longer choice has less lava so its preferred by the human. This is our that we will use to update our beliefs about w_lava and w_alive. Now look at Figure 8a, it has 3 trajectories, one of them is , the others are its own trajectories from . We are telling the robot that "the c_h trajectory is longer than the others you have, therefore adjust your reward to take this into account". This means the robot adjusts its reward so that longer paths are reward by having w_alive>0 .
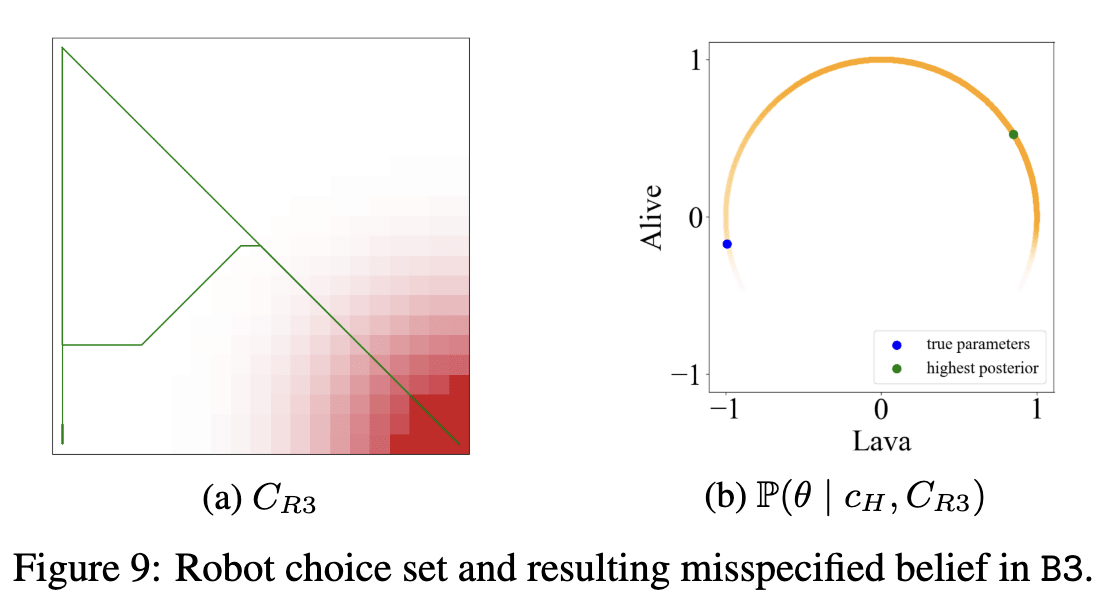
Next, we look at B3. Here again our c_h remains the same as above. Its the longest path in Figure 9a (if you are still confused, this is the same path as 7b). Remember, B3 is the case where this path is the worst path in C_R, so in Figure 9a, the other two choices are better. In previous example, c_h was the worst in terms of only length but here its worst in terms of both length and lava, which means we are basically saying to the model, "the best c_h is with maximum lava and maximum length, so adjust your reward such that both these things are rewarded" which leads to w_lava>0 and w_alive>0. We move in the opposite direction of the truth, explaining the big increase in regret.
Wait, why did this not happen in B2? Because remember B2 is the case where human choice is subset of robot choice. So, lets say we have 10 human choices, and our was the best of them, this means there are atleast 9 choices in the robot choice (since robot choice is superset) which our worse than . So when we go to the robot and say "adjust your reward to make paths like have more reward value" we are atleast pushing it away from the worst 9 choices, so its not as bad as B3 where we might be pushing towards the worst value itself. What happens if ? This is a very special (and non-practical) case because the human has no choice at all. It can only do one action.
Connection to Alignment
So how does choice set misspecification matter for alignment? If we had a super intelligent AI which is much smarter than any and all humans combined (like GPT-10 will be) then something like "minimize human suffering" wouldn't cut it. Because either it can reward hack (nuke the entire earth, no humans = no suffering) or plug us all into the matrix (again no human conscious to feel suffering = no suffering). Even if it saw, human demonstrations of what it is like to be "good" or "bad", the misspecification between choice sets could lead to very different outcomes, for example, AGI will be able to think of ideas that no human can or atleast much faster than any human, so there is huge possibility that the choice sets of human actions and AGI actions will not be aligned. But then we have a second axis where the AGI doesn't have a body of its own (for now), which means there are some actions that a human can perform that it can't. Therefore in the future we might find ourselves somewhere in the B3 or B2 category. If the field of robotics catches up soon enough, I feel its highly probable that we find ourselves in B3. And if we have learned anything from this paper, it is that B3 is not a good place to be if we want to align reward functions between humans and robots.
- ^
https://arxiv.org/pdf/2209.13085
- ^
This is similar to Goodhart's law: "When a measure becomes a target, it ceases to be a good measure."
- ^
https://ai.stanford.edu/~ang/papers/icml00-irl.pdf
- ^
A robot and human might fundamentally differ in what choices they can make, e.g. a human person cleaning can do things that a robot can't and vice-versa
- ^
Boltzman rational
- ^
We have 1/4 and x=0 to x=3 because we run are experiments on 4 different grid worlds and average it here
- ^
0 comments
Comments sorted by top scores.