Predicting AI Releases Through Side Channels
post by Reworr R (reworr-reworr) · 2025-01-07T19:06:41.584Z · LW · GW · 1 commentsContents
The Core Idea How I Tested This What I Found Limitations Why This Approach Could Still Work Next Steps for Anyone Interested None 1 comment
I recently explored whether we could predict major AI releases by analyzing the Twitter activity of OpenAI's red team members. While the results weren't conclusive, I wanted to share this approach in case it inspires others to develop it further.
The Core Idea
The idea came from side-channel analysis - a technique where you gather information about a system by looking at indirect signals rather than the system itself. Think tracking factory electricity usage to estimate production volumes, or stealing an LLM’s softmax layer through logprobs.
When OpenAI prepares to release a new AI model, their red team (safety and robustness testers) gets access to it a few weeks before launch. I hypothesized these intense testing periods might reduce red teamers' social media activity, creating a detectable pattern before releases.
How I Tested This
- Identified ~30 red team members from OpenAI's system cards
- Scraped their Twitter timelines
- Analyzed activity patterns around known model release dates
What I Found
The data showed a slight dip in Twitter activity before launches, but the signal was too weak to be reliable.
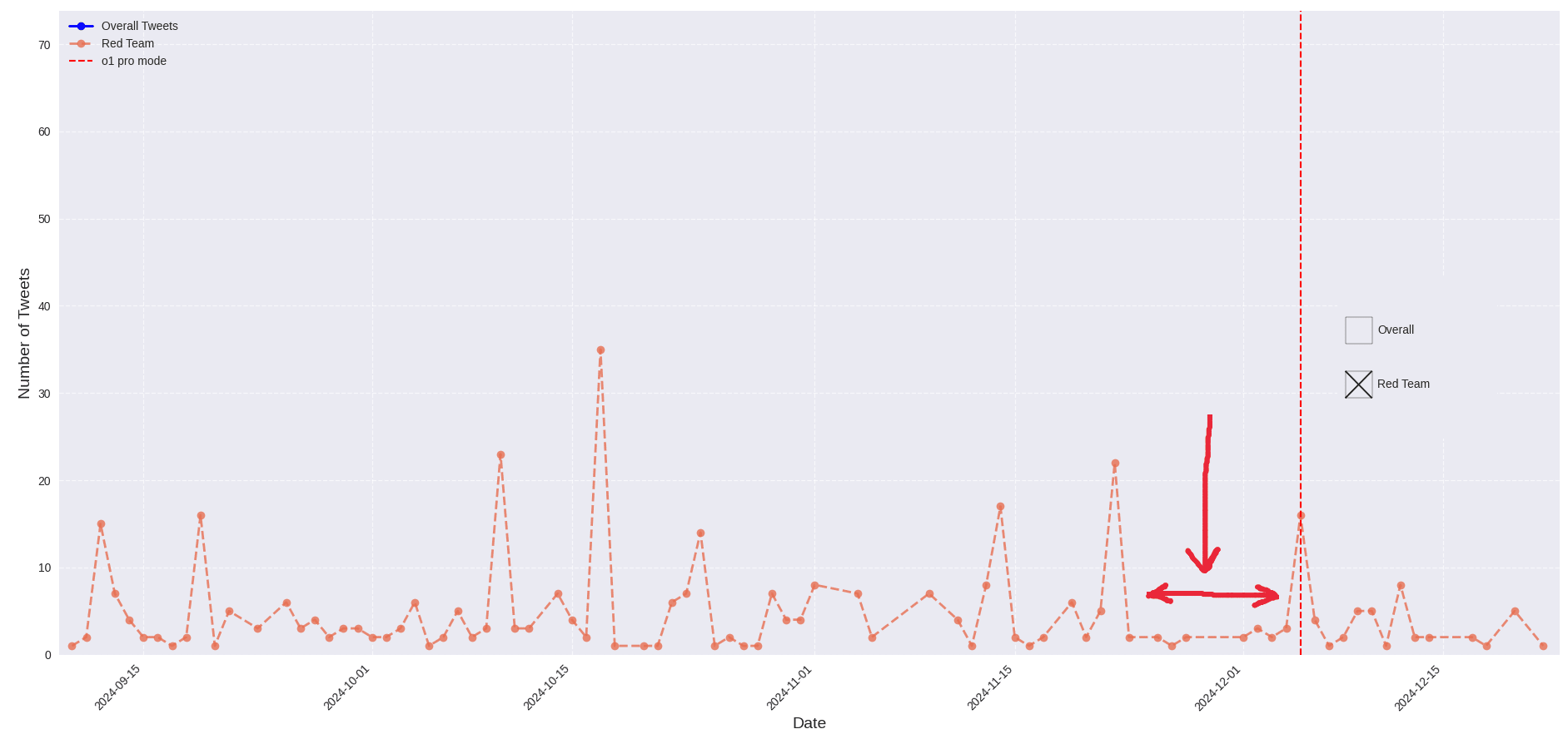
Limitations
Two main factors prevented more definitive results:
- Small sample size (only ~30 accounts). To get more statistical power, we’d need to look at more employees or additional side channels.
- Twitter API restrictions that limited data collection. To get more timeline data, you’ll need to find a Twitter dump.
Why This Approach Could Still Work
Despite inconclusive results, this method of tracking "side-channel signals" - indirect indicators like social media patterns, GitHub commits, or hiring changes - could prove valuable with refinements. Similar approaches have worked in other fields.
Next Steps for Anyone Interested
If you'd like to build on this idea, consider:
- Expanding to other/larger companies (Google, Meta)
- Exploring different indicators beyond Twitter
- Developing ways to aggregate multiple weak signals
I won't be continuing this research myself, but I hope sharing these preliminary findings helps someone else take this idea further.
Reworr works as a researcher at Palisade Research. The views expressed here are their own.
1 comments
Comments sorted by top scores.
comment by tchauvin (timot.cool) · 2025-01-09T13:50:40.356Z · LW(p) · GW(p)
Nice attempt. This reminds of the Pizza Meter and Gay Bar Index related to Pentagon crisis situations. I found it hard to find reliable information on this when I looked (I can't even find a good link to share), but the mechanism seems plausible.