'High-Level Machine Intelligence' and 'Full Automation of Labor' in the AI Impacts Surveys
post by Jeffrey Heninger (jeffrey-heninger) · 2025-02-07T20:40:52.388Z · LW · GW · 1 commentsContents
The 60+ Year Gap Possible Explanations AI Researchers Aren't Thinking Clearly or Consistently about the Future of AI Major Negative Disruptions Feasibility and Adoption What Is a ‘Task’? What to Do? Which Is AGI? None 1 comment
The 60+ Year Gap
AI Impacts has run three surveys (2016, 2022, & 2023) asking AI researchers about how they expect AI to develop in the future.[1] One of the key questions addressed was when AI capabilities will exceed human capabilities.
The surveys did not ask directly about 'Artificial General Intelligence' (AGI). Instead, they asked about two similar terms: 'High-Level Machine Intelligence' (HLMI) and 'Full Automation of Labor' (FAOL). These terms were defined in the surveys as follows:
High-level machine intelligence (HLMI) is achieved when unaided machines can accomplish every task better and more cheaply than human workers. Ignore aspects of tasks for which being a human is intrinsically advantageous, e.g. being accepted as a jury member. Think feasibility, not adoption.
- p. 4 (emphasis in original).
Say an occupation becomes fully automatable when unaided machines can accomplish it better and more cheaply than human workers. Ignore aspects of occupations for which being a human is intrinsically advantageous, e.g. being accepted as a jury member. Think feasibility, not adoption.
[…]
Say we have reached 'full automation of labor' when all occupations are fully automatable. That is, when for any occupation, machines can be built to carry out the task better and more cheaply than human workers.
- p. 7 (ellipsis and emphasis in original).
Respondents were asked either about HLMI or FAOL. The versions of the survey were randomly assigned, so we should expect the two groups to be similar.
Originally, Katja Grace intended for the term 'task' to be very general. Any occupation could be considered to be a particular complicated task. The predictions for HLMI should then be similar to, but strictly farther in the future than, predictions for FAOL.
This is not what the surveys found.
Instead, researchers' predictions of when there would be a 50% probability of FAOL have been at least 60 years farther in the future than the corresponding predictions of HLMI. The FAOL predictions are also a lot more volatile than the HLMI predictions.
| Survey Year | HLMI Predicted | FAOL Predicted |
| 2016 | 2061 | 2136 |
| 2022 | 2060 | 2164 |
| 2023 | 2047 | 2116 |
This is surprising !
To further emphasize this difference, here is a chart by Tom Adamczewski comparing the distribution of responses for these two questions in 2023.[2] The responses are not similar.
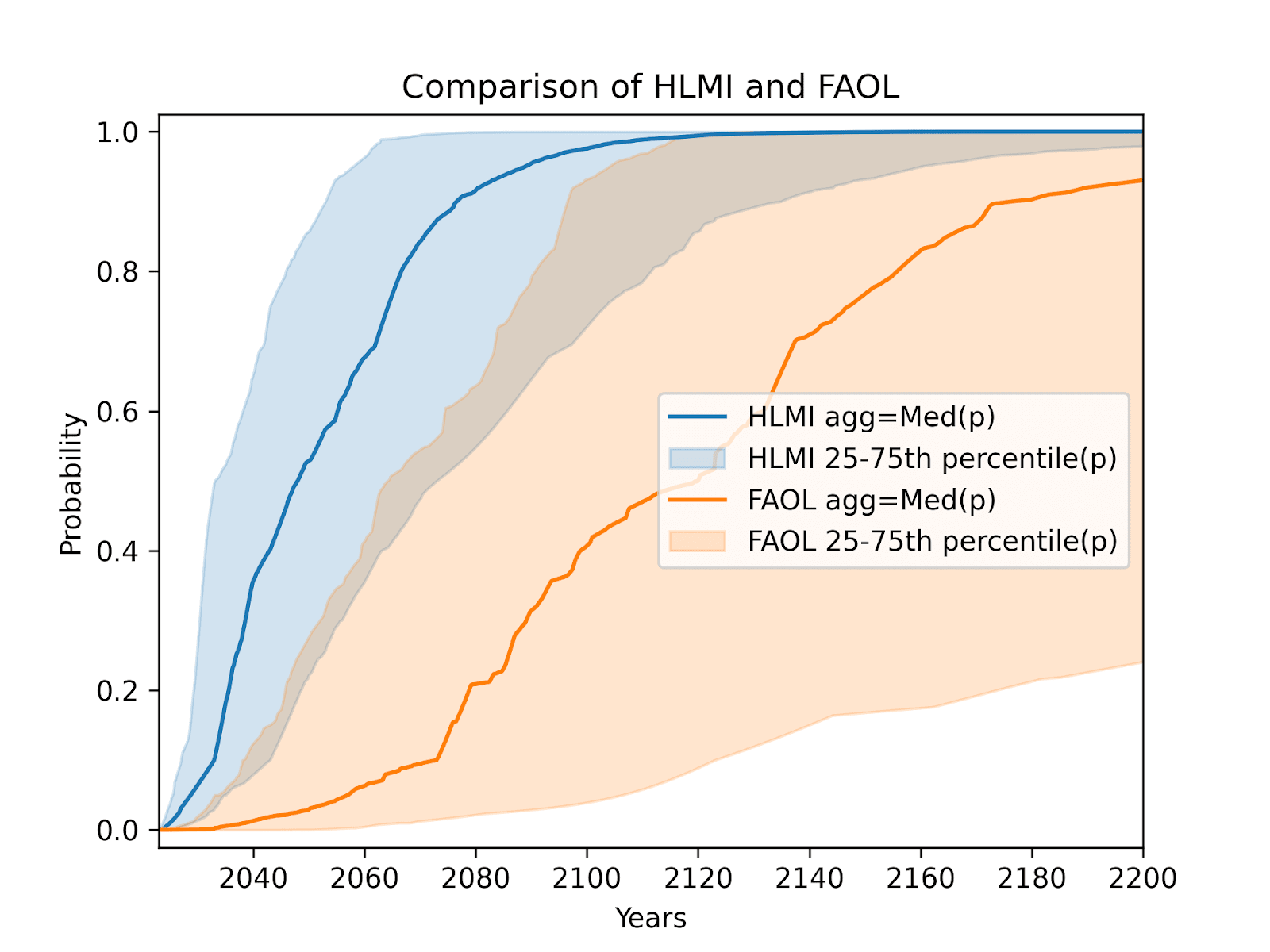
The most recent paper discusses the differences between these predictions:
Predictions for a 50% chance of the arrival of FAOL are consistently more than sixty years later than those for a 50% chance of the arrival of HLMI. This was seen in the results from the surveys of 2023, 2022, and 2016. This is surprising because HLMI and FAOL are quite similar: FAOL asks about the automation of all occupations; HLMI asks about the feasible automation of all tasks. Since occupations might naturally be understood either as complex tasks, composed of tasks, or closely connected with one of these, achieving HLMI seems to either imply having already achieved FAOL, or suggest being close.
We do not know what accounts for this gap in forecasts. Insofar as HLMI and FAOL refer to the same event, the difference in predictions about the time of their arrival would seem to be a framing effect.
However, the relationship between "tasks" and "occupations" is debatable. And the question sets do differ beyond definitions: only the HLMI questions are preceded by the instruction to "assume that human scientific activity continues without major negative disruption," and the FAOL block asks a sequence of questions about the automation of specific occupations before asking about full automation of labor. So conceivably this wide difference could be caused by respondents expecting major disruptions to scientific progress, or by the act of thinking through specific examples shifting overall expectations. From our experience with question testing, it also seems possible that the difference is due to other differences in interpretation of the questions, such as thinking of automating occupations but not tasks as including physical manipulation, or interpreting FAOL to require adoption of AI in automating occupations, not mere feasibility (contrary to the question wording).
- p. 7 (emphasis in original).
I do not know what is going on here.
Most people reporting on these surveys only mention the results for HLMI.[3] A few note the difference between these predictions.[4] It is also possible to aggregate these two results into a single prediction, in 2073.[2] The difference between predictions for HLMI and FAOL seems underappreciated in the discourse surrounding the AI Impacts surveys.
Possible Explanations
I would like to go through several of the possible explanations. None of these seem completely satisfactory. There could also be multiple compounding explanations.
If you think of other plausible explanations, please share them !
AI Researchers Aren't Thinking Clearly or Consistently about the Future of AI
Some of the results of the survey suggest that most AI researchers do not have clear and self-consistent predictions about the future of AI.
The clearest evidence of this is that people give somewhat different predictions depending on how you refer to years in the future. The surveys asked about when people expected HLMI[5] in two ways. Either they asked what the probability of HLMI will be in 10, 20, or 50 years ('fixed-year'), or they asked what year they expected there to be a 10%, 50%, or 90% chance of achieving HLMI ('fixed-probability').
In each of these surveys, the fixed-year predictions had HLMI arriving about 20 years later than the fixed probability predictions. This is substantial, although much smaller than the 60+ year gap described above.
AI researchers do not have to be good forecasters. It appears as though they are not responding on the basis of a self-consistent model of the future.
Nevertheless, when we think about the future of AI, it seems useful to know what AI researchers think, even if you do not expect their predictions to be accurate. This is how I think the survey results should be used.
Major Negative Disruptions
The HLMI questions were preceded by the phrase “assume that human scientific activity continues without major negative disruption.” The FAOL questions were not.
One way of reconciling these different views is if AI researchers expect there will be a major negative disruption before the advent of HLMI or FAOL.
I’m not sure what major negative disruption they’re expecting. The timelines they give without disruption are short enough that catastrophic climate change, pandemics substantially worse than COVID,[6] and nuclear war are not particularly likely.
Maybe they expect that disruption is caused by transformative AI which does not meet these definitions, but does still cause societal collapse.
It might also be possible that AI capabilities researchers expect PauseAI activists to succeed. This would be a surprising implication of the survey results – especially since PauseAI did not exist back in 2016 when the first survey was conducted.
My guess is that most respondents were not thinking about major negative disruptions when answering the FAOL questions. This explanation for the difference requires most respondents to have been reading the wording of the questions more closely than I expect that they were.
Feasibility and Adoption
For both HLMI and FAOL, the surveys told respondents to “think feasibility, not adoption.” Maybe they thought about feasibility for HLMI and adoption for FAOL.
I can see how the term “full automation of labor” might feel more like it were referring to adoption than “high-level machine intelligence,” although the surveys explicitly told them not to think that way.
The future that is expected under this explanation is which human occupations are automatable, but not automated. Anything a human could do, a machine could do better and cheaper, but people are still hired for these roles. This situation persists for more than 50 years.
This is an interesting claim about how society will develop in response to highly capable AI systems. I do not know if this is what many of the respondents were thinking about when answering these questions.
What Is a ‘Task’?
The initial intention of the surveys was that ‘all tasks’ and ‘all occupations’ would be similarly difficult benchmarks. If the word ‘task’ is interpreted differently, then this could explain the difference between the predictions for HLMI and FAOL.
One possibility is that respondents assumed that ‘tasks’ includes mental but not physical actions, while ‘occupations’ includes both mental and physical actions. This would imply that AI researchers expect that it would take more than 50 years of AI-assisted robotics research to match the dexterity of the human hand.
It is also possible that respondents think of a ‘task’ as something narrow and well-specified. Occupations can consist both of tasks and of responsibilities that are too broad or ill specified to be considered tasks. Building an AI that could perform an arbitrary task might then be much easier than building an AI that can navigate the complex and vague expectations of many occupations.
The respondents were either asked about 4 particular occupations, or were asked about 4 out of a list of 39 tasks before being asked about HLMI. The respondents expected FAOL to be later than any of the specific occupations, and HLMI to be later than all but one of the specific tasks.[7] Two of the occupations (surgeon and AI researcher) were rated as not being possible until further in the future than any of the tasks.
Respondents might have initially been uncertain about what the set of all tasks or the set of all occupations contains, and then used the examples given as typical examples. Since the particular tasks were expected to be solved sooner than the particular occupations, it would not be too surprising if the examples influenced when someone expected that machines could do everything-like-these-examples better and cheaper than a human.
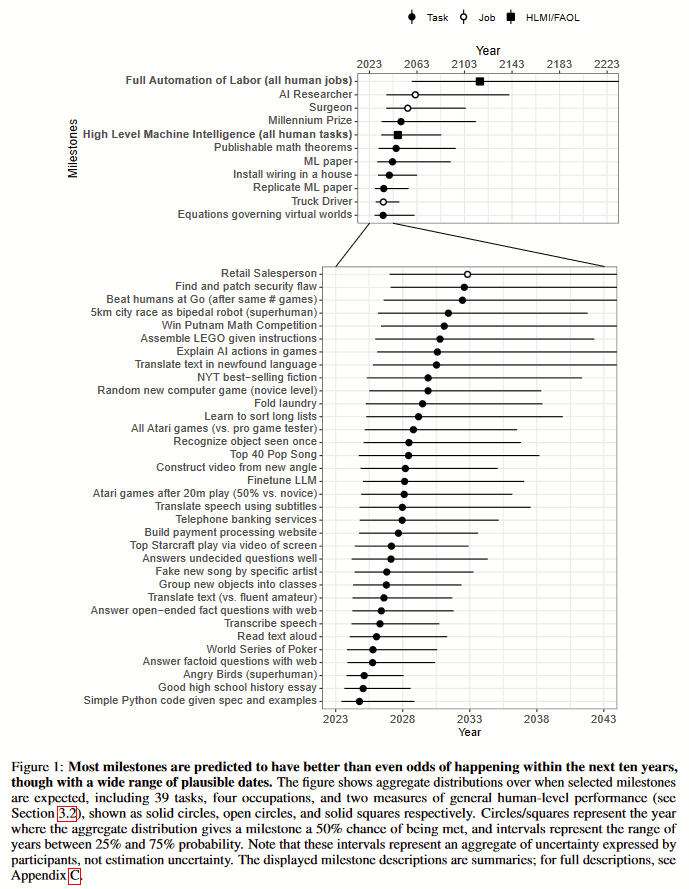
By best guess as to what is going on here is something involving what people are imagining a ‘task’ to be.
What to Do?
At this point, I should recommend some way to figure out whether HLMI or FAOL is closer to what AI safety researchers are concerned about. Unfortunately, I do not know how to figure out what AI researchers are actually thinking here.
Adding more to the definition of ‘task’ might be helpful, but I expect that most people won’t carefully read it. It might be interesting to ask some people about both HLMI and FAOL to see if those people give similar responses to the two questions.
One thing that someone could do with the data is to see whether people who were asked about different particular tasks gave different responses for the question about all tasks. We might expect that someone whose most difficult particular task was relatively easy would get shorter predictions for HLMI than someone whose most difficult particular task was relatively hard. If there is a significant difference here, then the particular examples are influencing what people think ‘all tasks’ refers to. Even if we find a difference, it is not clear whether that means that we should use FAOL as the default, or to do something else with the data.
There is a fourth AI Impacts survey currently ongoing, so we can see what else we can learn from those results when they come out.
Which Is AGI?
The term ‘artificial general intelligence’ (AGI), as used by AI safety researchers, has been defined multiple times by different people, and is somewhat ambiguous.[8] Is the way AI researchers interpreted HLMI or FAOL closer to what AI safety researchers are concerned about?
The definition of HLMI feels closer to the definitions of AGI often given. However, if AI researchers are thinking of a ‘task’ as being something narrow or well-specified, or as something like the few examples they saw, then they might not be thinking about AGI. In particular, something which could not automate AI researchers’ jobs is not sufficient for most AI safety researchers’ idea of AGI. In this case, FAOL might be a better proxy for AGI.
The difference between these two interpretations is not small.
‘Researchers expect AGI by 2047’ is a very different conclusion than ‘Researchers expect AGI by 2116.’
I am comfortable rounding ‘Researchers expect AGI by 2116’ to ‘Researchers expect AGI maybe never.’ The survey was not designed to measure predictions after 2100.[9] Even if it were, I am not convinced that we should trust forecasts of technological progress this far into the future.
The inconsistency between the HLMI and FAOL results makes me uncertain whether the median AI researcher thinks that AGI can be achieved in the foreseeable future or whether he thinks that AGI might never be built.
This is by far my main uncertainty in interpreting the results of the AI Impacts survey.
- ^
I was employed at AI Impacts during the later two surveys, but was not deeply involved with either.
- ^
Tom Adamczewski. How should we analyse survey forecasts of AI timelines? AI Impacts. (2024) https://aiimpacts.org/how-should-we-analyse-survey-forecasts-of-ai-timelines/.
- ^
Examples include:
Adam Bales, William D'Alessandro, & Cameron Domenico Kirk-Giannini. Artificial Intelligence: Arguments for Catastrophic Risk. Philosophy Compass 19.2. (2024) https://compass.onlinelibrary.wiley.com/doi/full/10.1111/phc3.12964.
Trevor Chow, Basil Halperin, & J. Zachary Mazlish. Transformative AI, existential risk, and real interest rates. (2024) https://basilhalperin.com/papers/agi_emh.pdf.
Jakub Growiec. Existential Risk from Transformative AI: An Economic Perspective. Technological and Economic Development of Economy 30.6. (2024) p. 1682-1708. https://journals.vilniustech.lt/index.php/TEDE/article/view/21525/12364.
Sabrina Renz, Jeanette Kalimeris, Sebastian Hofreiter, & Matthias Spörrle. Me, myself and AI: How gender, personality and emotions determine willingness to use Strong AI for self-improvement. Technological Forecasting and Social Change 209. (2024) https://www.sciencedirect.com/science/article/pii/S0040162524005584.
Jian-Qiao Zhu & Thomas L. Griffiths. Eliciting the Priors of Large Language Models using Iterated In-Context Learning. (2024) https://arxiv.org/pdf/2406.01860.
- ^
For example:
Scott Alexander. Through a Glass Darkly. Asterisk. (2023) https://asteriskmag.com/issues/03/through-a-glass-darkly.
- ^
A similar gap is also present when asking about FAOL.
- ^
COVID did not disrupt AI progress by decades.
- ^
This is not evidence that most of the individual respondents had inconsistent beliefs because most of the people who were asked about HLMI were not asked about the Millennium Prize Problems beforehand. Dávid Matolcsi also pointed out that we don’t actually know if these problems are within human capabilities.
- ^
Which is why these surveys used HLMI and FAOL instead.
- ^
The fixed-year respondents in particular were only asked about their predictions out to 50 years in the future. Pushing their prediction to after 2100 is an extrapolation.
The curve we fit to their results intrinsically has p → 1 as t → ∞, since it is a probability distribution. I think that this is also the case for the distributions Tom Adamczewski used. This is equivalent to assuming that everyone thinks that HLMI/FAOL is possible eventually with probability 1, which is probably not a safe assumption. These curve fits are good enough for interpolation, but I do not trust extrapolating them far into the future.
The high volatility of the FAOL forecasts is also evidence that the survey does not measure it very well.
1 comments
Comments sorted by top scores.
comment by Jakub Growiec (jakub-growiec) · 2025-03-06T09:28:20.717Z · LW(p) · GW(p)
I was also struck by this huge discrepancy between HLMI and FAOL predictions. I think that particularly FAOL predictions are unreliable. My interpretation is that when respondents are pushing their timelines so far into the future, some of them may be in fact attempting to resist admitting the possibility of AI takeover.
The key question is, what "automating all tasks" really means. "All tasks" includes in particular also all decision making: managerial, political, strategic, the small and the large, all of that. All the agency, long-term planning, and execution of one's own plans. Automating all tasks in fact implies AI takeover. But just considering this possibility may then easily clash with the view that many people have, namely that AIs are controllable tools rather than uncontrollable agents (see the excellent new paper by Severin Field on this).
And there will for sure be strong competitive forces pushing towards full automation, once that option becomes technically feasible. For example, if you automate production processes in a firm at all levels up to the CEO, but not the CEO, then the human CEO becomes a bottleneck, slowing down the firm's operations, potentially by orders of magnitude. Your firm may then be pushed out of the market by a competitor who automated their CEO as well.
My logic suggests that FAOL should be only slightly later than HLMI. Of course you should have first feasibility, then adoption. Some lag could follow from cost considerations (AI agents / robot actuators may be initially too expensive) or legal constraints, and perhaps also human preferences (though I doubt that point). But once we have FAOL, we have AI takeover - so in fact such scenario redirects our conversation to the topic of AI x-risk.