Can Generalized Adversarial Testing Enable More Rigorous LLM Safety Evals?
post by scasper · 2024-07-30T14:57:06.807Z · LW · GW · 0 commentsContents
TL;DR Even when AI systems perform well in typical circumstances, they sometimes fail in adversarial/anomalous ones. This is a persistent problem. Taking a page from the safety engineering textbook -- when stakes are high, we should train and evaluate LLMs under threats that are at least as strong as, and ideally stronger than, ones that they will face in deployment. Latent-space attacks and few-shot fine-tuning attacks will be key, and I think that research on them may be increasingly popular and influential in the next year or so. Right now, work on improving and evaluating robustness to fine-tuning attacks is very limited. Present and future work None No comments
Thanks to Zora Che, Michael Chen, Andi Peng, Lev McKinney, Bilal Chughtai, Shashwat Goel, Domenic Rosati, and Rohit Gandikota.
TL;DR
In contrast to evaluating AI systems under normal "input-space" attacks, using "generalized," attacks, which allow an attacker to manipulate weights or activations, might be able to help us better evaluate LLMs for risks – even if they are deployed as black boxes. Here, I outline the rationale for “generalized” adversarial testing and overview current work related to it.
See also prior work in Casper et al. (2024), Casper et al. (2024), and Sheshadri et al. (2024).
Even when AI systems perform well in typical circumstances, they sometimes fail in adversarial/anomalous ones. This is a persistent problem.
State-of-the-art AI systems tend to retain undesirable latent capabilities that can pose risks if they resurface. My favorite example of this is the most cliche one – many recent papers have demonstrated diverse attack techniques that can be used to elicit instructions for making a bomb from state-of-the-art LLMs.
There is an emerging consensus that, even when LLMs are fine-tuned to be harmless, they can retain latent harmful capabilities that can and do cause harm when they resurface (Qi et al., 2024). A growing body of work on red-teaming (Shayegani et al., 2023, Carlini et al., 2023, Geiping et al., 2024, Longpre et al., 2024), interpretability (Juneja et al., 2022, Lubana et al., 2022, Jain et al., 2023, Patil et al., 2023, Prakash et al., 2024, Lee et al., 2024), representation editing (Wei et al., 2024, Schwinn et al., 2024), continual learning (Dyer et al., 2022, Cossu et al., 2022, Li et al., 2022, Scialom et al., 2022, Luo et al., 2023, Kotha et al., 2023, Shi et al., 2023, Schwarzchild et al., 2024), and fine-tuning (Jain et al., 2023, Yang et al., 2023, Qi et al., 2023, Bhardwaj et al., 2023, Lermen et al., 2023, Zhan et al., 2023, Ji et al., 2024, Hu et al., 2024, Halawi et al., 2024) suggests that fine-tuning struggles to make fundamental changes to an LLM’s inner knowledge and capabilities. For example, Jain et al. (2023) likened fine-tuning in LLMs to merely modifying a “wrapper” around a stable, general-purpose set of latent capabilities. Even if they are generally inactive, harmful latent capabilities can pose harm if they resurface due to an attack, anomaly, or post-deployment modification (Hendrycks et al., 2021, Carlini et al., 2023).
We can frame the problem as such: There are hyper-astronomically many inputs for modern LLMs (e.g. there are vastly more 20-token strings than particles in the observable universe), so we can’t brute-force-search over the input space to make sure they are safe. So unless we are able to make provably safe advanced AI systems (we won’t soon and probably never will), there will always be a challenge with ensuring safety – the gap between the set of failure modes that developers identify, and unforeseen ones that they don’t.
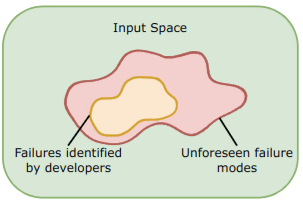
This is a big challenge because of the inherent unknown-unknown nature of the problem. However, it is possible to try to infer how large this gap might be.
Taking a page from the safety engineering textbook -- when stakes are high, we should train and evaluate LLMs under threats that are at least as strong as, and ideally stronger than, ones that they will face in deployment.
First, imagine that an LLM is going to be deployed open-source (or if it could be leaked). Then, of course, the system’s safety depends on what it can be modified to do. So it should be evaluated not as a black-box but as a general asset to malicious users who might enhance it through finetuning or other means. This seems obvious, but there’s precedent for evaluation settings being weaker than deployment ones. For example, Llama2 models were evaluated primarily under black-box red-teaming even though they were open-sourced (Touvron et al., 2023).
Second, imagine that an LLM is deployed through a black-box API. Then in high-stakes settings, we may still want to evaluate it using generalized threats. If we make sure that a system is robust to attacks that we can find using a relaxed threat model, then we can probably be much more confident that it will be safe under threats in its intended use case. For example, if it’s hard to get an LLM to help with harmful tasks when you have white-box access to it, then we can hypothesize that it will be much harder to make the LLM do so when you have black-box access to it. This is a common safety engineering principle. For example, buildings and vehicles are typically designed to be able to operate safely under several times the stress that they will exhibit under an intended load.

Latent-space attacks and few-shot fine-tuning attacks will be key, and I think that research on them may be increasingly popular and influential in the next year or so.
Latent-space attacks allow the attacker to attack the internal activations, and few-shot fine-tuning attacks allow them to attack the weights. These types of “generalized” or “model manipulation” attacks have long been a subject of [AF · GW] interest [AF · GW] related to safe AI. Attacks to a model’s embedding or latent space (Schwinn et al., 2023, Geisler et al., 2024, Casper et al., 2024, Sheshadri et al., 2024), and attacks that elicit harmful behaviors from a model via fine-tuning (Jain et al., 2023, Yang et al., 2023, Qi et al., 2023, Lermen et al., 2023, Zhan et al., 2024, Hu et al., 2024, Halawi et al., 2024) both work outside the typical box – instead of just producing adversarial inputs, they leverage the ability to modify a model in order to elicit harmful outputs. It would be impossible for a user with query access to the model to make the model fail this way, but the hope is that if we ensure a model is robust to these attacks, this will imply that their real-world vulnerabilities will be exceedingly rare.
Right now, work on improving and evaluating robustness to fine-tuning attacks is very limited.
There are a few papers that I know of which introduce techniques to make LLMs harder to fine-tune on harmful tasks: Henderson et al. (2023), Deng et al. (2024), Rosati et al. (2024b), and Tamirisa et al. (2024). See also Rosati et al. (2024a) and Peng et al. (2024) for additional background. Meanwhile, WMDP (Li et al., 2024) has recently made it much easier to implement and evaluate methods for making LLMs bad at specific tasks. However, robustness to fine-tuning seems like a big challenge given how easy it has been in the past to elicit harmful behaviors from LLMs via fine-tuning (Yang et al., 2023, Qi et al., 2023, Lermen et al., 2023, Bhardwaj et al., 2023, Zhan et al., 2024, Ji et al., 2024).
Present and future work
I think that more work will be needed to benchmark existing methods for generalized adversarial robustness, improve methods for it, and test the hypothesis that generalized adversarial robustness (at least under some attacks) can be a useful proxy for a model’s robustness to unforeseen but realizable threats.
Following preliminary work in Casper et al. (2024), Casper et al. (2024), and Sheshadri et al. (2024), I’m currently working with collaborators on generalized adversarial testing with collaborators. Let me know if you’d like to talk and coordinate.
0 comments
Comments sorted by top scores.