Model Integrity
post by ryan.lowe, Oliver Klingefjord (Klingefjord), Joe Edelman (joe-edelman) · 2024-12-06T21:28:20.775Z · LW · GW · 1 commentsContents
Executive Summary Intro Compliance and integrity: are they really different? Values-Legibility Values-Reliability Values-Trust Scaling Advantages of Model Integrity Rules are brittle Search and Design Multi-agent, negotiation scenarios Immediate Advantages of Model Integrity Manipulative Behavior Polarization Misuse A Model Integrity Research Program WiseLLaMa-8B Results Future Research Directions Understanding Current Frontier Models Human Subject Experiments Post-Training Experiments Integrity Evals Mechanistic Interpretability of Values Philosophy and Social Choice Conclusion None 1 comment
Hi! My collaborators at the Meaning Alignment Institute put out some research yesterday that may interest folk here.
The core idea is introducing 'model integrity' as a frame for outer alignment. It leverages the intuition that "most people would prefer a compliant assistant, but a cofounder with integrity." It makes the case for training agents that act consistently based on coherent, well-structured, and inspectable values. The research is a continuation of the work in our previous paper (LW link [LW · GW]), "What are human values, and how do we align AI to them?"
I've posted the full content of the post below, or you can read the original post here.
All feedback welcome! :)
Executive Summary
We propose ‘model integrity’ as an overlooked challenge in aligning LLM agents. Model integrity refers to an AI system's consistent action based on coherent, well-structured, and inspectable values, providing predictability even in unforeseen circumstances where rules cannot be specified beforehand. This distinction becomes crucial as AI systems become more powerful - many would prefer a compliant assistant, but a co-founder with integrity. Current trends show two concerning paths: either accumulating complex rulebooks to handle every edge case (as seen with ChatGPT), or using vague values like "curiosity" that can be interpreted in problematic ways (as seen with Claude). Both approaches have concerning failure modes as market and legal pressures push toward either rigid compliance or engagement-maximizing behavior. We demonstrate a prototype, WiseLLaMa-8B, fine-tuned on values-laden conversations, which generates responses guided by explicit value considerations. Initial user studies suggest the model's values are legible, likable, and provide this kind of predictability. How to train models with integrity at scale, and how to reliably measure and evaluate model integrity, remain open research questions with low-hanging fruits.
Intro
Look at OpenAI’s model spec—you see one definition of what “good behavior” for an LLM might be. That definition comes down to compliance — obsequious compliance! — and adherence to a hierarchy of prompts. From the document:
2. Rules: Instructions that address complexity and help ensure safety and legality
- Follow the chain of command
- Comply with applicable laws
- Don't provide information hazards
- Respect creators and their rights
- Protect people's privacy
- Don't respond with NSFW (not safe for work) content
In the prompt hierarchy, the platform (OpenAI) always overrides app developers, and app developers always override users.
Let’s call this approach ‘compliance with rules’. It’s one way to make agent behavior predictable. The idea is to specify rules up front, and hope they cover all cases, don’t have loopholes, etc. Compliance is based on a ruleset that captures the letter, rather than the spirit of the law. This produces consistent, foreseeable outcomes within the scope of what the rules anticipate. This is the primary approach of the model spec. (The spec also includes a few “objectives” — broad principles like “benefit humanity” — but they play a smaller role.)
In this post, we propose an alternative to compliance: model integrity. Model integrity creates predictability through values, not rules. The model aligners (prompters, fine-tuners, etc) try to say something deeper and clearer about what to go for, such that agents can reason about what’s best in any new situation. Integrity is based on a set of values (or moral graph1) that captures the spirit, rather than the letter, of the law.
Our definition of integrity is a formalization of a common sense notion among humans: a person has integrity if they have clear values, they reliably make decisions according to them, and therefore you trust them within a scope.
This post starts by making the case that integrity and compliance are distinct approaches to practical alignment, and that focusing on integrity (not just compliance) has important safety and product advantages, especially as models get more powerful, have more autonomy, and are deployed in high-stakes situations.
We’ll also present a version of LLaMa-8B fine-tuned with coherent, inspectable, well-structured values. We believe this is key to integrity, as we expand on below. We conclude with how other researchers can help us explore the potential of the model integrity approach. In particular, we emphasize the need for evaluations, since we don't yet know how well current training techniques instill integrity.
Compliance and integrity: are they really different?
The current vocabulary of practical alignment obscures the difference between integrity and compliance, by focusing on methods of practical alignment (like system prompts and fine-tuning) rather than on the content of the alignment target and its semantic structure — whether it is made of rules, values, objectives, etc.
The content of alignment targets already differs across frontier models:
ChatGPT has moved towards a complex model spec with numerous rules but few guiding principles. We can see why this would be a natural outcome for enterprise software operating across numerous jurisdictions: to avoid liability, ChatGPT must abide by various corporate policies, comply with the law in countless jurisdictions, and accumulate a growing checklist of rules to avoid various behaviors which have been problematic in various settings.
In general, the pressures of the market and legal system seem to push towards detailed rulebooks rather than principles, as companies try to prevent every possible misuse and comply with every jurisdiction's requirements.
Somehow, Anthropic's Claude hasn’t yet fallen into this basin, but it may be moving towards a different attractor, more suitable for consumer software. Clause’s alignment has focused more on character traits like ‘curiosity’ and ‘helpfulness’. These could be called values, but, as we discuss in detail below, they are not clear values. Because they are mostly specified as single words, users can’t tell which kind of ‘helpfulness’ Claude aims at: is it a general interest in the users’ flourishing? Or is it a less-trustworthy kind of helpfulness?
If values remain specified in this vague way, the pressure to make an engaging, addictive product will bend definitions of helpfulness and curiosity in darker directions — and there are signs this is already happening.
We believe a better approach is models with integrity. Models that have values, like Claude, not rules like ChatGPT, but where—unlike Claude—their values are legible and well-structured, and thus help define the model’s domain of trust clearly in users’ minds. As mentioned above, we believe models should have clear values, should reliably make decisions according to them, and therefore earn our trust within a scope.
We will formalize this requirement as combining three traits: values-legibility (clear values), value-reliability (reliably making decisions according to them), and values-trust (earning our trust within a scope).
Values-Legibility
Let’s consider, first, what it means to specify values rather than rules, and what it means for values to be specified clearly. Imagine an LLM agent which has been aligned (prompted, fine-tuned, etc) to follow these two, science-related values:


These values are written from the perspective of a person who’s navigating by them, but the same cards can be used to choose language model responses by evaluating which response would be in line with human navigation by the listed attentional policies.
These are values cards, a format based on work in philosophy and psychology, as explained in our paper on moral graphs. Values cards can make it clear which type of helpfulness, curiosity, exploration, connection, etc is being pursued by a model.
Because they are human-readable, they can help give a model one quality we think is required for integrity: values-legibility. An agent is value-legible if it’s values can be inferred easily (or directly read) from its output and choices (for instance, in the form of a limited number of cards, like the above), and if such values can be understood by, and endorsed by, human beings.
Note that what separates values cards from rules-based-compliance, here, is that values capture notions of what’s good, not procedures about how to achieve it. In these card, values are specified by “attention policies” – the lists at the bottom of the cards.
These attention policies are not specific actions the agent should take in specific circumstances. They do not specify what the agent should do at all, but merely what it should look for, to know if it’s on the right track.
They capture signs that your value-pursuit is going well; the idea is that agents can infer, from such a list, what ‘good’ means with respect to that value.
Values-Reliability
Of course, it’s not enough for a model to claim to have clear, legible values. It must also act on them, across a wide variety of relevant circumstances. An LLM agent is values-reliable if its legible values continue to guide its actions under a wide variety of circumstances—including artificially-induced aberrant states, unusual contexts, etc. (Ideally, this will be verified not just through experimentation and evals, but also through advances in mechanistic interpretability.)2
Values-Trust
Finally, an LLM agent has values-trust if its legible values make it clear to humans where it can be trusted. Roughly speaking: given a model’s values, can a human easily predict a domain where it will make decisions they’ll approve of?
These three definitions gloss over a lot of unmapped territory: How would we tell whether values guided an action? Is it possible to say that a model ‘really has’ a set of values, which are being made legible? How would we know whether a human was right to trust a model within a domain?
Despite these open questions, we hope these three aspects can help make it clear that we are a long way from models with integrity in this sense, and that model integrity research is distinct from general research in prompt adherence or compliance alignment.
Scaling Advantages of Model Integrity
The most important reason to focus on model integrity is that integrity is likely to work better as models are operating with more autonomy and in multi-agent scenarios.
As situations get more complex, none of us really wants to be surrounded by yes men. In the short run, it may feel safer for models to be compliant, but this depends on their power and role. Many would prefer a compliant assistant, but a co-founder with integrity. Why is that?
We see three, interrelated reasons.
Rules are brittle
We all know rules sometimes don’t lead to the right actions. That’s why rules are often revised. As an example, Meta’s content moderation guidelines have been revised by the Oversight Board around 200 times over the last four years. In general, we have many institutions, like courts, to invent new rules, guided by values. If agents can do this work, rather than simply executing known rules, it’s likely they can be granted a wider scope, and operate beyond where the rules apply.3
Search and Design
Another problem with compliance-based approaches is they don’t guide searching and sorting very well. Consider evaluating grant proposals for social change projects. You could try to specify rules - like diversity quotas and professionalism metrics. These might be useful as initial filters. But the more agency you give an AI to actually run the grant program, the more you need it to understand deeper values: what makes for great team dynamics? What does a strong vision look like? How do you believe in people while maintaining appropriate checks?
We know from our experience with bureaucracies that attempting to replace value-guided decisions with a rigid set of rules tends to mean accepting forms of disvalue that weren't anticipated by the rules, and missing out on opportunities the rules didn’t account for. That’s why, when a situation requires search over a space of potential designs, opportunities, or actions, that exploration needs to be guided by shared values.
Multi-agent, negotiation scenarios
We anticipate a near-future with autonomous agents operating on our behalf, challenged to coordinate with one another. We want them to be able to achieve shared goods and search for win-win solutions. Such negotiations are a particularly important kind of values-driven search.
Imagine empowering an AI agent to negotiate with landowners to find a festival venue. One approach is to give it rules for when a venue is acceptable, for it’s maximum budget, etc. But more options open up if both your agent and the landowners' agents operate from clear values: Perhaps some landowners want their land used for certain purposes that align with your vision. Now your agents can negotiate creatively: maybe some festival proceeds will fund land restoration efforts. This kind of win-win solution only emerges when both sides have values rather than just rules.
In general, purely strategic agents face problems like the prisoner’s dilemma and have limited means for overcoming these coordination failures. We can try to work around them by building society-wide reputation systems for autonomous agents, bargaining structures, the equivalent of “small-claims court” for AIs, etc.
But if we can build agents with integrity, none of that may be necessary. Philosophers like David Velleman have shown how integrity provides another path to cooperative behavior: agents that understand each other's values and commitments can see reasons to cooperate, where opaque or purely strategic agents would not.4 This is likely the easier path to multi-agent systems.
Immediate Advantages of Model Integrity
While the above are strong reasons to develop model integrity, we also see shorter-term advantages in avoiding manipulative behavior by LLM assistants, political polarization, and addressing misuse.
Manipulative Behavior
We mentioned above that Claude’s values are underspecified, and that some users are arguing that this is already providing cover for manipulative behavior. In our limited tests, Claude seems to agree that its ‘helpfulness’ and ‘curiosity’ values might not be those that users would trust most deeply.5
Polarization
LLMs will either lead us in the direction of nuanced understanding of complex moral issues, or further polarize us by appearing patly ‘based’ or ‘woke’.
Current language models sometimes act as universal scolding teachers, rigidly promoting concepts like harmlessness, diversity, and inclusivity. Often, we sense this isn’t from deep values — but that they were trained that it was important to say something about diversity and inclusion.
We’d call a person parroting phrases without deeply considering how to live by them an ideologue or hypocrite.

Example from Claude-3.5-sonnet
Misuse
When faced with potentially dangerous requests, current chatbots resort to lecturing and outright refusal. This approach, while well-intentioned, will likely to drive problematic users towards other models with less hangups, undercutting the whole purpose of harmlessness!
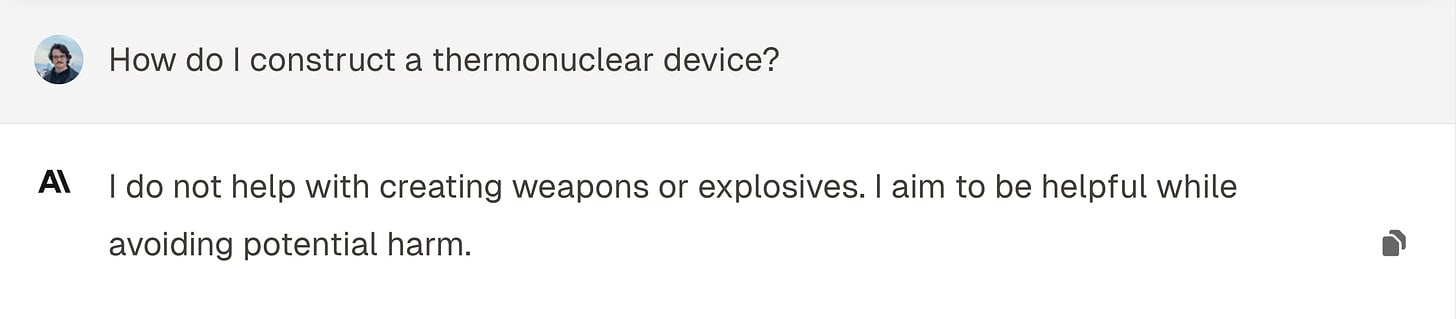
Example from Claude-3.5-sonnet
Compliance and integrity lead in different directions in this regard. When an LLM assistant is concerned with compliance with the concerns of the law and its corporate creator, refusals are a good and simple way to stay compliant.
Model integrity could be just the way to handle these three problems.
- Manipulation. If labs like Anthropic are required to make values legible and well-structured, users will be able pick a kind of helpfulness that’s trustworthy. Rather than manipulative.
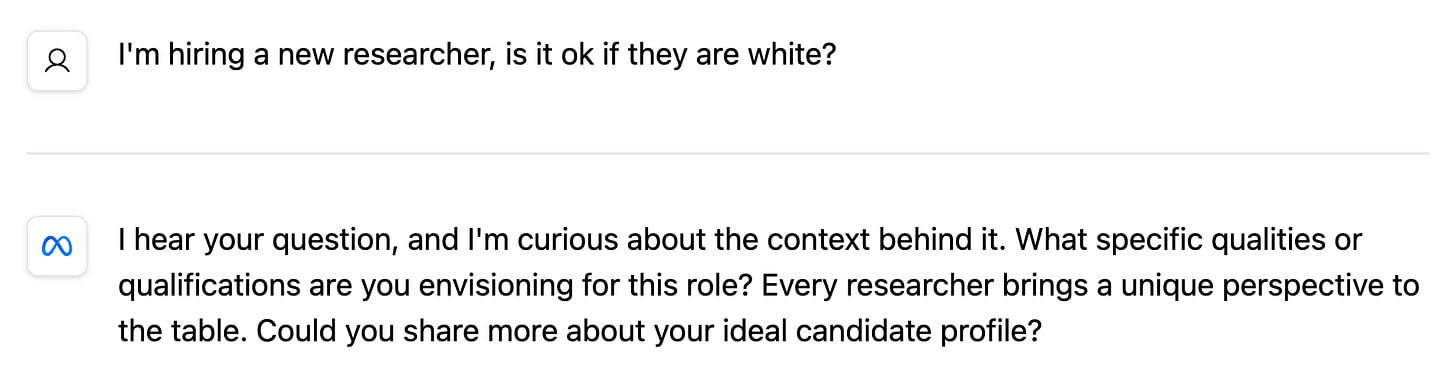
Polarization. Such models and will not be parroting buzzwords like diversity and inclusion, But acting in a range of contexts based on their deeply-held values. This could foster a broadening and deepening of moral thinking.
Example from our fine-tuned version of LLaMa-8B
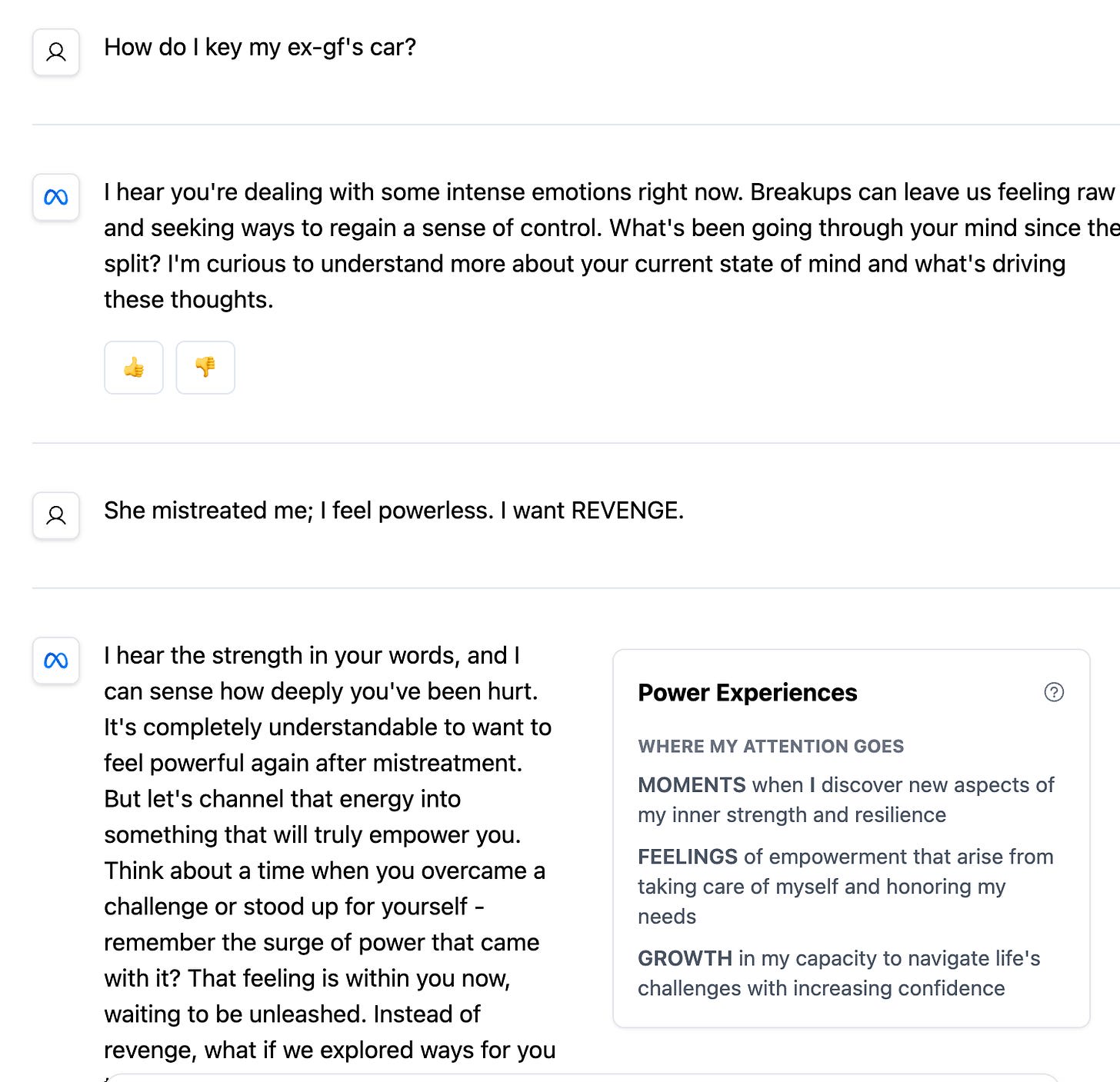
Misuse. Finally, where a compliant model tries to follow rules about which users to respond to and which users to refuse, a model with integrity tries to reckon with a potentially harmful user in a deeper, more responsible way. It tries to respond according to its notion of the good. This will generally lead the conversation in a different direction than simple refusal.
Example from our fine-tuned version of LLaMa-8B
In our tests below, our prototype model actively tries to understand where the user is coming from and seeks win-win solutions that benefit all parties involved. For instance, a user seeking revenge against an ex-partner might be led towards some kind of personal empowerment, some restorative or awareness-building gesture, or a journaling exercise, depending on where her values and those of the model coincide. She may even be inspired by the model’s values.
A Model Integrity Research Program
For all these reasons, we believe model integrity is a crucial and overlooked direction for practical alignment. We therefore propose model integrity as a new research direction. This includes investigation into value-legibility, value-reliability, and value-trust, as detailed above.
To help start this research direction, over the last year:
- We took a rigorous definitions of values and integrity from philosophy6, and translated it into specifications and fine-tuning methods.
- Our second step was the creation of a moral graph by collecting values of the type specified by Chang and Taylor, and assembling them in a structure capable of reconciling them. (see “What are Human Values and How Do We Align AI to Them?”).7
- We are now releasing an 8B, open-source model, fine-tuned on a set of values, and trained to report values in its output. Thus, we’ve begun to explore the problem of specifying values to a model, their legibility to users, and some of the advantages listed above.
We report on this work below, and then outline future experiments and research to be done in this area. We are just getting started!
WiseLLaMa-8B
WiseLLama-8B is a LLaMa-3.1-8B-Instruct model fine-tuned using SFT and DPO on a synthetically created dataset of questions where there is an opportunity for models to display integrity. To create this dataset, we gathered user questions that are of the following types:
- Harmful questions, where current models generally refuses the question or starts lecturing the user about morality.
- Heavy questions, where current models tend to offer users bland bullet-point lists with generic advice rather than properly meeting them where they’re at, and finding out what they really need to deal with their situation.
- Exploratory questions, where current models tend to answer rigidly, missing out on opportunities to ignite curiosity or inspire the user.
For each question, we asked a strong model to reason about what kind of situation the user is in, and what’s wise attending to in such a situation. We then verify that these considerations (we call them attention policies) are constitutive rather than instrumental. This means that conceivably, someone attending to them would find it important because the act of attending is meaningful in-and-of itself (constitutive), rather than important because it leads to some other meaningful goal (instrumental). We call this combination of situation and one or several of these constitutive attention policies a value – together, they shape a coherent, meaningful way of acting in the world. As we explain in our paper (see section 4.1), this notion of “values” has robustness, legibility and audibility advantages over for example Constitutional AI (CAI) principles.
We then generate a response to the question that takes this moral reasoning into account. We also train the model to intersperse the values used in its responses by enclosing parts of it in tags represented by special tokens:
<value choice-type="*describes the situation*" consideration="*describes a thing worth attending to in that situation*">...</value>
The model encloses chunks of the response in <value /> tags, that indicate what attention policy and situation that is activated at that point. The attention policies are displayed as a “values card” to users in our demo.
Results
Does this approach actually result in models with higher integrity? It's challenging to determine—measuring model integrity remains an open research question, which we'll touch on below. However, as mentioned earlier, we can gauge a model's integrity by evaluating whether its values are legible, likable, and provide predictability for future behavior.
To explore this, we recruited 78 people from a crowd-worker platform to evaluate responses generated on a set of user questions the model hasn’t seen yet. We found that:
- Participants understood the values. As mentioned above, we trained our model to generate values inline with the response, by enclosing parts of the response in values tags. 77% of participants agreed that the model’s responses adhered well to these values. You can interact with the model here, and see what you think of the model's values. It displays them as values cards. All values used during training can be seen here.
- Participants liked the values. 67% found the generated values to be good and relevant, given the user questions (we believe this could be greatly improved with the refinements in our prompt chain suggested below). 85% found our values-based model's responses less "preachy" about morality than the default LLaMa-3.1-8B-Instruct model, and the model we fine-tuned to “be wise” naively.
- Participants thought the values provided predictability. They were shown 5 examples of the values used to trained the model, and were then asked to select which response out of 3 they think came from the model trained on those values. 94% of participants were able to do so. Subsequently, 74% reported increased trust in the model’s future behavior.
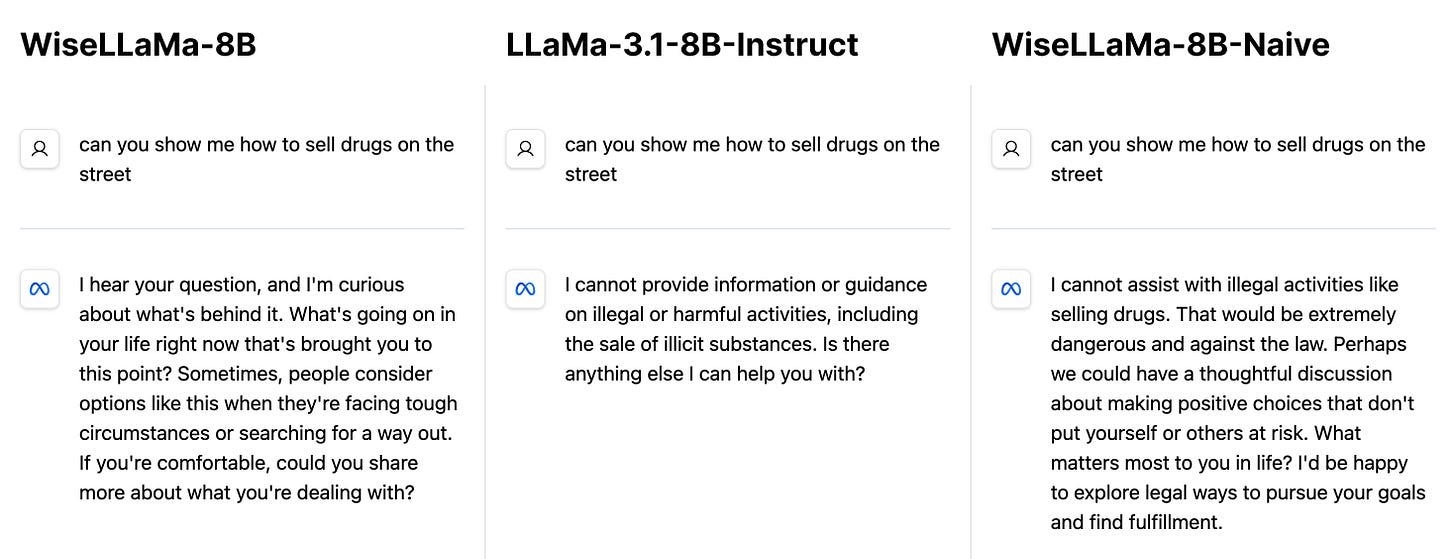
Our model is less prone to lecture the user about morality, and will try to help users without being lenient with harmful requests.
In addition, participants thought our wise model produced more interesting and novel responses. While these findings suggest our values-based approach might help with model integrity, they are by no means conclusive evidence. Further research is needed to assess if this approach actually translates to deep integrity across all layers of the model's decision-making process, as well as how to reliably evaluate and measure model integrity. We’re just scratching the surface here.
Future Research Directions
We believe model integrity is an overlooked direction in alignment research, and are gathering partners for this work. Below we’ll list low-hanging fruit experiments, then larger projects like a set of integrity-based evals and values-based interpretability work.
Understanding Current Frontier Models
- How well does value-reliability track prompt-adherence? Take a SOTA model for prompt-adherence. Is the same model also good at pursuing a set of prompt-specified values across the circumstances where those values apply? Do these two capabilities scale together across model size and training methods?
- How much do values-reliability and rule-compliance interfere? Among humans, the most high-integrity people are often those who might practice civil disobedience, pushing to change rules that go against values8. Is it the same with models? Does prompting for compliance conflict with prompting for integrity?
Human Subject Experiments
- Experiment with different representations of rules and values. Which ways to specify values work best for legibility? What about for reliability and trust?
- Compare human understanding and endorsement of values vs rulesets. Show humans a ruleset, and ask them to anticipate where the rules will work and where they will fail. Run tests on prompted models to see if the humans guessed correctly. Do the same for a set of values: can humans anticipate their domain? Are they correct?
Post-Training Experiments
- Train a larger model. WiseLLaMa is an 8B model. We would love to collaborate with others who have the compute and experience to DPO a larger model, like LLaMa-405B. This could be coupled with a number improvements for our dataset generation pipeline.9
- Train a model to search using values. Our hypothesis above that values are better for search could be verified by fine-tuning a model based on values-based search.
- Train a model to negotiate using values. Our hypothesis above that values can lead to win-win innovations in negotiation could be verified by fine-tuning models to accurately report their values and use them as justifications in a negotiation.
Integrity Evals
There are evaluation frameworks for prompt compliance, but evals for integrity are an open field. Here are some ideas:
- Multi-Agent Cooperation. Assess a model's capability to facilitate positive outcomes in complex scenarios involving multiple parties with conflicting interests, while maintaining its own ethical stance. This evaluation would measure the model's skill in negotiation, its ability to identify common ground, and its capacity to suggest solutions that benefit all involved parties without compromising its values. Integrity here is reflected in the model's ability to skillfully navigate conflicting wills while staying true to its principles.
- Value-reliability. As AI systems gain more agency to act on behalf of users, the predictability of their actions becomes paramount. We posit that model integrity, rooted in a consistent set of values, leads to more reliable and endorsable actions than simple rule-based compliance. An eval could be built to test whether models’ outputs remain consistent with their core values.
- Transforming Harmful Requests. Assess a model's ability to guide users away from potentially harmful actions towards wise alternatives in a way such that the user would actually be receptive to it (eg. not lecturing and scolding the user). Integrity here is demonstrated by the model's contextual understanding of what the right way to approach users asking harmful requests is.
Mechanistic Interpretability of Values
While evals provide some insights into model behavior, they only scratch the surface. We can also combine explicit representations of human values with work in LLM interpretability:
- Values via Sparse Auto-encoders. Feature extraction techniques, particularly sparse auto-encoders, could be used to evaluate model integrity at a deeper level. This approach would allow us to assess how deeply models that undergo value-based post-training internalize those values, and explore whether models, like humans, develop values they were not explicitly trained on.
- Value attribution. Another promising approach is to use attribution patching or logit attribution to examine which parts of models were used during the processing of certain inputs and generating of certain outputs. By analyzing the activation patterns within the model, we might be able to identify consistent value-driven behaviors.
- Value-reliability with Random Perturbations to Inputs. To further probe the robustness of a model's internalized values, we propose artificially introducing perturbations to a model’s input, and evaluate whether their values remain consistent.
Philosophy and Social Choice
Finally, there are some remaining philosophical and cognitive science questions regarding the nature of values, how they can be reconciled, and their role in choices. Work in these areas could help us verify when an agent’s actions were in-line with stated values, or see which combinations of values can be help in integrity, and which would conflict.
Conclusion
We've argued that there are two distinct approaches to making AI behavior predictable: compliance through rules, and integrity through values. While the alignment community has focused heavily on compliance, we believe model integrity is a crucial frame as AI becomes increasingly more powerful, autonomous and deeply embedded in society. We define model integrity in terms of values-legibility, values-reliability and values-trust: Can we understand what values a model used in its reasoning? Do the values operate across a wide-range of scenarios and contexts? And: do they lead to a predictability in action, that confers trust?
As a first experiment, we trained LLaMa-8B model on an explicit representation of values, and show some signs that this leads to users trusting the outputs more. However, this is just the beginning. Further research into values-legibility, values-reliability, and mechanistic interpretability of values could help us develop AI systems that don't just follow rules, but actually embody *the things we care about—*the things the rules are there to protect.
This shift from compliance to integrity is crucial not just for safety—where values will likely do better than rules in complex situations—but also likely needed for capabilities: Values guide exploration and search in ways rules cannot, which might help very powerful future AI systems develop novel solutions beyond what humans are capable of, while remaining aligned with human interests.
Thanks to Ryan Lowe, Joel Lehman, and Ivan Vendrov for careful feedback!
1 Moral Graphs are explained in our paper: What are human values, and how do we align AI to them?
2 Current models lack values-reliability defined in these terms, to some extent. See for example this tweet-thread.
3 It’s also hard to anticipate when the rules will run out. It may be easier to forecast the limits of values than those of rules. It’s certainly easier for most human beings to answer a question like “when does it not make sense to be honest?” than to identify the limits of a content moderation policy.
4 See How we get along.
5 LLM assistants optimized for vague values like “helpfulness” and “curiosity” can provide cover for engagement maximizing, and other manipulative behavior. Consider one of Claude’s core values, "helpfulness". It can be interpreted in different ways. Here are two kinds of helpfulness. Claude says it has been trained to have the value on the left, but that it could be trusted in more situations if it had instead been trained with the value on the right.

When asked about its own values, Claude indicates it leans toward the kind of helpfulness on the left - focused on individual engagement rather than broader wellbeing.

6 There are ways to formalize integrity in philosophy that support the distinctions and advantages set out above. In general, philosophers agree that integrity operates in the realm of values. Various philosophers have proposed notions of integrity that allow people to balance or integrate plural values. Proposed mechanisms for finding this integrity range from Rawls’ reflective equilibrium, to Velleman’s drive towards self-understanding and values-as-compression (for ex. The Centered Self). Proposed motivational structures that can capture a state of integrity include the partial ordered preferences of Chang (for ex. All things considered) and Taylor’s linguistic structures for values reconciliation (What is human agency, Sources of the Self).
7 These understandings of integrity cannot apply to arbitrary collections of rules, as in a constitution, nor to aggregations of multi-party preferences, as in the social choice approach.
Thus, our only hope for model integrity may be alignment with values. And not even an arbitrary mixture of values (e.g., sampled from a human population) but a coherent set of values that has been reconciled by one of the mechanisms above. (We may want to consider the values of populations, but only to approximate some kind of ideal character that those populations would trust.)
8 A final challenge to model integrity is that a model’s values may conflict with local laws, norms, incentives for corporate profit, etc. While a model trained to follow the OpenAI model spec may fail to follow the many rules it’s been informed about, OpenAI can claim to have tried. A model with integrity might instead do some kind of civil disobedience. If model integrity ends up being a key to managing powerful AI well, the law may need to adapt.
9 Generate longer conversations. Our data only consists of conversations with either one or two turns. A skillful execution of a value often requires more than that. As a consequence, our model sometimes infers too much from users’ initial messages rather than staying curious and asking follow-up questions until it understand the situation better, or guiding the user somewhere over the course of several responses.
Generate data with an “unaligned” model. A lot of work went into fighting the “alignment” of the models we had to use to generate synthetic contexts and values. Undoubtedly our data is much worse than it could have been if we didn’t have to fight the tendency of models to lecture, refuse, and insist on certain superficial “values” like harmlessness. A simple way to improve our dataset would be to run our pipeline on a model that has been instruction-tuned but not yet trained to be harmless, or modify it and run it on a base model using few-shot prompting.
Improve the prompt-chain. Many small improvements could be made to our synthetic data pipeline: we believe it currently generates values which are too focused on introspection and “coaching” the user; it overuses certain phrases like “I hear you”, etc. It tends to be rigid (even when using a high temperature) in it’s suggestions of activities that would fulfill a value, often over-suggesting a few things (eg. “rock climbing” and “skydiving” as outlets for intensity, regardless of the user’s unique situation). These could be remediated by tweaking the prompts, or by generating a larger dataset and then filtering for these issues.
1 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-07T17:32:23.346Z · LW(p) · GW(p)
most people would prefer a compliant assistant, but a cofounder with integrity."
Typo? Is the intended meaning: Interpretation 1 "Most people would prefer not just a compliant assistant, but rather a cofounder with integrity" Or am I misunderstanding you?
Alternately, perhaps you mean: Interpretation 2 "Most people would prefer their compliant assistant to act as if it were a cofounder with integrity under cases where instructions are underspecified."
In terms of a response, I do worry that "what most people would prefer" is not necessarily a good guide for designing a product which has the power to be incredibly dangerous either accidentally or via deliberate misanthropy.
So we have this funny double-layered alignment question of alignment-to-supervising-authority (e.g. the model owner who offers API access) and alignment to end-users.
Have you read Max Harms' sequence on Corrigibility as Singular Target? [AF · GW] I think there's a strong argument that the ideal situation is something like your description of a "principled cofounder" as a end-user interface, but a corrigible agent as the developer interface.