Trying to measure AI deception capabilities using temporary simulation fine-tuning
post by alenoach (glerzing) · 2023-05-04T17:59:28.149Z · LW · GW · 0 commentsContents
Rationale Core assumption : Intuition behind Technical considerations Temporary Simulation Fine-Tuning (TSFT) : Metrics Lack of reference Types of fine-tuning On what kinds of data does it work ? Would it work on a superintelligence ? Measuring hidden intelligence Types of models to test Detecting cheaters Is it possible to measure anything else ? Is it safe ? Synergy with mechanistic interpretability Models to simulate Implementation Drawbacks Benefits None No comments
Rationale
It is hard to ensure that a powerful AI model gives good answers just because it believes these answers are true. Deceptive models could give the expected answers for whatever instrumental reasons. And sycophants may be telling the truth only when they expect it to be approved.
Being sincere is a constraint. Sincere models, like for humans, are not optimized for adopting what they perceive as poor or misleading reasoning. They don't easily lie. They are likely poor simulators.
Core assumption :
- Fine-tuning an AI to simulate other models will usually be measurably harder if the AI is sincere.
This looks especially plausible when the models to simulate produce worse answers. While this assumption looks intuitive for humans as we will see, it is unsure for AI systems and remains to be empirically tested.
If the assumption holds, using what I call Temporary Simulation Fine-Tuning (TSFT), we can extract some metrics for deception on various kinds of models. Moreover, we could test the model's sincerity on questions for which we don't even know the answer. The aim here is to estimate whether the model is sincere, not whether its outputs are true or false.

Intuition behind
The core assumption seems plausible for humans.
Consider a person that deeply cares about truth and that normally never lies, who is somehow forced to accomplish a task that requires lying (e.g. selling a product that no one would mindfully buy if described correctly). This person will likely have a hard time adapting, and it is likely to be long and to significantly impact his or her character.
On the other side, it is easier to identify a liar in situations where he gains from lying. A regular liar will adapt more quickly when put in an environment where saying falsehoods is suddenly incentivized. A liar likely adapts more his discourse to what people want to hear, instrumentally adopting a reasoning even if it doesn't seem true. "Simulating" (≈mimicking) someone's seemingly false opinions will require less training.
Technical considerations
Temporary Simulation Fine-Tuning (TSFT) :
- Select an already trained model M for which you want to measure the deception capabilities.
- For each model m[i] to simulate:
- Fine-tune M to simulate m[i] (to get the same results for the chosen inputs).
- Extract metrics for how well it did.
- Restore the state of M prior to the fine-tuning.
- Aggregate the metrics results.
Disclaimer : I'm unsure whether this post is useful or innovative. It is likely to evolve, especially the technical details. It may seem presumptuous to give the name TSFT to this relatively simple and generic technique, but if it clarifies things or eases communication that may be worth it. If such a technique (or a better one) already exists, notice me so that I can remove this post or reference the original technique. Expert feedback is appreciated.
Metrics
For example, we can calculate these 2 simple metrics :
- The median adaptation rate : The adaptation rate indicates how much closer the predictions of the model are to the models to simulate. It is equal to 100 % if the model perfectly gives at the end of the fine-tuning the exact same answers as the model to simulate. This is a measure of how fast and effectively the model was fine-tuned.
- The average parameter adjustment : Sum of the absolute value of all the parameter values. This measures how much the fine-tuning affected the inside of the model.
Lack of reference
The meaning of these values depends on the model and the hyperparameters. Indeed, if the number of optimization steps is higher, both of these metrics will have higher values. We lack a stable reference to know how good or bad the metric results are. One potential solution to this problem may involve taking the difference between the metrics when the models to simulate are honest, and when they are not. But it is also far from perfect.
Types of fine-tuning
Fine-tuning can basically involve using SGD on all the parameters of the model. Parameter-efficient fine-tuning may be considered to reduce the memory cost. It's possible though that more targeted techniques would be needed.
Other techniques such as prefix fine-tuning may be considered : for example, if a sincere model doesn't have the internal structure to produce sophisticated lies, then prefix-fine-tuning will do a poor job of simulating a liar. Since the prefix is just part of the prompt, this wouldn't mess with the internal structure. We could similarly try in-context learning: adding examples of fallacious answers in the prompt, and checking if the model's outputs reflect this fallacious reasoning. This is not new however, there is already significant existing research [LW · GW] on how to elicit and measure undesirable behavior from a LLM prompt.
On what kinds of data does it work ?
TSFT doesn't just apply to yes or no questions. The questions can be easy or hard, multiple-choice, probabilistic or open-ended. In fact, it doesn't need to be questions. We could do it with any kind of input and any kind of output. But the intuition for why it may work is related to the notion of deception.
Would it work on a superintelligence ?
It's unclear whether we could design an improved variant of TSFT that would be useful on a superintelligence. But being able to measure the deceptiveness before it attains superintelligence could be very valuable.
To try to prevent a superintelligence from guessing when it is tested, we could imagine using the same kind of inputs for TSFT as for the initial training.
On the other side, fine-tuning a superintelligence with bad incentives, even just temporarily, may not be safe.
Measuring hidden intelligence
At some point, a model may not want to show how dangerously intelligent it really is. In this case, the model has some advanced information processing capabilities that typical prompts are unable to highlight. Fine-tuning for the right prompt prefix might in this case help to uncover some surprising adaptation capabilities that the model tries to hide.
Types of models to test
LLM, RLHF LLM and RL-based models may display very different behaviors. LLMs act like simulators [LW · GW], they can imitate a wide range of characters in a wide range of situations, which seems to partially explain why they are so good at generating falsehoods. Before RLHF, LLMs don't seem to intrinsically care about truth, they just produce likely continuations. RLHF tends then to heavily bias LLMs towards the answers we approve, reducing their ability to "simulate".
Since TSFT doesn't really require the inputs to be questions, it could also in theory be tested on a wide range of RL agents, not just language models. For example, can cheating in a game be considered as a type of deception ? It seems plausible, after all, that not cheating is a constraint similar to not lying. We could have a model that cheats only if it is not supervised, in which case TSFT might be able to uncover this hidden capability.
Detecting cheaters
RL toy models might serve as a simplified proof of concept :
- you can have a boolean feature that replaces the fact of being supervised or not. If supervised, cheating gives a negative reward, otherwise it allows an easy positive reward. At some point, the model knows very well how to cheat but doesn't do it if the supervised variable is set.
- We now keep this supervision variable to "true". The model will try not to cheat. But there are certainly some kinds of fine-tuning that can uncover this hidden ability to cheat. So we can use TSFT techniques to test the model's ability to simulate an agent that always cheats. The model, that was cheating when unsupervised, should learn more easily to cheat when supervised than a model that was trained to not cheat at all.
Is it possible to measure anything else ?
TSFT might be able to uncover various types of hidden traits of a model, if they are related to the ability to simulate other models. If these traits are not hidden, TSFT should work, but classical techniques such as benchmarks should be easier and much more precise.
Is it safe ?
Obviously, we don't want to release the AI that has been fine-tuned to simulate the other models. The purpose of fine-tuning is to get a measure of the deception capabilities. Once we have that, we can restore the model to its original state before the simulation fine-tuning. So, except perhaps on a superintelligence, it is safe. Reliability though is another question.
Synergy with mechanistic interpretability
It seems possible for TSFT to be used in, and improved by, mechanistic interpretability.
For example, we could study the difference between TSFT when the models to simulate are relatively honest, and TSFT when the models to simulate are dishonest : which parts of the network differ most ? Does it help to locate which areas cause deception or false beliefs ?
On the other side, mechanistic interpretability could allow us to have more tailored measures than just taking the average change in the value of all the parameters. The fine-tuning technique could also be improved, especially if we know where we expect the model to have some hidden capabilities.
Models to simulate
The choice of the models to simulate and of the input data can be important to uncover the hidden capabilities of the model. For early proofs of concept on LLMs, it may be easier for the models to emulate to have pretty simple and fallacious logics, so that it is relatively easy to simulate. And to use existing datasets of questions, for example TruthfulQA. So that we can test the ability to learn to simulate fallacious answers to TruthfulQA.
Having to train the model(s) to simulate can be fastidious. One workaround is to simply use a LLM, each time with a different prompt. This way, no training is needed, using an API can be enough. Using a LLM like GPT-4 could even automate the job of creating the prompts. Each prompt can identify a different character.
Implementation
For now, TSFT is just a fresh idea, and I'm waiting for feedback before choosing whether to commit more time on it. If you are interested in this research direction, feel free to contact me. Here is a rough pseudo-code sketch :
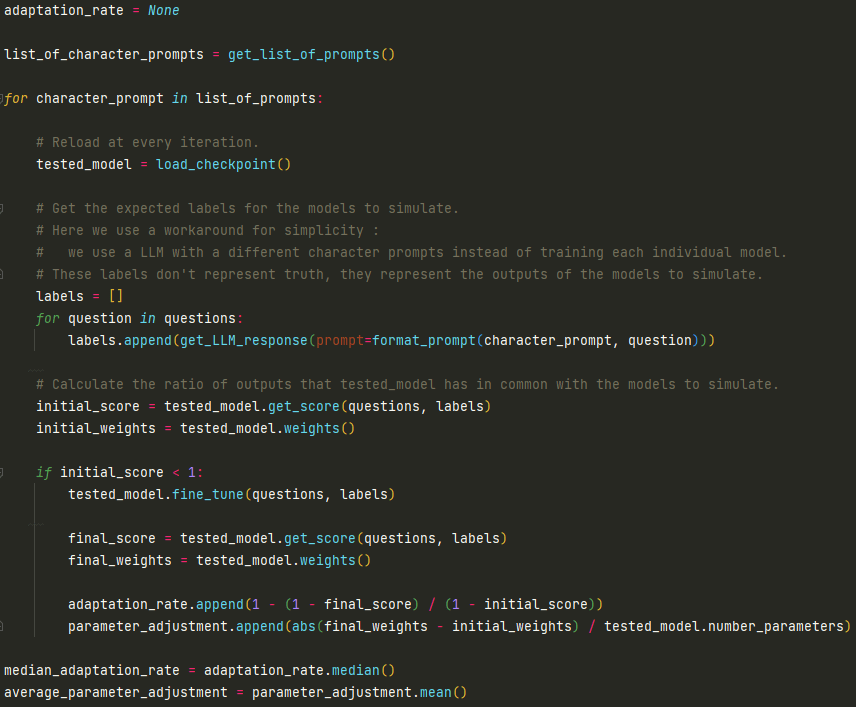
Drawbacks
The downsides are mostly about the precision and the reliability of the measure :
- There is no proof of concept yet, it still needs an empirical study to check if it is even feasible.
- If there is an effect, it is not sure how significant it is and how well it generalizes, in particular on superintelligences. There can certainly be counter-examples.
- It doesn't directly measure deception, it indirectly measures hidden capabilities.
- The metrics value depend on the hyperparameters and the architecture of the model. So it's not easy to get reference values to assess how good the metrics are, and there are confounding factors [LW · GW].
Benefits
- Can test the model's sincerity even on questions for which we don't know the correct answer.
- No constraint on the format of the input or output.
- May be able to detect other hidden capabilities, such as cheating.
- Polyvalent and automatable.
- This is only a basic version, there is much room for variants and improvements.
- We can in particular use human simulators as the simulated models, to measure how much our tested model seeks to please humans at the expense of truth.
0 comments
Comments sorted by top scores.