SGD Understood through Probability Current
post by J Bostock (Jemist) · 2021-12-19T23:26:23.455Z · LW · GW · 1 commentsContents
Gradient Variance Validation of the First Term of the Equations Validation of the Second Term of the Equations Solving for End-States What's the point? Further Investigation None 1 comment
My previous post about SGD was an intro to this model. That post concerned a model of a loss landscape on two "datapoints". In this post I attempt to build a new model of SGD and validate it, with mixed success, but it is sort of interesting.
Gradient Variance
We could model this another way. The expected change of on each step is , but we will also expect variance. will evolve over time through probability space. There are two competing "forces" here, the "spreading force" created by variance in in over all datapoints in the model, and the "descent force" being exerted by gradient descent pushing back into the centre of a given local minimum.
I think it makes sense to introduce some new notation here.
The notation should be thought of like the notation.
Plotting these for our current system:
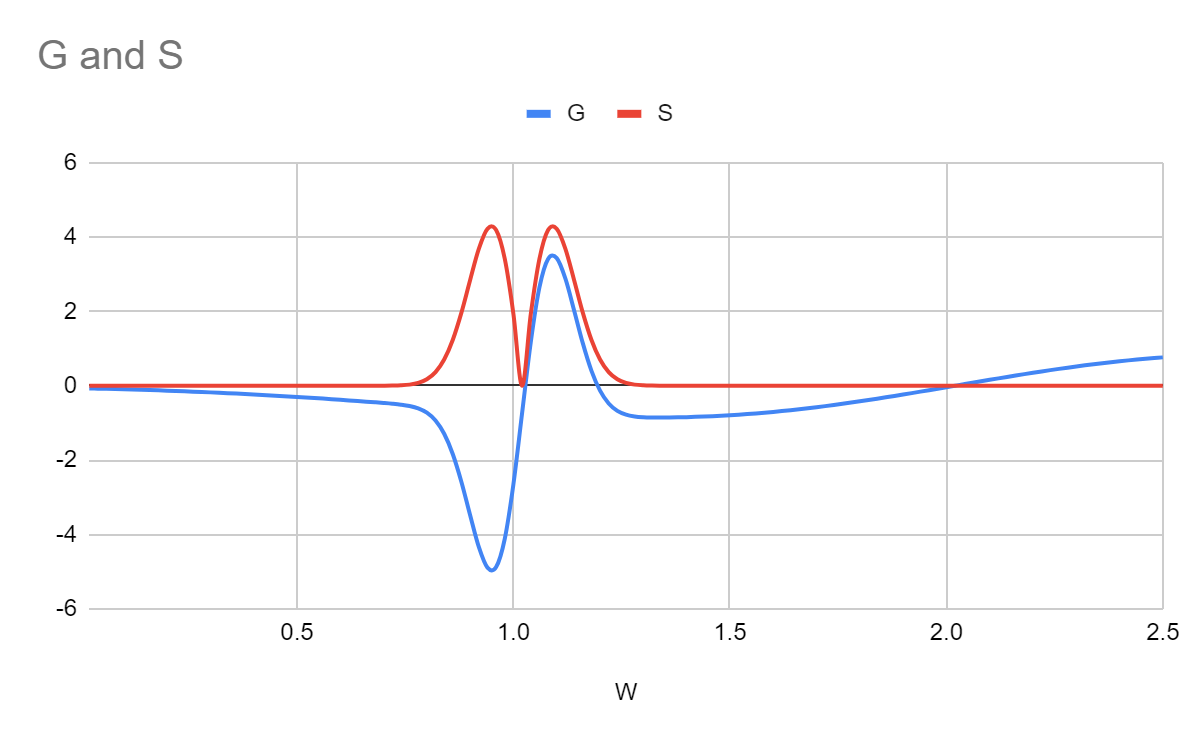
Places where is zero and the gradient of is positive are the stable equilibrium points with regards to gradient descent on (at ~1 and 2). If and are both zero at the same place, then this is an equilibrium point with regards to SGD on (only at 2). The zero points for and around the pit at 1 are not quite in the same pace.
It is possible to consider probability mass of "moving" according to the following rule:
A "point" (dirac distribution) of probability at , between and , changes to a distribution centred at with a variance of .
Now we have abstracted away from the actual process of discontinuous updates, we can try and factor out the discontinuity entirely. This will make the maths more manageable when it comes to generalizing to larger models. will likely be much smaller for larger models but as long as grows larger with the number of datapoints used, this will compensate.
(Point of notation, I will be using rather than , even though the latter is arguably more correct. As we will never be "mixing" and it won't make a difference to our results)
Instead of probability distribution moving, we might now consider it flowing. This can be described by a probability current density :
Consider a system with everywhere. The probability will just flow down the gradient:
Taking we get (when dependencies are removed for ease of reading):
Now consider a system with everywhere. Now we effectively have the evolution of a probability distribution via random walk. This gives a "spreading out" effect. With constant we have the following equation for , borrowed from the heat equation. I will take the central limit theorem and assume that the gradients are normally distributed.
Based on the fundamental solution of the heat equation this will increase our variance by each step of .
Which gives us:
But the speed of "spreading out" is proportional to which changes the equation. The slower the "spreading out", the higher the probability of being there. This makes act like a "heat capacity" of the location for for which is a conserved current. We might be able to borrow more from heat equations. In this case acts as the "temperature" of a region.
Calculating based on our previous equation gives , which gives:
This can be reduced to the rather unwieldy equation (removing function dependencies for clarity):
But these can be expressed in terms of rather than , which is good when is pathological in some way (like when is zero above, has a discontinuous derivative). It also makes sense that our equation shouldn't depend on our choosing positive rather than negative .
Finally giving our master equations:
Validation of the First Term of the Equations
Let's start with the first equation, and simulate using our G function from before.
T = 0.02, no stochasticity yet.
Here's on the y-axis, and on the x-axis. This is what the evolution of looks like for a series of initial values:
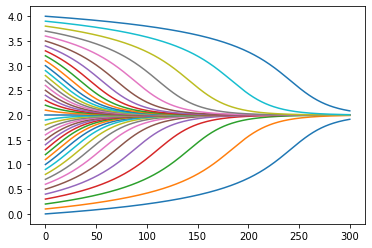
Now let's pick a couple of initial distributions and see how they evolve over time:
Time evolution with steps of :
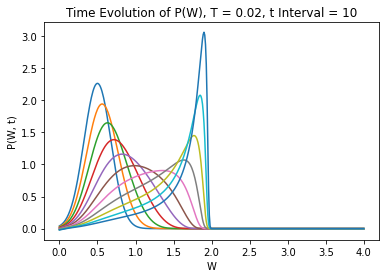
This looks about right!
Now let's plot the mean of this over time, and compare to the mean and standard deviation of a Monte Carlo simulation of gradient descent. The Monte Carlo simulation starts with 1000 values chosen to form a normal distribution with the roughly same mean and standard deviation (0.5 and 0.175 respectively) as our initial distribution.
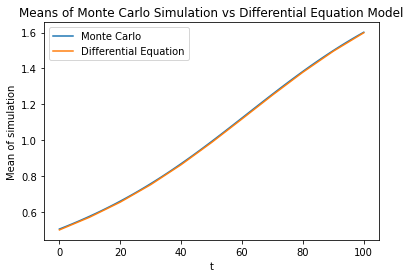
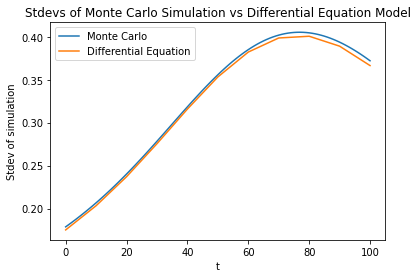
Our first equation is an accurate description of non-stochastic gradient descent. The rest of the difference in the standard deviation is most likely due to imperfect matching of our initial data ( is a truncated normal distribution but our Monte Carlo uses a normal distribution with matched mean and variance to the truncated , so some elements are where the gradient is small).
Validation of the Second Term of the Equations
Let's take our first example as a distribution spreading out.
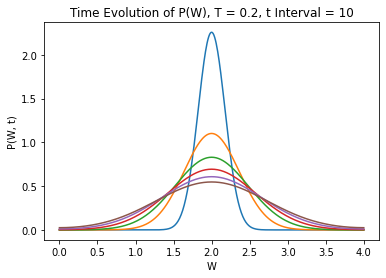
And compare standard deviations to our Monte Carlo simulation:
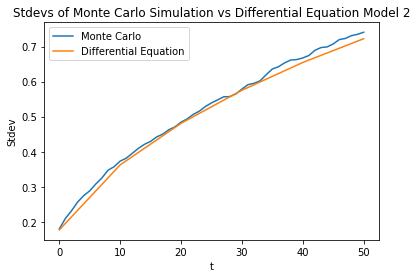
Looking good, errors here may also be due to truncation.
One final validation step: take , , , , . This model will be used to assess a few things: our ability to perform well at higher , its ability to predict the correct form of the counterbalancing "concentrating" and "spreading" forces of and , and its ability to predict the concentration of probability mass in regions of lower .
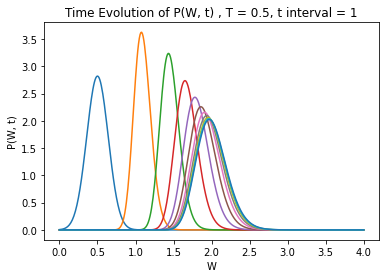
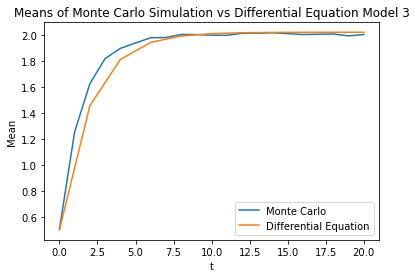
Unfortunately the computational modelling seems to fall apart when applied to the original system. The large first and second derivatives of lead to a lot of instability. This means I can't validate it much more than this. High values of also cause the model to break down, as the gradient might change a lot in the span of a step. I think this can be remedied by (for example) picking a to update on and updating with multiple small steps before changing .
I'm no master programmer and I don't have much experience working with unstable PDEs. So I can't do much more here.
Solving for End-States
For an end-state, everywhere. This means:
This shows our problem. When vanishes, our equations don't work terribly well. We might have to hope that the two opposing terms cancel out and it works, but who knows. This is probably the source of instability in our equations.
But around some minimum it lets us interpret something. If is decreasing linearly then decreases exponentially. Let's consider the term now. If we have two minima (with a maximum between them) around which the loss landscapes are exactly the same, except one is twice as wide (in all ) then the component will be halved in the wider one, but the part will be quartered. This means the integral of from the centre of the wider one to the maximum will be four times that of the narrower one. Therefore the probability density at the centre of the wider minimum's basin will be e^4 = 56 times Edit: a lot higher.
What's the point?
Reasoning about stochastic processes is difficult. Reasoning about differential equations is also difficult, but the tools to analyse differential equations are different and might be able to solve different problems.
SGD is believed to have certain "bias" towards low-entropy models of the world. Part of this is a preference for "broader" rather than "narrower" minima in . Now we have some tools which may allow us to understand this. Under this model, SGD is also biased towards regions of low variance in loss function.
Further Investigation
I think there's something like a metric acting on a space here. looks like a metric, and perhaps it's actually more correct to consider the space of with the metric such that everywhere. For higher dimensions we get the following transformations:
Now and are vectors and is a matrix. This extends nicely as we can choose our metric such that . It might be useful to define some sort of function like an "energy" over the landscape of \(\\) in terms of , , and alone which describes the final probability distribution. In fact such a function must exist assuming SGD converges, as is well-defined. What the actual form of this function is would require to do some working out, and it may not be at all easily described. This whole process is very reminiscent of both chemical dynamical modelling and finding the minimum-energy configuration of a quantum energy landscape, as both consist of a "spreading" term and an "energy" term.
While it is quite interesting, I don't consider this a research priority for myself. About 90% of this post has been sitting in my drafts for the past 3 months. Even if powerful AI is created using SGD, I'm not convinced that this sort of model will be hugely useful. It might be possible to wrangle some selection-theorem-ish-thing out of this but I don't think I'll focus on it.
1 comments
Comments sorted by top scores.
comment by jacob_cannell · 2021-12-20T19:56:19.215Z · LW(p) · GW(p)
I haven't walked through your math carefully, but I find this type of analysis interesting.
SGD is believed to have certain "bias" towards low-entropy models of the world. Part of this is a preference for "broader" rather than "narrower" minima in L. Now we have some tools which may allow us to understand this. Under this model, SGD is also biased towards regions of low variance in loss function.
This bias towards regions of low variance makes intuitive sense.
SGD's bias towards low-entropy models also has a simple explanation - good inits start it in a low entropy config, and SGD moves in an entropy efficient direction of maximizing loss decrease per unit weight change, which biases it strongly towards staying near the low entropy init. This becomes quite noticeable when you experiment with 2nd order optimizers which generally don't have this bias - they tend to overfit far more easily and need more explicit regularization.