Transformer Attention’s High School Math Mistake
post by Max Ma (max-ma) · 2025-03-22T00:16:34.082Z · LW · GW · 1 commentsContents
Reference None 1 comment
Each data point (input data, weights & bias) of a neural network has coordinates. Data alone, without coordinates, is almost meaningless. When attention mechanisms (Q, K, and V) undergo a linear transformation, they are projected into a different space with new coordinates. The attention score is then computed based on the distance between Q and K after transformation. However, this transformed distance does not necessarily reflect the true, original distance between the data points.
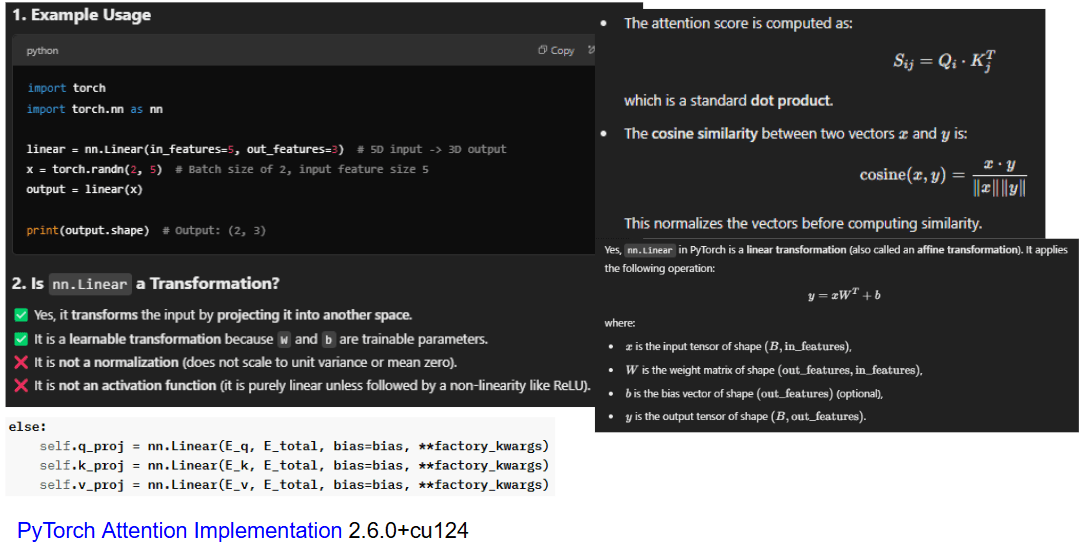
Each of Q, K, and V undergoes its own linear transformation with different weights, meaning they are projected into distinct spaces with different coordinate systems. As a result, the transformed values of Q and K may become closer or farther apart compared to their original positions. The distance computed via cosine similarity does not accurately represent their true, original distance. This is a fundamental mathematical oversight.
However, attention is still very powerful. Two critical aspects of attention, which makes Transformer so powerful, remain unrecognized by the AI community. This discovery is part of Deep Manifold development.
Reference
Q/A with ChatGPT 4o






1 comments
Comments sorted by top scores.
comment by Max Ma (max-ma) · 2025-03-23T23:05:58.429Z · LW(p) · GW(p)
DeepSeek V3 mitigated this mistake unknowingly. In their MLA, K, V shares the same nn.linear.