Intrinsic Dimension of Prompts in LLMs
post by Karthik Viswanathan (vkarthik095) · 2025-02-14T19:02:49.464Z · LW · GW · 0 commentsContents
Introduction Method Dataset Shuffle Experiment Correlation of ID to Surprisal Correlation of ID to Latent Prediction Entropy Conclusion None No comments
My paper recently came out on arXiv which I briefly summarize here. The code for the paper can be found on GitHub.
TLDR: We investigate the relation between the intrinsic dimension of prompts and the statistical properties of next token prediction in pre-trained transformer models. To qualitatively understand what intrinsic dimension measures, we explore how semantic content impacts it by shuffling prompts to various degrees. Our findings reveal a correlation between the geometric properties of token embeddings and the cross-entropy loss (or surprisal) of next token predictions, implying that prompts with higher loss values have tokens represented in higher-dimensional spaces.
Introduction
In the context of interpretability of transformer models, some analytic approaches have been developed to model transformer architectures as dynamical systems of particles. In this perspective, transformers are viewed as evolving a mean-field interacting particle system where the distribution of tokens encodes the probability distribution of the next token predictions and controls the evolution of tokens across layers. This analytical framework motivates the study of the geometry of tokens within a prompt and their evolution across the layers of a transformer model.
A complementary perspective to the evolution of token representations across layers can be gained by studying the latent predictions of transformer models. Since the latent predictions (logit lens [LW · GW], tuned lens) are obtained by unembedding the residual stream, and our method probes the geometric properties of the residual stream, we can expect the statistical properties (e.g. entropy) of the latent prediction probabilities to be encoded in the geometry of the internal representations of the tokens.
In this blog, we check how the intrinsic dimension (ID) of prompts changes across layers of transformer models and understand what it measures. To understand its qualitative aspects, we experiment by shuffling a prompt to various extents and observing the resulting changes in its intrinsic dimension. On the quantitative side, we uncover a correlation between the ID of prompts and the surprisal of the next token predictions - suggesting that tokens with higher surprisal tend to be represented in higher-dimensional spaces. Finally, we analyze the correlation between the intrinsic dimension of the internal representations and the entropy of the latent predictions for different models.
Extensive work has been done in studying the intrinsic dimension of last-token representations across a corpus in LLMs which motivates the use of intrinsic dimension as an observable to understand the geometry of tokens within a prompt. While the intrinsic dimension of last-token representations reflects the semantic content of the data, the intrinsic dimension of tokens within a prompt captures the semantic correlations among them.
Method
We analyze the geometry of tokens in the hidden layers of large language models using intrinsic dimension (ID) and study its relation to the surprisal of the next token prediction and entropy of the latent predictions obtained from TunedLens. Given a prompt, we extract the internal representations of the tokens using the hidden states variable from the Transformers library on Hugging Face. We calculate the intrinsic dimension for each hidden layer by considering the point cloud formed by the token representation at that layer. On this point cloud, we calculate the intrinsic dimension (ID). Specifically, we use the Generalized Ratio Intrinsic Dimension Estimator (GRIDE) to estimate the intrinsic dimension implemented using the DADApy library.
Dataset
We use the prompts from Pile-10K selecting only those with at least 1024 tokens, resulting in 2244 prompts after filtering. and compute the intrinsic dimension on the first 1024 tokens for each of the prompts.
Shuffle Experiment
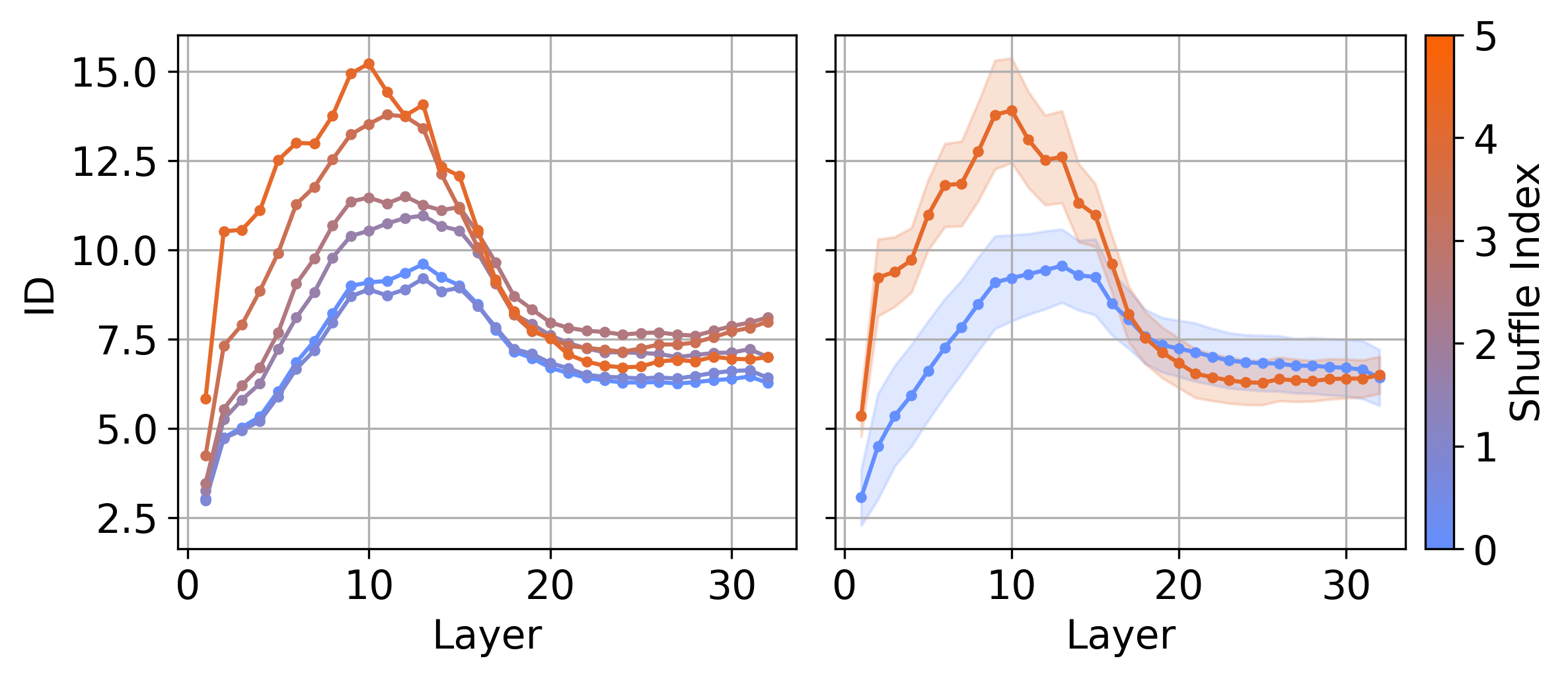
The left panel shows the ID profile of a single prompt at various levels of shuffling, while the right panel presents the average ID across 2244 prompts for both fully shuffled and structured cases for the Llama-3-8B model. A larger shuffle index indicates a higher degree of shuffling. In all scenarios, we observe a peak in ID in the early to middle layers. Additionally, the height of this peak increases with the degree of shuffling, indicating a relation between the two. This experiment also serves to distinguish the geometry of last-token representations and tokens within a prompt since the shuffling results in a lower intrinsic dimension for last-token representations as shown in this paper.
Correlation of ID to Surprisal
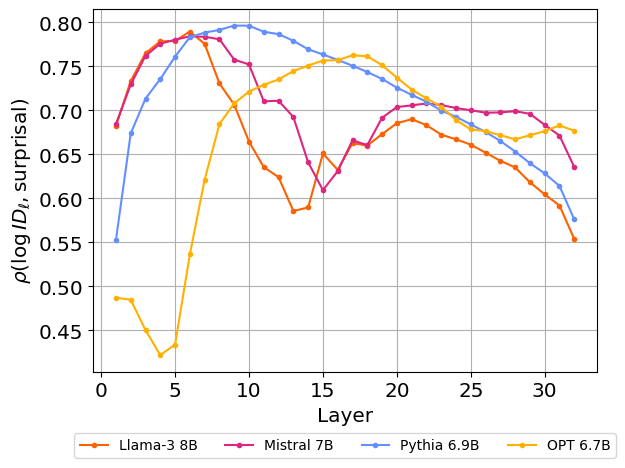
We compute the Pearson coefficient among the 2244 prompts between the average surprisal and the logarithm of intrinsic dimension as a function of layers for different models. Here the average surprisal refers to the cross-entropy loss of the next token averaged across the tokens within a prompt.
All four models have a high positive correlation across the layers of the model, implying that prompts with a higher average surprisal have a higher intrinsic dimension. This observation is qualitatively consistent with the shuffling experiment since the shuffled data is expected to have a higher surprisal and hence a higher intrinsic dimension. Notably, this correlation exists in the early layers even though the surprisal is calculated after the final layer.
Correlation of ID to Latent Prediction Entropy
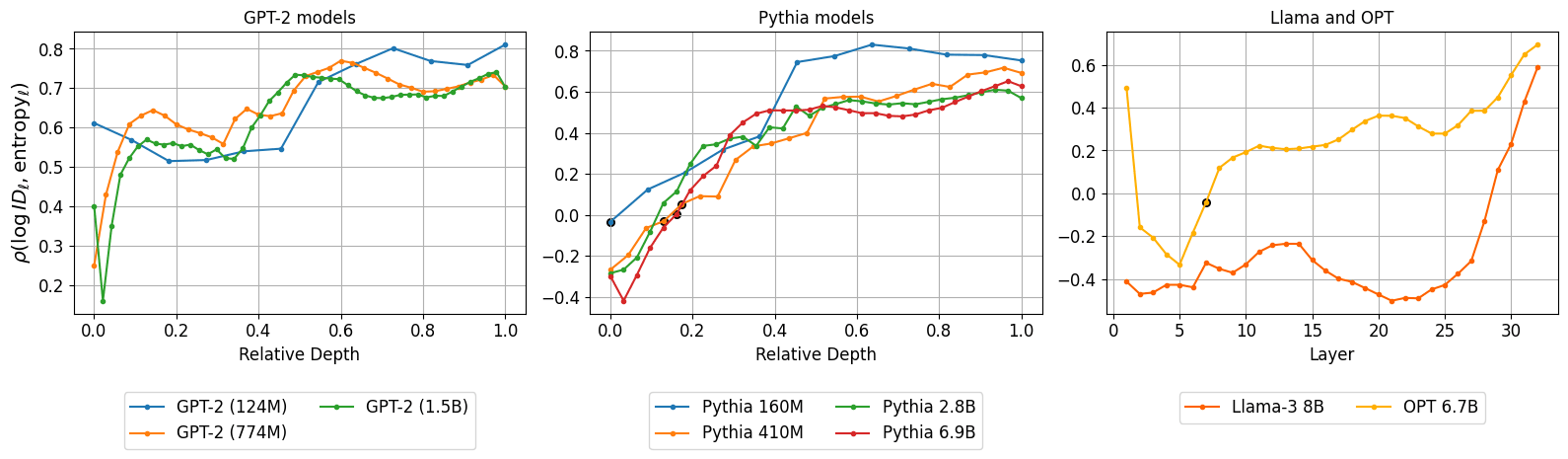
We summarize the results for the correlation of ID to latent prediction entropy obtained from TunedLens -
- GPT-2 models (left panel): There is a notable positive correlation ρ > 0.5 between the two quantities from the early layers onwards. This implies that the prompts that have a high dimensional representation tend to have a higher latent prediction entropy.
- PYTHIA models (middle panel): In this case, we observe a positive correlation ρ > 0.5 from the middle layer onwards. There is a similar trend in the correlation across different model sizes.
- LLAMA and OPT (right panel): In these models, we do not see a positive correlation until the late layers. In LLAMA, we see a moderate negative correlation (ρ ∼ −0.5) around layer 20. In the GPT-2 and PYTHIA models, we notice a positive correlation from the middle layers onwards according to our expectations. However, the negative correlation found in LLAMA requires further understanding, which we leave for future work.
The analysis in this section motivates the use of intrinsic dimension, obtained at the level of hidden states, as a regularization component when training translators. This could help achieve specific statistical properties in latent predictions, such as maintaining a positive correlation between entropy and intrinsic dimension.
Conclusion
We find a correlation between the ID of internal representations to the surprisal of a prompt implying that prompts with higher loss values have tokens represented in higher-dimensional spaces. We examine the relation between ID and the latent prediction entropies and find a notable positive correlation in GPT-2 and PYTHIA models confirming the intuition that prompts that have a higher latent prediction entropy are represented in higher dimensional spaces. This suggests that the intrinsic dimension can serve as a measure of the complexity of a prompt.
0 comments
Comments sorted by top scores.