Trust status sigmoidally
post by DirectedEvolution (AllAmericanBreakfast) · 2021-03-20T19:50:21.567Z · LW · GW · 2 commentsContents
2 comments

Status, at its finest, makes it easy to find out who the crowd believes is the most skilled, experienced, and capable. It helps us know who we should follow, collaborate with, bet on.
As a proxy metric, it's vulnerable to Goodhart's law and hacking. Sometimes we can detect and fix these issues; other times we can't.
One of the most obvious and pervasive status markers on social media is upvotes.
I just got an RSS service (Feedly), and it helped me find a lot of blogs I wouldn't have otherwise discovered. Yay, abundance! I merrily subscribed. But how to choose from among them? And without a second thought, I picked out the ones with over 100 followers, because that's a big-looking number.
And if upvotes are a good proxy for the wisdom of a crowd, that's actually not a bad strategy.
But whether that's true or not is an open question. I think it's wise to start by assuming they're not. The way that evolved embodied culture functions as a good proxy for status is complex. How likely is it that some random RSS service that's just trying to get users is going to replicate it?
I think that the utility of an upvote button as a proxy for status is probably best evaluated in specific circumstances, by specific people. After a couple years on LessWrong, I've developed a sense both globally and for some specific users about how much their upvote count (and time since posting) makes me want to read/trust their article. In that sense, an upvote feature is context-dependent and an investment.
But if you're using a new platform (i.e. Feedly), to look at new people/communities (i.e. blogs also followed by people who follow LessWrong), and you're doing that for the first time, the number of follows is extremely difficult to interpret, to the point you're best off interpreting it as noise.
The key lesson is that it takes a lot of time and energy to learn how to extract skill-signal from the noisiness of a particular platform or community's status markers. It's an investment. I think this is what's going on when you're at a party with a bunch of new people and come away from it feeling bewildered and exhausted. It's like being at a loud rock concert, but it's status-noise that your brain has been desperately trying to make sense of for a couple of hours. Sometimes, some people are able to switch that off (I think I've gotten better at this over the years), but other times it's just impossible.
It seems like a bad bind if you're stuck choosing between either ignoring the noisy signal, so that you never gain skill in interpreting it; or in paying attention to the noisy signal, which is exhausting and can lead to a lot of initial mistakes.
To be constructive, it seems useful to figure out ways to learn to interpret status cues more quickly and easily in novel contexts. This in theory should let you tap into and contribute to the hive mind more effectively.
But it might also be that you're best served by ignoring status completely, and just focusing on object-level stuff. In written material, is the writing clear, the thinking cogent? In human relations, do you enjoy the people? In the marketplace, do you like the taste of the food, the look of the house, the color and smell of the flowers?
The more object-level assessment you do, the more you focus on it, totally disregarding status-signals to the best of your (probably limited) ability, the more skill you gain. And having skill lets you evaluate skill. And this in turn, perhaps, lets you identify or intuit actually-useful status proxy metrics for skill.
Hence, when you're faced with a novel context, a novel metric for status, the very first thing you'd want to do is identify that status-noise you're glomming onto, and deliberately ignore it. In my case, I need to deliberately follow blogs with few followers, and apply extra scrutiny to the popular ones.
For apparently low-status blogs, they're either low-status because they're bad, or because they're unfairly neglected or niche. If it's because they're bad, you won't be tricked into thinking they're actually good by their status; it'll be extra easy to detect. If they're low-status because they're neglected/niche, then you play an important role in correcting this deficiency by reading them.
And the reverse is true for apparently high-status blogs. First, if their badness is masked by their high status, deliberately ignoring it will help you notice the badness. Likewise, if you ignore the blog because it's high-status, but it's actually a really good blog, it seems likely to me that the "wisdom of the crowd," i.e. the references and links you encounter in your other reading, will eventually lead you to it.
I think there's probably a middle ground here where this model is most true, but that if you take it too far, or not far enough, you either get totally sucked into status-jockeying, or else you wind up in nowhere-land, reading the ramblings of isolated individuals who are just totally out of touch.
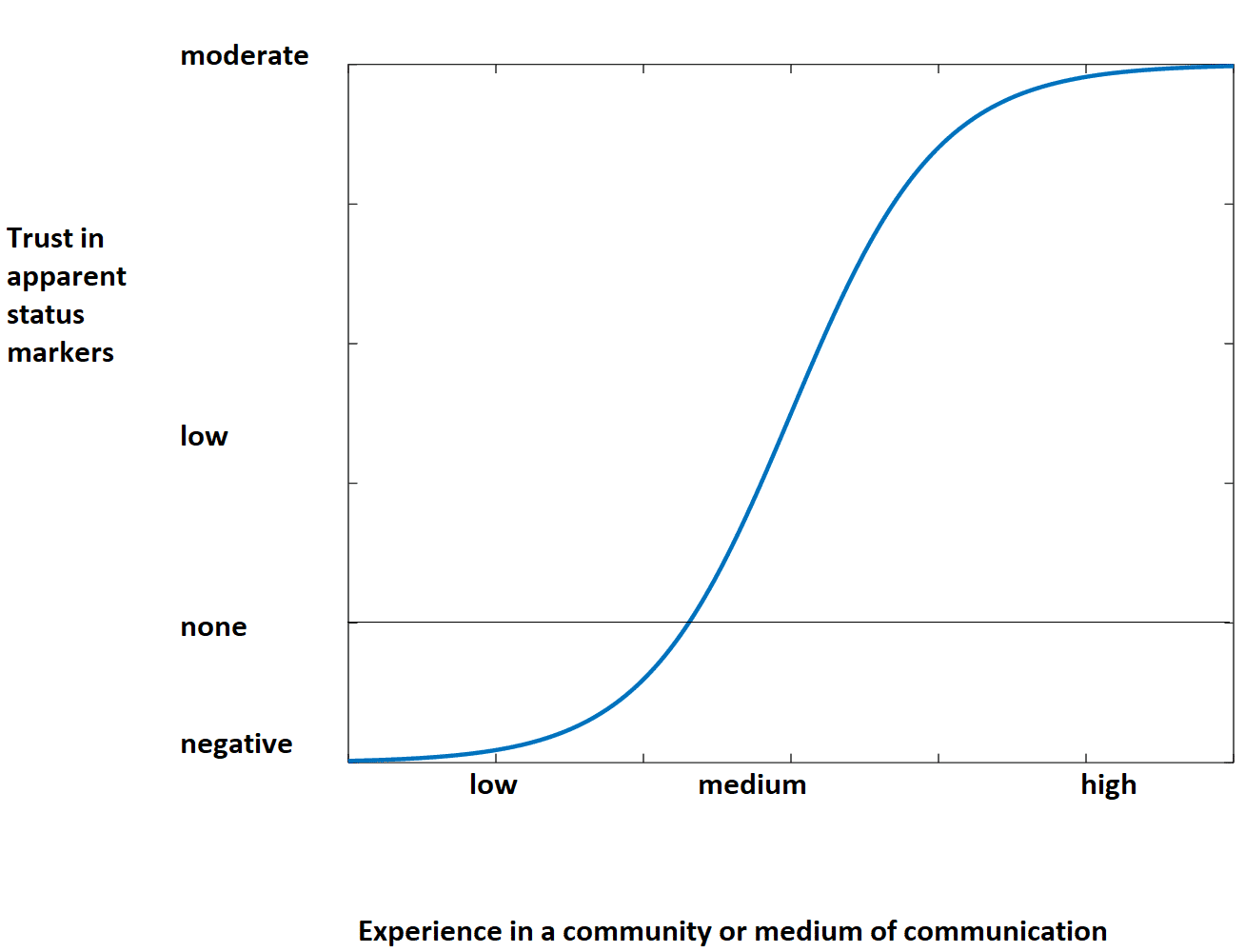
The most specific way I can state this heuristic is:
When you're new to a community or medium of communication, try to ignore, or even invert, any apparent status markers until you've had a chance to get quite a bit of concrete experience. The weight you give to status should be sigmoidal over time.
2 comments
Comments sorted by top scores.
comment by knite · 2021-03-20T20:11:55.512Z · LW(p) · GW(p)
Two thoughts.
First, it wasn't immediately clear that you meant within a range of [-1, 1], perhaps adding that to the graphic would help?
Second, this sounds like it generalizes as "trust your own opinion on any topic sigmoidally, scaling with your personal knowledge of it" - in other words, actively notice and reject your initial bias, until you have enough background to be truly informed, at which point you should trust your own judgment.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2021-03-20T20:27:28.590Z · LW(p) · GW(p)
Thanks, I tried putting rough axis labels on it to get at the point better. The point goes one step beyond, to say that once you can trust your own object-level judgment, you can also better trust your own proxy-level judgment.
For example, if you're a great programmer, you know good code when you see it. Because of that, you know good programmers, and so when they tell you that Jackie is a good programmer, you trust them. That means you no longer have to scrutinize Jackie's code in order to know whether or not to hire her onto your team.
But if you're just starting out, and don't know how to judge code, then you should actively ignore it when people try to tell you that so-and-so is a good programmer. Such claims abound, and how will you know which to accept and which to ignore? They're a distraction at best, and at worst you'll be uniquely vulnerable to status-gamers.