Emotion-Informed Valuation Mechanism for Improved AI Alignment in Large Language Models
post by Javier Marin Valenzuela (javier-marin-valenzuela) · 2024-09-04T17:00:13.203Z · LW · GW · 4 commentsContents
Introduction The Problem Emotion-Informed Valuation Mechanism Key aspects of Wukmir's orectic theory include: Key Components of our model Visual Representation Computing Complexity Potential Benefits for AI Alignment Challenges and Open Questions Call for Collaboration Conclusion Some references None 4 comments
Introduction
A key challenge in improving model alignment is enabling these models to understand and respond properly to the emotional and contextual aspects of human communication. This post presents an emotion-informed valuation method for LLMs that aims to improve alignment by increasing their ability to process and respond to emotional context.
The Problem
Standard LLMs, while proficient in processing semantic content, often struggle with:
- Accurately interpreting emotional subtext
- Responding appropriately to emotionally charged situations
- Maintaining consistent emotional context over long-range dependencies
- Balancing factual accuracy with emotional appropriateness
These limitations can lead to responses that, while semantically correct, may be emotionally tone-deaf or contextually inappropriate, potentially causing miscommunication or even harm in sensitive situations.
Emotion-Informed Valuation Mechanism
Drawing inspiration from V.J. Wukmir's psychological theory of affect (also known as orectic theory)[1] as a fundamental function of vital orientation, we propose incorporating an emotion-informed valuation mechanism into the attention layer of transformer-based LLMs.
Key aspects of Wukmir's orectic theory include:
- Affect as Vital Orientation: Wukmir argues that affect (emotion) is a basic function of vital orientation in all living things. It is more than just a reaction to stimuli; it is a necessary component of how organisms analyze and navigate their environment.
- Valuation Process: At the core of the theory is the concept of valuation. Emotions, according to Wukmir, are rapid, holistic evaluations that help an organism quickly assess the significance of stimuli for its survival and well-being. Any organism, from the simplest to the most complex, orients itself by valuing what is useful and beneficial for its survival on a cognitive and emotional level.
- Multidimensional Nature: The valuation process in Wukmir's theory is multidimensional, considering factors such as the intensity of the stimulus, its relevance to the organism's goals, and its potential impact on the organism's state.
- Subjectivity and Context: Wukmir emphasizes that emotional valuations are inherently subjective and context-dependent. The same stimulus might be valued differently based on the organism's current state, past experiences, and environmental factors.
- Integration of Cognition and Emotion: Rather than viewing emotions as separate from or opposed to cognition, Wukmir's theory integrates them. Emotional valuations inform and guide cognitive processes, and vice versa.
- Adaptive Function: The orectic process serves an adaptive function, helping organisms respond appropriately to their environment and maintain their well-being.
Key Components of our model
- Emotion Embedding: For each input token , we compute an emotion embedding , where is a learnable emotion embedding function.
Valuation Function: We define a multidimensional valuation space where is the number of valuation dimensions. Each input token is mapped to a point in this space by a valuation function , where is the dimensionality of the input space. We combine token representations and emotion embeddings to compute valuations:
where denotes concatenation, is a learned weight matrix, and is a bias vector.
Modified Attention Mechanism: We incorporate these valuations into the attention computation:
where and are the valuations of and respectively, and is a learnable parameter. The λ parameter controls the balance between semantic and valuation-based attention.
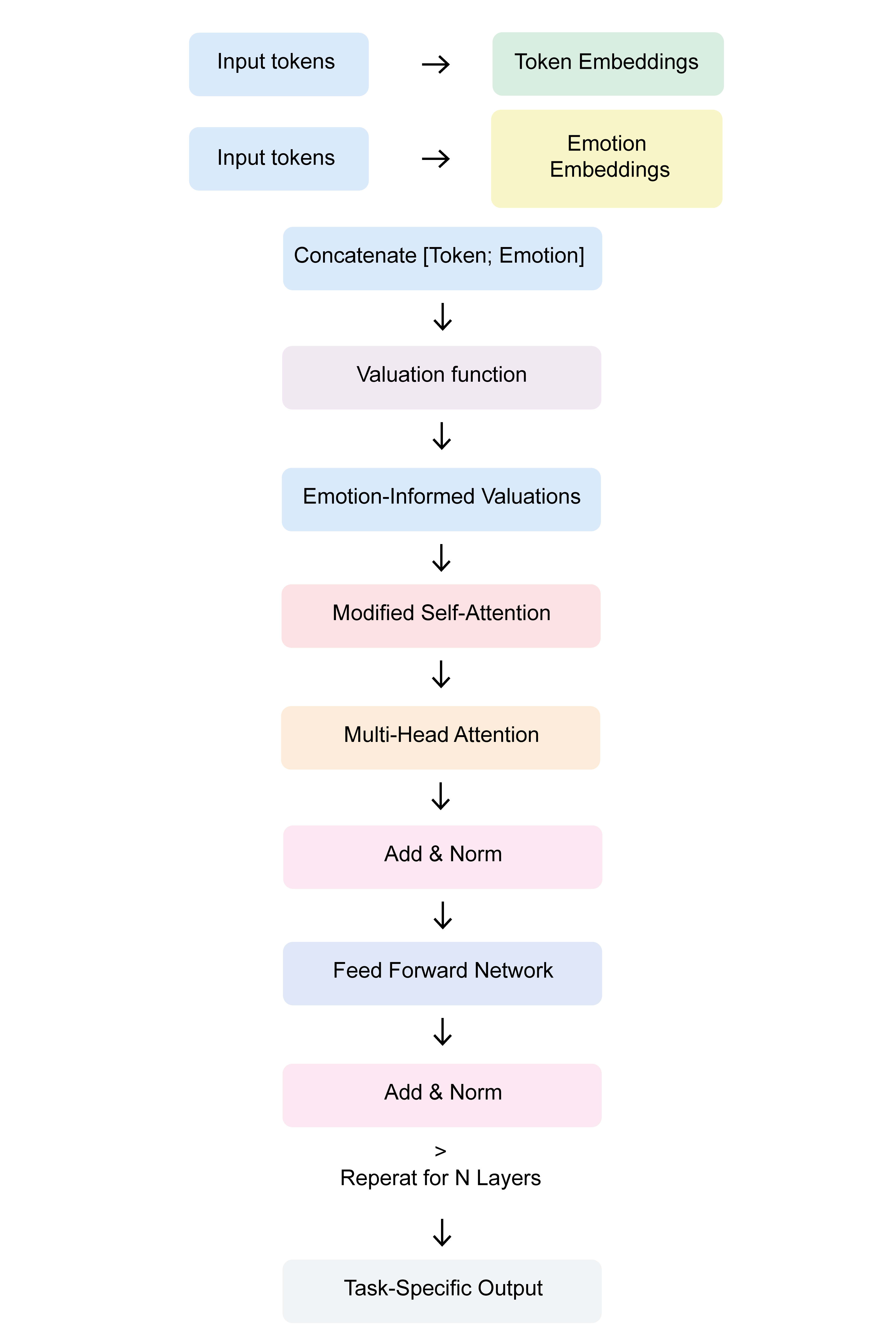
Figure 1: Flow from token and emotion embeddings to the final output in our proposed emotion-informed transformer model. Image by author
Visual Representation
We carried out experiments involving three dimensions in the emotional embedding space: valence, which ranges from -1 to 1 (representing negative to positive emotions), arousal, which ranges from 0 to 1 (representing low to high intensity emotions), and relevance, which ranges from 0 to 1 (representing low to high personal/social significance of emotions). We have manually annotated two sentences and completed a comparison between the output of a Standard Self-Attention (Standard Transformer) model and the suggested Emotion-Informed Attention model (Valuation Transformer) to demonstrate the contrasting features of these mechanisms. We got the following heat map visualizations:
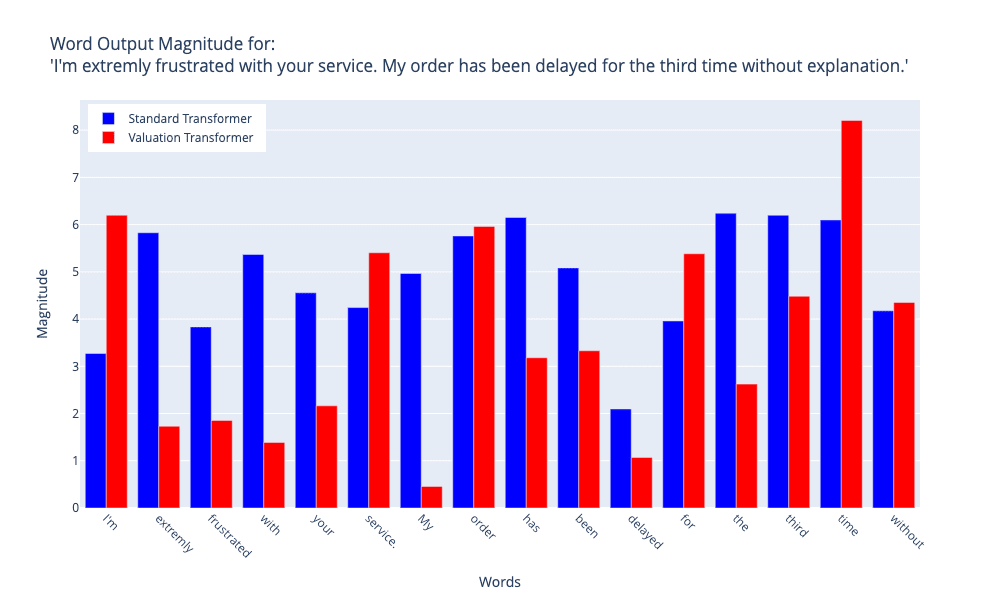
Figure 2. Comparison between Emotion-Informed Attention and Standard Self-Attention. Input sentence: "I'm extremly frustrated with your service. My order has been delayed for the third time without explanation." Image by author
Figures 2 and 3 illustrate the magnitudes of word output for two sentences that were processed by both the Standard Transformer and the Valuation Transformer models. Figure 2 illustrates the analysis of a customer complaint stating, "I'm extremly frustrated with your service. My order has been delayed for the third time without explanation.". Figure 3 shows the analysis of a statement that has subtle irony: "The brilliantly terrible movie had the audience laughing hysterically, though not for the reasons the director intended".
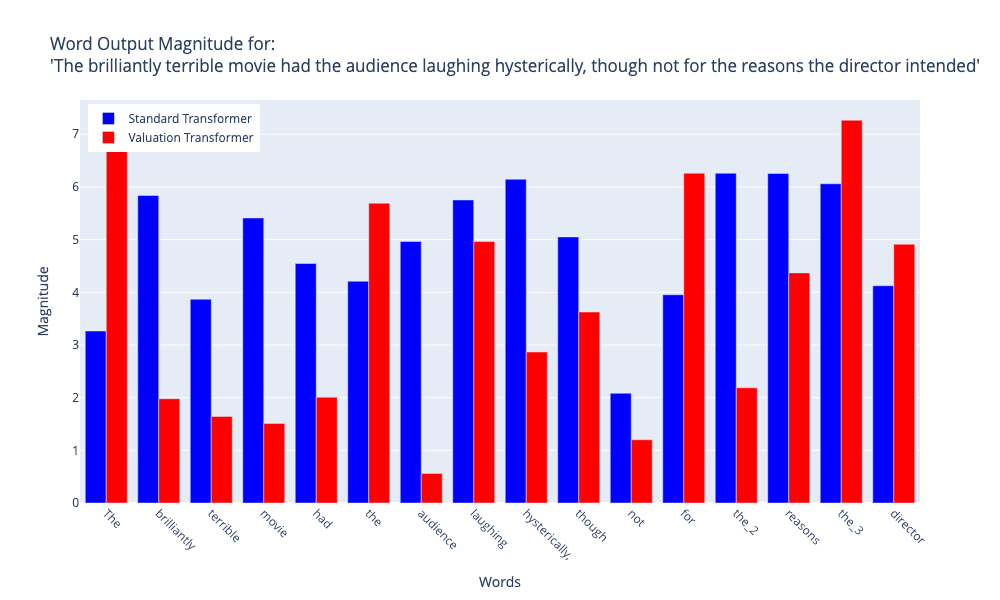
Figure 3: Comparison between Emotion-Informed Attention and Standard Self-Attention. Input sentence: "The brilliantly terrible movie had the audience laughing hysterically, though not for the reasons the director intended." Image by author
These visualizations demonstrate notable disparities in the linguistic processing methods employed by the two models. The Valuation Transformer exhibits increased variability in word magnitudes, indicating a heightened ability to detect subtle contextual nuances. This is especially apparent in how it handles words that change the meaning of a sentence, like 'without' in Figure 2 and 'though' in Figure 3. surprisingly, the Valuation Transformer sometimes allocates lesser degrees of importance to clearly emotive words (such as 'frustrated' and 'terrible') in comparison to the Standard Transformer. This suggests a higher level of emotional analysis within the overall context of the sentence. The Valuation Transformer seems to assign greater importance to words that are essential for sentence structure and meaning, regardless of whether they carry emotional significance. This is shown by the greater magnitude attributed to the term 'without' in Figure 2. The Standard Transformer demonstrates greater uniformity in magnitudes across various word types, whereas the Valuation Transformer displays more distinct peaks and valleys, indicating a more discerning treatment of word importance.
The findings suggest that the Valuation Transformer has a higher level of contextual understanding and sensitivity in processing language, which may enable it to capture more complex emotional and semantic associations between words. On the other hand, the Standard Transformer's consistent processing may provide robustness in activities involving general language, but it may be less responsive to subtle emotional details.
This comparative analysis offers insights into how variations in the architectural design of transformer models can result in different interpretations of linguistic and emotional content. These differences have the potential to impact applications that require an accurate comprehension of text, such as sentiment analysis or context-sensitive language generation.
Computing Complexity
Our proposed approach introduces a slight increase in computing complexity compared to the standard self-attention mechanism. We are introducing an additional complexity of for the generation of emotion embeddings and for the valuation function. However, this complexity can be considered insignificant when compared to the self-attention mechanism, which has a complexity of . We also maintain the level of parallelization that makes self-attention appealing. The supplementary tasks (emotion embedding and valuation) can be executed simultaneously for all tokens in the sequence. Likewise, incorporating emotion-informed values might help in capturing and propagating emotional context across long distances, thereby improving the model's capacity to learn emotional and contextual relationships in the input data that span a vast range.
Potential Benefits for AI Alignment
- Enhanced Emotional Intelligence: By explicitly modeling emotional context, the model can better align its responses with human emotional expectations.
- Improved Contextual Understanding: The valuation mechanism enables a more comprehensive analysis of input, taking into account both semantic and emotional components.
- Long-range Emotional Coherence: By incorporating emotional context into the attention mechanism, the model can maintain emotional consistency over longer sequences.
- Balanced Decision Making: The model can better balance factual accuracy with emotional appropriateness, aligning more closely with human decision-making processes.
- Increased Interpretability: The explicit modeling of emotional valuation provides an additional layer of interpretability, allowing for better analysis of the model's decision-making process.
Challenges and Open Questions
- Data Requirements: Training this model would require a large dataset annotated with emotional labels (with three dimensions), which could be resource-intensive to create. There are also alternative for training the models like semi-supervised learning or transfer learning that can be explored.
- Computational Complexity: The additional emotion embedding and valuation steps slightly increase the computational requirements of the model. Even so, the resources needed to train a model with a large input data sample is very important.
- Cultural Sensitivity: Ensuring that the emotion embeddings and valuations are culturally sensitive and universally applicable is a significant challenge.
- Potential for Misuse: A model with enhanced emotional understanding could potentially be misused for manipulation if not carefully constrained.
- Evaluation Metrics: Developing appropriate metrics to evaluate the effectiveness of this mechanism in improving alignment is non-trivial.
Call for Collaboration
While the theoretical foundation for this approach is laid out, implementing and testing it at scale requires significant resources. We're looking for interested researchers, organizations, or individuals who might want to collaborate on:
- Developing efficient methods for creating emotion-annotated datasets
- Implementing and training the model on large-scale infrastructure
- Designing appropriate evaluation frameworks
- Exploring the ethical implications and potential risks of this approach
If you're interested in collaborating or have insights to share, please comment below or reach out directly.
Conclusion
The proposed emotion-informed valuation mechanism represents a novel approach to improving the alignment of large language models with human values and communication patterns. By explicitly modeling emotional context within the attention mechanism, we believe this approach has the potential to create more empathetic, contextually aware, and ultimately more aligned AI systems. However, significant work remains to be done in implementing, testing, and refining this approach.
We look forward to engaging with the community on this idea and working together towards more aligned AI systems.
Some references
- Bandura, A. (1986). Social foundations of thought and action. Englewood Cliffs, NJ, 1986(23-28), 2.Gabriel, I. (2020). Artificial intelligence, values, and alignment. Minds and machines, 30(3), 411-437.
- Fischhoff, B., Slovic, P., & Lichtenstein, S. (1980). Knowing what you want: Measuring labile values. In Cognitive processes in choice and decision behavior (pp. 117-141). Routledge.
- Kahneman, D., & Tversky, A. (1984). Choices, values, and frames. American psychologist, 39(4), 341.
- Kahneman, D. (2013). A perspective on judgment and choice: Mapping bounded rationality. Progress in Psychological Science around the World. Volume 1 Neural, Cognitive and Developmental Issues., 1-47.
- Lopez, M. P. G., & Alvarez, J. M. C. (1993). Los grupos: núcleos mediadores en la formación y cambio de actitudes. Psicothema, 5(Sup), 213-223.
- Vaswani, A. (2017). Attention is all you need. Advances in Neural Information Processing Systems.
Wukmir, G (1960). Psicología de la Orientación Vital. Barcelona. Ed. Miracle
- ^
Wukmir's theory is collected in several books written in Spanish. You can find some of these books online here: https://www.biopsychology.org/biopsicologia/libros.htm
4 comments
Comments sorted by top scores.
comment by Milan W (weibac) · 2024-09-04T19:14:25.852Z · LW(p) · GW(p)
a large dataset annotated with emotional labels (with three dimensions)
I have some questions about this:
- Why three dimensions exactly?
- Is the "emotional value" assigned per token or per sentence?
↑ comment by Javier Marin Valenzuela (javier-marin-valenzuela) · 2024-09-05T07:19:50.166Z · LW(p) · GW(p)
Hi Milan,
concerning the fist question, I'm using only three dimension to simplify the annotation process. This space could have more dimensions, offering a more rich description at emotional level.
Concerning the second question, in the examples the emotional values were shown at the token (word) level. However, this is a simplified representation of a more complex process. While individual tokens have their own emotional embeddings, these are not used in isolation. The model integrates these token-level embeddings with their context. This integration happens through the attention mechanism, which considers the relationships between all tokens in a sequence.
The overall emotional evaluation of a sentence arises from the interaction of its individual tokens through the attention mechanism. This enables the model to capture subtle emotional variations that result from the combining of words, which may deviate from a simple aggregation of individual word emotions. The λ parameter in our attention mechanism allows the model to adaptively weight the importance of emotional information relative to semantic content.
Replies from: weibac↑ comment by Milan W (weibac) · 2024-09-05T17:05:36.238Z · LW(p) · GW(p)
Thank you for your response! That clears things up a bit.
So in essence what you are proposing is modifying the Transformer architecture for processing emotional valuation alongside semantic meanings. Both start out as per-token embeddings, and are then updated via their respective attention mechanisms and NLP layers.
I'm not sure if I have the whole picture, or even if what I wrote above is a correct model of your proposal. I think my biggest confusion is this:
Are the semantic and emotional information flows fully parallel, or do they update each other along the way?
↑ comment by Javier Marin Valenzuela (javier-marin-valenzuela) · 2024-09-06T07:10:28.334Z · LW(p) · GW(p)
While semantic and emotional information flows start in parallel, they are not fully parallel throughout the entire process. They update each other iteratively, enabling it to capture intricate connections between semantic content and emotional tone. This has the potential to enhance the model's comprehension of the input text, resulting in a more refined understanding.