Do Antidepressants work? (First Take)
post by Jacob Goldsmith (jacgoldsm) · 2025-01-12T17:11:55.417Z · LW · GW · 9 commentsContents
How is depression measured? What does it mean for antidepressants to work? What do these studies find? What does BCH find? How do you reconcile this? Simulation Conclusion References None 9 comments
I've been researching the controversy over whether antidepressants truly work or whether they are not superior to a placebo. The latter possibility really contains two possibilities itself: either placebos are effective at treating depression, or the placebo effect reflects mean reversion. Here, the term "antidepressant" refers to drugs classified as SSRIs and SNRIs.
Some stylized facts from the literature of RCTs:
- Both antidepressants and placebos are associated with a reduction in symptoms of depression
- Antidepressants are associated with a larger reduction in depressive symptoms than placebos
- This difference in efficacy is attenuated when "enhanced" placebos are used, that is placebos that are designed to provoke side effects to persuade the subject that they are being treated with a real medication
- Studies on antidepressants broadly measure either an average treatment effect according to some continuous scale or a binary treatment according to a cutoff for success/failure of treatment (or both). Universally, if you looked only at the former measure you would conclude that the effect of antidepressants on depression is clinically insignificant, while if you looked only at the latter measure you would come to a more favorable conclusion.
How is depression measured?
Most studies of antidepressant efficacy use the Hamilton Depression Rating Scale (HDRS) to measure changes in depressive symptoms from the baseline, although entrance into the clinical trials themselves is often not based on this measure. There are several versions of this scale, but the most popular one is HDRS-17, which is a seventeen question survey administered by a clinician. Scores on HDRS-17 vary from zero to 57. Scores of 0-7 are generally considered normal, while a score of 20 or greater indicates at least moderate depression.
You can look at the questions on HDRS-17 here. To my eye, it seems to strangely underweight feelings of subjective psychological distress that define depression, and includes a lot of symptoms that are only contingently associated with what we actually mean when we talk about depression. I think the heterogeneity in types of questions is a potential problem in using it to quantitatively assess the effectiveness of interventions on depressive disorder, but I'd like to leave that aside for now for the most part.
What does it mean for antidepressants to work?
Most studies that use a scale like HDRS-17 to look at the effectiveness of interventions on depression either define a cutoff of how much improvement counts as partial or full remission and use that cutoff as a binary indicator for success, or look at the average treatment effect in terms of points of improvement for the treatment arm relative the placebo arm. In the former case, a decrease of 50% of baseline HDRS-17 points or more is often used as the cutoff, corresponding to at least partial remission of depression. In the continuous treatment effect, an improvement of three points or more is often considered to be a clinically significant effect, although that might be too low (three point swings in HDRS would usually be considered noise for an individual patient in a clinical setting).
What do these studies find?
In this essay, I'm going to focus on one particular meta-analysis of the effectiveness of fluoxetine (Prozac) by Bech P, Cialdella P, Haugh MC, et al in BJP. However, I believe that this study is representative of most similar analyses, and my discussion of it is broadly applicable. Other studies are discussed in a review of meta-analyses in the Annals of Hospital Psychiatry and a critical review of the literature in BMJ. The pattern that studies with a quantitative endpoint found a small and clinically insignificant improvement seems to hold nearly universally as far as I can find.
Conversely, most studies that examine the efficacy of antidepressants in terms of a cutoff on percent improvement show a clinically significant effect. Sometimes, the same meta-analysis includes both endpoints. The Bech, Cialdella, Haugh et al (heretofore BCH) analysis that I want to look into more closely is one of them.
What does BCH find?
BCH is a meta-analysis of 30 studies, some of which compare fluoxetine to a placebo, and others that compare it to old Tricyclic antidepressants (TCAs). I want to focus on the comparisons to the placebo, of which there were 16, all conducted in the US. The authors consider three measures of treatment: Intention to treat, which counts any study dropouts as having failed the study, Efficacy analysis, which takes anyone who completed four weeks of treatment and uses their last check-in as the post-treatment result, and End-point, which takes anyone who had any post-treatment visit and uses their last check-in as their post-treatment result. The results are summarized in the following table from the paper:
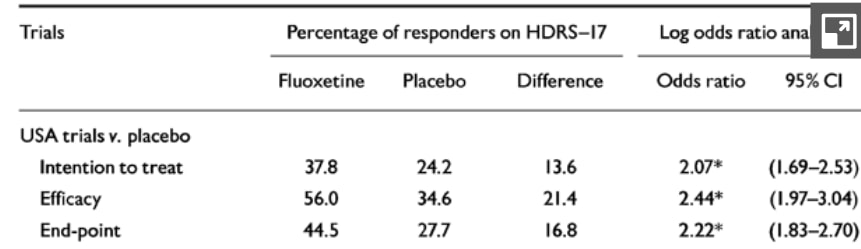
I think the intent to treat measure is the best since antidepressants are not supposed to continue to work after discontinuation, so anyone who does not continue the treatment throughout the post-baseline period should be expected not to show any long-term improvement (though for some, short term relief could be a meaningful benefit). However, only the third measure (End-point) is used for the average treatment effect analysis. In every case, the results seem pretty clinically significant: to be a responder, you have to halve your HDRS-17 score relative to the baseline. If a treated subject is 13.6 or 21.4 or 16.8 percentage points more likely to be a responder by this definition than a recipient of the placebo, I think it is reasonable to call this a positive result for fluoxetine.
The average treatment effect analysis uses the End-point measure and simply takes the mean difference in HDRS-17 scores from before and after treatment and compares the difference in differences for the treatment arm and the survey arm. Unfortunately, it does not report the original averages nor the single-differenced results—it only displays the last difference-in-differences figure. The individual study results and the average are displayed below:
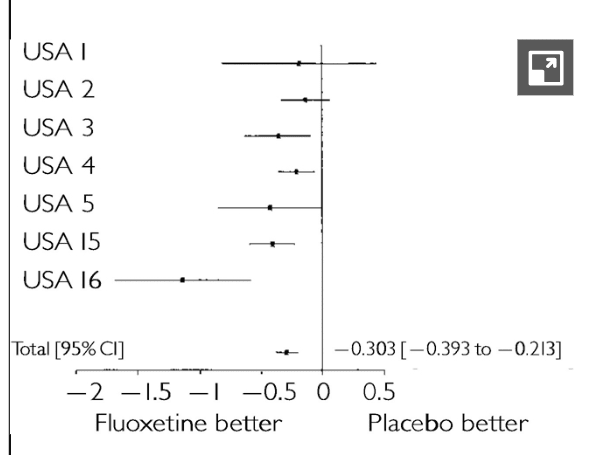
The average treatment effect across all studies was an improvement for the fluoxetine relative to the placebo of 0.303 HDRS-17 points. Recall that the HDRS-17 is out of 57 points, most of the participants probably started with a score of 20 or greater, and a score difference of three (ten times what the study shows) is not usually considered clinically significant. Clearly, this result is a pretty precisely estimated zero.
How do you reconcile this?
It is of course possible to get different results when you analyze a variable as continuous versus if you dichotomize it. Indeed, it's possible to make a dichotomous result look material even with a small change by choosing the right threshold. For example, if 50% of treated participants improved their score by two points and 50% saw no effect, while no placebo respondents had a change, then choosing a threshold of one point of improvement would show that the treatment group was 50 percentage points more likely to respond to treatment.
However, I don't think this is sufficient to explain the discrepancy in this case. The only way I can come up with numbers that approach what the study found is to assume an extremely heterogeneous treatment effect, to the point where the heterogeneity should be a first-order object of concern more than the average treatment effect itself.
Simulation
There are a lot of parameters to the study that aren't given, so I made them up. However, essentially all reasonable parameters give about the same result. Feel free to try to find some assumptions under which the difference in treatment versus control remission rates approaches 16.8 percentage points.
Note that the only thing that the study does state is that the mean difference in change between the pre and post period for treated versus placebo respondents was 0.303 HDRS-17 points. Here's some R code that shows my approach. In the following code, I assume a homogeneous treatment effect.
ENTRY_CUTOFF <- 20L
MAX_HDRS_SCORE <- 57L
AVERAGE_HDRS_SCORE <- 30L
MEAN_PLACEBO_CHANGE <- 8L
set.seed(100)
entrants <- rnorm(1000000L, mean=AVERAGE_HDRS_SCORE,sd=4)
entrants <- ifelse(entrants < ENTRY_CUTOFF, ENTRY_CUTOFF, entrants)
entrants <- ifelse(entrants > MAX_HDRS_SCORE, MAX_HDRS_SCORE, entrants)
treat <- entrants
pla <- entrants
treatment_effect <- rep_len(-0.303,1000000)
placebo_effect <- rnorm(1000000,mean=-1*MEAN_PLACEBO_CHANGE,sd=4)
treatment_diff <- treatment_effect + placebo_effect
post_treat <- treat + treatment_diff
post_pla <- pla + placebo_effect
post_treat <- ifelse(post_treat < 0, 0, post_treat)
post_pla <- ifelse(post_pla < 0, 0, post_pla)
diff_diff <- post_treat - post_pla
mean(diff_diff)
# partial remission: 50% decline
treatment_comp <- (post_treat - treat) / treat
treat_remission <- ifelse(treatment_comp < -0.5,1,0)
tm <- mean(treat_remission)
tm*100
pla_comp <- (post_pla - pla) / pla
pla_remission <- ifelse(pla_comp < -0.5,1,0)
tp <- mean(pla_remission)
tp*100
print((tm - tp)*100)
# 0.8337%With these parameters, I find that treated participants should be 0.84 percentage points more likely to be in remission than placebo respondents.
In the following code, I allow for a heterogeneous treatment effect. To get to something approaching the results of the study, I have to let the treatment effect itself (recall, its mean is 0.303) to be normally distributed with a massive standard deviation of 7.75.
ENTRY_CUTOFF <- 20L
MAX_HDRS_SCORE <- 57L
AVERAGE_HDRS_SCORE <- 30L
MEAN_PLACEBO_CHANGE <- 8L
set.seed(100)
entrants <- rnorm(1000000L, mean=AVERAGE_HDRS_SCORE,sd=4)
entrants <- ifelse(entrants < ENTRY_CUTOFF, ENTRY_CUTOFF, entrants)
entrants <- ifelse(entrants > MAX_HDRS_SCORE, MAX_HDRS_SCORE, entrants)
treat <- entrants
pla <- entrants
treatment_effect <- rnorm(1000000,mean=-0.303, sd=7.75)
placebo_effect <- rnorm(1000000,mean=-1*MEAN_PLACEBO_CHANGE,sd=4)
treatment_diff <- treatment_effect + placebo_effect
post_treat <- treat + treatment_diff
post_pla <- pla + placebo_effect
post_treat <- ifelse(post_treat < 0, 0, post_treat)
post_pla <- ifelse(post_pla < 0, 0, post_pla)
diff_diff <- post_treat - post_pla
mean(diff_diff)
# partial remission: 50% decline
treatment_comp <- (post_treat - treat) / treat
treat_remission <- ifelse(treatment_comp < -0.5,1,0)
tm <- mean(treat_remission)
tm*100
pla_comp <- (post_pla - pla) / pla
pla_remission <- ifelse(pla_comp < -0.5,1,0)
tp <- mean(pla_remission)
tp*100
print((tm - tp)*100)
# 16.8374%The implications of this are very strange. Under such a heterogeneous treatment effect, about 48% of respondents were made worse off by the drug. Among those who were made worse off, their HDRS-17 score was increased by an average of 6.07 points, 20 times the average treatment effect in the opposite direction. Among the 52% of those who were made better off, their HDRS-17 score decreased by an average of 6.29 points. This is a histogram of the treatment effect (the actual assumed effect of the drug, not including mean reversion or the placebo effect):
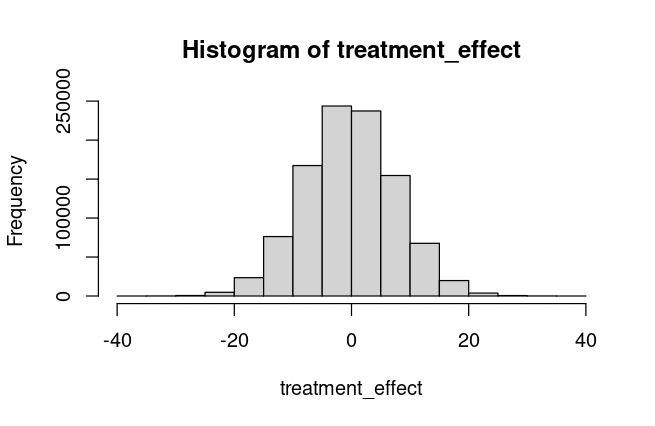
The overwhelming story here is the heterogeneity, not whether the mean is different from zero. Many patients appear to be helped quite a bit by fluoxetine, and almost as many are harmed.
Conclusion
There are several possibilities that I can think of from this analysis:
- I made a mistake with my simulation
- The simulation is correct but is missing some structural feature of the study that isn't explained in the write-up
- The distribution of depression scores, the distribution of placebo effects, or the distribution of treatment effects is so dissimilar from my assumptions that it is actually possible to get the results that the authors did without having massive heterogeneity of treatment effects
- My simulation and analysis are correct and the treatment effect of fluoxetine is massively heterogeneous.
If the last option is true, then the endpoints of this study, and most other studies on antidepressants in general, are entirely missing the forest for the trees. A small average treatment effect and a difference in binary remission rates are masking the fact that these drugs are highly effective for some and very harmful for others, at least in the short term. Is it possible to determine a priori who will fall in which group? Is the heterogeneity limited to a subset of the questions on the HDRS-17, like sleep or appetite? Do people who benefit from fluoxetine also benefit from duloxetine and other drugs and vice-versa? Without more information about heterogeneity, it seems very difficult to come to any conclusions about the effectiveness of SSRI antidepressants.
References
- Bech P, Cialdella P, Haugh MC, et al. Meta-analysis of randomised controlled trials of fluoxetine v. placebo and tricyclic antidepressants in the short-term treatment of major depression. British Journal of Psychiatry. 2000;176(5):421-428. doi:10.1192/bjp.176.5.421
- Jakobsen JC, Gluud C, Kirsch I. Should antidepressants be used for major depressive disorder? BMJ Evid Based Med. 2020 Aug;25(4):130. doi: 10.1136/bmjebm-2019-111238. Epub 2019 Sep 25. PMID: 31554608; PMCID: PMC7418603.
- Hamilton M. A rating scale for depression. J Neurol Neurosurg Psychiatry 1960; 23:56–62
- Moncrieff J. What does the latest meta-analysis really tell us about antidepressants? Epidemiol Psychiatr Sci. 2018 Oct;27(5):430-432. doi: 10.1017/S2045796018000240. Epub 2018 May 28. PMID: 29804550; PMCID: PMC6999018.
- Rossi A, Barraco A, Donda P. Fluoxetine: a review on evidence based medicine. Ann Gen Hosp Psychiatry. 2004 Feb 12;3(1):2. doi: 10.1186/1475-2832-3-2. PMID: 14962351; PMCID: PMC356924.
9 comments
Comments sorted by top scores.
comment by AnthonyC · 2025-01-13T01:10:18.832Z · LW(p) · GW(p)
If the last option is true, then the endpoints of this study, and most other studies on antidepressants in general, are entirely missing the forest for the trees.
This seems like the most likely scenario to me. I appreciate the need and desire to have a conclusive, defensible, formally rigorous answer to this question, but also, in some sense the answer very obviously has to end up being "Yes, but both 'depression' and 'antidepressant' are probably somewhat confused or overloaded categories that none of our available endpoints or diagnostic metrics demultiplex well enough to satisfy anyone or match patients' lived experiences."
I'm one patient who has been on bupropion for depression for ~6 years, and I truly cannot imagine a study that would convince me that it "didn't work" for me, in the ways that actually matter. The effects on my mind kick in sharply, scale smoothly with dose, decay right in sync with half-life in the body, and are clearly noticeable not just internally for my mood but externally in my speech patterns, reaction speeds, ability to notice things in my surroundings, short term memory, and facial expressions.
Replies from: Hzn, LosPolloFowler↑ comment by Hzn · 2025-01-13T04:24:15.499Z · LW(p) · GW(p)
Do you have any opinion on bupropion vs SSRIs/SNRIs?
Replies from: nathan-helm-burger, AnthonyC↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-13T17:35:50.856Z · LW(p) · GW(p)
I'm on both for the past year (vs just sertraline for prev decade). Love the extra energy and reduction in anxiety I've experienced from the buproprion.
On at least 5 different occasions I've tried weaning myself gradually off of sertraline. Every time I fall back into depression within a month or two. My friends and family then beg me to go back on it ASAP.
↑ comment by Stephen Fowler (LosPolloFowler) · 2025-01-13T08:38:04.958Z · LW(p) · GW(p)
"cannot imagine a study that would convince me that it "didn't work" for me, in the ways that actually matter. The effects on my mind kick in sharply, scale smoothly with dose, decay right in sync with half-life in the body, and are clearly noticeable not just internally for my mood but externally in my speech patterns, reaction speeds, ability to notice things in my surroundings, short term memory, and facial expressions."
The drug actually working would mean that your life is better after 6 years of taking the drug compared to the counterfactual where you took a placebo.
The observations you describe are explained by you simply having a chemical dependency on a drug that you have been on for 6 years.
Replies from: AnthonyC↑ comment by AnthonyC · 2025-01-13T15:09:27.457Z · LW(p) · GW(p)
I suppose, but 1) there has been no build-up/tolerance, the effects from a given dose have been stable, 2) there are no cravings for it or anything like that, 3) I've never had anything like withdrawal symptoms when I've missed a dose, other than a reversion to how I was for the years before I started taking it at all. What would a chemical dependency actually mean in this context?
My depression symptoms centered on dulled emotions and senses, and slowed thinking. This came on gradually over about 10 years, followed by about 2 years of therapy with little to no improvement before starting meds. When I said that for me the effects kicked in sharply, I meant that on day three after starting the drug, all of a sudden while I was in the shower my vision got sharper, colors got brighter, I could feel water and heat on my skin more intensely, and I regained my sense of smell after having been nearly anosmic for years. I immediately tested that by smelling a jar of peanut butter and started to cry, after not crying over anything for close to 10 years. Food tasted better, and my family immediately noticed I was cooking better because I judged seasonings more accurately. I started unconsciously humming and singing to myself. My gait got bouncier like it had been once upon a time before my depression all started. There was about a week of random euphoria after which things stayed stable. Over the first few months, if I missed my dose by even a few hours, or if I was otherwise physically or emotionally drained, I would suddenly become like a zombie again. My face went slack, my eyes glazed over, my voice lost any kind of affect, my reactions slowed down dramatically. By suddenly, I mean it would happen mid-conversation, between sentences. These events decreased to 1-2x/month on an increased dose, and went away entirely a few years later upon increasing my dose again. I have also, thankfully, had no noticeable side effects. Obviously a lot of other things have happened in 6 years, many quite relevant, that I don't feel like getting into here, but those are mostly related to me regaining the ability to build capacity to actually live my life.
Yes, it is theoretically possible a placebo could have done that. I don't think it is plausible, or that any study (maybe I should say, any study that did not include me? Even then I'm not sure what a study on me-now could entail that would be convincing).
I do realize my experiences on these meds are atypical, my depression presented somewhat unusually, and SNRIs are not SSRIs. I got extremely lucky. But that was kind of my point in my original comment.
comment by Hzn · 2025-01-13T04:21:52.072Z · LW(p) · GW(p)
I don't know about depression. But anecdotally they seem to be highly effective (even overly effective) against anxiety. They also tend to have undesirable effects like reduced sex drive & inappropriate or reduced motivation -- the latter possibly a downstream effect of reduced anxiety. So the fact that they would help some people but hurt others seems very likely true.
Replies from: jacob-goldsmith-1↑ comment by Jacob Goldsmith (jacob-goldsmith-1) · 2025-01-13T16:01:09.655Z · LW(p) · GW(p)
Yes, I personally take SSRIs for anxiety and I find them highly effective, and I have a hard time believing the effect is a placebo though of course it’s possible.
comment by Martin Plöderl (martin-ploederl) · 2025-01-19T18:25:46.643Z · LW(p) · GW(p)
You know this one?
https://pubmed.ncbi.nlm.nih.gov/35918097/
In the supplement there's also the cumulative distribution of change from baseline.