Domain-specific SAEs
post by jacob_drori (jacobcd52) · 2024-10-07T20:15:38.584Z · LW · GW · 2 commentsContents
Introduction Experimental Setup Comparisons 1: Loss Recovered 2: Feature rarity 3: Feature novelty 4: Feature quality Limitations and Future Work Acknowledgements Appendix: Detailed Score Breakdown Appendix: Cherry-picked Features Biology Feature 1 (SSAE) Biology Feature 2 (SSAE) Biology Feature 3 (Direct SAE) Math Feature 1 (SSAE) Math Feature 2 (SSAE) Math Feature 3 (SSAE) Math Feature 4 (SSAE) Math Feature 5 (SSAE) Math Feature 6 ( Direct SAE) None 2 comments
TLDR: Current SAE training doesn't specifically target features we care about, e.g. safety-relevant ones. In this post, we compare three ways use SAEs to efficiently extract features relevant to a domain of interest.
Introduction
If Sparse Autoencoders (SAEs) are to be useful for alignment, they should reliably extract safety-relevant features. But currently, our methods for training SAEs are not targeted towards finding such features. Instead, we train SAEs on unstructured web text, then check if any of the learnt features happen to be safety-relevant (see e.g. here). By making our SAEs wider, we hope to find more and more - even all - of a model's features, thereby guaranteeing that the ones we care about show up.
This "find all the features" method is extremely expensive. According to Scaling Monosemanticity:
If a concept is present in the training data only once in a billion tokens, then we should expect to need a dictionary with on the order of a billion alive features in order to find a feature which uniquely represents [it]... If we wanted to get all the features… we would need to use much more compute than the total compute needed to train the underlying models.[1]
Individuals and small labs will not be able to afford this level of compute, and even scaling labs may be unwilling to pay such a high alignment tax. This motivates the following question:
Given some small, domain-specific dataset , what is the best way to efficiently extract features relevant to that domain?
In this post, we assume access to a General SAE (GSAE), which is a medium-sized SAE trained in the usual way on web text.[2] We will compare three methods:
- GSAE-finetune: finetune the GSAE on .
- Direct SAE: throw out the GSAE and train a small SAE on .
- Specialized SAE (SSAE): train a small SAE to reconstruct GSAE residuals on . That is, if is a model activation on we want .
The intuition for method 3 is that the GSAE takes care of the boring, general features that occur both in web text and in D (e.g. "this token is a verb"), freeing up the capacity of the SSAE to find the interesting, domain-specific features that the GSAE missed.
We find that the GSAE-finetune and Direct SAE perform best in terms of recovering model performance on (as measured by CE loss). On the other hand, the SSAE finds features that are rarer (on unstructured web text), newer (i.e. less similar to features that were already present in the GSAE), and higher-quality (as judged by human raters in a blind test). The best option therefore depends on the needs of the user.
[Note: in concurrent work, Anthropic also addressed what they call the "feature coverage" problem. They use a fourth method: mixing into a standard pretraining dataset. I have not yet had time to compare this to the other three methods].
Experimental Setup
- SAEs are trained on the layer 12 residual stream of Gemma 2B.
- All SAEs are gated (though if I started the project now, I'd use TopK SAEs for convenience).
- The GSAE has expansion factor 16, whereas the SSAE and Direct SAE have expansion factor 2.[3]
- The domain-specific datasets are collections of textbooks from a given subject, e.g. high-school biology or college math. Each contains between 1M and 10M tokens.[4]
- These datasets were used for convenience, but we expect the results to remain true for domains such as cybersecurity or bioweapons where large datasets are harder to find.
Comparisons
1: Loss Recovered
Let be the model's loss on , be the loss when the GSAE reconstruction is patched in, and be the loss when the domain-specific SAE's reconstruction is patched in.
Since the GSAE is imperfect, . We want our domain-specific SAE to recover part of this loss gap. Below, we plot the fraction of loss recovered,, against (the average number of active features per token).
[Note: when evaluating the SSAE, we patch in . Similarly, the we report is the sum of the for the GSAE and SSAE. In effect, our new, domain-specific SAE is the concatenation of the GSAE and SSAE.]
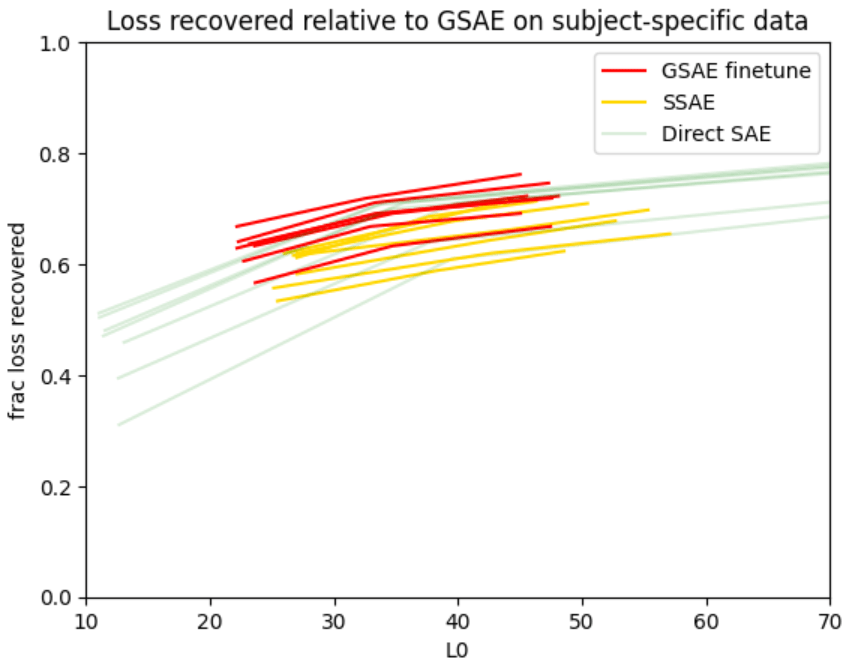
Each Pareto curve here corresponds to a different subject (high-school biology, college physics, etc). The GSAE-finetune and Direct SAE tend to marginally outperform the SSAE. If all you care about is fraction of loss recovered, you're probably best off finetuning a GSAE.
2: Feature rarity
We're interested in finding features that only occur rarely in unstructured web text - here we use OpenWebText (OWT). For each SAE, we plot a histogram of the log-frequencies of its features on OWT.
[Note: the largest plot below is for SAEs trained on economics text; the others are for other subjects. The spike at frequency = 1e-8 is artificial, and corresponds to dead features: I rounded frequencies from 0 to 1e-8, to avoid log(0) errors.]
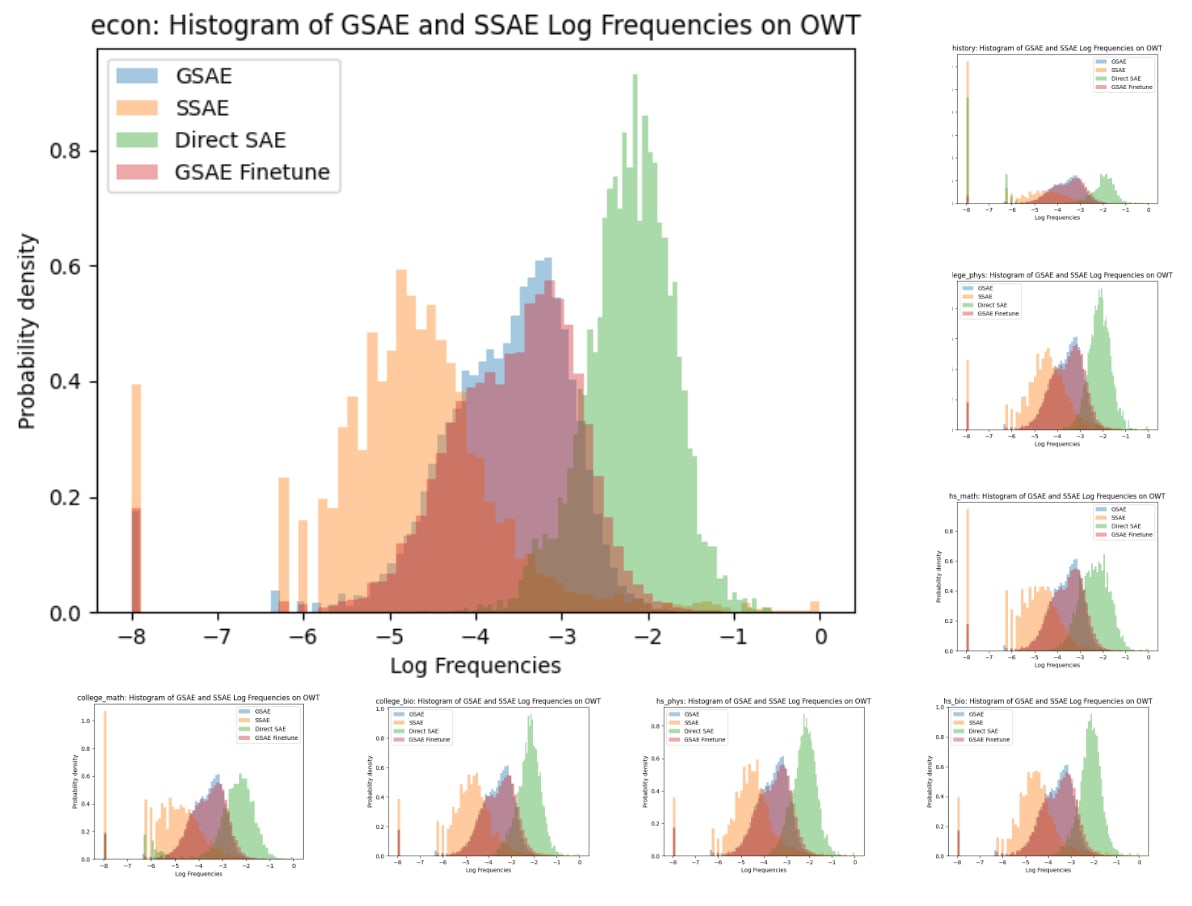
The GSAE (blue) and GSAE-finetune (red) frequencies are so similar that they appear as a single purple plot. Below, we will see that this is because the encoder weights hardly change during finetuning.
The typical SSAE feature is much rarer than typical GSAE-finetune or Direct SAE features. So if our goal is to capture features from the tail of the distribution, the SSAE seems best.
3: Feature novelty
Given a feature in our new, domain-specific SAE, we'd like to know whether it is "new", or whether it is very similar to some feature that was already present in the GSAE. To quantify this, we can look at the decoder column of a given feature in the domain-specific SAE, and calculate its maximum cosine similarity across all decoder columns from the GSAE. We can also do the same for the encoder rows. Below are histograms of max cossims, for SAEs trained on high-school physics textbooks. (The plots for other subjects looked identical).
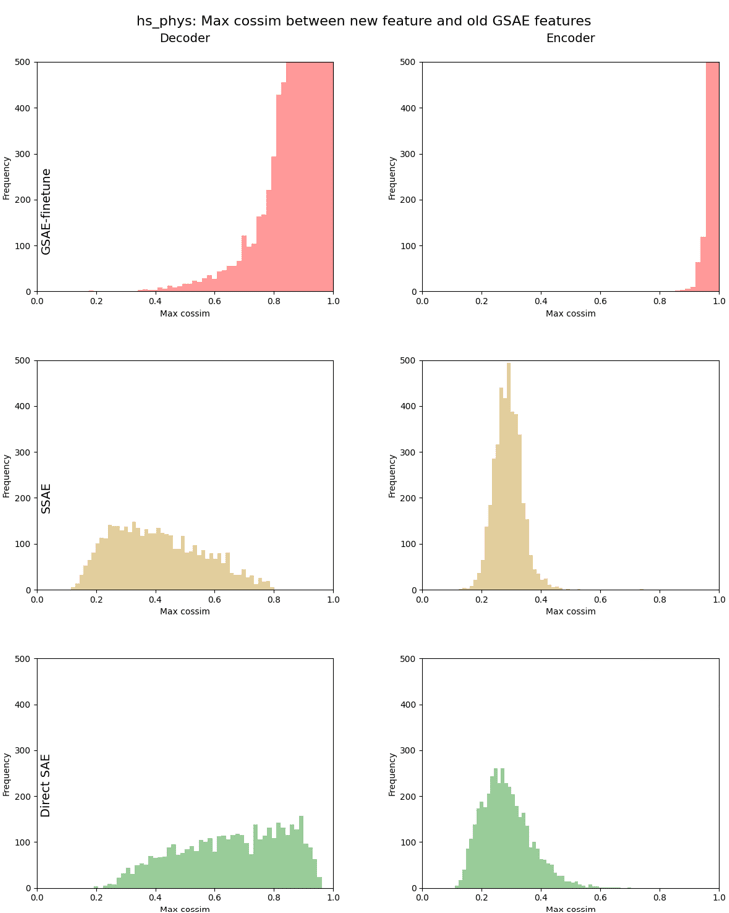
The GSAE-finetune features (top row) are very similar to features from the GSAE, particularly when we compare encoders. This suggests that finetuning the GSAE achieves good reconstruction not by finding new, physics-related features, but instead by making all the GSAE features ever-so-slightly more physics-y (whatever that means).
This property of GSAE-finetune is somewhat undesirable: it means its feature activations - and in particular the max-activating text examples for a given feature - are very similar to the GSAE's. Since looking at max-activating examples is currently our main method for interpreting features, all the GSAE-finetune features end up having the exact same interpretations as those from the GSAE. In this sense, we don't get "new" features at all.
4: Feature quality
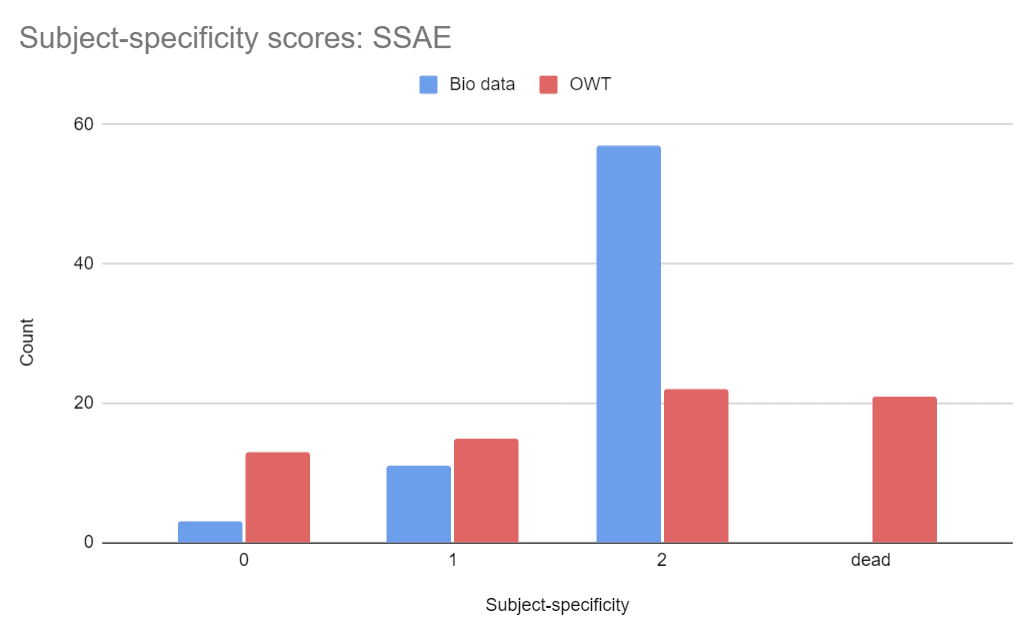
To compare subjective "feature quality", we (@Wilson Wu [LW · GW] and I) selected 100 random features each from the Direct SAE and SSAE, both trained on college math textbooks. For each feature, we looked at top-activating examples from OWT, and from math data, generating an explanation based on each. We then scored each explanation on subject-specificity:
- 0 = not related to math (e.g. verbs at the end of a sentence)
- 1 = associated to math, but not exclusively (e.g. the word “dimension”)
- 2 = strongly associated to math (e.g. base cases in proofs by induction)
[Note: the GSAE-finetune feature dashboards were identical to the GSAE dashboards, as mentioned above, so we did not bother generating explanations for these features.]
Although the scores were subjective and imperfect, the test was performed blind - the labelers did not know which SAE a given feature came from - so the results should reflect some sort of difference in quality between the SAEs.
Here are the average scores:
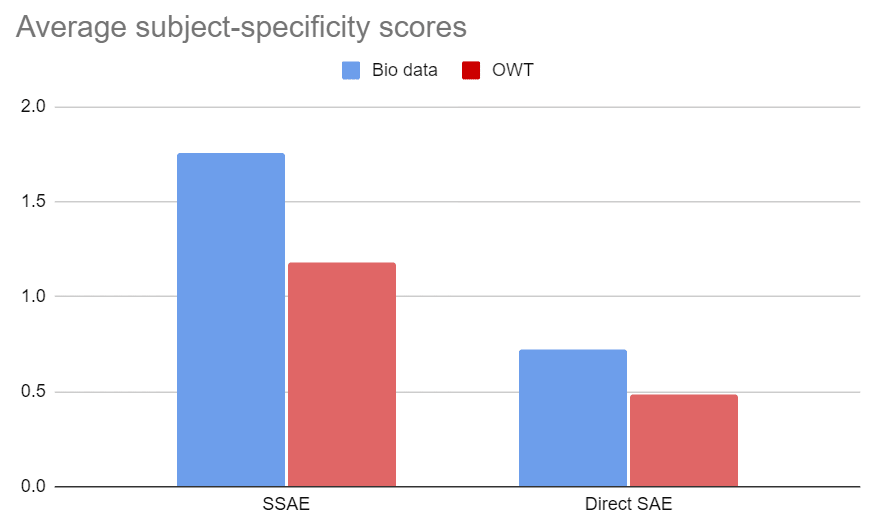
The SSAE features tend to score higher. The results were similar for biology textbooks:
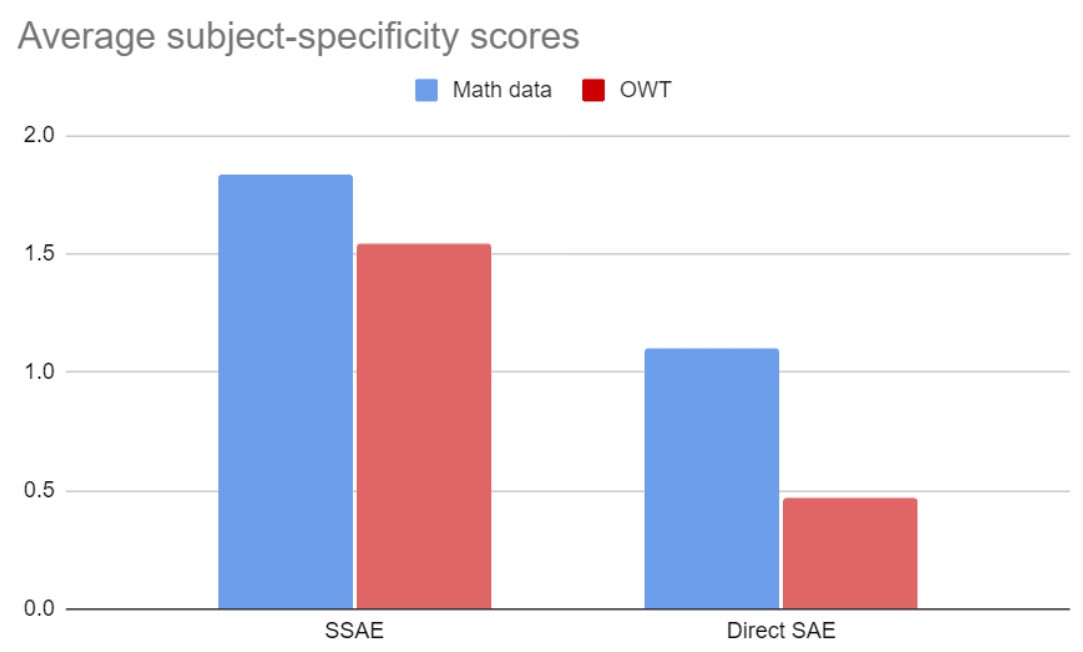
In terms of subjective quality of features, the SSAE beats the Direct SAE. See the Appendix for more detailed plots of the score distributions, as well as some of the most interesting feature dashboards we encountered during labelling.
Limitations and Future Work
The main limitation of this work is scope: I only investigated a single model and a small number of datasets. Therefore all the above claims are tentative. Still, I hope that this work encourages others to train domain-specific SAEs and improve upon the simple methods I described here.
I'd be particularly keen to see SAEs trained on safety-relevant data. This first will involve creating large datasets of text involving deception, persuasion, virology, or whatever domain we're interested in. For some domains, finding a sufficient amount of data on the web may be difficult, in which case we might turn to synthetic data. I'd then be very excited if one of these domain-specific SAEs was shown to improve upon vanilla SAEs in some alignment task.
Acknowledgements
This work was completed during MATS 6.0. Thanks to my mentors @Lucius Bushnaq [LW · GW] and @jake_mendel [LW · GW] for guidance, to @Wilson Wu [LW · GW] for setting up the blind feature-labelling experiment and doing half the labelling, and to @Kola Ayonrinde [LW · GW] for feedback on a draft of this post.
Appendix: Detailed Score Breakdown
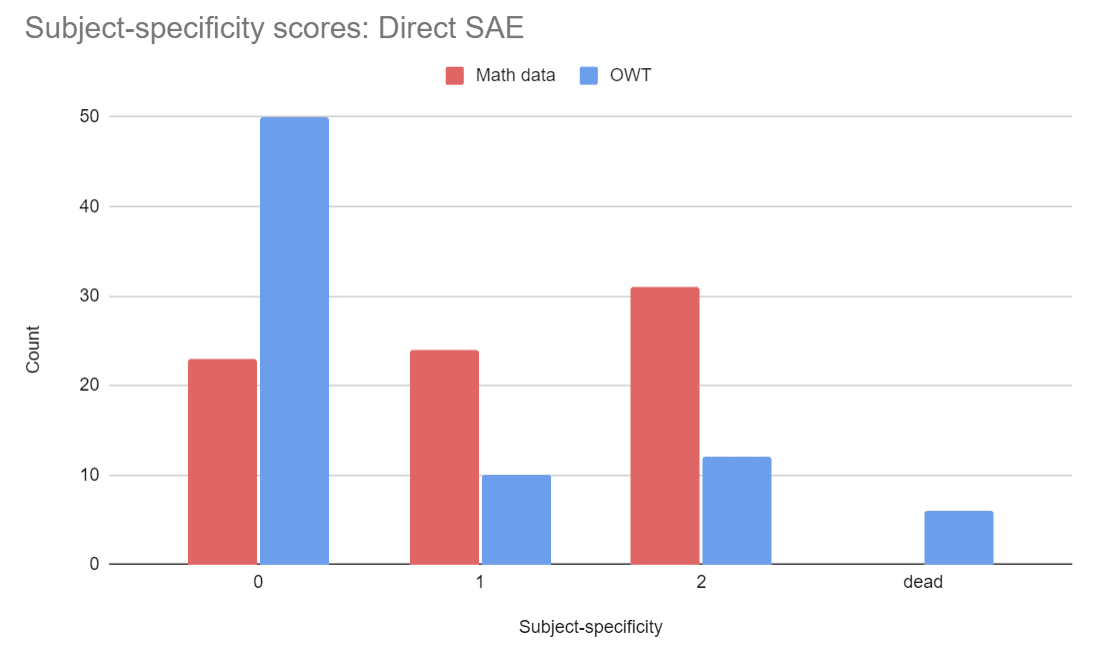
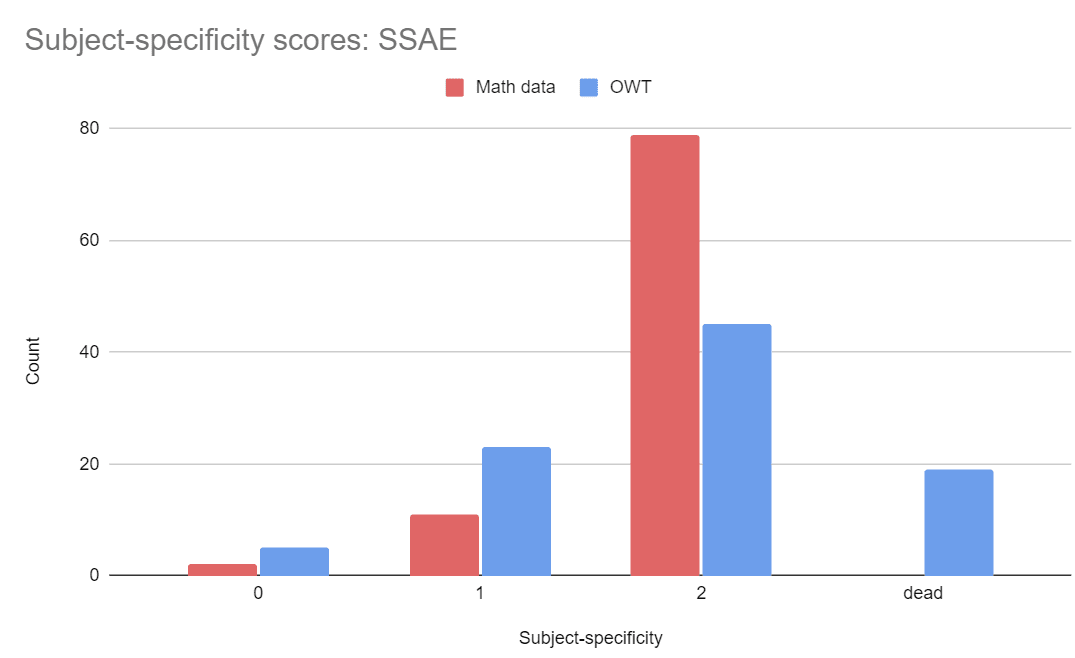
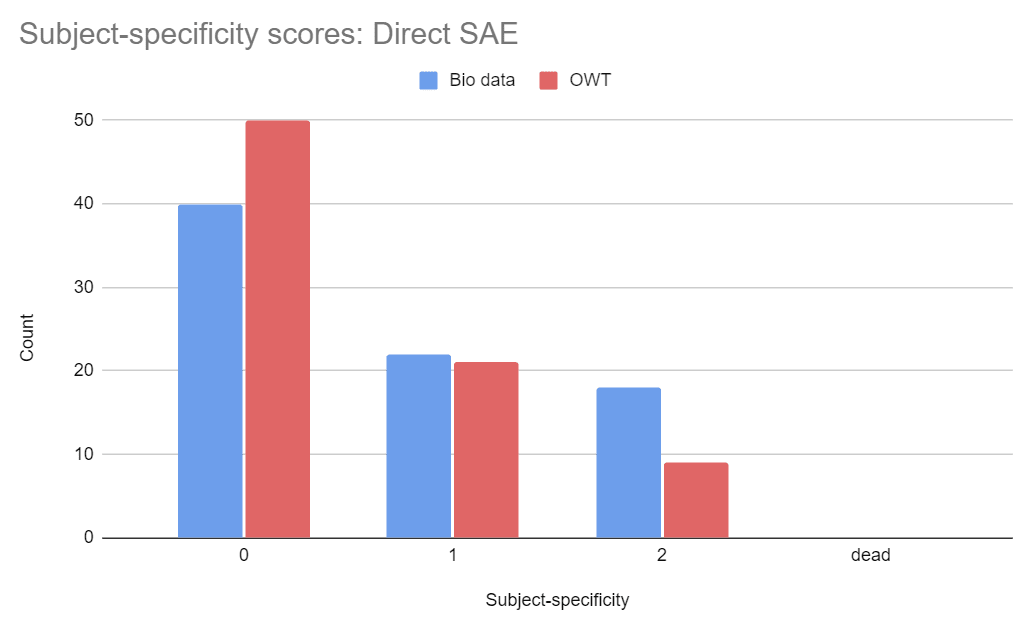
Appendix: Cherry-picked Features
During the blind feature-labelling, we marked some as particularly "nice". This was mostly for fun, and purely based off personal taste. 22 of the 200 SSAE features were "nice", compared to only 7 of the Direct SAE features. Below are the top-activating examples for a few of these "nice" features, taken from the subject-specific dataset D as well as from OpenWebText.
Biology Feature 1 (SSAE)
Top activations on D: references to density & heat capacity of water

Top activations on OWT:

Biology Feature 2 (SSAE)
Top activations on D: natural selection affecting frequency of genes/traits

Top activations on OWT:

Biology Feature 3 (Direct SAE)
Top activations on D: energy loss/the 2nd law of thermodynamics

Top activations on OWT

Math Feature 1 (SSAE)
Top activations on D: expressions rewritten in factorized form

Top activations on OWT: (not many nonzero activations for this feature)
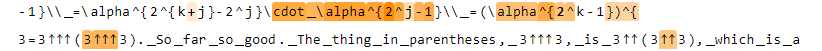
Math Feature 2 (SSAE)
Top activations on D: every X is Y

Top activations on OWT:

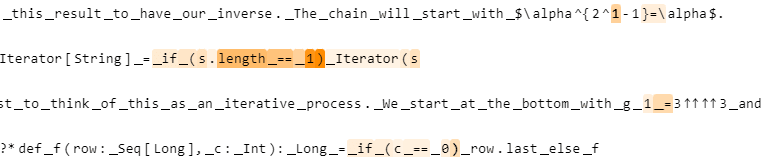
Math Feature 3 (SSAE)
Top activations on D: base cases of induction

Top activations on OWT:
Math Feature 4 (SSAE)
Top activations on D: associativity
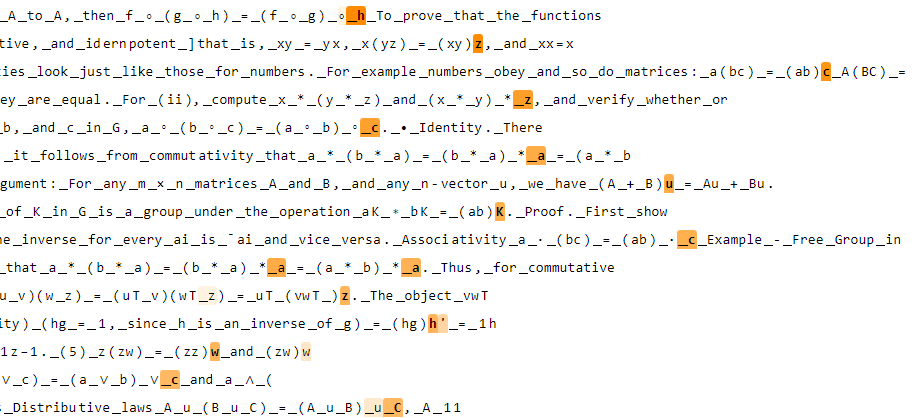
Top activations on OWT:
[Feature did not activate]
Math Feature 5 (SSAE)
Top activations on D: applying a theorem with a specific setting of variables

Top activations on OWT:
Math Feature 6 ( Direct SAE)
Top activations on D: circles

Top activations on OWT:

- ^
@Lucius Bushnaq [LW · GW] pointed out to me that the total number of features a model can represent is limited by its parameter count, see 1, 2. So it's unclear whether finding all features really requires more compute than the original model used to train. I have not yet formed a strong opinion here. It may be informative to train very wide SAEs on a toy model, and observe how loss scales with width in this regime.
- ^
"Medium-sized SAE" could be operationalized as meaning that it was trained with far less compute than the underlying model, but on a dataset much larger than our domain-specific dataset D.
- ^
This means the test is slightly unfair: the GSAE-finetune has 16x expansion, whereas the GSAE + SSAE concatenation together have an effective 18x expansion. I expect this difference to be small enough that it doesn't affect our conclusions.
- ^
Since the datasets contain copyrighted material, I have not made them available.
- ^
This means somewhat more compute is spent on GSAE-finetune, since it is wider than SSAE and Direct SAE. But the difference is small, since most compute is spent running forward passes of the underlying model to get activations.
2 comments
Comments sorted by top scores.
comment by Cheng-Han Chiang (d223302) · 2025-01-05T06:47:24.809Z · LW(p) · GW(p)
Thanks for the fantastic post. I have a question on the Loss Recovered comparison. In the text, you calculate the ratio . Based on the interpretation, it seems that a higher ratio is better. However, it seems to me that if the domain-specific SAE is good enough and perfectly reconstructed, we should have . In this case, the ratio from the above definition is zero, while this seems to be an optimal case. Can you point out where my interpretation may be wrong?
Replies from: jacobcd52↑ comment by jacob_drori (jacobcd52) · 2025-01-05T22:11:36.168Z · LW(p) · GW(p)
Oops, good spot! I meant to write 1 minus that quantity. I've edited the OP.