Seeing Through the Eyes of the Algorithm
post by silentbob · 2025-02-22T11:54:35.782Z · LW · GW · 3 commentsContents
Example 1: Trackmania AI Example 2: NPC Pathfinding Example 3: Vacuum Robot Example 4: LLMs Text does not equal text[5] Wrapping Up None 3 comments
There’s a type of perspective shift that can bring a lot of clarity to the behavior and limitations of algorithms and AIs. This perspective may be called seeing through the eyes of the algorithm (or AI, or LLM). While some may consider it obvious and intuitive, I occasionally encounter people – such as inexperienced programmers struggling with why some algorithm doesn’t work as expected, or generally many people complaining about the limitations of LLMs – who seem to be unfamiliar with it. For those who do find it obvious, it may still prove beneficial to explore a variety of examples to make this perspective shift more intuitive. It also sheds some light on why LLMs nowadays still often appear less capable than they actually are and why certain industries have not been disrupted to the degree some might have expected. If you primarily care about the latter, feel free to jump ahead to Example 4: LLMs.

See through the eyes of an algorithm in two easy steps:
- Wipe your mind clean. Imagine you’re in a dark room with no memory and no context.
- Now visualize precisely the inputs available that the algorithm / AI has access to.
When you’re programming an algorithm you usually have a lot of context in mind. You know what the algorithm’s goal is, why you need it, in which kind of environment you’re using it, how crucial it is to obtain precise solutions, and so forth. And it’s very easy to let this context influence your expectations about the algorithm. But the algorithm doesn’t care, and it doesn’t know – all it knows is the inputs it has and the rules it follows. And the best way I know of getting a better feel for how the algorithm behaves and why, and what its optimal performance would look like (given the context it currently lives in), is to put yourself as deeply into its shoes as you can. And the best way to let your System 1 participate in this exercise is to actually visualize things and do your best to see things exactly as the algorithm or AI would.
Example 1: Trackmania AI
In this video, at the linked timestamp, the creator Yosh presents a brief hypothesis – “it looks like the AI wants to stay in the center of the stadium” – but quickly reveals that’s not possible due to the fact that the AI cannot even see the stadium, demonstrating briefly what the world looks like from the AI’s point of view:
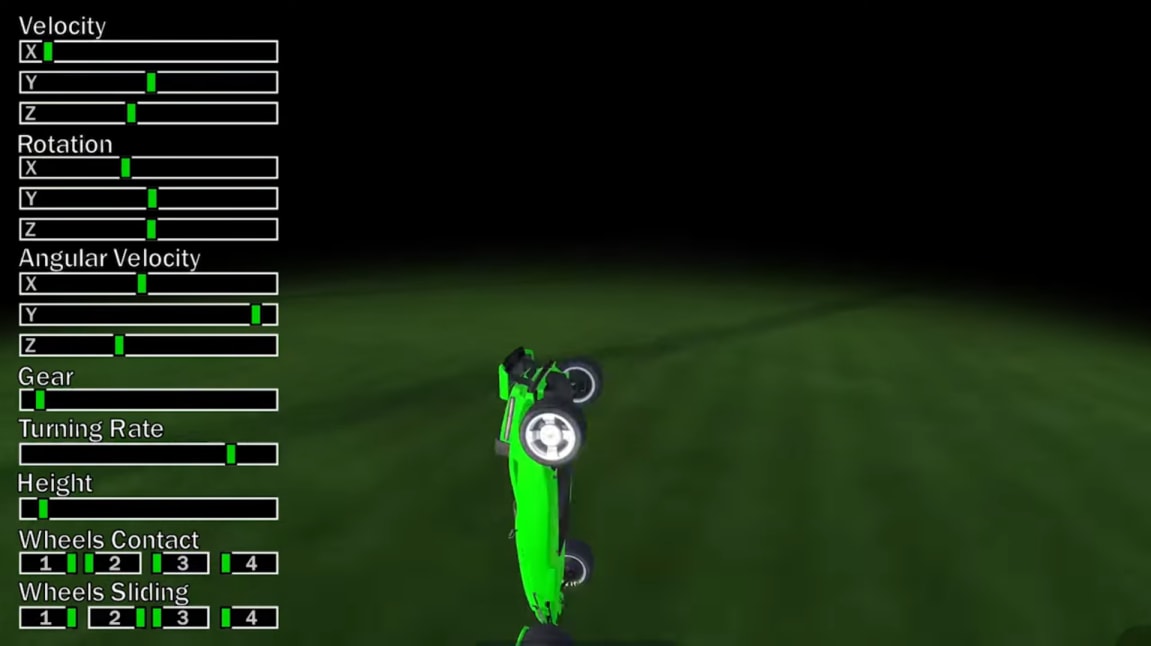
Example 2: NPC Pathfinding
A somewhat similar example can be seen here. Game developer RujiK the Comatose demonstrates in this dev log how the characters in this game at one point didn’t care at all what the shortest path to a goal looked like – they would happily jump off a bridge into a river just to shave a few virtual inches off their route.

This is arguably pretty easy to understand, and the developer probably realized directly, upon encountering this behavior for the first time, that some form of ground type distinction was still missing.
Still, it can’t hurt to be aware that what the AI (or rather the pathfinding algorithm) is seeing is, at this point, something like this:

Once you see through the algorithm’s eyes, it becomes instantly obvious why it took the route through the river: it simply has no way of seeing the river. All it sees is waypoints and connections. So, the algorithm needs additional inputs in order to produce more sensible-looking behavior.
Example 3: Vacuum Robot
I once had an autonomous vacuum cleaner of the more limited kind – one that just randomly moves around, bumping into things left and right for an hour or two, hoping to get the flat reasonably clean with its randomized movement pattern. Whenever it got stuck, I would just pick it up and drop it off somewhere nearby, and it happily continued.
A few years later, I finally got a more advanced one, one that maps out the whole flat and cleans everything systematically. This is, of course, generally much more effective. But one thing surprised me initially: whenever I, during the cleaning process or when it got stuck, picked it up and dropped it off again nearby, it was confused. It then spent 30 seconds very cautiously moving around and looking in all directions to reorient itself. Even when I placed it right to where it had just been, it would go through this process.
For us humans, orientation in our flat is pretty easy. We have seen pretty much all corners from all directions. And we usually move around self-controlled. On top of that, we have very high-fidelity vision, with millions of bits of information streaming into our brains in real time, second by second. With so much information available, orientation in this space becomes quite easy – so easy, in fact, that it didn’t even occur to me that this would be something my vacuum robot could struggle with until I saw it happen![1]
But from the vacuum’s point of view, this confusion makes sense. I’m not entirely sure what sensors it has, but it probably has some array of distances in all horizontal directions to the next solid object, maybe the distance and direction to its charging station (if it can sense it). And, crucially, it usually knows where it is, relative to its map of the flat, based on its own controlled actions. When it knows its orientation and that it’s currently moving “forward”, it’s probably quite straightforward to keep its position synced relative to its map. But I doubt it has accelerometers that allow it to sense in which direction it’s being carried. This means that keeping track of where it moves while it’s not controlling its own movement is a much harder problem than updating its world state while it’s acting on its own.[2]
If I imagine myself sitting in a dark room, and all I see is a bunch of distances around me in all directions (probably even just in one dimension), and then somebody picks me up, maybe even rotates me around all kinds of axes, then it doesn’t matter if they drop me off in the same place – it’s almost impossible for me to know that based on the very limited information that I’m seeing.

Example 4: LLMs
People often come to the conclusion that today’s LLMs are surprisingly stupid. In some cases this is basically just correct. Andrej Karpathy calls it “jagged intelligence”: the fact that LLMs are superhuman in some areas while making incredibly basic mistakes in others. But there’s more to it. In my view, there are at least three different problems playing into this:
- Missing context
- Fundamental difficulties of deriving your intentions from any prompt
- Limited intelligence
Points 1 and 2 are entangled, as you could argue that your intentions are just part of the context, but I think it makes sense to differentiate them.
First, LLMs often lack context about the setting of the problem they’re supposed to solve. They don’t know what you, the user, know. They don’t have the full picture but see only what’s in the context window (and system prompt, and a whole bunch of very generic priors they internalized from the training data)[3]. It’s easy to forget this unless you very deliberately imagine what it’s like to see exactly what the LLM sees.
Second, LLMs can’t read your mind. And the process of turning your desires into a text prompt is a very lossy one. However much effort you put into the perfect prompt, some other person who wants something subtly (or not so subtly) different could end up writing the exact same prompt, also thinking that this prompt perfectly captures their intentions. The LLM essentially has to solve the inverse problem [LW · GW] of deriving your intentions from your prompt, which is to some degree impossible because your prompt is such a lossy representation. On top of that, this inverse mapping is generally just extremely difficult to get right.
To put yourself in the AI’s shoes, imagine sitting in a dark room – yes, for some reason, these imaginary rooms always have to be dark 🤷– and all you have is a text-only chat window via which you converse with a total stranger whom you know nothing about.

And now this total stranger asks you to, say, solve some puzzle involving a goat and a boat to cross a river. This puzzle sounds extremely similar to a very well-known one, so you rightly have a strong prior that most people giving you this prompt likely refer to that original puzzle and just made a mistake in explaining it. All you get is this prompt. And some instructions from your employer who tells you to be a helpful assistant who doesn’t use swear words or whatever. And you happen to have a strong preference to always try to provide answers rather than first asking for clarification.
So what do you do? When you take the prompt literally, ignoring that it's close to a well-known but slightly different puzzle, many of the possible users who may have written this prompt will be annoyed that the LLM didn’t spot and correct the obvious mistake. But if the LLM does that, then the Gary Marcuses of the world will point out how limited and flawed it is, taking this as proof that the LLM is not truly intelligent. The LLM basically can never win because you can always find prompts that it necessarily answers “incorrectly”, depending on your somewhat arbitrary expectations.[4]
Similarly, I suspect the main reason that LLMs have not yet disrupted the software industry that much is exactly this: it looks through a narrow window, often seeing only some highly limited part of a huge code base, and is then asked to implement a new function, come up with unit tests, or document or refactor something. But without seeing the whole picture, it will not be able to do very useful things, no matter how intelligent it may be. And this whole picture is huge. Even a 1M token context window may not be sufficient to encode all the deep, varied, and nuanced context that the brain of a software engineer maintains at all times. And even if it was sufficient, this still takes an incredible amount of smart scaffolding, optimization, and constant maintenance, all of which goes way beyond the raw intelligence of the AI itself.
When looking through your eyes, it’s easy to get frustrated when the unit tests the LLM writes for you don’t live up to your standards. But when imagining yourself in a dark room on a laptop, where all you get is the prompt “write unit tests for this function: …” without more context or examples or even any idea whether this is for some personal project, a university exercise, or a production code base, then it makes a lot of sense that the LLM will often fail to deliver what you hoped for. Not (always or only) because it’s stupid, but because it’s missing context and because your prompt is never a 100% accurate representation of your desires.
Only when you can say in good faith that you, sitting in a dark room with nothing but a terminal in front of you, seeing exactly the same inputs that the LLM sees and nothing else around it, would reliably produce exactly the type of output that real-you in your real situation is hoping for, then the LLM’s failure to live up to your aspirations may indeed be due to its limited intelligence.
Text does not equal text[5]
Finally, speaking of LLMs and how they see the world, another important point is this: text does not equal text. We (or at least those of us blessed with eyesight) usually see text as rendered rich text, with formatting and font sizes and line breaks adding to the overall visual impression. We see text visually, in space.
Where we, for instance, can experience beautiful ASCII art such as this:
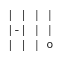
Why yes, thank you, I did indeed create that myself.
What the AI sees is pretty much this:
| | | |↵|-| | |↵| | | o
Now, in principle, all the information is there to deduce the geometric relations between the characters, and a sufficiently advanced AI (or at least a reasoning model reflecting about things in-depth step by step, which is able to decompose the string of characters into individual "emerging" letters systematically) will be able to understand and create complex ASCII art anyway. But it should also be clear that when it comes to something like ASCII art – or even the question how many r’s exist in the word strawberry[6] – the way we perceive text gives us a huge advantage. While the LLM has all the information that’s needed in principle, it perceives it in a way that makes it much harder to perform some of the operations on text that come to us so effortlessly[7]. So, an LLM struggling with such tasks is often less a problem of intelligence than one of, in this case, their modality not matching the use case very well.
Wrapping Up
If there’s one takeaway from all of this, it’s that AIs don't “see” the world as we do, and that perspective matters a lot. By deliberately stepping into their shoes – or, rather, their input streams – we can better grasp why they behave the way they do. Whether it’s an AI driving circles in Trackmania, an NPC carelessly plummeting into a river, a vacuum robot struggling with disorientation, or an LLM not quite meeting our expectations, the core issue is often the same: they operate within much stricter constraints than we care to remember while interacting with them from our rich and often surprisingly multi-modal human perspective.
This perspective shift is not just an exercise in curiosity but an essential tool for debugging, plus an important way to understand the struggles and limitations of today’s AIs. Whatever peak LLM intelligence of 2025 may look like, it would be a mistake to attribute failure modes to a lack of intelligence whenever they can be adequately explained by context (or lack thereof) and perspective.
- ^
If we’re honest, it’s not actually “easy”, and it’s quite a miracle our brains are able to pull it off so effortlessly. But the point is, we obtain more than enough information through sight alone, in any given moment, to determine at a glance where exactly in our flat we currently are.
- ^
One could say that this updating process, while it’s in control of its movement, is a forward problem, whereas updating its position when it’s moved by some other entity is an inverse problem [LW · GW].
- ^
Yeah, alright, if you use ChatGPT and have that one feature activated where it learns things about you over time, then it will also have some context about you as a user based on prior conversations.
- ^
This is not to say that LLMs are intelligent enough for all these cases. There are definitely many examples out there where we can observe basic failures of intellect rather than a lack of context. But in many other cases, even the smartest human would necessarily struggle with the given prompt because they cannot possibly know what the person who’s asking expects exactly. So, pointing out these failures often is not sufficient to derive conclusions about the AI’s level of intelligence.
- ^
Case in point: Grammarly complained that there should be a period behind this heading. I suspect that the Grammarly AI does maybe not “see” formatting but only plain text, so it can’t tell reliably whether something is a heading or not, and usually infers that from the phrasing alone. My gut reaction was “stupid Grammarly, why should there be a period in a heading?”, but probably it’s just another case where it’s not the “intelligence” that is limited, but the AI behind it just has less context than I have.
- ^
Just imagine a computer asking you how many ‘1’ bits exist in the machine representation of the word "strawberry", and concluding that clearly you are not actually intelligent when you fail to spontaneously name the right number.
- ^
It’s also noteworthy that the Hi!-example above probably exists somewhere in the training data of most big LLMs, so they may be able to answer it correctly merely due to having been exposed to that specific example. But with slightly more complex or unusual ones, they are likely to struggle much more.
3 comments
Comments sorted by top scores.
comment by kvas_it (kvas_duplicate0.1636121129676118) · 2025-04-09T09:20:53.730Z · LW(p) · GW(p)
Ideally the kinds of misunderstandings described in this post should not happen between humans because of shared context and common sense. However, they do. Not all humans have the same mental models and the same information context. Common sense is also not as common as it might seem at first.
comment by silentbob · 2025-02-22T12:14:54.669Z · LW(p) · GW(p)
Interestingly, the text to speech conversion of the "Text does not equal text" section is another very concrete example of this:
- The TTS AI summarizes the "Hi!" ASCII art picture as "Vertical lines arranged in a grid with minor variations". I deliberately added an alt text to that image, describing what can be seen, and I expected that this alt text would be used for TTS - but seemingly that is not the case, and instead some AI describes the image in isolation. If I were to describe that image without any further context, I would probably mention that it says "Hi!", but I grant that describing it as "Vertical lines arranged in a grid with minor variations" would also be a fair description.
- the "| | | |↵|-| | |↵| | | o" string is read out as "dash O". I would have expected the AI to just read that out in full, character by character. Which probably is an example of me falsely taking my intention as a given. There are probably many conceivable cases where it's actually better for the AI to not read out cryptic strings character by character (e.g. when your text contains some hash or very long URL). So maybe it can't really know that this particular case is an exception.
↑ comment by Rana Dexsin · 2025-04-09T12:12:23.826Z · LW(p) · GW(p)
the "Hi!" ASCII art picture
FWIW, I, ostensibly a human, did not see the “Hi!” either and instead saw something like one of those dangling-string curtains with an orb on one (maybe a control pull) and a little crossbar (maybe it's in front of a window).