CBiddulph's Shortform
post by CBiddulph (caleb-biddulph) · 2025-01-30T21:35:10.165Z · LW · GW · 15 commentsContents
15 comments
15 comments
Comments sorted by top scores.
comment by CBiddulph (caleb-biddulph) · 2025-03-09T08:11:09.470Z · LW(p) · GW(p)
I recently learned about Differentiable Logic Gate Networks, which are trained like neural networks but learn to represent a function entirely as a network of binary logic gates. See the original paper about DLGNs, and the "Recap - Differentiable Logic Gate Networks" section of this blog post from Google, which does an especially good job of explaining it.
It looks like DLGNs could be much more interpretable than standard neural networks, since they learn a very sparse representation of the target function. Like, just look at this DLGN that learned to control a cellular automaton to create a checkerboard, using just 6 gates (really 5, since the AND gate is redundant):
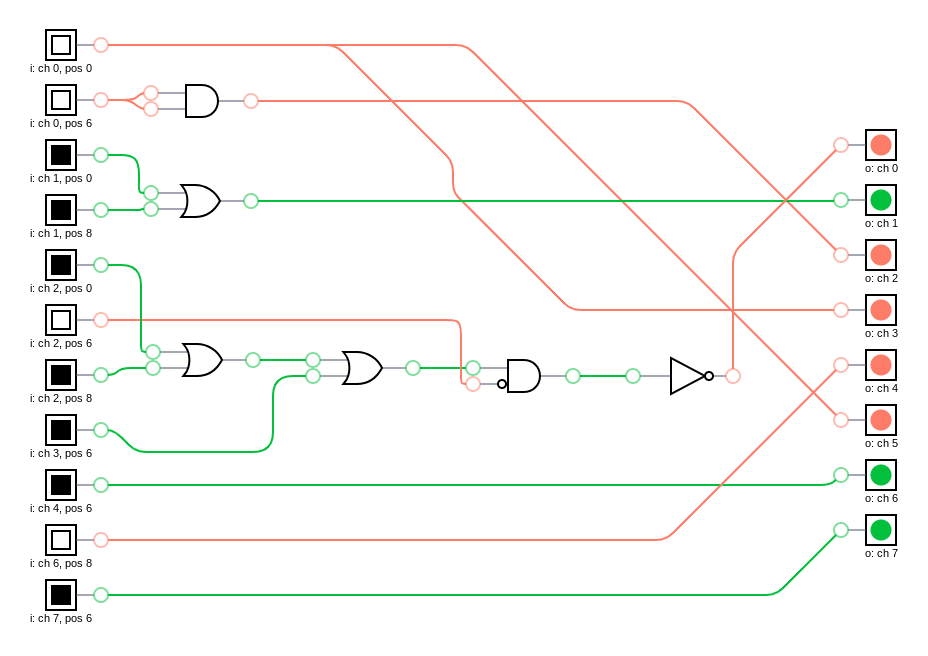
So simple and clean! Of course, this is a very simple problem. But what's exciting to me is that in principle, it's possible for a human to understand literally everything about how the network works, given some time to study it.
What would happen if you trained a neural network on this problem and did mech interp on it? My guess is you could eventually figure out an outline of the network's functionality, but it would take a lot longer, and there would always be some ambiguity as to whether there's any additional cognition happening in the "error terms" of your explanation.
It appears that DLGNs aren't yet well-studied, and it might be intractable to use them to train an LLM end-to-end anytime soon. But there are a number of small research projects you could try, for example:
- Can you distill small neural networks into a DLGN? Does this let you interpret them more easily?
- What kinds of functions can DLGNs learn? Is it possible to learn decent DLGNs in settings as noisy and ambiguous as e.g. simple language modeling?
- Can you identify circuits in a larger neural network that would be amenable to DLGN distillation and distill those parts automatically?
- Are there other techniques that don't rely on binary gates but still add more structure to the network, similar to a DLGN but different?
- Can you train a DLGN to encourage extra interpretability, like by disentangling different parts of the network to be independent of one another, or making groups of gates form abstractions that get reused in different parts of the network (like how an 8-bit adder is composed of many 1-bit adders)?
- Can you have a mixed approach, where some aspects of the network use a more "structured" format and others are more reliant on the fuzzy heuristics of traditional NNs? (E.g. the "high-level" is structured and the "low-level" is fuzzy.)
I'm unlikely to do this myself, since I don't consider myself much of a mechanistic interpreter, but would be pretty excited to see others do experiments like this!
Replies from: tailcalled, anaguma, lahwran, caleb-biddulph↑ comment by tailcalled · 2025-03-10T18:53:49.426Z · LW(p) · GW(p)
Deep Learning Systems Are Not Less Interpretable Than Logic/Probability/Etc [LW · GW]
Replies from: caleb-biddulph↑ comment by CBiddulph (caleb-biddulph) · 2025-03-10T20:00:05.325Z · LW(p) · GW(p)
Interesting, strong-upvoted for being very relevant.
My response would be that identifying accurate "labels" like "this is a tree-detector" or "this is the Golden Gate Bridge feature" is one important part of interpretability, but understanding causal connections is also important. The latter is pretty much useless without the former, but having both is much better. And sparse, crisply-defined connections make the latter easier.
Maybe you could do this by combining DLGNs with some SAE-like method.
↑ comment by anaguma · 2025-03-09T17:35:39.294Z · LW(p) · GW(p)
Do you know if there are scaling laws for DLGNs?
Replies from: caleb-biddulph↑ comment by CBiddulph (caleb-biddulph) · 2025-03-10T03:20:36.722Z · LW(p) · GW(p)
It could be good to look into!
↑ comment by the gears to ascension (lahwran) · 2025-03-10T03:44:23.848Z · LW(p) · GW(p)
This is just capabilities stuff. I expect that people will use this to train larger networks, as much larger as they can. If your method shrinks the model, it likely induces demand proportionately. In this case it's not new capabilities stuff by you so it's less concerning, bit still. This paper is popular because of bees
Replies from: caleb-biddulph↑ comment by CBiddulph (caleb-biddulph) · 2025-03-10T05:45:12.213Z · LW(p) · GW(p)
I'd be pretty surprised if DLGNs became the mainstream way to train NNs, because although they make inference faster they apparently make training slower. Efficient training is arguably more dangerous than efficient inference anyway, because it lets you get novel capabilities sooner. To me, DLGN seems like a different method of training models but not necessarily a better one (for capabilities).
Anyway, I think it can be legitimate to try to steer the AI field towards techniques that are better for alignment/interpretability even if they grant non-zero benefits to capabilities. If you research a technique that could reduce x-risk but can't point to any particular way it could be beneficial in the near term, it can be hard to convince labs to actually implement it. Of course, you want to be careful about this.
This paper is popular because of bees
What do you mean?
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2025-03-10T08:04:37.475Z · LW(p) · GW(p)
I buy that training slower is a sufficiently large drawback to break scaling. I still think bees are why the paper got popular. But if intelligence depends on clean representation, interpretability due to clean representation is natively and unavoidably bees. We might need some interpretable-bees insights in order to succeed, it does seem like we could get better regret bound proofs (or heuristic arguments) that go through a particular trained model with better (reliable, clean) interp. But the whole deal is the ai gets to exceed us in ways that make human interpreting stuff inherently (as opposed to transiently or fixably) too slow. To be useful durably, interp must become a component in scalably constraining an ongoing training/optimization process. Which means it's gonna be partly bees in order to be useful. Which means it's easy to accidentally advance bees more than durable alignment. Not a new problem, and not one with an obvious solution, but occasionally I see something I feel like i wanna comment on.
I was a big disagree vote because of induced demand. You've convinced me this paper induces less demand in this version than I worried (I had just missed that it trained slower), but my concern that something like this scales and induces demand remains.
↑ comment by CBiddulph (caleb-biddulph) · 2025-03-10T04:58:25.924Z · LW(p) · GW(p)
Another idea I forgot to mention: figure out whether LLMs can write accurate, intuitive explanations of boolean circuits for automated interpretability.
Curious about the disagree-votes - are these because DLGN or DLGN-inspired methods seem unlikely to scale, they won't be much more interpretable than traditional NNs, or some other reason?
comment by CBiddulph (caleb-biddulph) · 2025-01-30T21:35:10.409Z · LW(p) · GW(p)
There's been a widespread assumption that training reasoning models like o1 or r1 can only yield improvements on tasks with an objective metric of correctness, like math or coding. See this essay, for example, which seems to take as a given that the only way to improve LLM performance on fuzzy tasks like creative writing or business advice is to train larger models.
This assumption confused me, because we already know how to train models to optimize for subjective human preferences. We figured out a long time ago that we can train a reward model to emulate human feedback and use RLHF to get a model that optimizes this reward. AI labs could just plug this into the reward for their reasoning models, reinforcing the reasoning traces leading to responses that obtain higher reward. This seemed to me like a really obvious next step.
Well, it turns out that DeepSeek r1 actually does this. From their paper:
2.3.4. Reinforcement Learning for all Scenarios
To further align the model with human preferences, we implement a secondary reinforcement learning stage aimed at improving the model’s helpfulness and harmlessness while simultaneously refining its reasoning capabilities. Specifically, we train the model using a combination of reward signals and diverse prompt distributions. For reasoning data, we adhere to the methodology outlined in DeepSeek-R1-Zero, which utilizes rule-based rewards to guide the learning process in math, code, and logical reasoning domains. For general data, we resort to reward models to capture human preferences in complex and nuanced scenarios. We build upon the DeepSeek-V3 pipeline and adopt a similar distribution of preference pairs and training prompts. For helpfulness, we focus exclusively on the final summary, ensuring that the assessment emphasizes the utility and relevance of the response to the user while minimizing interference with the underlying reasoning process. For harmlessness, we evaluate the entire response of the model, including both the reasoning process and the summary, to identify and mitigate any potential risks, biases, or harmful content that may arise during the generation process. Ultimately, the integration of reward signals and diverse data distributions enables us to train a model that excels in reasoning while prioritizing helpfulness and harmlessness.
This checks out to me. I've already noticed that r1 feels significantly better than other models at creative writing, which is probably due to this human preference training. While o1 was no better at creative writing than other models, this might just mean that OpenAI didn't prioritize training o1 on human preferences. My Manifold market currently puts a 65% chance on chain-of-thought training outperforming traditional LLMs by 2026, and it should probably be higher at this point.
We need to adjust our thinking around reasoning models - there's no strong reason to expect that future models will be much worse at tasks with fuzzy success criteria.
Adapted from my previously-posted question [LW · GW], after cubefox [LW · GW] pointed out that DeepSeek is already using RLHF.
Replies from: Vladimir_Nesov, Thane Ruthenis↑ comment by Vladimir_Nesov · 2025-01-31T15:40:16.435Z · LW(p) · GW(p)
This is an obvious thing to try, but it's not what currently already works, and it's not certain to work without some additional ideas. You can do a little bit of this, but not nearly to the extent that o1/R1 inch towards saturating benchmarks on math/coding olympiad-like problems. So long as using LLMs as reward for scalable RL doesn't work yet, supercharged capabilities of o1/R1-like models plausibly remain restricted to verifiable tasks.
↑ comment by Thane Ruthenis · 2025-01-31T03:43:19.033Z · LW(p) · GW(p)
The problem with this neat picture is reward-hacking. This process wouldn't optimize for better performance on fuzzy tasks, it would optimize for performance on fuzzy tasks that looks better to the underlying model. And much like RLHF doesn't scale to superintelligence, this doesn't scale to superhuman fuzzy-task performance.
It can improve the performance a bit. But once you ramp up the optimization pressure, "better performance" and "looks like better performance" would decouple from each other and the model would train itself into idiosyncratic uselessness. (Indeed: if it were this easy, doesn't this mean you should be able to self-modify into a master tactician or martial artist by running some simulated scenarios in your mind, improving without bound, and without any need to contact reality?)
... Or so my intuition goes. It's possible that this totally works for some dumb reason. But I don't think so. RL has a long-standing history of problems with reward-hacking, and LLMs' judgement is one of the most easily hackable things out there.
(Note that I'm not arguing that recursive self-improvement is impossible in general. But RLAIF, specifically, just doesn't look like the way.)
Replies from: caleb-biddulph, nathan-helm-burger↑ comment by CBiddulph (caleb-biddulph) · 2025-01-31T17:27:56.234Z · LW(p) · GW(p)
Yeah, it's possible that CoT training unlocks reward hacking in a way that wasn't previously possible. This could be mitigated at least somewhat by continuing to train the reward function online, and letting the reward function use CoT too (like OpenAI's "deliberative alignment" but more general).
I think a better analogy than martial arts would be writing. I don't have a lot of experience with writing fiction, so I wouldn't be very good at it, but I do have a decent ability to tell good fiction from bad fiction. If I practiced writing fiction for a year, I think I'd be a lot better at it by the end, even if I never showed it to anyone else to critique. Generally, evaluation is easier than generation.
Martial arts is different because it involves putting your body in OOD situations that you are probably pretty poor at evaluating, whereas "looking at a page of fiction" is a situation that I (and LLMs) are much more familiar with.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-02-02T03:25:52.147Z · LW(p) · GW(p)
Well... One problem here is that a model could be superhuman at:
- thinking speed
- math
- programming
- flight simulators
- self-replication
- cyberattacks
- strategy games
- acquiring and regurgitating relevant information from science articles
And be merely high-human-level at:
- persuasion
- deception
- real world strategic planning
- manipulating robotic actuators
- developing weapons (e.g. bioweapons)
- wetlab work
- research
- acquiring resources
- avoiding government detection of its illicit activities
Such an entity as described could absolutely be an existential threat to humanity. It doesn't need to be superhuman at literally everything to be superhuman enough that we don't stand a chance if it decides to kill us.
So I feel like "RL may not work for everything, and will almost certainly work substantially better for easy to verify subjects" is... not so reassuring.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-02-02T03:41:51.120Z · LW(p) · GW(p)
Such an entity as described could absolutely be an existential threat to humanity
I agree. I think [LW · GW] you don't even need most of the stuff on the "superhuman" list, the equivalent of a competent IQ-130 human upload probably does it, as long as it has the speed + self-copying advantages.