Future ML Systems Will Be Qualitatively Different
post by jsteinhardt · 2022-01-11T19:50:11.377Z · LW · GW · 10 commentsContents
Emergent Shifts in the History of AI What This Implies for the Engineering Worldview None 10 comments
In 1972, the Nobel prize-winning physicist Philip Anderson wrote the essay "More Is Different". In it, he argues that quantitative changes can lead to qualitatively different and unexpected phenomena. While he focused on physics, one can find many examples of More is Different in other domains as well, including biology, economics, and computer science. Some examples of More is Different include:
- Uranium. With a bit of uranium, nothing special happens; with a large amount of uranium packed densely enough, you get a nuclear reaction.
- DNA. Given only small molecules such as calcium, you can’t meaningfully encode useful information; given larger molecules such as DNA, you can encode a genome.
- Water. Individual water molecules aren’t wet. Wetness only occurs due to the interaction forces between many water molecules interspersed throughout a fabric (or other material).
- Traffic. A few cars on the road are fine, but with too many you get a traffic jam. It could be that 10,000 cars could traverse a highway easily in 15 minutes, but 20,000 on the road at once could take over an hour.
- Specialization. Historically, in small populations, virtually everyone needed to farm or hunt to survive; in contrast, in larger and denser communities, enough food is produced for large fractions of the population to specialize in non-agricultural work.
While some of the examples, like uranium, correspond to a sharp transition, others like specialization are more continuous. I’ll use emergence to refer to qualitative changes that arise from quantitative increases in scale, and phase transitions for cases where the change is sharp.
In this post, I'll argue that emergence often occurs in the field of AI, and that this should significantly affect our intuitions about the long-term development and deployment of AI systems. We should expect weird and surprising phenomena to emerge as we scale up systems. This presents opportunities, but also poses important risks.
Emergent Shifts in the History of AI
There have already been several examples of quantitative differences leading to important qualitative changes in machine learning.
Storage and Learning. The emergence of machine learning as a viable approach to AI is itself an example of More Is Different. While learning had been discussed since the 1950s, it wasn’t until the 80s-90s that it became a dominant paradigm: for instance, IBM’s first statistical translation model was published in 1988, even though the idea was proposed in 1949[1]. Not coincidentally, 1GB of storage cost over $100k in 1981 but only around $9k in 1990 (adjusted to 2021 dollars). The Hansard corpus used to train IBM’s model comprised 2.87 million sentences and would have been difficult to use before the 80s. Even the simple MNIST dataset would have required $4000 in hardware just to store in 1981, but that had fallen to a few dollars by 1998 when it was published. Cheaper hardware thus allowed for a qualitatively new approach to AI: in other words, More storage enabled Different approaches.
Compute, Data, and Neural Networks. As hardware improved, it became possible to train neural networks that were very deep for the first time. Better compute enabled bigger models trained for longer, and better storage enabled learning from more data; AlexNet-sized models and ImageNet-sized datasets wouldn’t have been feasible for researchers to experiment with in 1990.
Deep learning performs well with lots of data and compute, but struggles at smaller scales. Without many resources, simpler algorithms tend to outperform it, but with sufficient resources it pulls far ahead of the pack. This reversal of fortune led to qualitative changes in the field. As one example, the field of machine translation moved from phrase-based models (hand-coded features, complex systems engineering) to neural sequence-to-sequence models (learned features, specialized architecture and initialization) to simply fine-tuning a foundation model such as BERT or GPT-3. Most work on phrase-based models was obviated by neural translation, and the same pattern held across many other language tasks, where hard-won domain-specific engineering effort was simply replaced by a general algorithm.
Few-shot Learning. More recently, GPT-2 and GPT-3 revealed the emergence of strong few-shot and zero-shot capabilities, via well-chosen natural language prompting.
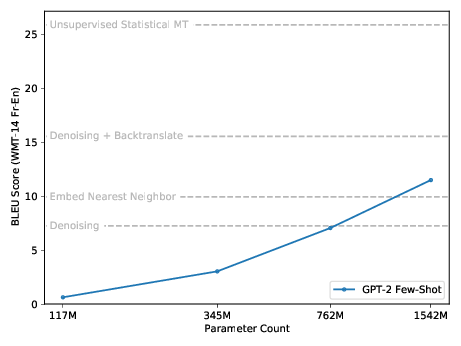
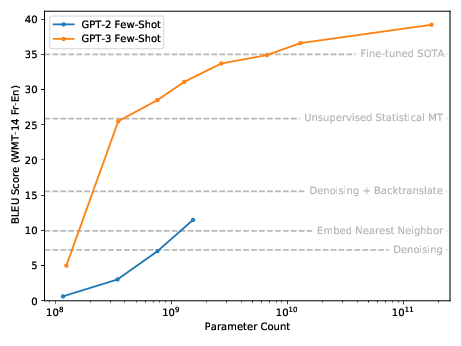
Top: Few-shot machine translation performance (BLEU score) for GPT-2. Bottom: GPT-3 (trained on more data) has an even starker curve, going from 5 to 25 BLEU between 100M and 400M parameters. Unsupervised baselines, as well as fine-tuned state-of-the-art, are indicated for reference.
This was an unexpected and qualitatively new phenomenon that only appeared at large scales, and it emerged without ever explicitly training models to have these few-shot capabilities. Comparing GPT-2 to GPT-3 shows that the exact model size needed can vary due to the training distribution or other factors, but this doesn’t affect the basic point that new capabilities can appear without designing or training for them.
Grokking. In 2021, Power et al. identified a phenomenon they call "grokking", where a network’s generalization behavior improves qualitatively when training it for longer (even though the training loss is already small).
Specifically, for certain algorithmically generated logic/math datasets, neural networks trained for 1,000 steps achieve perfect train accuracy but near-zero test accuracy. However, after around 100,000 steps the test accuracy suddenly increases, achieving near-perfect generalization by 1 million steps.
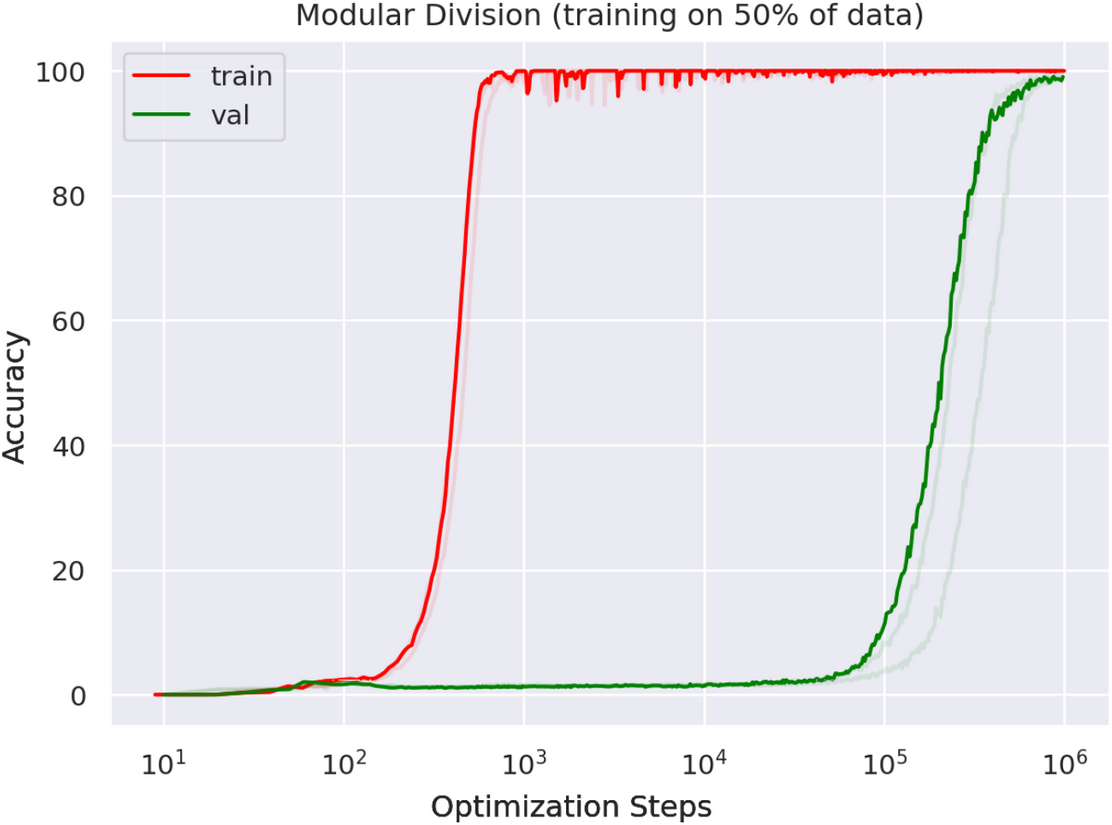
This shows that even for a single model, we might encounter qualitative phase transitions as we train for longer.
Other potential examples. I'll briefly list other examples from recent papers. I don't think these examples are as individually clear-cut, but they collectively paint an interesting picture:
- McGrath et al. (2021) show that AlphaZero acquires many chess concepts at a phase transition near 32,000 training steps.
- Pan et al. (2021) show that reward hacking sometimes occurs via qualitative phase transitions as model size increases.
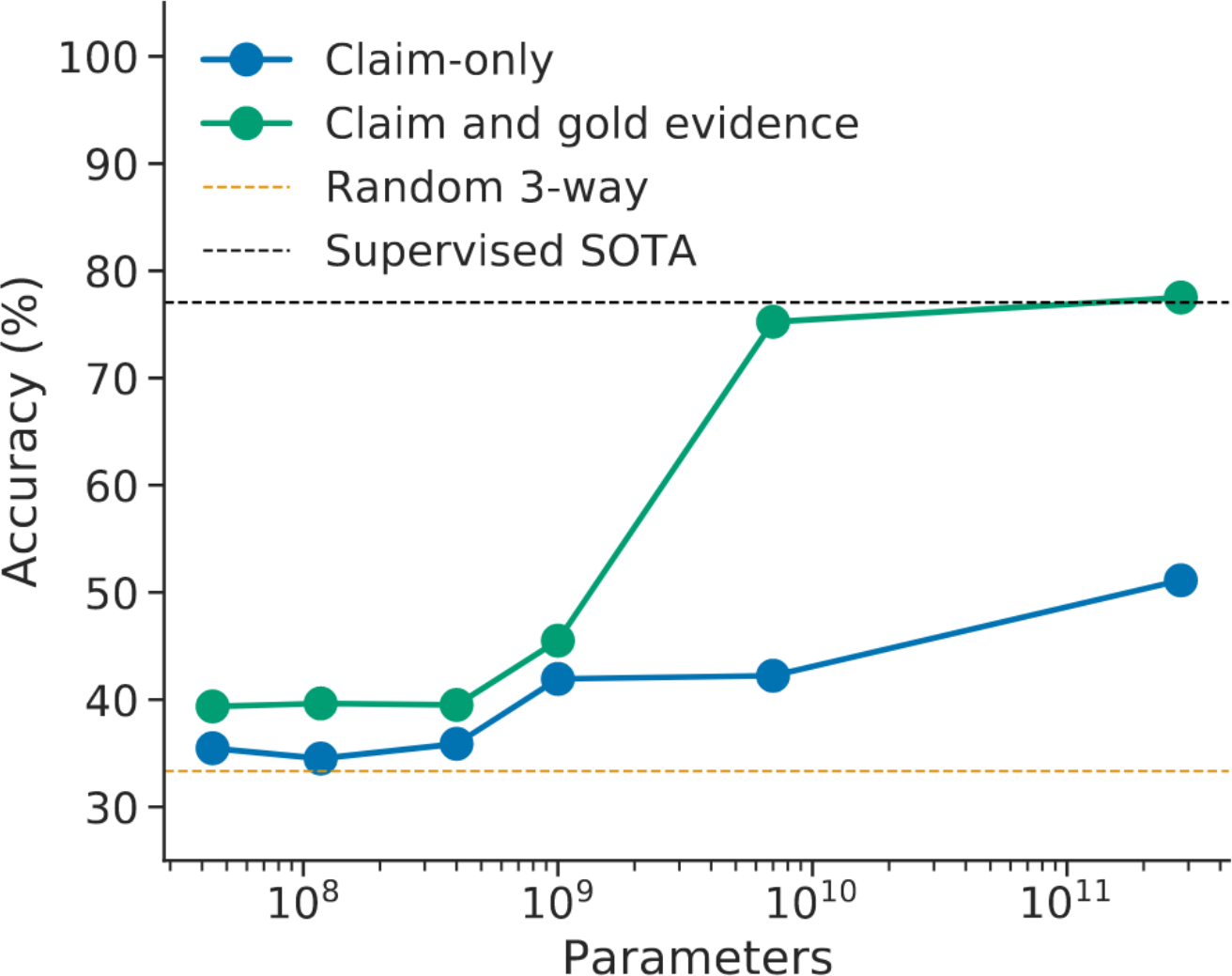
- DeepMind's recent Gopher model exhibits a phase transition on the FEVER task, acquiring the ability to utilize side information (Figure 3):
- Wei et al. (2021) show that instruction-tuning hurts small models but helps large models (see Figure 6).
- Some few-shot tasks such as arithmetic show phase transitions with model size (see Brown et al. (2020), Figure 3.10).
- This researcher shares an anecdote similar to the “grokking” paper.
What This Implies for the Engineering Worldview
In the introduction post to this series, I contrasted two worldviews called Philosophy and Engineering. The Engineering worldview, which is favored by most ML researchers, tends to predict the future by looking at empirical trends and extrapolating them forward. I myself am quite sympathetic to this view, and for this reason I find emergent behavior to be troubling and disorienting. Rather than expecting empirical trends to continue, emergence suggests we should often expect new qualitative behaviors that are not extrapolations of previous trends.
Indeed, in this sense Engineering (or at least pure trend extrapolation) is self-defeating as a tool for predicting the future[2]. The Engineering worldview wants to extrapolate trends, but one trend is that emergent behavior is becoming more and more common. Of the four phase transitions I gave above, the first (storage) occurred around 1995, and the second (compute) occurred around 2015. The last two occurred in 2020 and 2021. Based on past trends, we should expect future trends to break more and more often.[3]
How can we orient ourselves when thinking about the future of AI despite the probability of frequent deviations from past experience? I'll have a lot more to say about this in the next few posts, but to put some of my cards on the table:
- Confronting emergence will require adopting mindsets that are less familiar to most ML researchers and utilizing more of the Philosophy worldview (in tandem with Engineering and other worldviews).
- Future ML systems will have weird failure modes that don't manifest today, and we should start thinking about and addressing them in advance.
- On the other hand, I don't think that Engineering as a tool for predicting the future is entirely self-defeating. Despite emergent behavior, empirical findings often generalize surprisingly far, at least if we're careful in interpreting them. Utilizing this fact will be crucial to making concrete research progress.
From the IBM model authors: “In 1949 Warren Weaver suggested that the problem be attacked with statistical methods and ideas from information theory, an area which he, Claude Shannon, and others were developing at the time (Weaver 1949). Although researchers quickly abandoned this approach, advancing numerous theoretical objections, we believe that the true obstacles lay in the relative impotence of the available computers and the dearth of machine-readable text from which to gather the statistics vital to such an attack. Today, computers are five orders of magnitude faster than they were in 1950 and have hundreds of millions of bytes of storage. Large, machine-readable corpora are readily available.” ↩︎
This is in contrast to using Engineering to build capable and impressive systems today. If anything, recent developments have strongly solidified Engineering’s dominance for this task. ↩︎
This list is probably subject to selection bias and recency effects, although I predict that my point would still hold up for a carefully curated list (for instance, I didn’t include the several ambiguous examples in my count). I would be happy to bet on more phase transitions in the future if any readers wish to take the other side. ↩︎
10 comments
Comments sorted by top scores.
comment by jacob_cannell · 2022-01-12T22:37:08.143Z · LW(p) · GW(p)
Your post suggests that the engineering worldview is somehow inferior to the philosophical worldview for predicting qualitative phase transitions, but you don't present any good evidence for this. In fact all the evidence for qualitative phase transitions you present is from the engineering worldview. At most you present evidence that predicting phase transitions is inherently difficult.
Do you have any evidence of the philosophical worldview making superior predictions on any relevant criteria? If not, I think you should add a clarifying disclaimer.
Replies from: jsteinhardt↑ comment by jsteinhardt · 2022-01-13T20:07:08.974Z · LW(p) · GW(p)
I don't think it's inferior -- I think both of them have contrasting strengths and limitations. I think the default view in ML would be to use 95% empiricism, 5% philosophy when making predictions, and I'd advocate for more like 50/50, depending on your overall inclinations (I'm 70-30 since I love data, and I think 30-70 is also reasonable, but I think neither 95-5 or 5-95 would be justifiable).
I'm curious what in the post makes you think I'm claiming philosophy is superior. I wrote this:
> Confronting emergence will require adopting mindsets that are less familiar to most ML researchers and utilizing more of the Philosophy worldview (in tandem with Engineering and other worldviews).
This was intended to avoid making a claim of superiority in either direction.
comment by dkirmani · 2022-01-12T05:57:55.771Z · LW(p) · GW(p)
What's the relationship between grokking and Deep Double Descent?
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-12T15:56:01.579Z · LW(p) · GW(p)
They may be the same phenomena?
Replies from: jsteinhardt↑ comment by jsteinhardt · 2022-01-13T20:24:55.377Z · LW(p) · GW(p)
I'm not sure I get what the relation would be--double descent is usually with respect to the model size (vs. amout of data), although there is some work on double descent vs. number of training iterations e.g. https://arxiv.org/abs/1912.02292. But I don't immediately see how to connect this to grokking.
(I agree they might be connected, I'm just saying I don't see how to show this. I'm very interested in models that can explain grokking, so if you have ideas let me know!)
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-13T21:27:55.109Z · LW(p) · GW(p)
(That arxiv link isn't working btw.)
It makes sense that GD will first find high complexity overfit solutions for an overcomplete model - they are most of the high test scoring solution space. But if you keep training, GD should eventually find a low complexity high test scoring solution - if one exists - because those solutions have an even higher score (with some appropriate regularization term). Obviously much depends on the overparameterization and relative reg term strength - if it's too strong GD may fail or at least appear to fail as it skips the easier high complexity solution stage. I thought that explanation of grokking was pretty clear.
I was also under the impression that double descent is basically the same thing, but viewed from the model complexity dimension. Initially in the under-parameterized regime validation error decreases with model complexity up to a saturation point just below where it can start to memorize/overfit, then increases up to a 2nd worse overfitting saturation point, then eventually starts to decrease again heading into the strongly overparameterized regime (assuming appropriate mild regularization).
In the strongly overparameterized regime 2 things are happening: firstly it allows the model capacity to more easily represent a distribution of solutions rather than a single solution, and it also effectively speeds up learning in proportion by effectively evaluating more potential solutions (lottery tickets) per step. Grokking can then occur, as it requires sufficient overpamaterization (whereas in the underparameterized regime there isn't enough capacity to simultaneously represent a sufficient distribution of solutions to smoothly interpolate and avoid getting stuck in local minima)
Looking at it another way: increased model complexity has strong upside that scales nearly unbounded with model complexity, coupled with the single downside of overfitting which saturates at around data memoriation complexity.
Replies from: jsteinhardt↑ comment by jsteinhardt · 2022-01-13T23:56:48.902Z · LW(p) · GW(p)
But if you keep training, GD should eventually find a low complexity high test scoring solution - if one exists - because those solutions have an even higher score (with some appropriate regularization term). Obviously much depends on the overparameterization and relative reg term strength - if it's too strong GD may fail or at least appear to fail as it skips the easier high complexity solution stage. I thought that explanation of grokking was pretty clear.
I think I'm still not understanding. Shouldn't the implicit regularization strength of SGD be higher, not lower, for fewer iterations? So running it longer should give you a higher-complexity, not a lower-complexity solution. (Although it's less clear how this intuition pans out once you already have very low training loss, maybe you're saying that double descent somehow kicks in there?)
Replies from: jacob_cannell, jsteinhardt↑ comment by jacob_cannell · 2022-01-14T07:59:46.866Z · LW(p) · GW(p)
I think grokking requires explicit mild regularization (or at least, it's easier to model how that leads to grokking).
The total objective is training loss + reg term. Initially the training loss totally dominates, and GD pushes that down until it overfits (finding a solution with near 0 training loss balanced against reg penalty). Then GD bounces around on that near 0 training loss surface for a while, trying to also reduce the reg term without increasing the training loss. That's hard to do, but eventually it can find rare solutions that actually generalize (still allow near 0 training loss at much lower complexity). Those solutions are like narrow holes in that surface.
You can run it as long as you want, but it's never going to ascend into higher complexity regions than those which enable 0 training loss (model entropy on order data set entropy), the reg term should ensure that.
↑ comment by jsteinhardt · 2022-01-14T00:00:34.651Z · LW(p) · GW(p)
Okay I think I get what you're saying now--more SGD steps should increase "effective model capacity", so per the double descent intuition we should expect the validation loss to first increase then decrease (as is indeed observed). Is that right?
comment by hawkebia (hawk-ebia) · 2022-03-13T04:52:36.384Z · LW(p) · GW(p)
Heuristics explain some of the failure to predict emergent behaviours. Much of Engineering relies on "perfect is the enemy of good" thinking. But, extremely tiny errors and costs, especially the non-fungible [LW · GW] types, compound and interfere at scale. One lesson may be that as our capacity to model and build complex systems improves, we simultaneously reduce the number of heuristics employed.
Material physical systems do use thresholds, but they don't completely ignore tiny values (eg. neurotransmitter molecules don't just disappear at low potential levels).