AtP*: An efficient and scalable method for localizing LLM behaviour to components
post by Neel Nanda (neel-nanda-1), János Kramár (janos-kramar), Tom Lieberum (Frederik), Rohin Shah (rohinmshah) · 2024-03-18T17:28:37.513Z · LW · GW · 0 commentsThis is a link post for https://arxiv.org/abs/2403.00745
Contents
No comments
Authors: János Kramár, Tom Lieberum, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mechanistic interpretability team, from core contributors János Kramár and Tom Lieberum
Abstract:
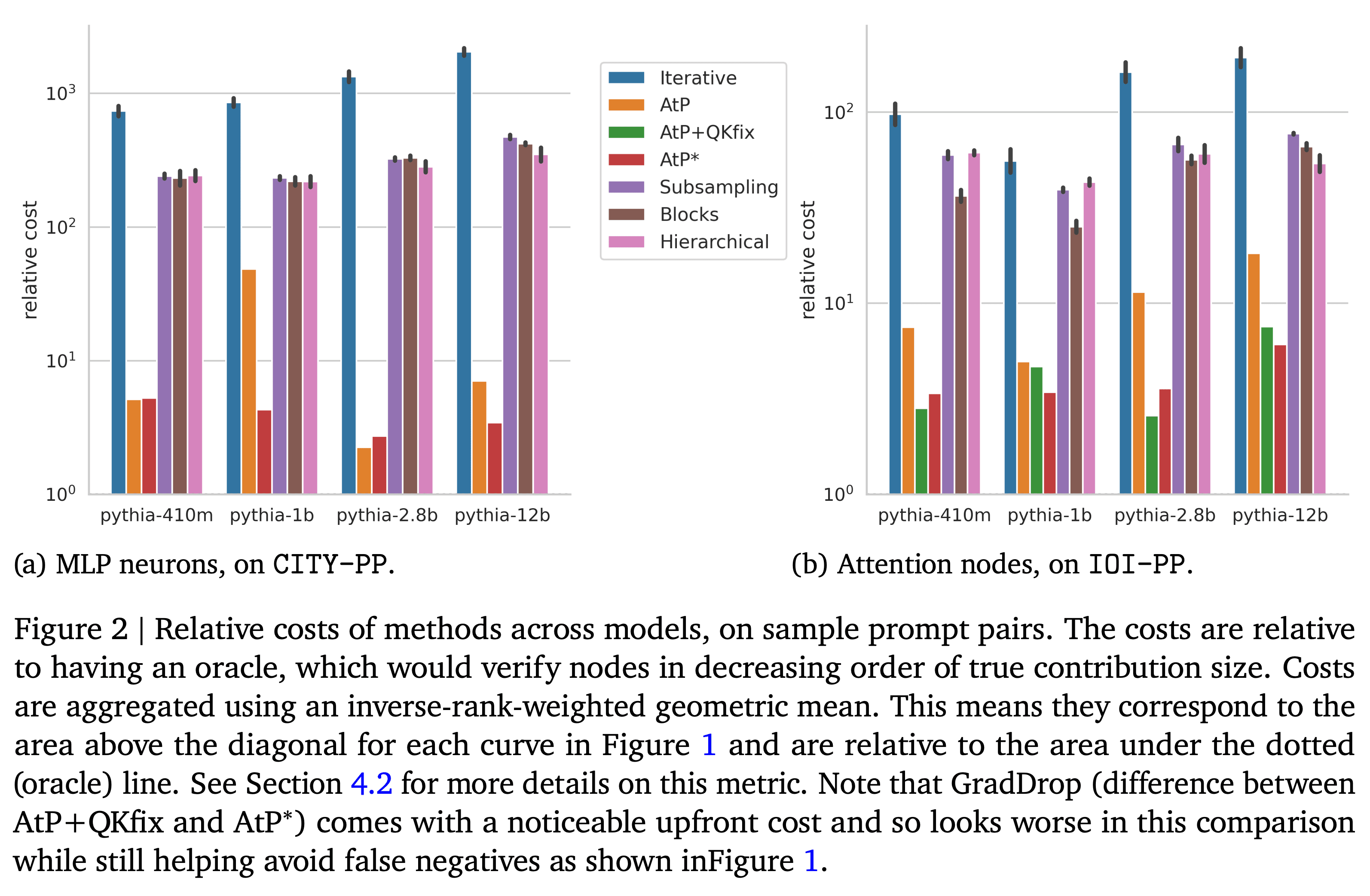
Activation Patching is a method of directly computing causal attributions of behavior to model components. However, applying it exhaustively requires a sweep with cost scaling linearly in the number of model components, which can be prohibitively expensive for SoTA Large Language Models (LLMs). We investigate Attribution Patching (AtP), a fast gradient-based approximation to Activation Patching and find two classes of failure modes of AtP which lead to significant false negatives. We propose a variant of AtP called AtP*, with two changes to address these failure modes while retaining scalability. We present the first systematic study of AtP and alternative methods for faster activation patching and show that AtP significantly outperforms all other investigated methods, with AtP* providing further significant improvement. Finally, we provide a method to bound the probability of remaining false negatives of AtP* estimates.
0 comments
Comments sorted by top scores.