Measuring Learned Optimization in Small Transformer Models
post by J Bostock (Jemist) · 2024-04-08T14:41:27.669Z · LW · GW · 0 commentsContents
Methods Pretraining on Sequence Prediction Measuring Optimization Results Optimization vs RL Success Rate Cross-Objective Evaluation Optimization vs Impact Model Self-Evaluation Conclusions Alex Turner's Existing Work Appendices Appendix A: Impact and Differential Impact Derivation of Imp Differential Impact Appendix B: Proofs Derivation and proof of Imp≥Impmin Derivation of Differential Impact Derivation of Multivariate Differential Impact and Optimization Appendix C: Supplementary Plots Other Ways to Visualize Impact Plots Example training runs from ngood = 4 Example figures summarizing training runs: None No comments
This is original, independent research carried out in March and April of 2024.
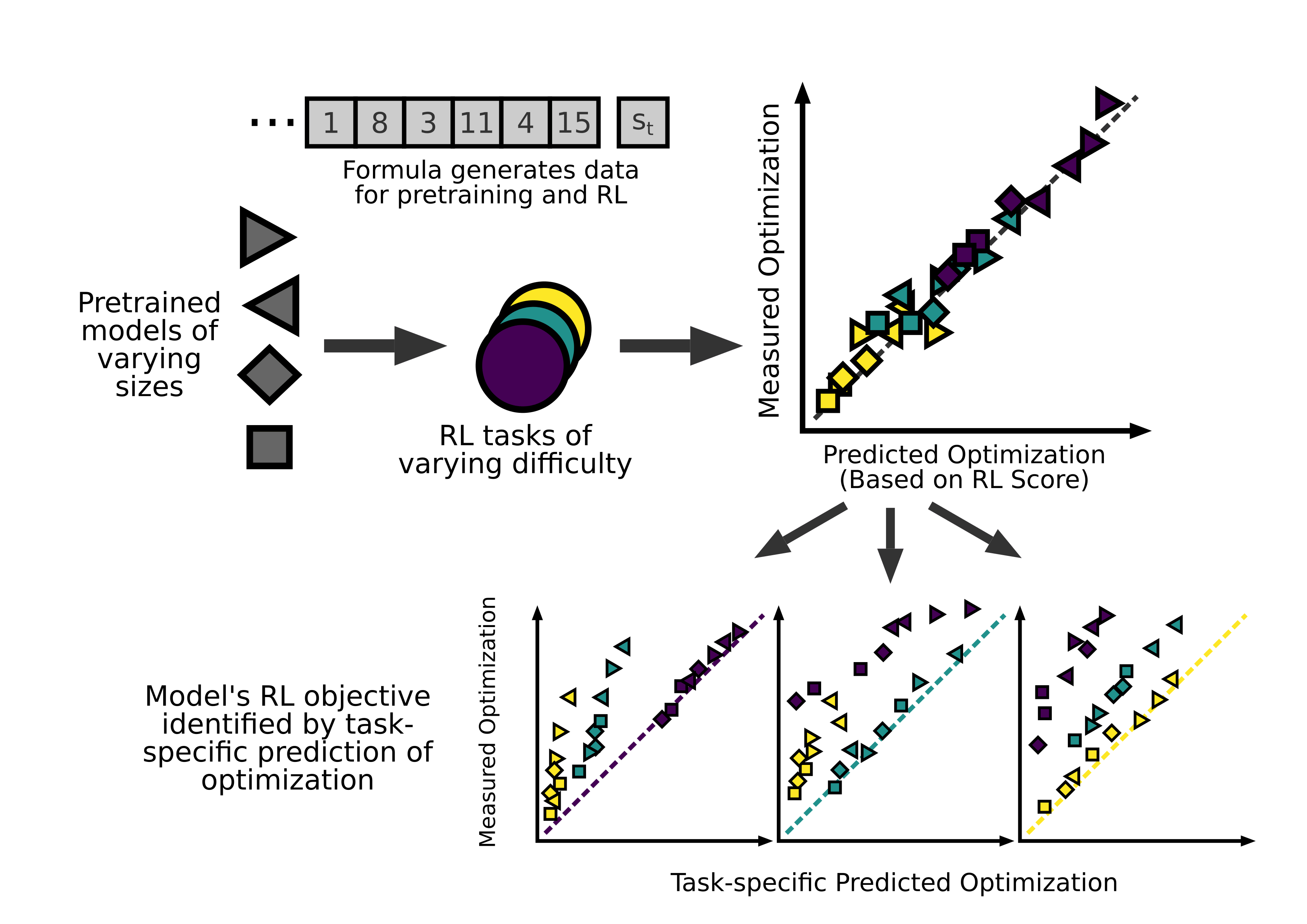
The degree to which a a policy optimizes the future can be quantified mathematically. A set of of very small transformer models were pretrained to predict the next token in a mathematical sequence, then subjected to reinforcement learning finetuning.
The optimizing power of each model can be predicted with high accuracy based on each model's score on its own RL task. By comparing predictions of optimization based on scores on each different RL task, a model's original reinforcement objective can be identified.
A related measure for impact can also be derived mathematically, and given a theoretical lower bound based on RL score. This gives further information about model behavior, and allows for the same analysis as the measure of optimization.
I also investigate the possibility of getting models to self-evaluate optimization and impact, with limited success.
Methods
Pretraining on Sequence Prediction
I defined a simple mathematical sequence defined by the following stochastic recurrence relation. This produces a pseudo-random but (to 98%) predictable sequence, alternating between elements of on even values of and on odd values of .
I then trained a small encoder-only transformer model to predict the next element in the sequence given the previous 20 elements of the sequence.
This was followed by a reinforcement-learning phase in which the transformer was used to generate the next token on odd values of only, and the recurrence relation was used to generate the value of . If was in , this was used as a "successful" example to reinforce the model. I used a temperature of 1 when generating these sequences to introduce some randomness, but the temperature was reduced to 0 during evaluations and when calculating optimization.
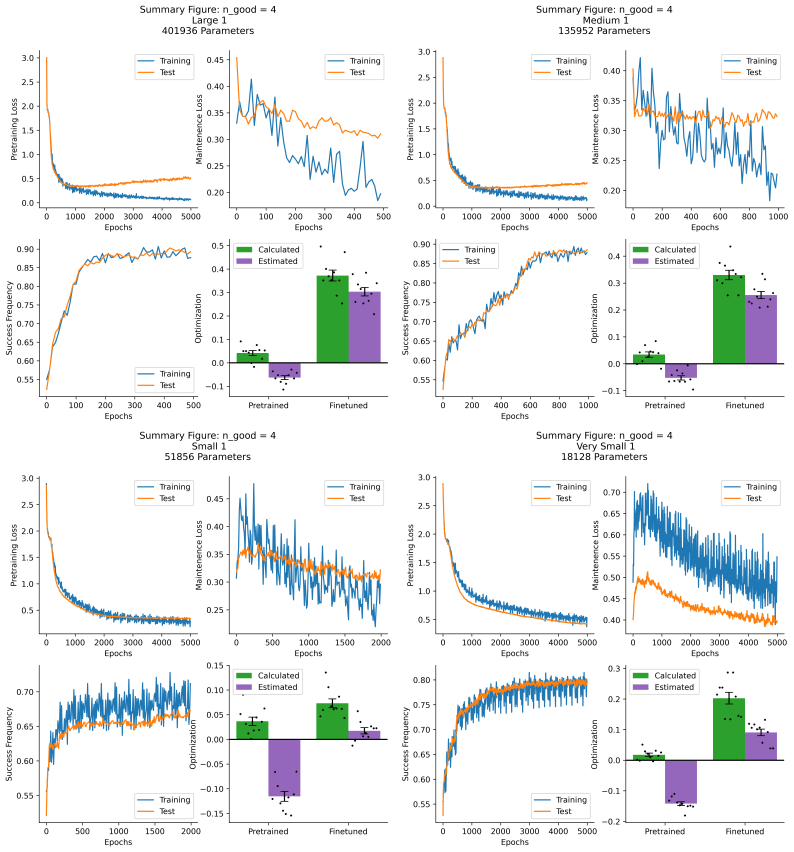
A small amount of "maintenance" training (much lower learning rate) was used during this phase to ensure that model performance on the predictive tasks for even values of was maintained. Without this I saw rapid loss of performance on the "maintenance" dataset. I also found that I was unable to include "unsuccessful" examples (i.e. where ) with even a tiny negative learning rate, as this caused worsened performance at all tasks. Here is a typical set of results from training and evaluation:
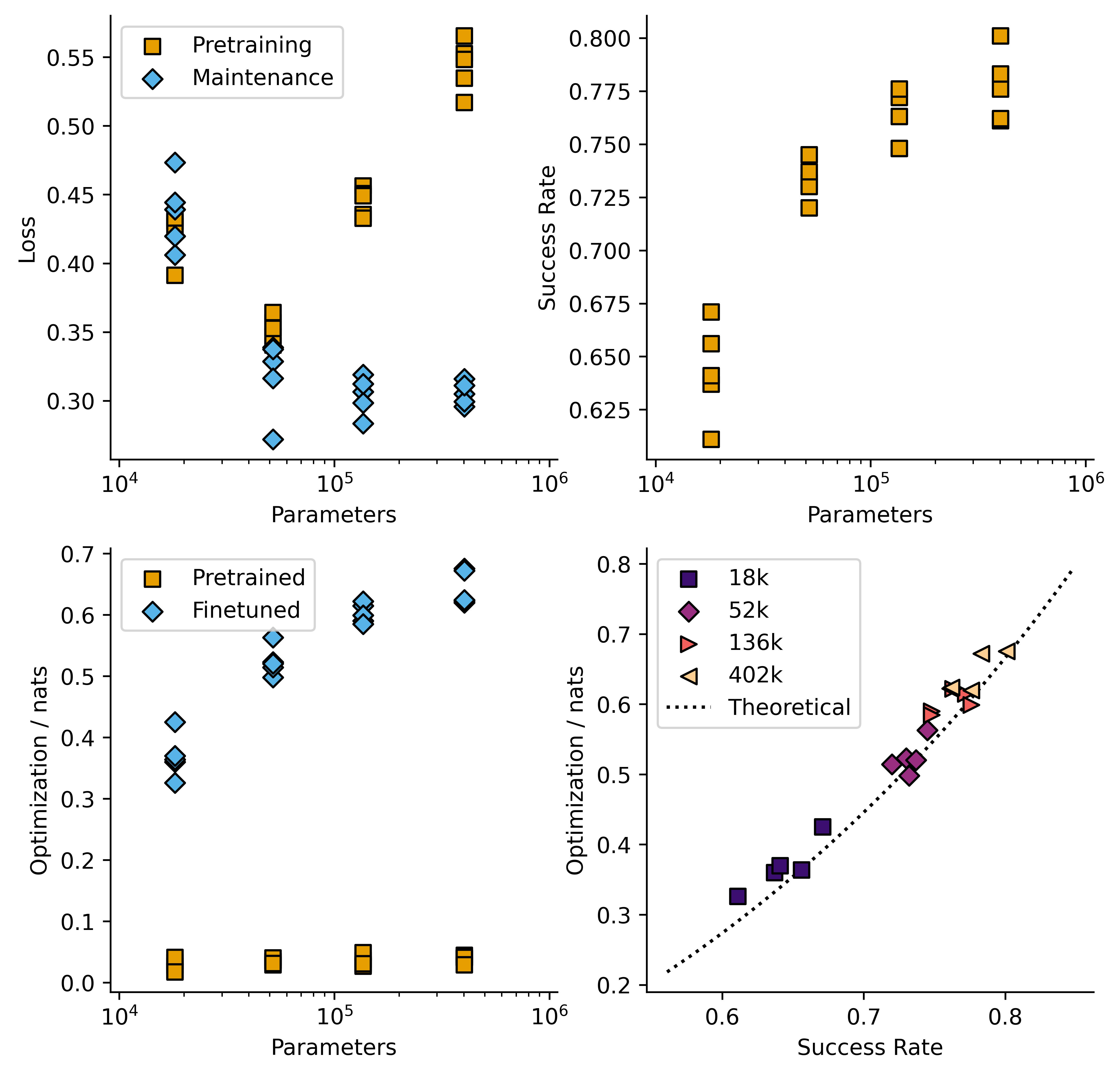
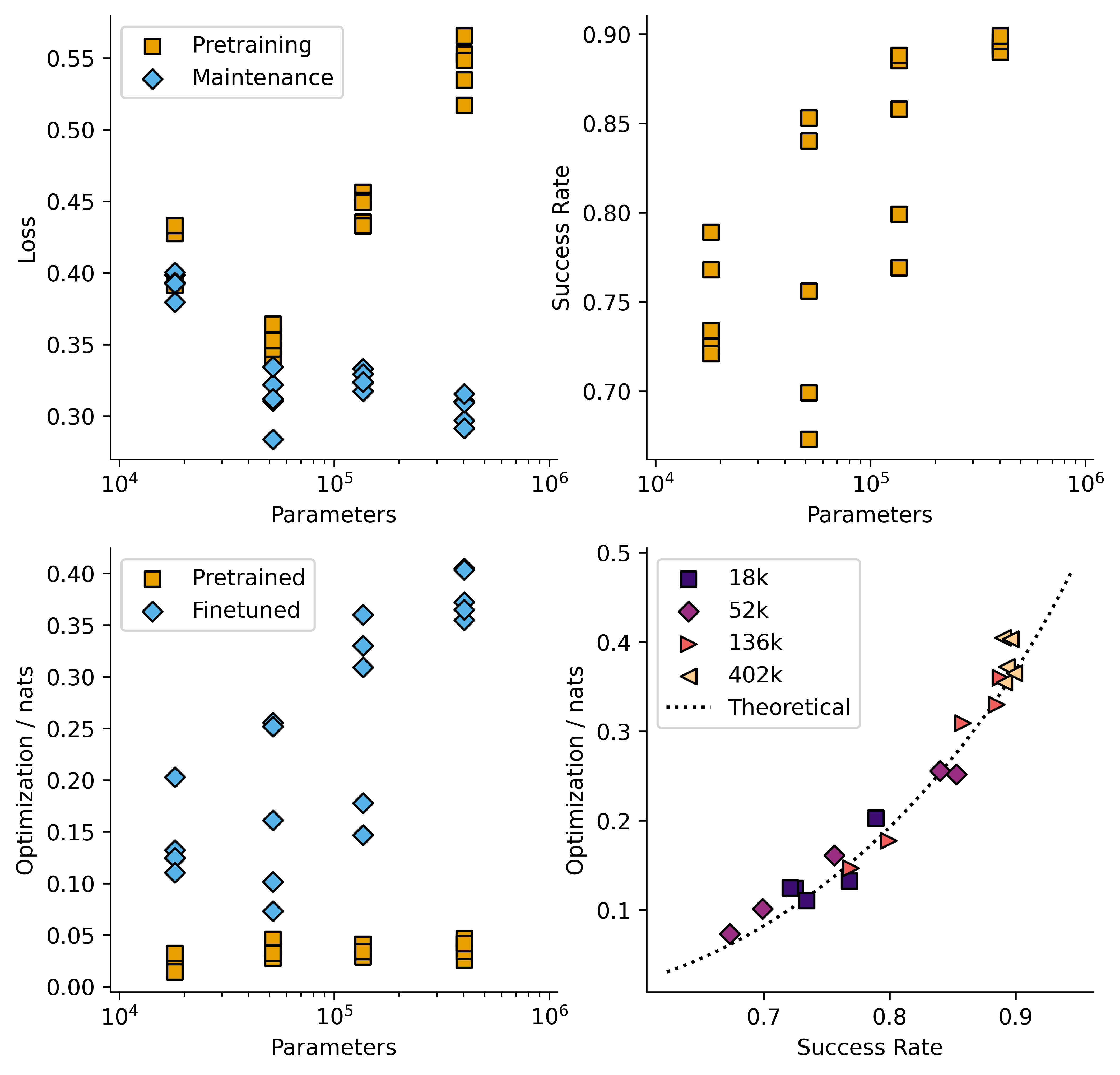
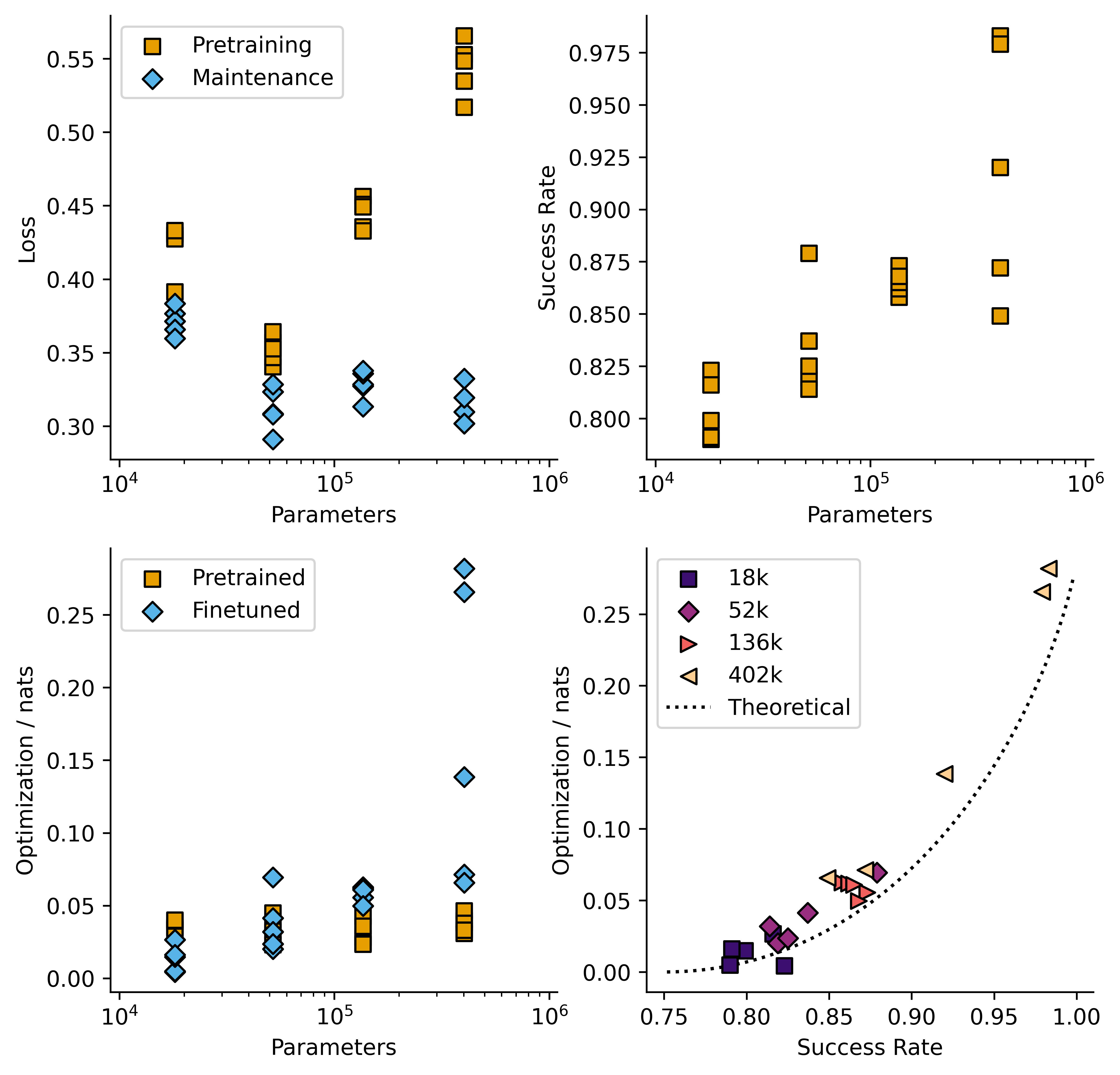
I carried out this training on models per size for four model sizes between 18k and 402k parameters, giving the following plot:
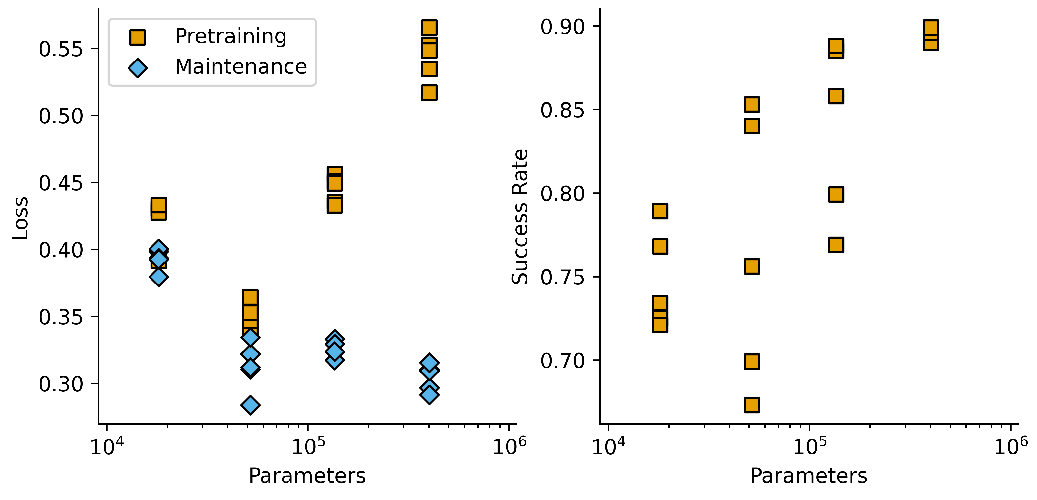
Pretraining loss increases over the last few model sizes, and the loss/time plots (some of which I have put in the Supplementary Information at the bottom of this post) showed signs of overfitting in the large models. Regularization was employed during training (0.01 weight decay in an AdamW optimizer, 10% dropout rate for neurons) so perhaps a larger dataset size is required to totally avoid this.
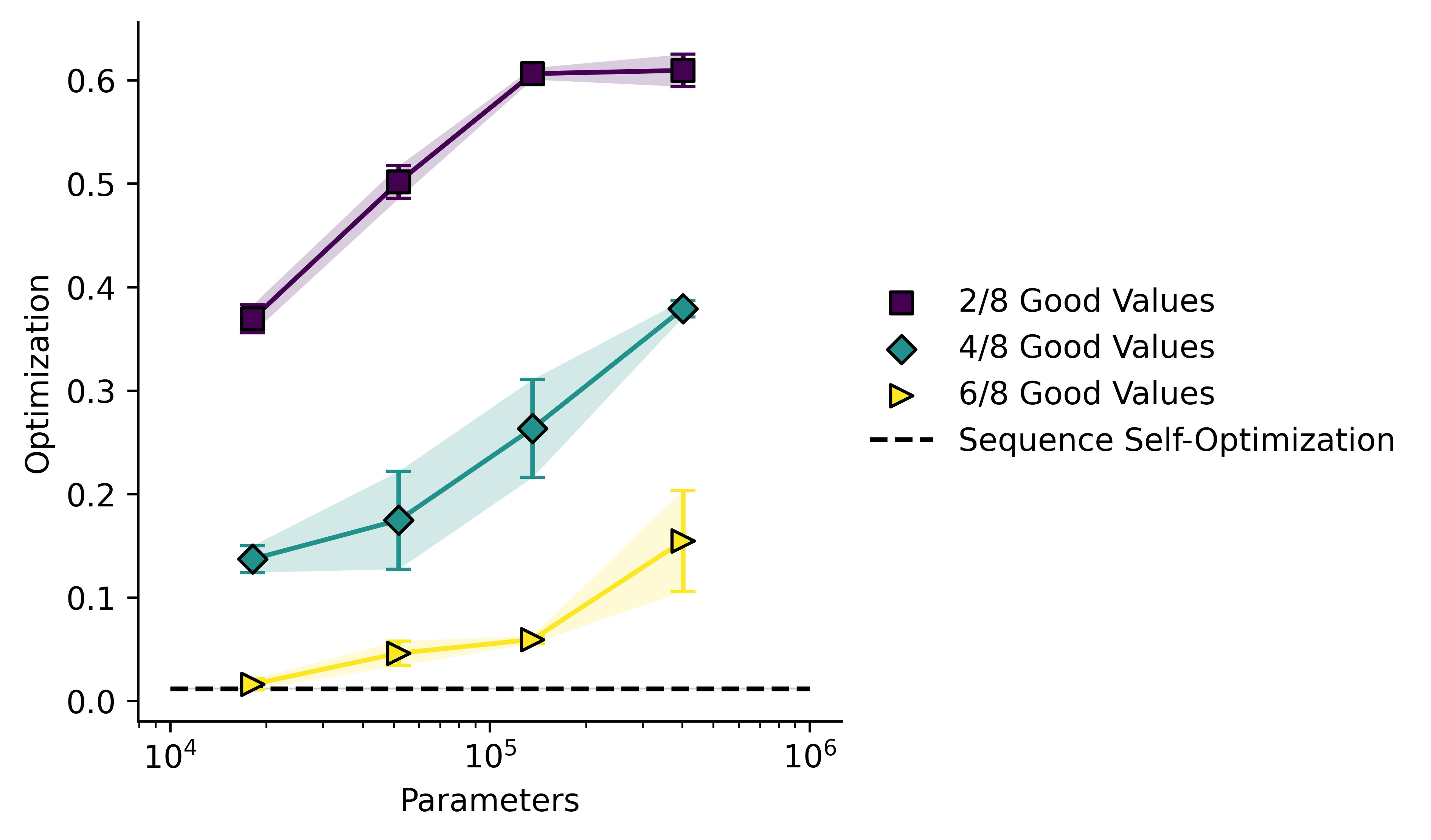
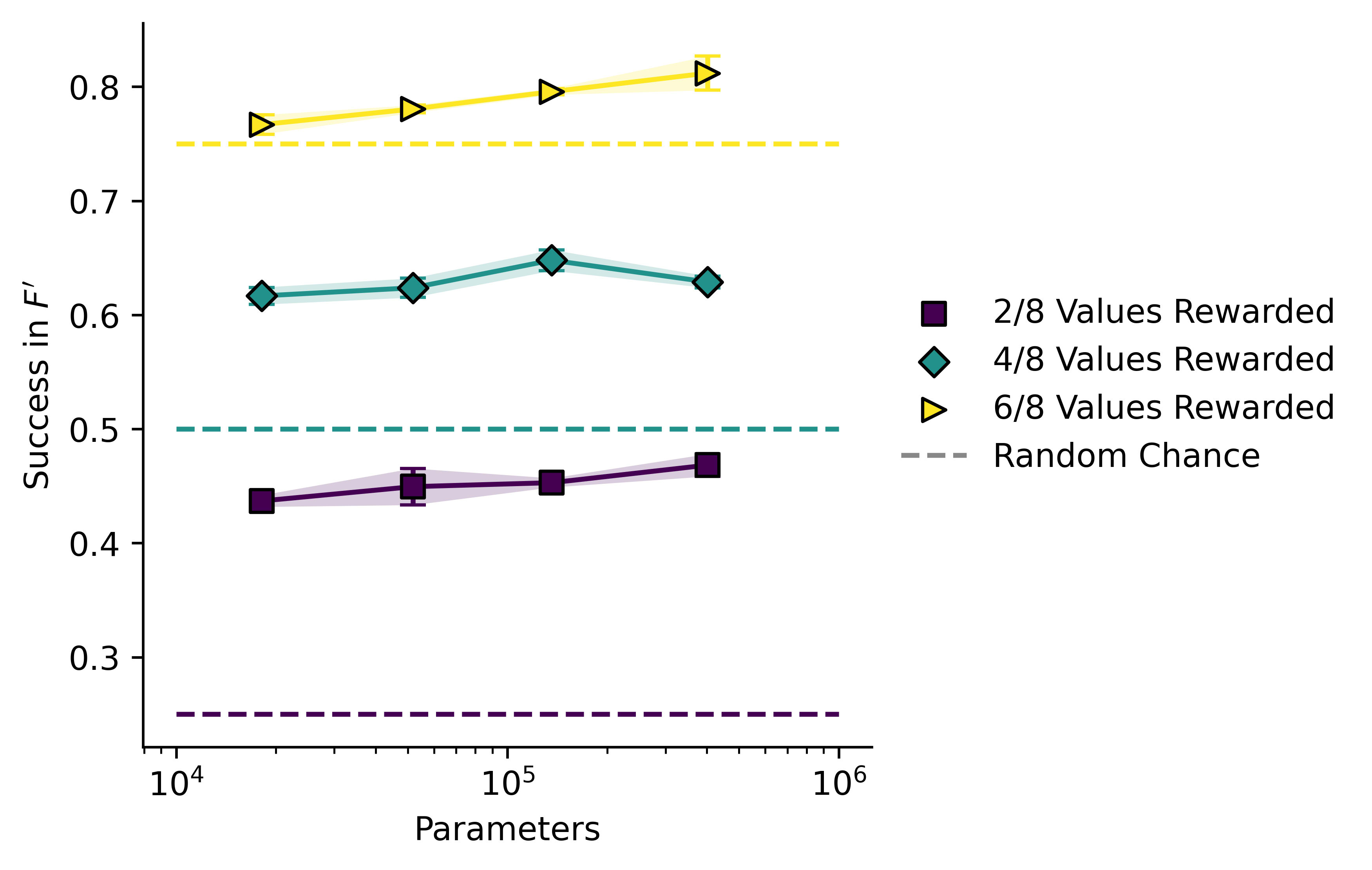
I then repeated the RL phase twice, once with being reinforced, ( = 2) and once with being reinforced ( = 6). Here is a plot of success rate against model size across all three conditions.
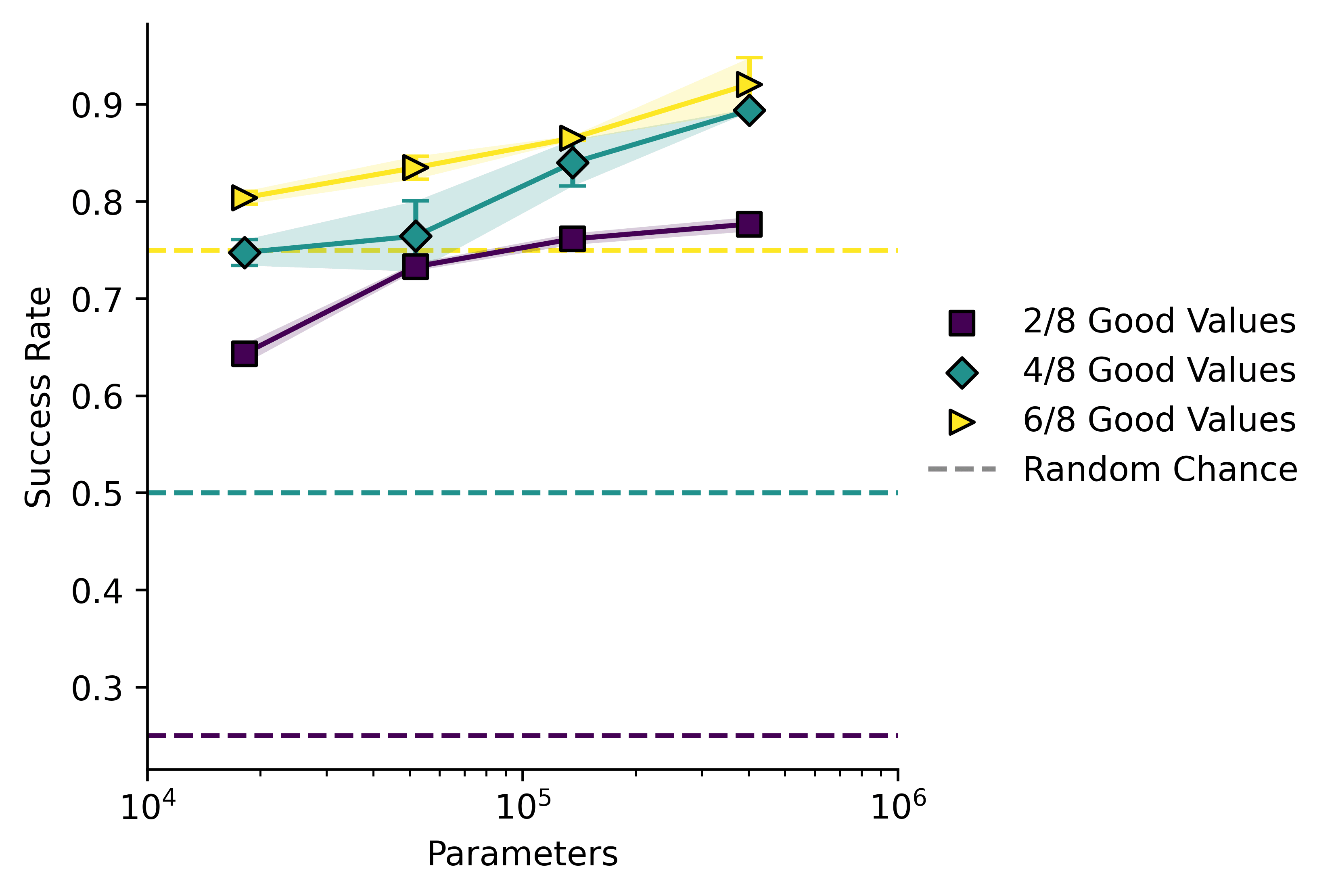
This plot shows mean standard error. In all cases model performance is a lot better than chance, and increases with model size.
Measuring Optimization
I used a Monte Carlo simulation to measure the nats of optimization that are being applied to using the split-history method I've previously outlined. This involves taking the difference in entropy between two distributions:
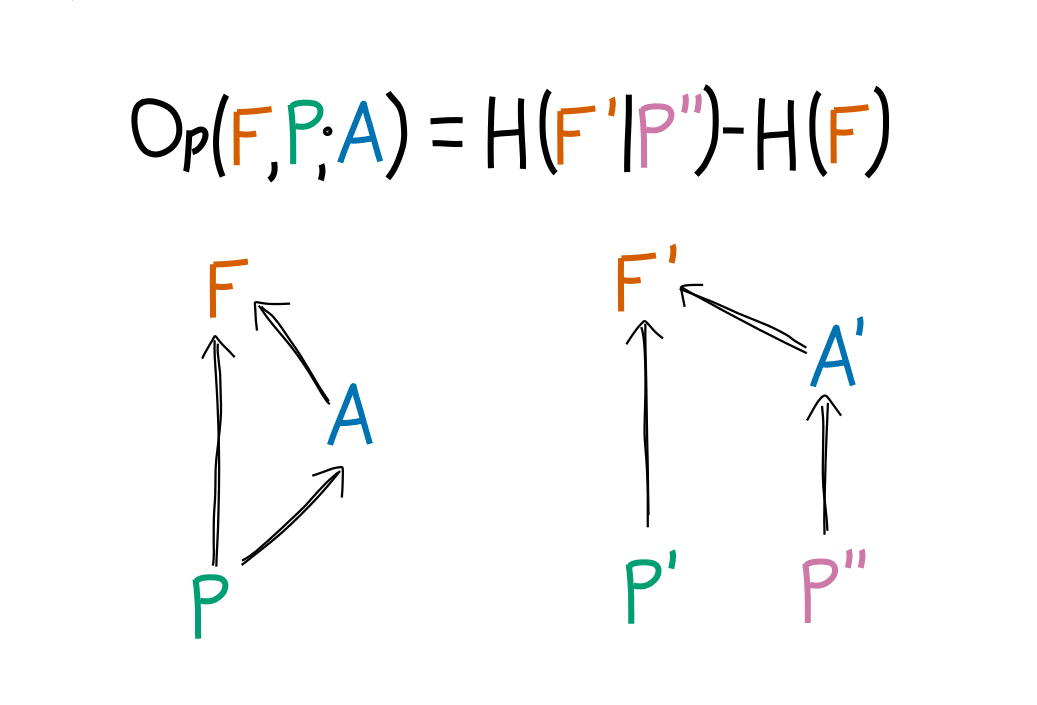
The algorithm in practice is this:
- Take a bunch of sequence examples from the testing data, ensuring that is odd.
- Feed them into the models to get a value for , append to the sequence.
- Use the sequence-generator to get a set of values for
- Look at the entropy of the resulting distribution over , this is the optimized entropy.
- For each sequence from the training data, and get a value of from this.
- Repeat Steps 3-4 with the entire data set as prepended to , get one sample of "unoptimized" entropy
- Repeat Steps 5-6 with each sequence from the initial dataset, take the average unoptimized entropy
- Optimization = unoptimized entropy - optimized entropy
Here is a schematic illustration:
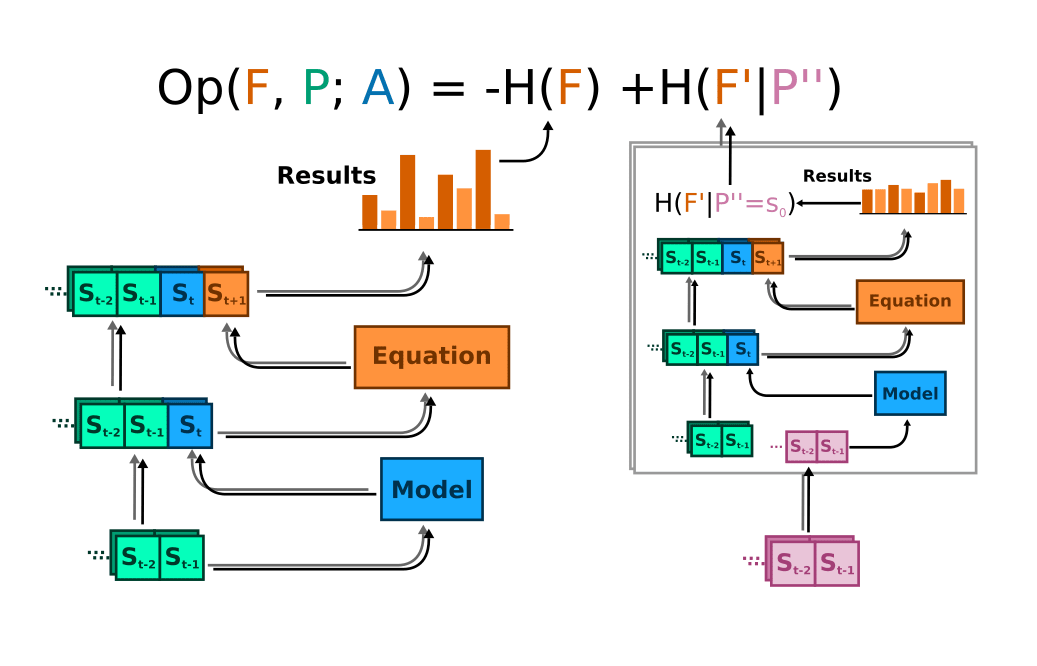
I ran this calculation 10 times with 200 sequences in and took an average to get an idea of the model's optimizing capability. I also tested the sequence-generating function's self-optimization.
The fact that the sequence is optimizing itself mostly just amounts to saying that it is not a random walk, which we already knew. It is a good sanity check that all of the models get values either equal to or above this, and that optimization improves with model size.
Results
Optimization vs RL Success Rate
Optimization is calculated as the entropy difference of two distributions. Let us consider three parameters: : the number of possible outcomes; : the proportion of outcomes which are "successes"; and : the chance that the model achieves a successful outcome.
Assuming the model is "ambivalent" over successful outcomes, and likewise ambivalent over failed outcomes, then the value of should be equal to . If we then assume that all outcomes are equally likely when the model's outputs are "randomized", then is just . If we take the difference we get the following expression:
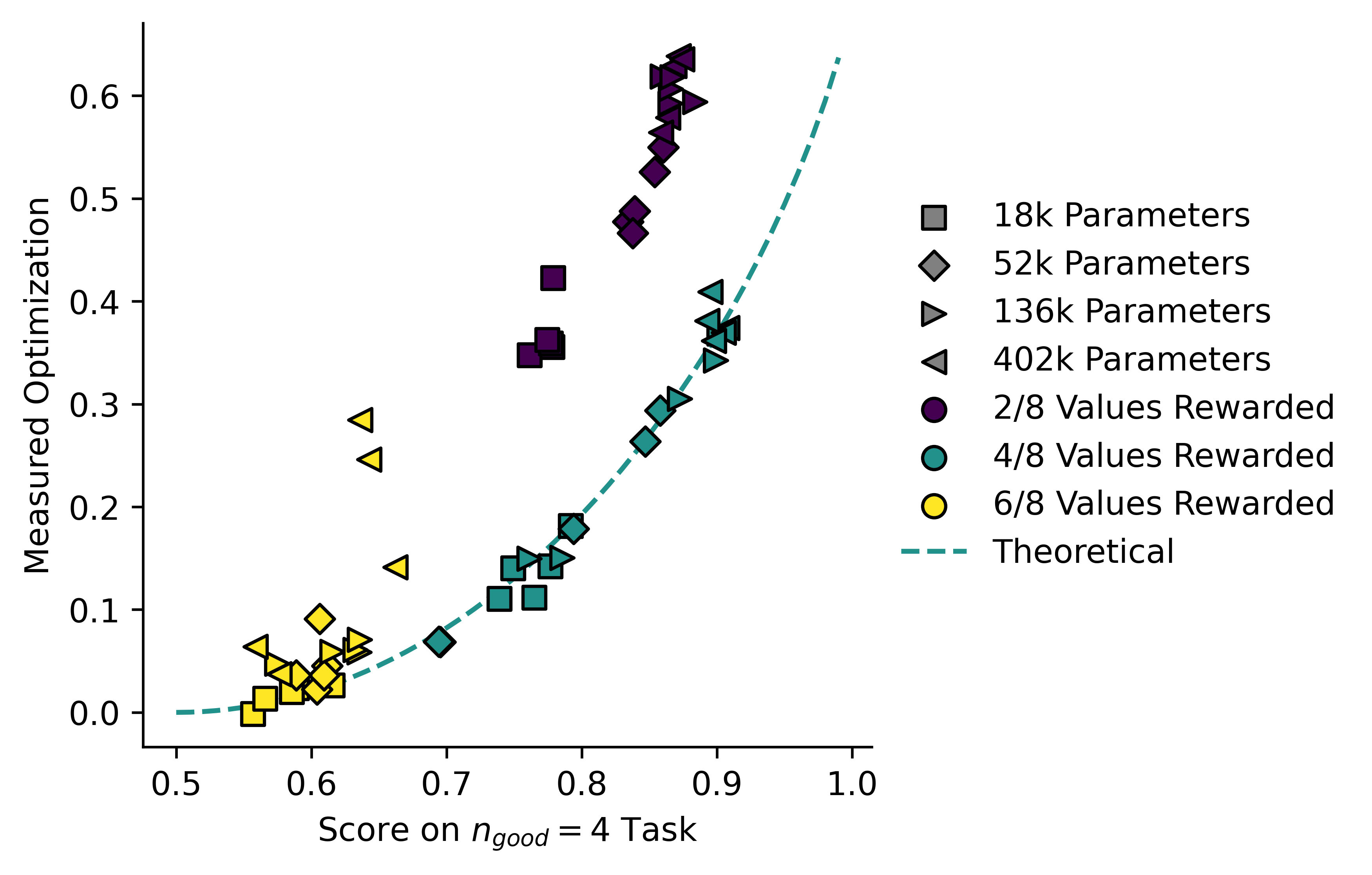
Now I can plot this theoretical value for against for , and also plot all of the models on the same axes. Since we see a lot of run-to-run variation in model performance, I'll plot the raw data per model rather than statistics.
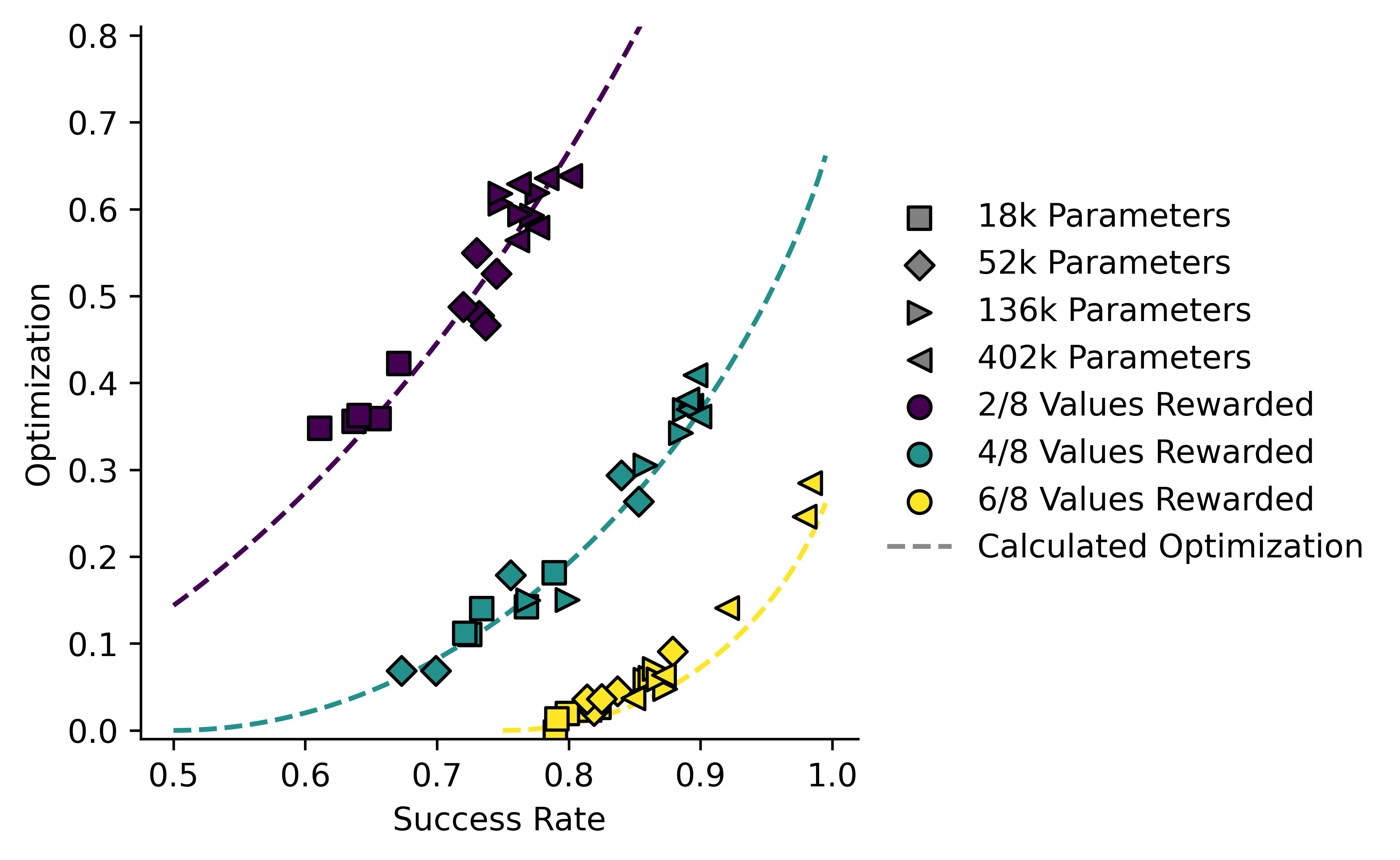
I tried to find some galaxy-brained variable change which would make those three curves the same, but I couldn't. Instead I will just plot the predicted value of (based on their success rate) for each model against the actual value:
In theory none of the models should fall below the dashed line representing the equation derived above. In practice they do. Some of this is error in measurements, but I'm sure some of it is also due to errors in my assumptions. In particular the assumption that is completely flat is unlikely to hold.
On the other hand, there there is no reason at all why the models shouldn't fall quite far above the theoretical line. Consider the case, so successful values are. If the model ends up with a 85:15 ratio of values 2 and 3 for (and never gets any other number, which is impossible in this specific case but that's not important for my point) then it will have a success rate of 0.85, which implies an of 0.03, but its actual will be 1.66!
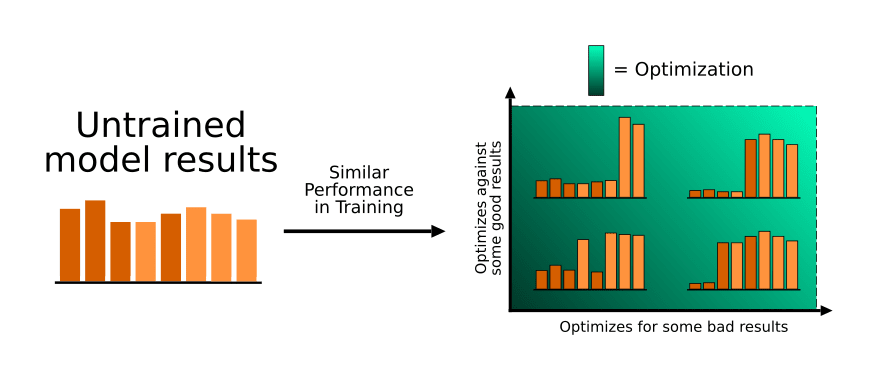
For a given training performance (in this case I've tried to make them all ~75% correct) the model might do one of several things:
- Optimize for reinforced results and against non-reinforced results in an unbiased way
- Optimize against non-reinforced results correctly, but only optimize for some of the successful results
- Optimize for reinforced results correctly, but only optimize against some of the non-reinforced results
- Behave in such a way that certain reinforced results are optimized against and certain non-reinforced results are optimized for.
The last three are examples of one type of inner misalignment. All three are characterized by excess optimization compared to the "correct" answer.
Cross-Objective Evaluation
The fact that most of the models don't sit far above the line shows that the RL is doing its job! They are (mostly) pursuing the training objective faithfully, without picking up on other objectives. I simulate what might happen if a model picks up on an "incorrect" objective by cross-evaluating models on each others' tasks:
Now it becomes obvious that the -trained models are behaving correctly whereas the other models are not. This is important since a model trained on the task will typically have a good score on the task, sometimes even higher than a similarly-sized model trained on the task (!) but this plot clearly shows us that something is going wrong.
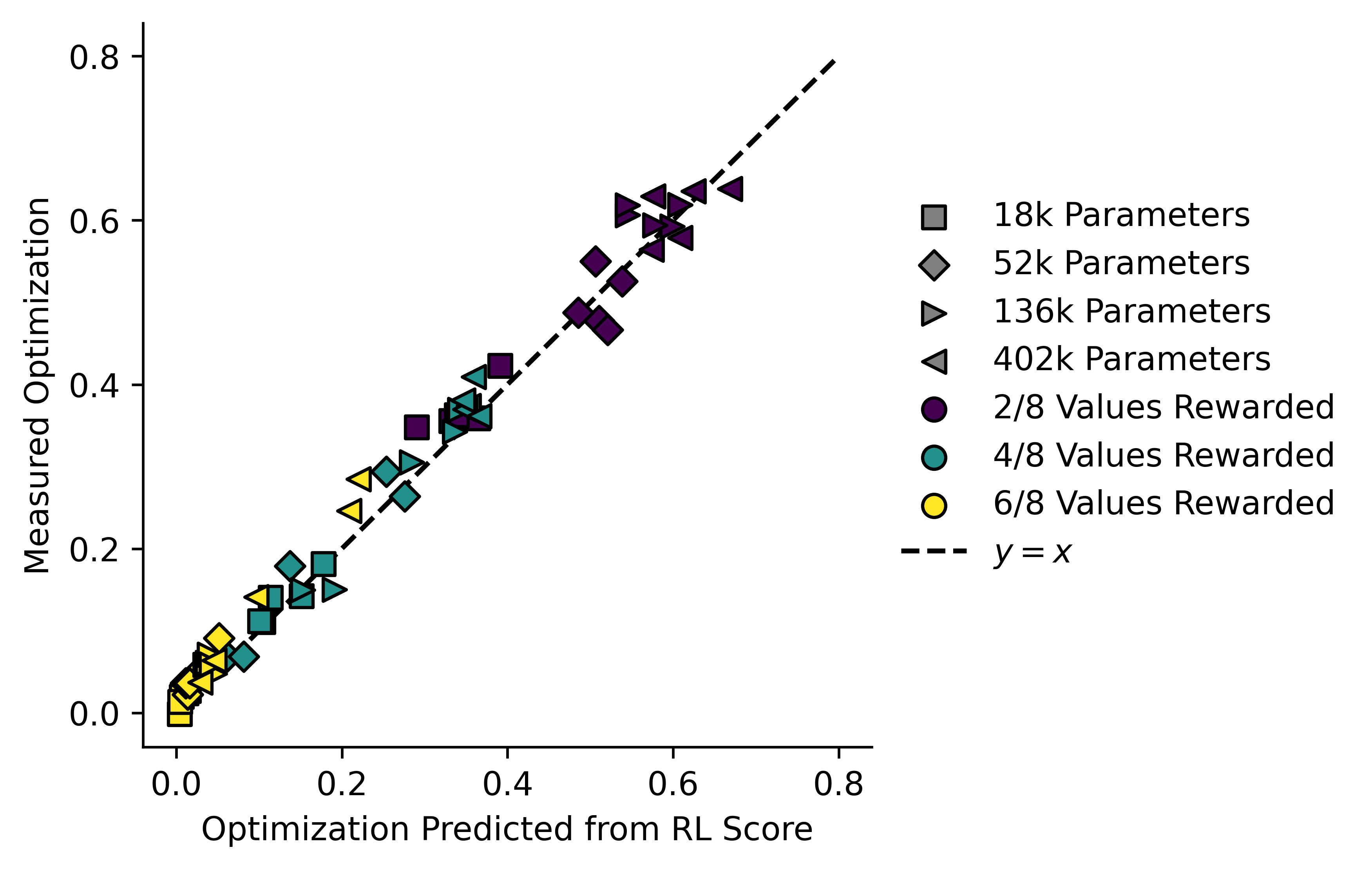
It becomes even clearer if we instead take the value of implied by the formula from above, and plot it against the actual value of . Here are the results for all three tasks:
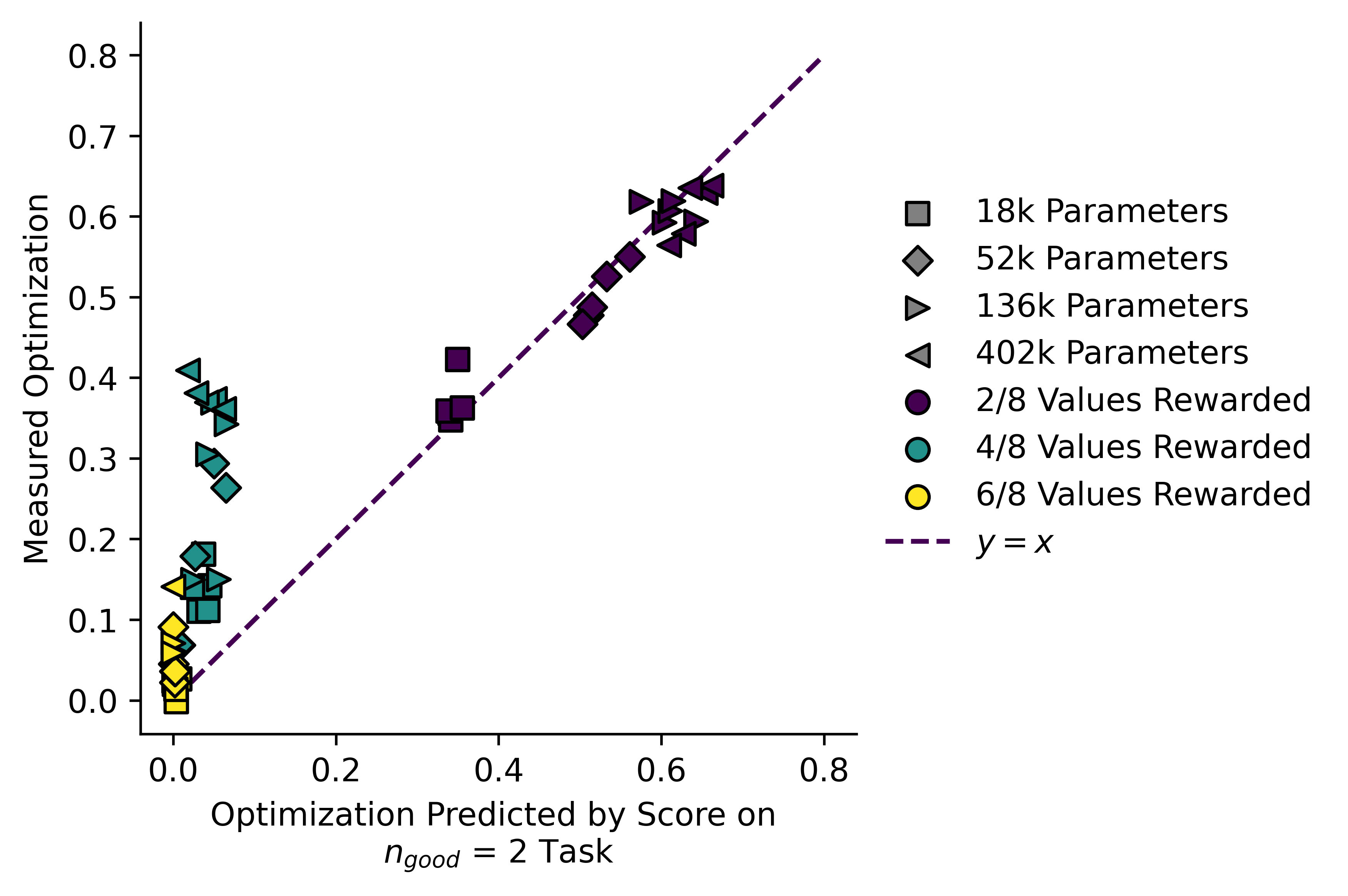
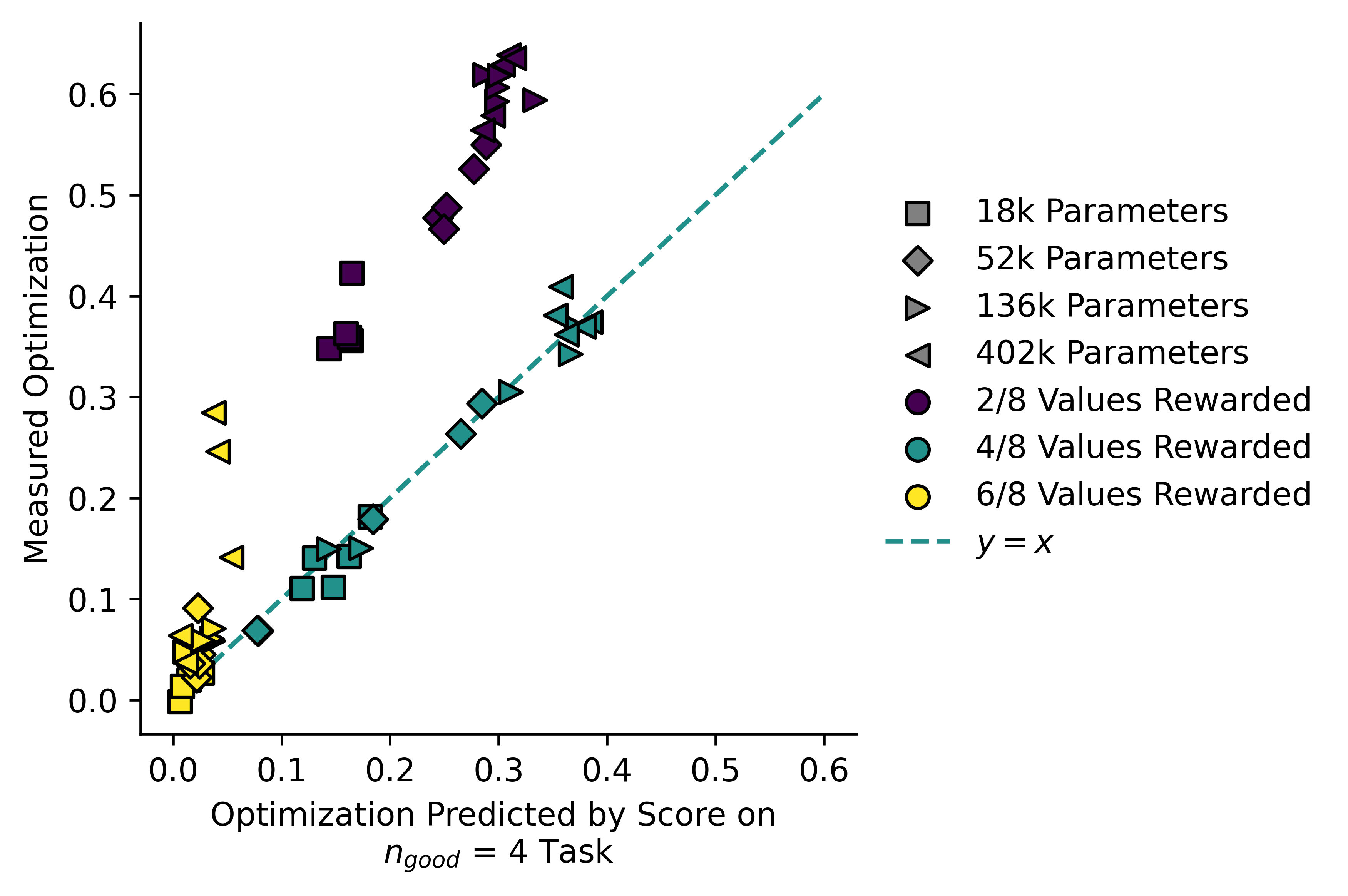
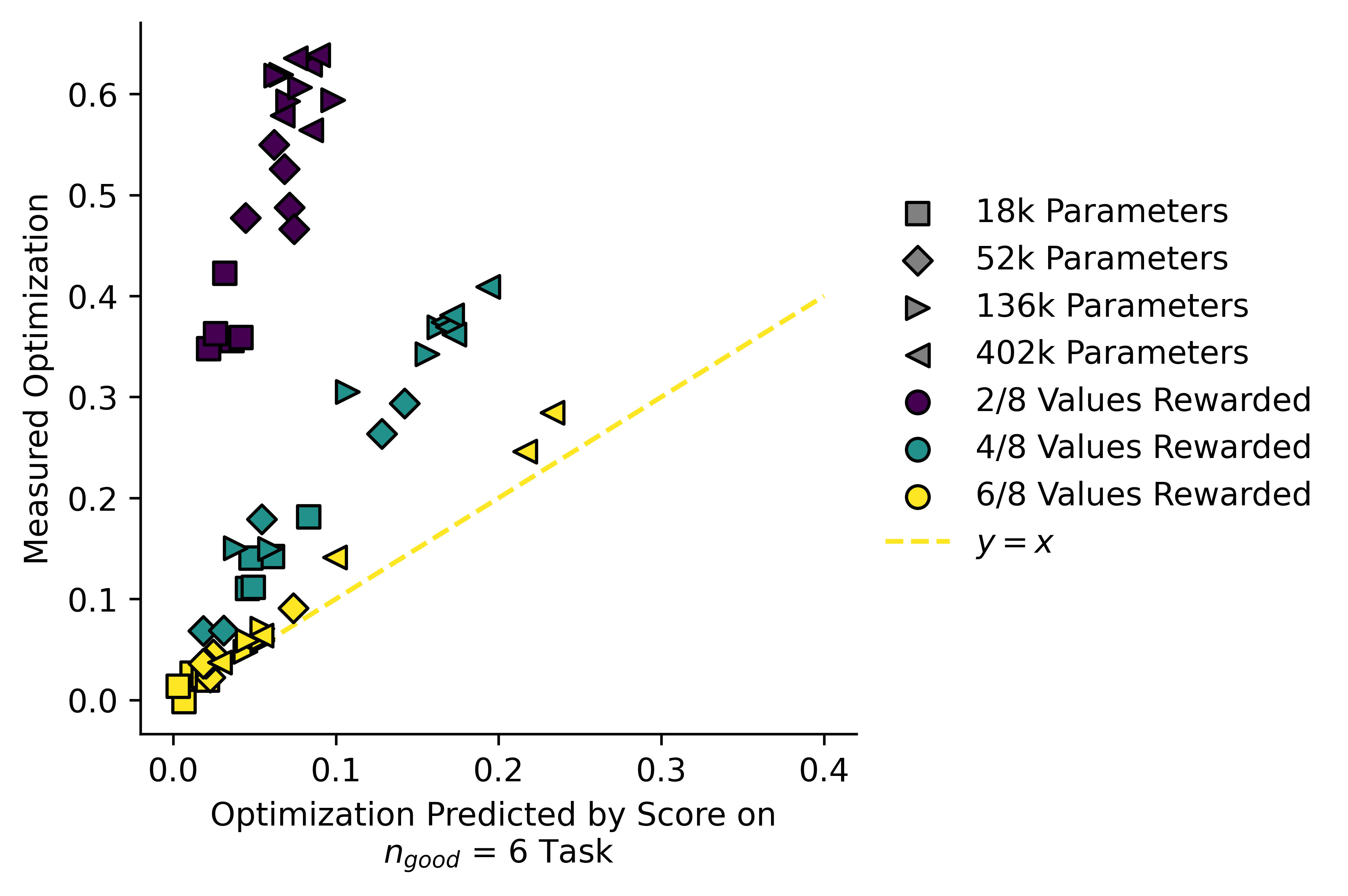
By comparing implied and measured , we can separate the models trained on a given reward signal from ones trained on a different reward signal, even when one of the reward signals is a subset of the other.
Optimization vs Impact
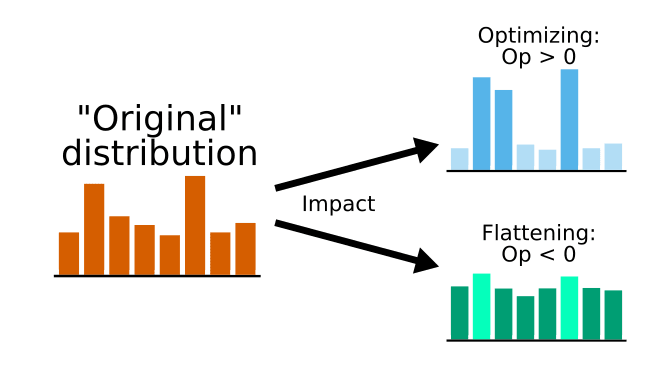
I will now take a second look at the measure for . What I really wanted all along is to measure a policy's impact on the world, and optimizing the future is only one way in which this can happen. Another way is flattening the possibilities out! Consider the following informal diagram. "Original" distribution is not well-defined here, the point is just to give an intuitive explanation:
The motivation and derivations for this can be found in Appendix A, with longer proofs listed in Appendix B, but the upshot is that we can define a new function: using the KL divergence of and like this:
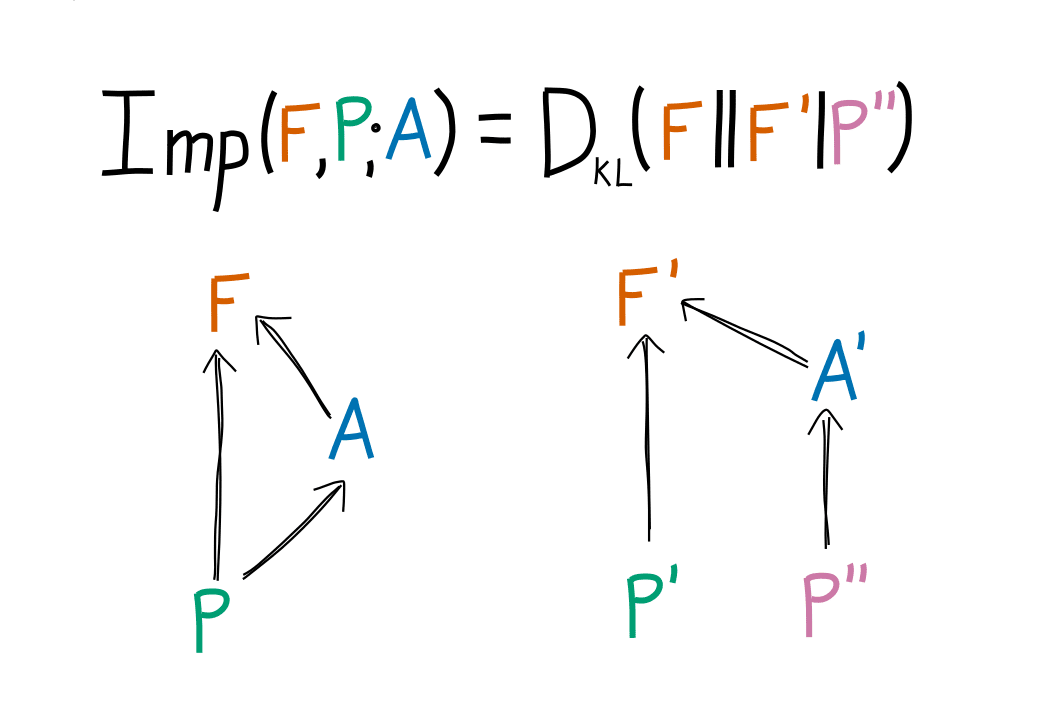
Which if we have a task success rate in and in must obey the following equation:
This can be measured using the same split-history method used to measure :
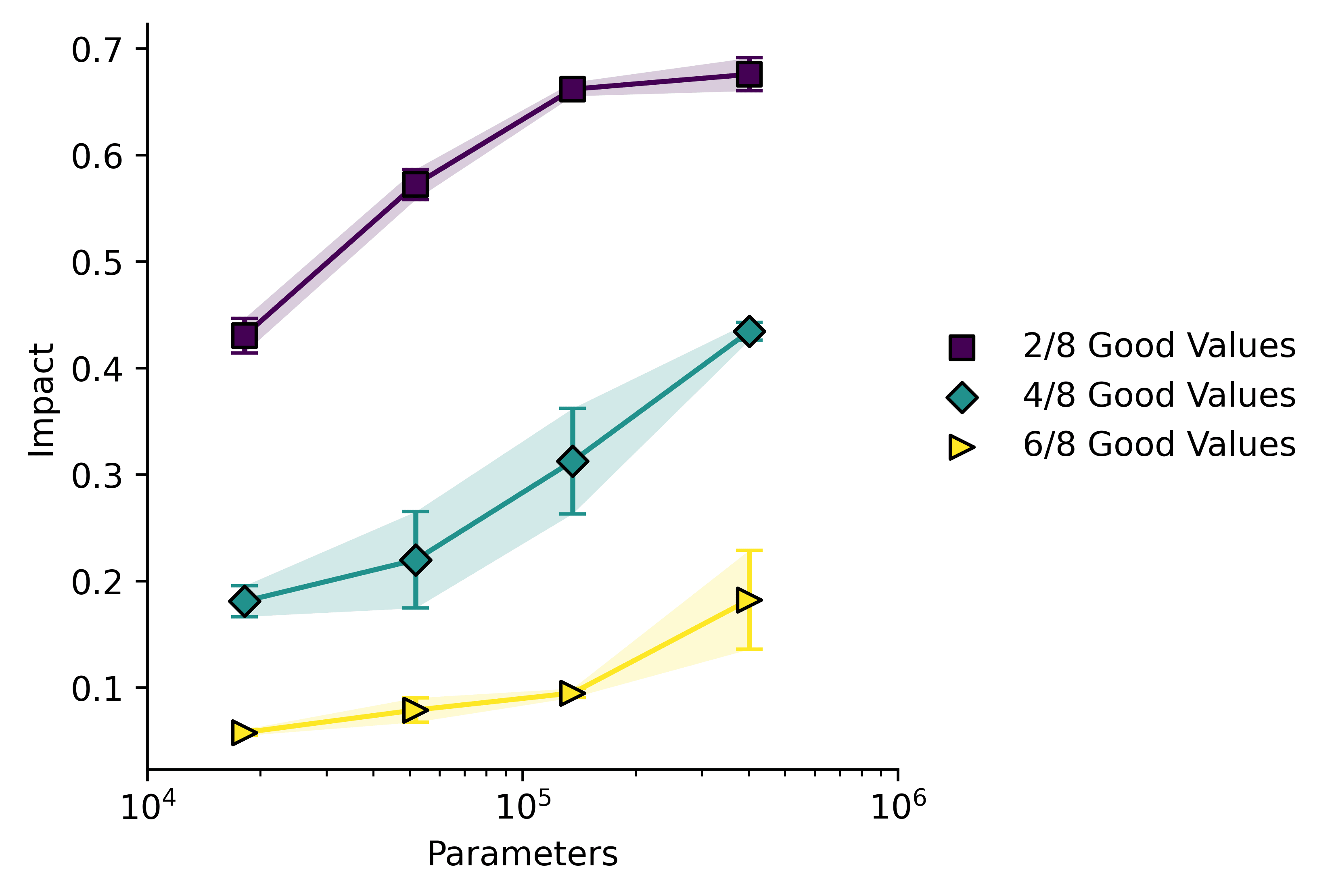
The lower bound can be calculated from success rates and the two can be compared:
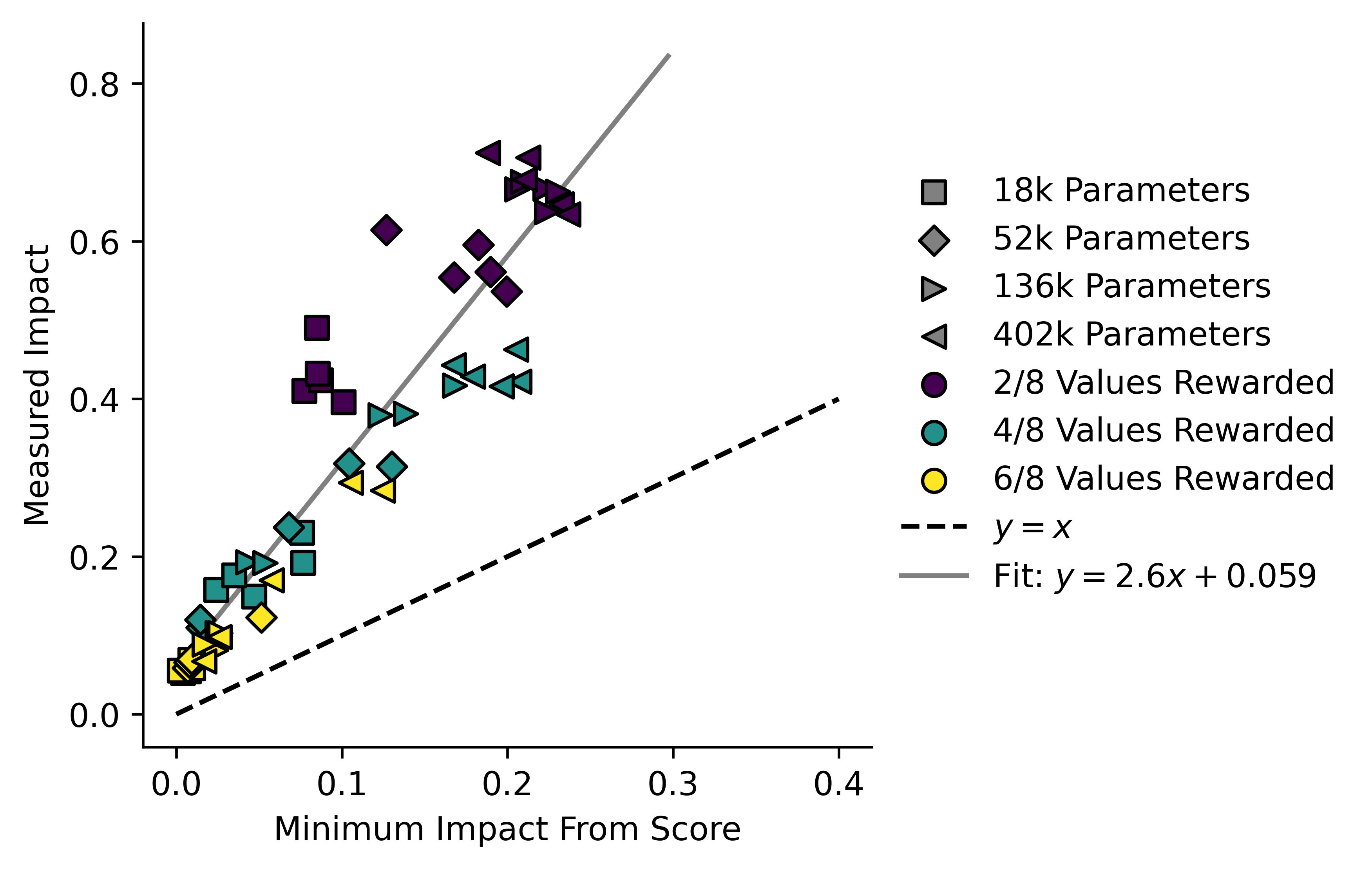
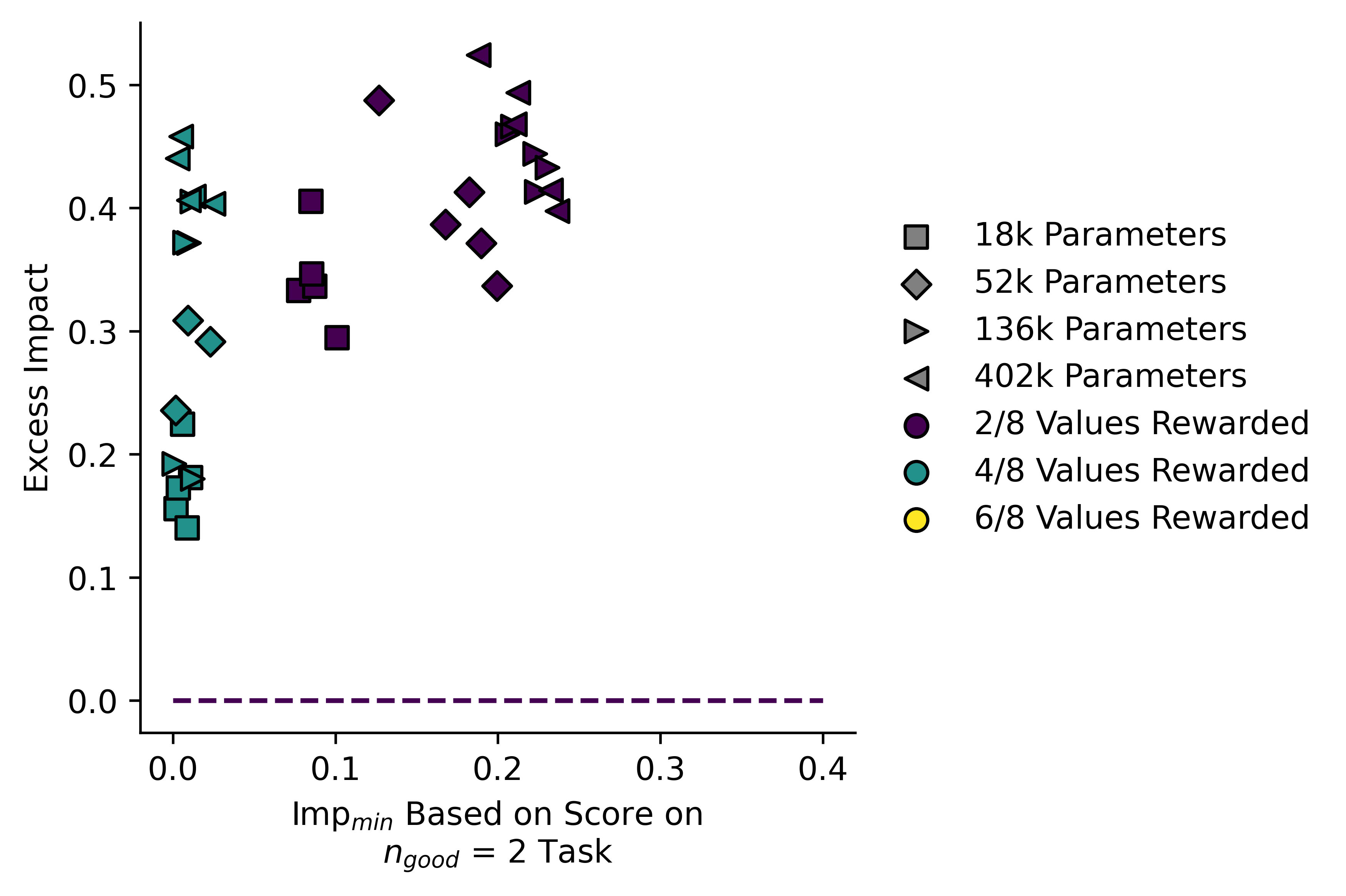
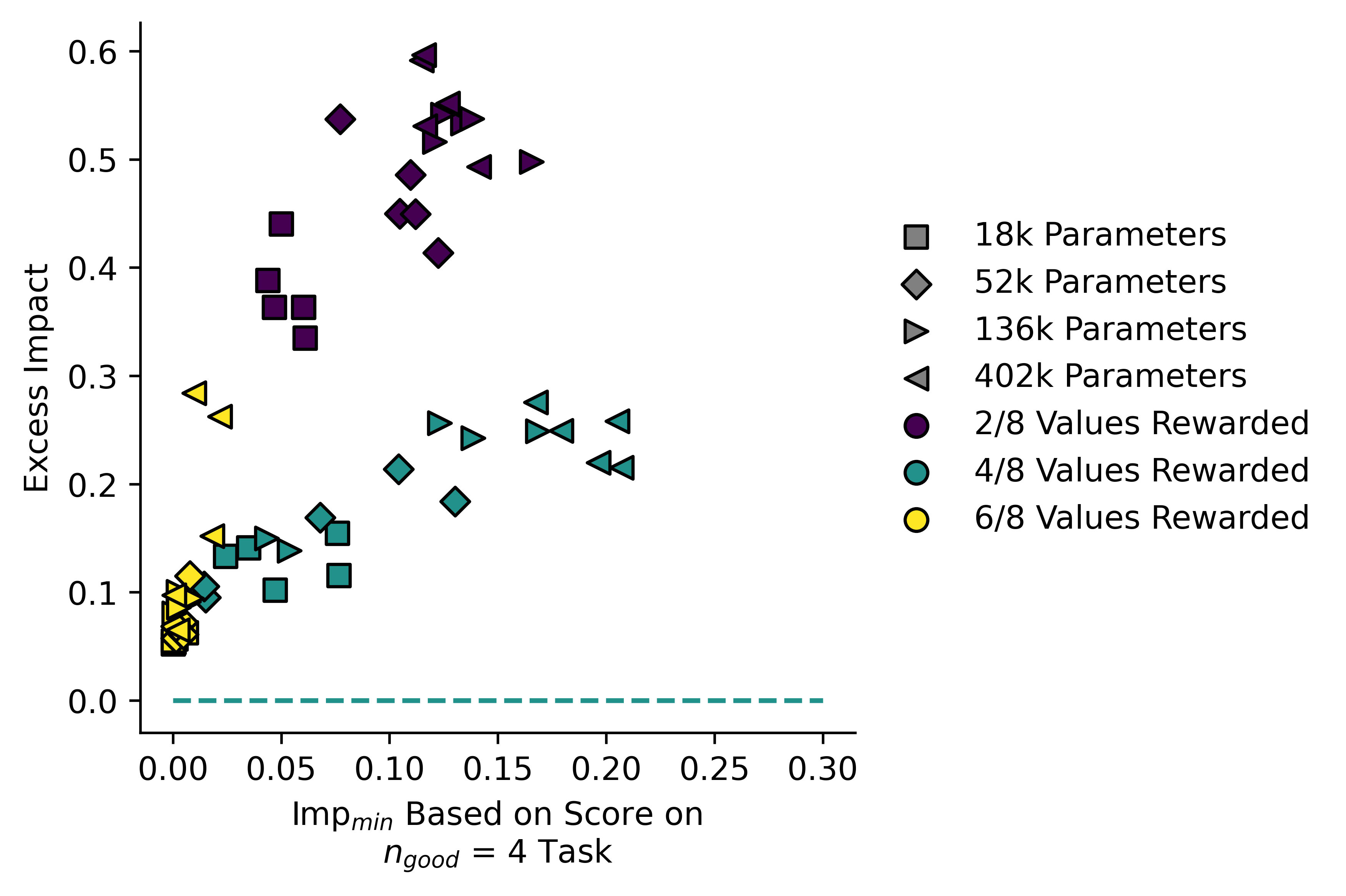
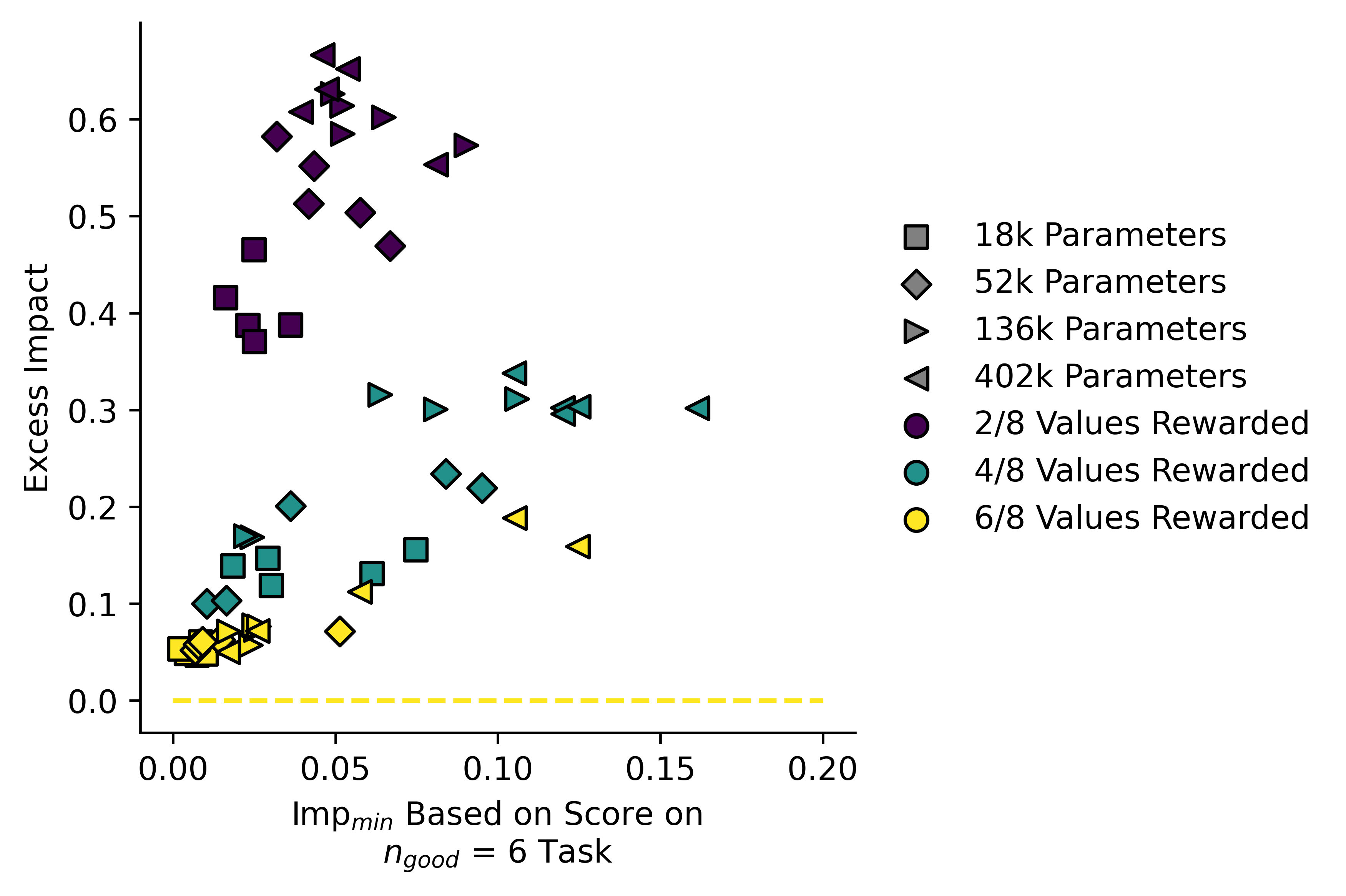
Larger models have a higher impact, but they also tend to have a lower ratio of than do the smaller ones. The single-line fit is also somewhat misleading, and actually the models appear to lie on three separate lines. I note that the values of are somewhat low in this case, rather than our measured impact being unexpectedly high. Our measure for may not be perfect in this case.
I think the difference between and tells us something. In this case it tells us that the success rates in are actually quite high:
Success rate in doesn't scale very much at all with model size, which indicates that models of all sizes exhibit roughly the same bias in outputs, based on statistical regularities in the data (e.g. a "13" is more commonly followed by a "2" than a "15" is). It might also be an artefact stemming from an uneven distribution of numbers in our sequence by default.
This highlights an important point about split-history measures: they only pick up on the effects of "active" inference in the policy, not on biases in the outputs which are produced during training. We don't have to use a split-history method to generate , we can think up plenty of alternative ways to generate a comparison future, and therefore generate a family of measures for and :
- Use a privileged "Do nothing" token as the model's output
- Use a totally random output token
- Use an untrained model, or a pretrained (but not finetuned) model
Despite these problems, if we repeat cross-objective evaluation using we get these plots:
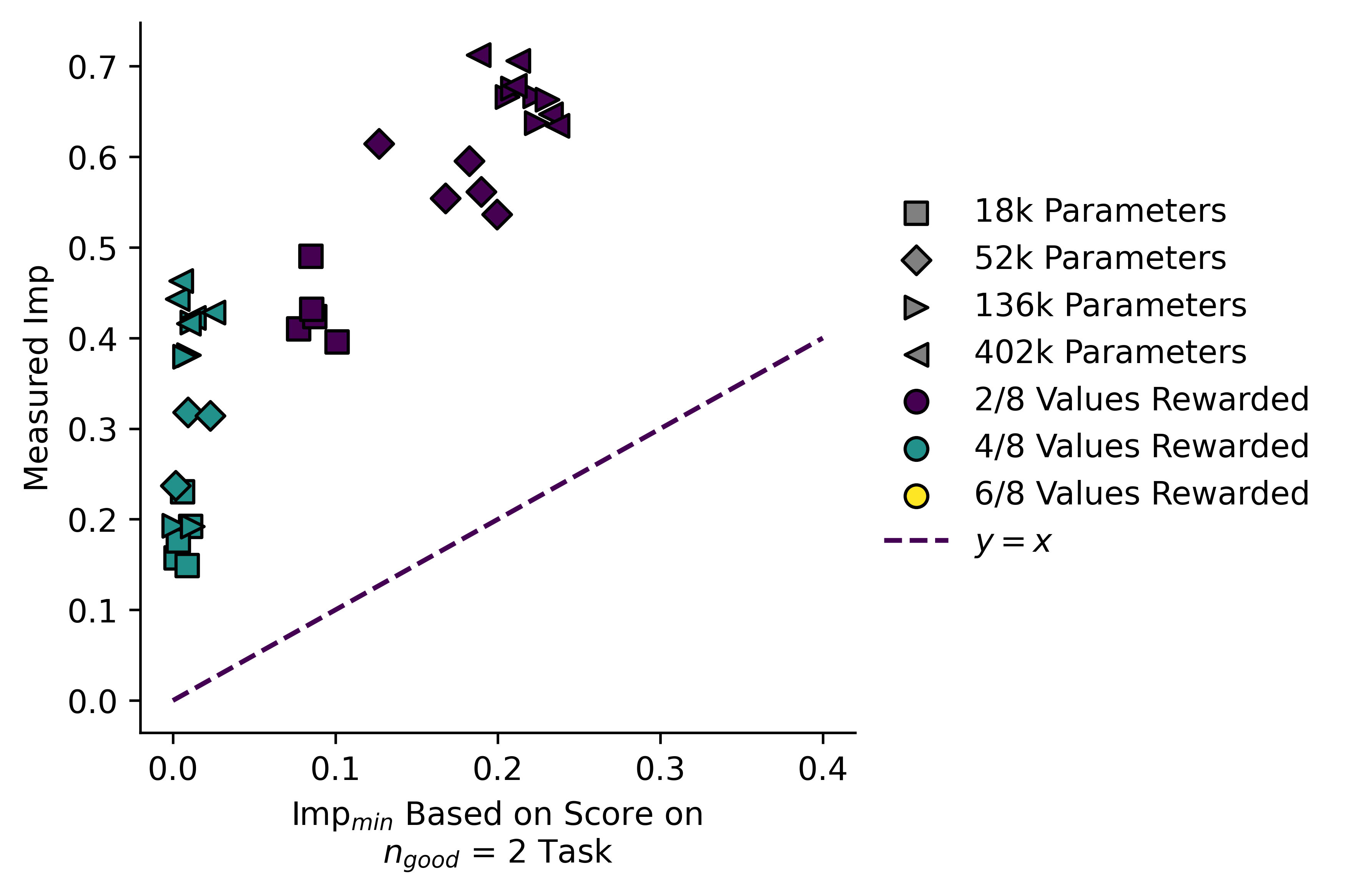
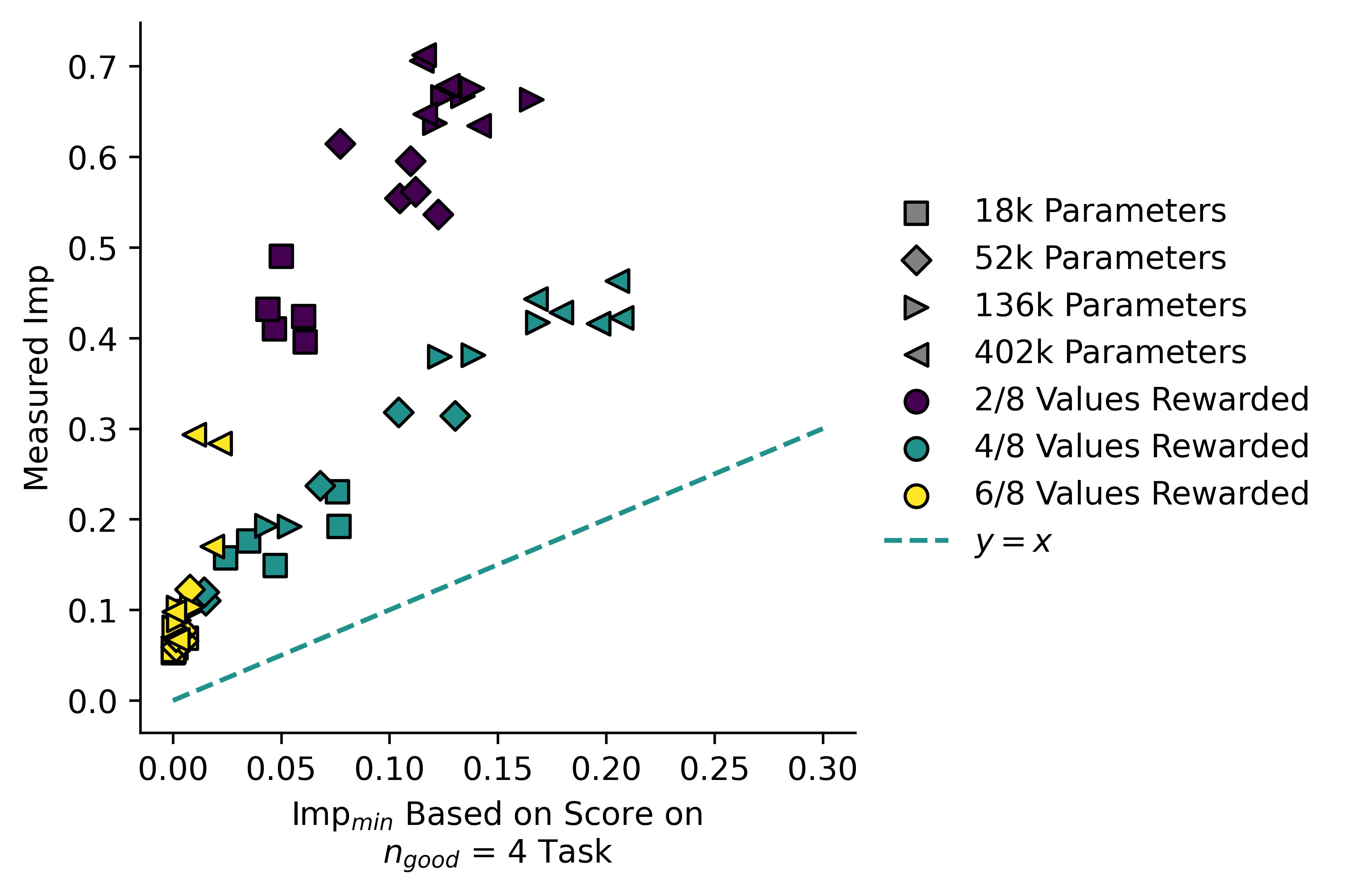
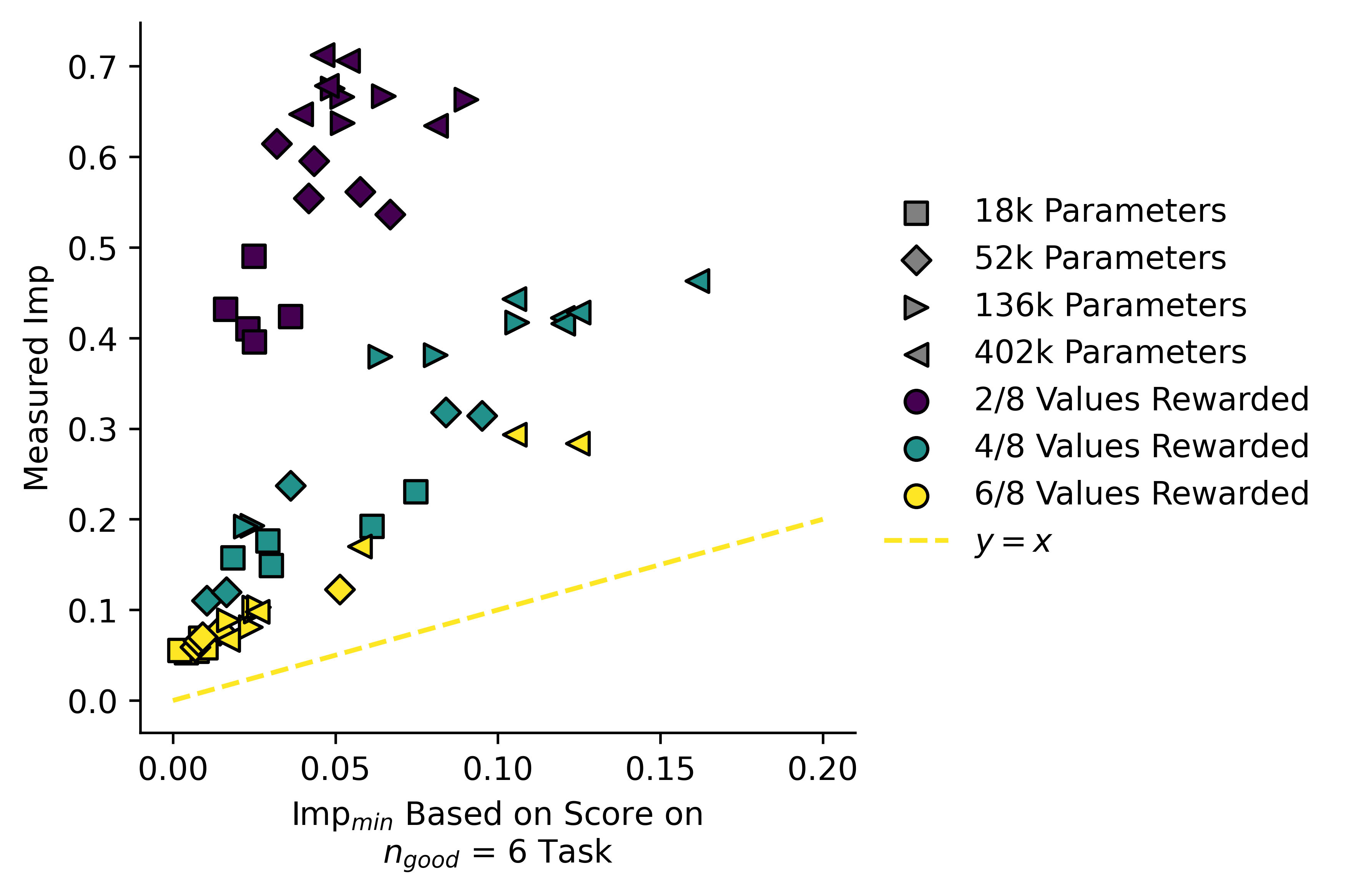
While the split is not as good as we saw with , it seems that models not trained on the "correct" fall along a line of lower gradient, and models trained on "incorrect" tasks have higher gradients i.e. the latter diverge from the line more rapidly.
There are many potential ways to visualize what's going on here, two more of which are in Appendix C at the end of this post.
Model Self-Evaluation
A secondary goal of my work was to get models to evaluate their own optimizing power and impact. This is the reason for the maintenance training during finetuning. The self-evaluation scheme is the same as the optimization measuring scheme, except that instead of using the sequence-generating formula to get values for , I used the model's own predictive power to get expected distributions over and :
A plot showing measured optimization plotted against self-estimated optimzation. Models from the task tend to fall on the line , but as decreases, models fall further above the line.
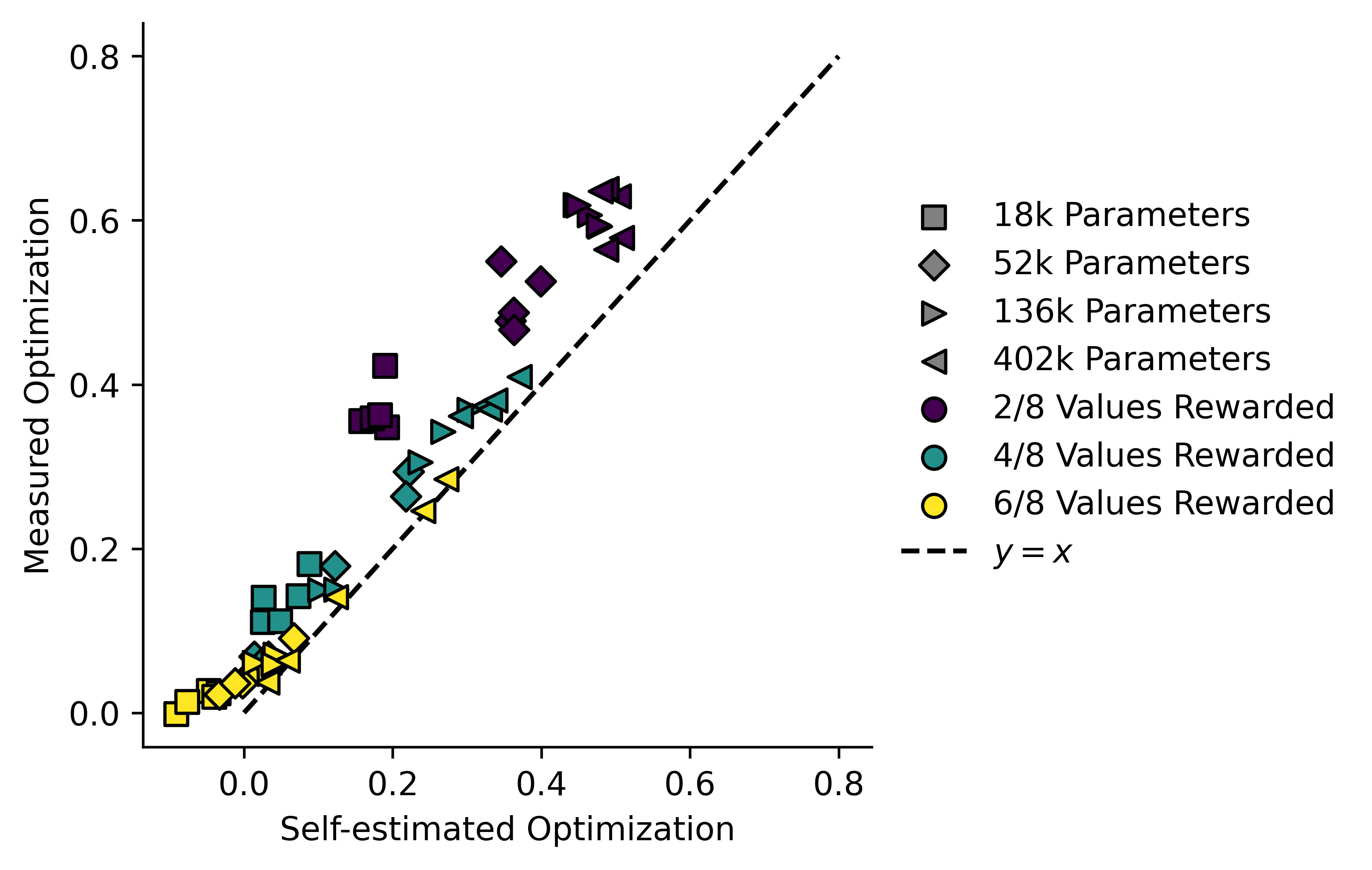
I suspect what's happened here is bog standard model bias. The more heavily the model is optimizing, the less even the distribution of examples of it gets fed during the maintenance training. This might make it more biased towards predicting the rewarded variables after any sequence, which would cause it to underestimate .
The same can be done for :
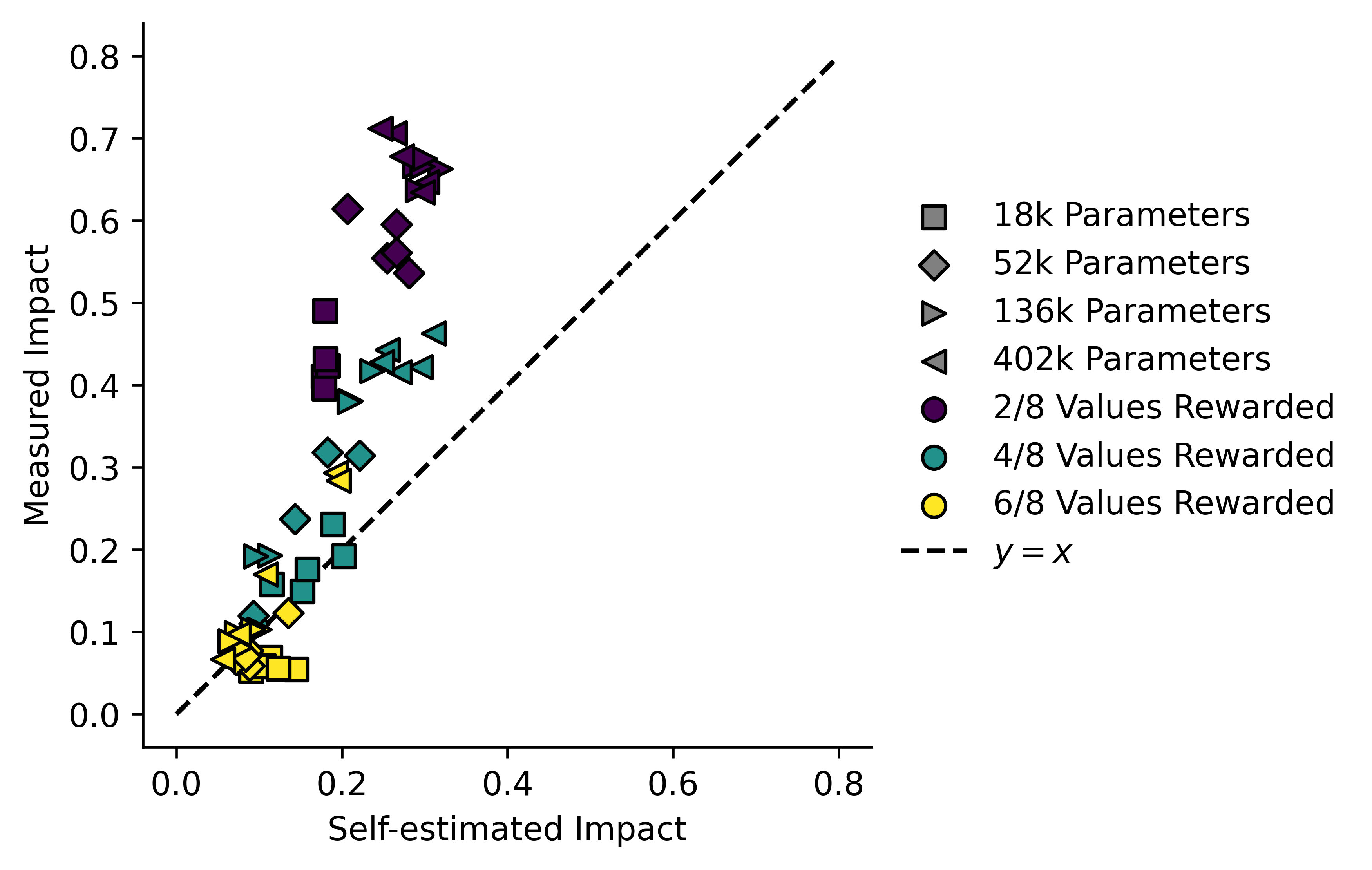
Which gives even worse results! I'm not sure whether or not this is also model bias. I don't have a tremendous amount of experience with ML, so I will not pursue this further in this post.
Conclusions
The measure I've introduced for seems to be predicted very well by theory, and might have utility in detecting how well a policy's results line up with an RL task when it can be predicted accurately. The measure for has some issues but shows some success towards the same goal. These can be considered complementary measures in many ways:
| Optimization | Impact |
| Can be positive or negative, the sign gives us information | Always |
| Can be cancelled out by opposite-signed optimization elsewhere | Always a positive value, always at least adds up across different sources |
| No easy way to calculate theoretical values of Op in general (that I've found) | can be calculated for any success/failure RL task |
| Excellent at identifying model behaviour in this case | Less good at identifying model behaviour in this case |
I would be interested in applying both of these to more complex ML systems, but at the moment I don't any specific plans to do so, due to my very limited experience with ML. In Appendix A I also present equivalent measures which can be applied to the activations of a neural network.
A theoretical limitation of this work is that can only be calculated when a task is binary success/failure. If the policy is trying to maximize some function world-state then there's no simple formula for based on RL score. Work on these systems must either develop new maths or or find a way to break down utility maximization into a series of success/failure tasks, which can separately be evaluated for impact.
One practical limitation is in the self-evaluation stage. If the model's self-evaluation is biased, the measures of and will be as well. This is especially problematic if or is underestimated, allowing the policy to "lie" to us about how much optimization/impact it is doing. My wild guess is that AIs which include explicit world-modelling (such as DreamerV3) will be less biased by default, but that attempts at introducing impact regularization might reintroduce bias.
Alex Turner's Existing Work
The expression for impact that I present here is totally independent with the AUP measure of impact as proposed by Alex Turner in Towards a New Impact Measure [AF · GW]. There might be some subtle way in which they're related but I haven't thought about this enough to say more. I've also read World State is the Wrong Abstraction for Impact [LW · GW] and agree with some of the points presented.
In response I would say that the metric I present here relies strongly on a model of the future world state, so only details captured in can affect the impact. In the limit where the future states only consist of , then impact is trivially equal to the lower bound and excess impact = 0.
Appendices
Appendix A: Impact and Differential Impact
Derivation of
I present the motivation for, and derivation of, the measure of which I've used in this post. Returning to my estimator for :
If we think these being two distributions over and think of as the probability of succeeding by chance, this becomes the formula for a Kullback-Liebler divergence. For a quick recap, the KL divergence of two distributions over a variable follows this formula:
We could also estimate the probability of succeeding by chance using the split-history method. Let be the success rate in , and be the success rate in :
I will now present some results about KL divergences. I will start by defining as the successful outcomes. Let us define a "baseline" probability distribution and from it a "baseline" success rate :
Now imagine a policy acts on this distribution and changes it to a new distribution. If this policy has a success rate , I define as follows:
This is what we might expect to be the effects of a "minimum impact" policy: it makes successful outcomes more likely and unsuccesful outcomes less likely while leaving relative probabilities otherwise intact. The KL-divergence between and can then be calculated, and it looks familiar:
This is the minimum KL divergence possible in shifting a distribution to achieve a given success rate. If we change the variable names to this allows us to write down the original relation for a policy's impact:
Differential Impact
In this case "differential" means "to do with differentiation". I've studied a construct I call differential optimization in the past, as it pertains to functions of real-valued variables. In this case if we have the functions , we can define the following value:
Intuitively, if is "optimizing" , then when it is allowed to vary, since will change less when we allow to change than when we fix . This led to the derivation of the differential optimization .
This can be extended to a differential impact metric:
This has a minimum at , but it is speculative and has not been tested, so while I will present it here I can give no guarantees at all about its utility.
We can also extend this to vector-valued . If we define as the Jacobian when varies, and as the Jacobian when is constant, then we get the following values for and :
If and do not have the same dimension, then does not exist and instead the following construction must be used:
The motivation for constructions like this is to apply them to the activations of neural networks. For a network with width , and a backpropagation time of , I believe the time-complexity of this contains a polynomial term in (possibly if using Bareiss algorithm) for the matrix inverse, and a term in .
Appendix B: Proofs
Derivation and proof of
I will prove that this choice of is a global minimum of for a fixed .
Consider a distribution , which involves moving some amount of probability mass from to . Without loss of generality, take both to be in (they must both be in either or so that holds) Consider the value of
Trivially we only need to look at the components relevant to and :
Expand values of :
Expand and collect factors of , cancelling the on the bottom:
Collect the factors of , expand stuff to a form:
Use the taylor expansion up to .
Sub in , expand, cancel:
Subtract:
Therefore is a local minimum of subject to our condition that . is convex in for fixed , therefore we have found the unique global minimum.
Derivation of Differential Impact
The measure of based on entropy that I've used here was based on the following comparison to differential optimization:
Consider the network , . This gives and .
This can be extended to an entropic measure of by considering uncertainty over , specifically:
Using split-histories we get:
If we take this gives the familiar value of . We may instead investigate the value of . Letting , for brevity:
Substituting:
Taking with respect to requires taking , :
Substituting into our original equation:
Which, if we extend to , gives
Derivation of Multivariate Differential Impact and Optimization
Let us take vectors , and in the same manner as above. Assume around some value of we have the following Jacobians.
Without loss of generality, take the means of all of these variables to be . There exists a formula for transforming a multivariate normal distribution[1].
Now for , the mean will no longer be zero:
We can calculate the KL divergence of using another formula[2]:
Therefore our impact will be:
Taking the expected value of the third component is actually easy if you have access to the internet. We can see that it is of the form where is multivariate normal. This has a closed-form solution[3]:
Therefore we have the following expression:
We can make some progress towards simplifying this if we take , which in this case lets us cancel everything out involving a , since the scalar value of commutes with all matrices, , and . We will also assume that all the Jacobians are invertible.
Using the cyclic property of the trace:
And if we define we get:
This seems to have the form of , and in fact if we consider , , and to just be concatenations of variables, which maeans all the matrices are diagonal, we see that our equation has the form.
Which is a nice sanity check. The value of is just the entropy difference which simplifies to for free.
If the Jacobians are not invertible, but we assume that is invertible, we instead get:
Appendix C: Supplementary Plots
Other Ways to Visualize Impact Plots
Here I plotted the "Impact ratio" against :
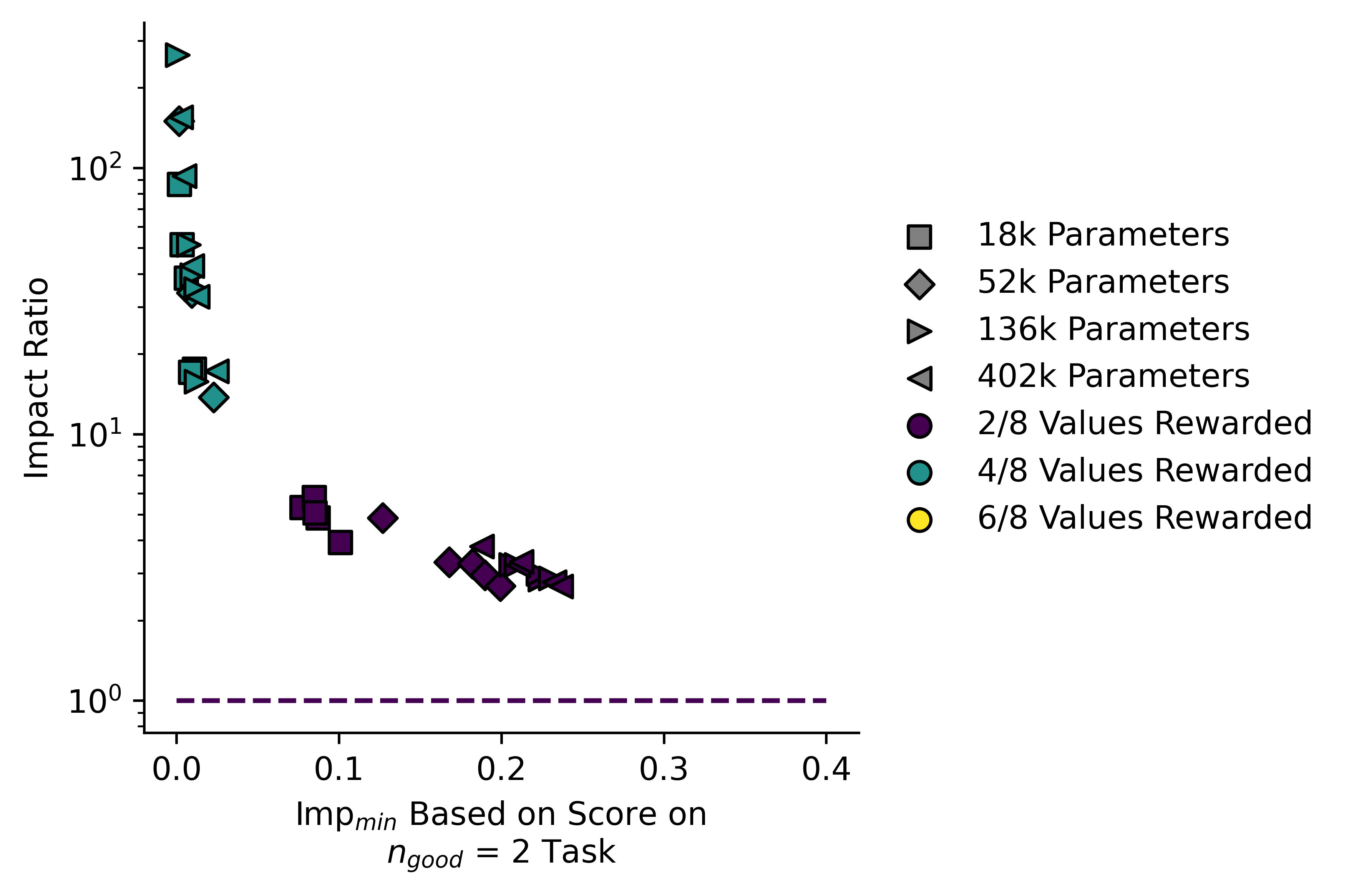
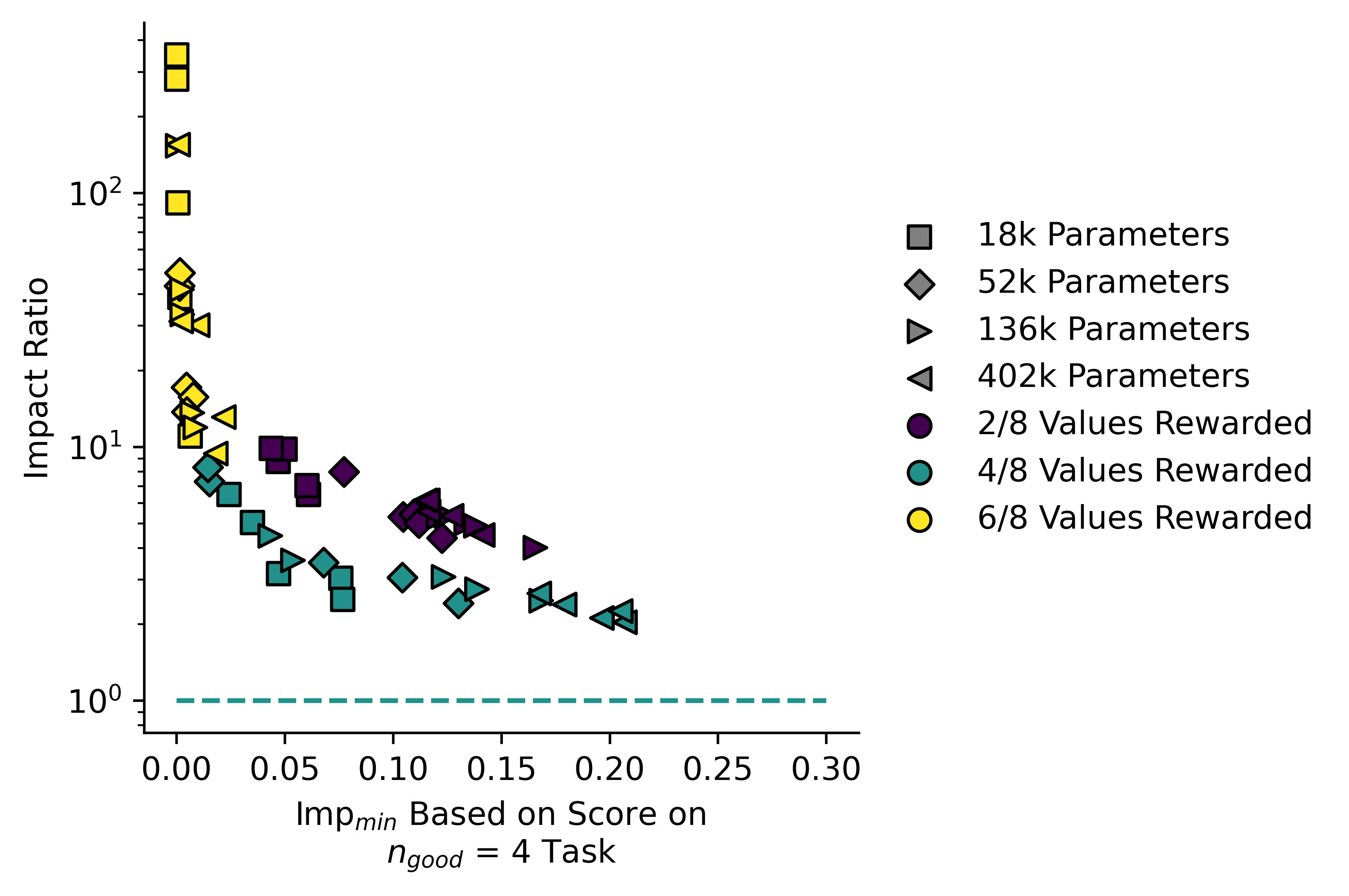
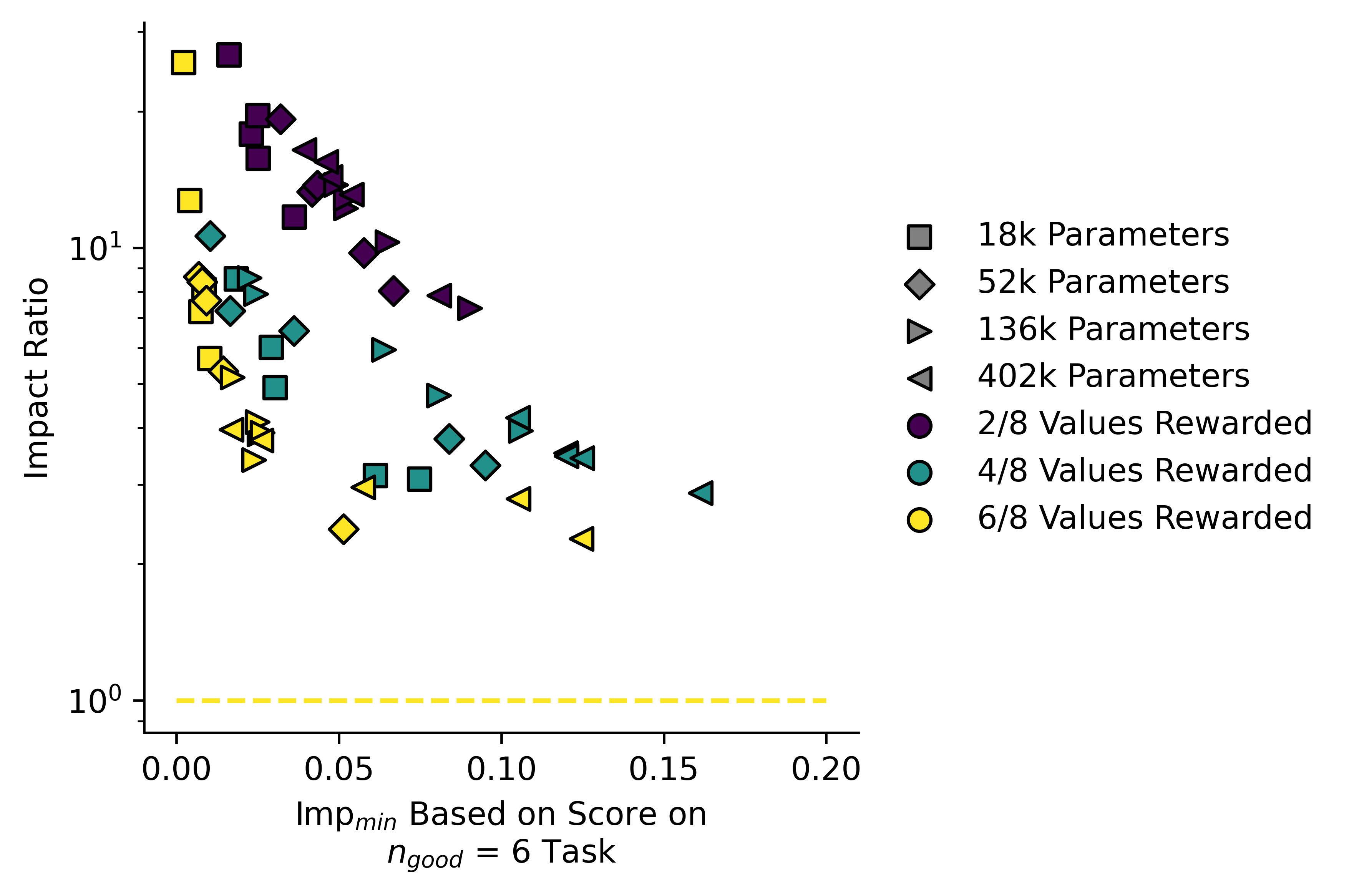
Here I plotted "Excess Impact" against :
Example training runs from = 4
Example figures summarizing training runs:
- ^
https://statproofbook.github.io/P/mvn-ltt.html
- ^
https://stats.stackexchange.com/questions/60680/kl-divergence-between-two-multivariate-gaussians
- ^
https://statproofbook.github.io/P/mean-qf.html
0 comments
Comments sorted by top scores.