Many methods of causal inference try to identify a "safe" subset of variation
post by tailcalled · 2021-03-30T14:36:10.496Z · LW · GW · 6 commentsContents
Vanilla methods for causal inference Other methods for causal inference A unified model: Xc/Xr splits Know your Xc! None 6 comments
(crossposted from my substack)
I have been thinking a lot about causality lately, and as a result I’ve come up with a common way to think of many different methods of causal inference that often seem to be used in science. This is probably not very novel, but I asked around whether it had a standard term, and I couldn’t find any, so I decided to write it up. I’ve personally found this model helpful, as I think it sheds light on what the limitations of these methods are, and so I thought I would write about it.
Roughly speaking, many methods of causal inference try to identify a “safe” subset of variation. That is, when trying to examine the causal effect of X on Y, they look in the variation of X to see how it relates to variation of Y. But this is possibly biased due to common causes or reverse causality (Y influencing X); so therefore to limit this problem, they find some way of partitioning X into a “safe” sort of variation that is not subject to these problems, and an “unsafe” sort that may be subject to them. Then they examine the correlation between this safe variation and Y.
The model abstracts over naive regression or multiple regression, longitudinal studies, instrumental variables, co-twin controls (Turkheimer’s “quasicausality”), and even randomized controlled trials. So to understand the common model, it is worth going through these methods of causal inference first.
Vanilla methods for causal inference
I don’t know who is going to read this blog, but I assume that most of my readers will be familiar with regression and experiments. Still it might be worth taking a recap:
Regression is the most naive method of causal inference; you’ve got two variables X and Y, and then you assume that any association between X and Y is due to a causal effect of X on Y. With regression, it is then straightforward to use data to see how much X correlates with Y and use this as the causal estimate. This is invalid if Y affects X, or if there is some common factor Z which affects both X and Y, which there usually is; hence the phrase “correlation is not causation”.[1]
To give an example, in order to figure out the effect of a medical treatment, you could look at differences between the people who get the treatment and the people who don’t get the treatment on various outcomes, such as the disease it’s supposed to treat, potential side-effects like mortality, and similar. The problem with this is that it is subject to reverse causality and confounding; e.g. people with the disease are probably more likely to be treated for the disease, which could make it seem like the treatment increases rather than decreases the disease. And general factors like health/age might influence the likelihood of getting the disease, and also the likelihood of negative later outcomes like death, making the naive estimate biased; this is a key concept called confounding, and it shows up everywhere.
Since there is usually some variable Z that confounds the relationship between X and Y, regression doesn’t work. Multiple regression is the naive solution to this, where one attempts to list every possible confounder Z, and include these in the statistics, with the hope that the rest of the association between X and Y is genuinely causal.
In the previous example of a medical treatment, in multiple regression one would try to measure the various confounders, like age or preexisting medical problems, to control for that.[2] If you can list all of the confounders, then this solves the problem of biased estimates. If you can list some major confounders, then that might reduce the problem. But a lot of the time in practice you can’t list the confounders, or can’t measure them well enough to control for them, which makes it far from a perfect method.
If one doesn’t like assumptions, then a very popular method is experiments. In an experiment, to find out the effect of X on Y, you modify X and then observe the resulting effect on Y. The standard sort of experiment used is a randomized controlled trial, where one has two groups of individuals, one group is assigned to some intervention while another is assigned to be controls that receive no intervention. The contrast between these two groups is then taken to be an estimate of the causal effect.
This obviously requires some intervention that influences X, and doesn’t influence any things other than X. In medicine, this seems straightforward enough, because often X already is some medical intervention that needs to be tested. But even in medicine you run into the fact that some people are going to leave the treatment or similar; and both inside and outside of medicine, you run into the problem that what you often want to test isn’t an intervention per se. As part of basic research, you might be interested in the direct causal effects of variables that you don’t know how to intervene on. In such cases you might be able to intervene very indirectly, and possibly shift X too; but higher degrees of indirection leaves more space for confounding, where a “heavy-handed” intervention has influence on other things than just X.
Other methods for causal inference
People often associate causality with change over time. If you see the variable X change first, and then the variable Y change, you might start to suspect that X influences Y. This is the intuition behind Granger causality, RI-CLPM, and other similar methods. I lump them together under the label of longitudinal/time-series methods (though that is a bit simplified as there are other kinds of longitudinal methods that don’t involve this premise). These methods look at whether a change in X predicts a later change in Y, and if they do, they assume that the correlation is causal.
It’s in principle pretty simple to consider how it might be used. Suppose you want to know how, say, personality and politics are related. Then with these methods you try to measure personality and political orientation repeatedly over time, and use various clever statistical models to see if changes in one are related to changes in the other.
These methods in a way combine two different reasons that they might work. First, if X comes before Y, then it would seem that Y couldn’t influence X, ruling out reverse causality. But to me, this argument is kind of weak; reverse causality isn’t usually as big a problem as some other variable influencing both X and Y. Granger causality does to an extent address this too, though, in that if it is discovered to hold, then a common cause must be sufficiently “close” or “late” in the causal network so as to be able to match the pattern that arises in the associations over time; “shocks” to X have to predict shocks to Y.
Another powerful-sounding method for causal inference is the co-twin control method, or as Turkheimer and Harden renamed it, quasicausality. It is based on the observation that, in social science, a great deal of proposed confounds are genetic or due to nurture, so if we look at identical twins, we can control for all of these confounds. If these identical twins are discordant for X, then this provides a natural experiment that you can use to guess the effect of X on Y. Turkheimer and Harden give the example of religion and delinquency, where they find no effect after using co-twin controls.
A method that seems more popular in economics is instrumental variables. Here, you have some variable Z which forms a “natural experiment” for X. That is, if Z influences X, and is not confounded with and does not have a direct influence on Y, then Z can be used to estimate the effect of X on Y.
It is often used where Z is just some randomized experiment to begin with. For instance, a popular example given is estimating the effect of military participation on wages. Military participation is positively correlated with future income, but this might be due to the characteristics of the people who volunteer; since some are conscripted to serve in the military, this serves as an instrument that can be used for comparison, and using this, military participation was found to have the opposite effect.
Z doesn’t need to be a randomly assigned experiment like this; you could use all sorts of variables that affect X for Z. The trouble is that many variables that influence X may also be confounded with or have an influence on Y, so this needs to be ruled out when using Z as an instrument. One example that is relevant to bring up for this is Mendelian randomization; here, a genetic predisposition to X is used as the instrument Z. This can be done in non-randomized ways, but it is often safer to do in randomized ways, using the fact that genes are assigned randomly from the parents due to sexual reproduction.
A unified model: Xc/Xr splits
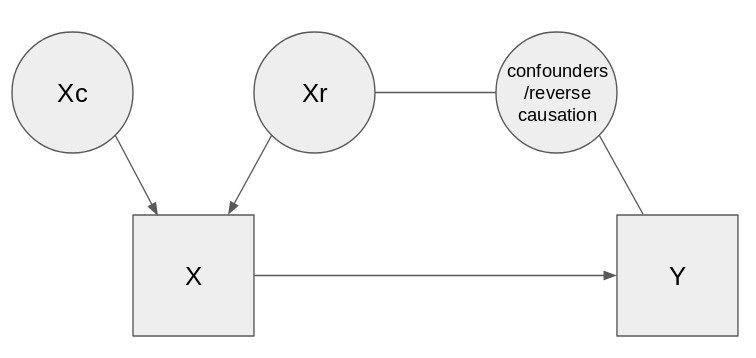
To me, what all of the previous models have in common is: You want to find the causal effect of X on Y. In order to do so, you construct a setting where X has two fragments; Xc (“X causal”) and Xr (“X residual”). Then you hope that Xc is not confounded, and regress Xc on Y to estimate the causal effect. Or more concretely:
- In multiple regression, you control for some set of confounders Z. This ends up “explaining” some of the association between X and Y; this explanation you attribute to Xr. The remainder you attribute to Xc.
- With randomized controlled trials, being in the experimental arm is the Xc, and any other variation is Xr.
- With longitudinal/time-series methods, changes over time is Xc, while things like seasonality (predictable changes that are plausibly confounded) or individual mean differences (if studying multiple time series in parallel, e.g. time series for different people or different countries) are Xr.
- With quasicausality, effects that are independent of nature and nurture are Xc, while effects that are shared between twins is Xr.
- With instrumental variables, variance due to the instrument is Xc, while variance independent of the instrument is Xr.
The family of methods makes three assumptions, which are rather obvious:
- Xc must be valid influence in X. This is an important point that I think there is not enough attention paid to, so we’ll come back to this in the next section.
- Xc must not be confounded with Y (or similar, such as via reverse causation); its effect on Y should be solely via its effect on X. This is usually not directly testable, and one must instead have some theoretical argument for why this is so.
- Xr must not be a consequence of Xc. This is a somewhat subtle technical point that I’m not going to address much here, but if you are not familiar with it, I suggest reading up on overadjustment bias.
Know your Xc!
There’s an easy way to remove all confounding from Xc; just place all of your variance in Xr, and let Xc be constant. If you want to know the effect of smoking on lung cancer, but you are worried that smokers have a gene that independently causes lung cancer, you can just control for smoking, and that gene can’t mess up your results. If Xc doesn’t vary, then it can’t be confounded. Of course, that also means that you can’t estimate the effect of X on Y; you are relying on variance in X (smoking) to estimate variance in Y (lung cancer), and controlling amounts to destroying this variance.
This is obviously a silly example, but it illustrates an important point: It is not the amount of confounding in Xc that matters, but rather the ratios of the variances in Xc. Xc should have as much unconfounded variance as possible, and as little confounded variance as possible. With multiple regression, this is often simple enough; you have a couple of confounders that you believe to be relevant, so you can adjust for those explicitly, and this likely reduces the degree of confounding because you have good reason to believe that these confounders specially problematic. You are unlikely to meaningfully reduce the valid variance much, as it would require the listed confounders to be highly predictive of X, which they rarely are. However, for many of the other methods, you often indiscriminately place huge amounts of the variance into Xr, removing it from Xc. Going back to the example of longitudinal modelling of personality and politics, a lot of personality and political orientation is stable over time; by only looking at the changes to these variables, one throws out all of this stable variance.
But do we really believe that temporary shifts in personality and politics are less confounded than long-term shifts? Remember, this is a necessary condition for these methods to work. I have no idea how to answer that question in the abstract, because I don’t know which factors influence personality and politics. The main options I could think of would be something like, changes in social environment or decisions to change one’s identity - but neither of those seem unconfounded.
And even that might be overly generous, as it assumes that things are either confounded or valid. Some studies find that if you adjust for measurement error, personality has a stability of 0.99 over different years; a lot of the apparent changes in personality might just be changes in the measurement error. Thus, this gives a third sort of variance that Xc might have, which biases the effect towards zero. You get similar problems with other methods than longitudinal methods too; for instance many traits are highly genetic (e.g. intelligence), and using quasicausality to control for the genetic influence leaves you with a tiny fraction of the original variance, which functions in unclear ways.
When I read scientific studies, I often find that they run into these sorts of problems. I’ve been thinking of ways to solve it, and each time it always runs back into the issue of, know your Xc. That is, rather than coming up with some story of how you’ve placed confounders in Xr, come up with some story for how X varies in an unconfounded way, and figure out some way to place that unconfounded variance in Xc. This severely limits the usability of the method[3], because it then requires a lot of understanding for how X comes to vary in the first place, which you may not know. I think there might be a few limited examples where not knowing why Xc varies still lets you infer causality, but I find that in a lot of papers when I switch from the perspective of “can I think of some confounder that they have missed?” to “do I know why Xc varies?”, their causal inference becomes a lot less convincing; it’s not obvious that Xc varies a lot in an unconfounded way.
In future blog posts, I will look into additional problems with doing Xc/Xr splits, as well as some alternative very different methods of causal inference that are applicable in a wider range of contexts than Xc/Xr splits are.
[1] A lot of the time, “correlation is not causation” is used in reference to other problems, such as spurious correlations or even nondeterministic causality. This is misleading, IMO, since the bigger problem most of the time is common causes.
[2] In practice, you would also restrict yourself to the people who have the disease that is getting treated in the first place. However, that is not very relevant for my point.
[3] One could perhaps say that one could use it as a cheap sanity-check or hypothesis-screening; if you assert a causal connection between X and Y, then there better also be a correlation, even when controlling in all of these varied ways. I agree that these sorts of sanity-checks are very valuable, but they may have some problems too, due to overadjustment bias, measurement error, as well as an as-of-yet unnamed bias that I’ve come up with which I want to address in a later blog post. Still, it’s probably fair to say that under a lot of circumstances, you can use this method to disprove causal claims, but not to prove them.
6 comments
Comments sorted by top scores.
comment by IlyaShpitser · 2021-03-31T14:02:59.155Z · LW(p) · GW(p)
If there is really both reverse causation and regular causation between Xr and Y, you have a cycle, and you have to explain what the semantics of that cycle are (not a deal breaker, but not so simple to do. For example if you think the cycle really represents mutual causation over time, what you really should do is unroll your causal diagram so it's a DAG over time, and redo the problem there).
You might be interested in this paper (https://arxiv.org/pdf/1611.09414.pdf) that splits the outcome rather than the treatment (although I don't really endorse that paper).
---
The real question is, why should Xc be unconfounded with Y? In an RCT you get lack of confounding by study design (but then we don't need to split the treatment at all). But this is not really realistic in general -- can you think of some practical examples where you would get lucky in this way?
↑ comment by tailcalled · 2021-03-31T14:29:42.141Z · LW(p) · GW(p)
If there is really both reverse causation and regular causation between Xr and Y, you have a cycle, and you have to explain what the semantics of that cycle are (not a deal breaker, but not so simple to do. For example if you think the cycle really represents mutual causation over time, what you really should do is unroll your causal diagram so it's a DAG over time, and redo the problem there).
I agree, but I think this is much more dependent on the actual problem that one is trying to solve. There's tons of assumptions and technical details that different approaches use, but I'm trying to sketch out some overview that abstracts over these and gets at the heart of the matter.
(There might also be cases where there is believed to be a unidirectional causal relationship, but the direction isn't know.)
The real question is, why should Xc be unconfounded with Y? In an RCT you get lack of confounding by study design (but then we don't need to split the treatment at all). But this is not really realistic in general -- can you think of some practical examples where you would get lucky in this way?
Indeed that is the big difficulty. Considering how often people use these methods in social science, it seems like there is some general belief that one can have Xc be unconfounded with Y, but this is rarely proven and seems often barely even justified. It seems to me that the general approach is to appeal to parsimony and assume that if you can't think of any major confounders, then they probably don't exist.
This obviously doesn't work well. I think people find it hard to get an intuition for how poorly it works, and I personally found that it made much more sense to me when I framed it in terms of the "Know your Xc!" point; the goal shouldn't be to think of possible confounders, but instead to think of possible nonconfounded variance. I also have an additional blog post in the works arguing that parsimony is empirically testable and usually wrong, but it will be some time before I post this.
comment by [deleted] · 2021-03-30T21:05:04.277Z · LW(p) · GW(p)
You're seeking an algorithm F, that, given observations O, gives you a correct causal model M. Each observation has a cost, and each manipulation of a variable (experimental case) has a large cost. You are seeking an algorithm with a good ratio of effectiveness to cost.
So I have an idea. You have a large number of cases : places where there is correlation, where there is causation, where confounding factors are large, where they are small.
To me this sounds like you can find a better model by generating a 'benchmark' of a large number of randomized situations, generating the observations, with error, that you would see, and find out which algorithms discover the true relationship best. Might be easier than theorizing with flowcharts.
Replies from: tailcalled↑ comment by tailcalled · 2021-03-31T09:57:33.049Z · LW(p) · GW(p)
😅 I think that is a very optimistic framing of the problem.
The hard part isn't really weighing the costs of different known observables to find efficient ways to study things, the hard part is in figuring out what observables that there are and how to use them correctly.
I don't think this is particularly viable algorithmically; it seems like an AI-complete problem. (Though of course one should be careful about claiming that, as often AI-complete things turn out to not be so AI-complete anyway.)
The core motivation for the series of blog posts I'm writing is, I've been trying to study various things that require empirical causal inference, and so I need to apply theory to figure out how to do this. But I find existing theory to be somewhat ad-hoc, providing a lot of tools with a lot of assumptions, but lacking an overall picture. This is fine if you just want to apply some specific tool, as you can then learn lots of details about that tool. But if you want to study a phenomenon, you instead need some way to map what you already know about the phenomenon to an appropriate tool, which requires a broader overview.
This post is just one post in a series. (Hopefully, at least - I do tend to get distracted.) It points out a key requirement for a broad range of methods - having some cause of interest where you know something about how the cause varies. I'm hoping to create a checklist with a broad range of causal inference methods and their key requirements. (Currently I have 3 other methods in mind that I consider to be completely distinct from this method, as well as 2 important points of critique on this method that I think usually get lost in the noise of obscure technical requirements for the statistics to be 100% justified.)
Regarding "theorizing with flowcharts", I tend to find it pretty easy. Perhaps it's something that one needs to get used to, but graphs are a practical way to summarize causal assumptions. Generating data may of course be helpful too, and I intend to do this in a later blog post, but it quickly gets unwieldy in that e.g. there are many parameters that can vary in the generated data, and which need to be explored to ensure adequate coverage of the possibilities.
Replies from: None↑ comment by [deleted] · 2021-03-31T18:48:16.394Z · LW(p) · GW(p)
I wasn't saying a flowchart wasn't helpful. I was saying if you want to find an algorithm to solve the problem, which is obtaining information about causal relationships at the lowest cost, you need to do it numerically.
This problem is very solvable as you are simply seeking an algorithm with the best score on a heuristic for accuracy and cost. Where "solvable means" "matches or exceeds state of the art".
comment by tailcalled · 2021-03-30T14:39:45.666Z · LW(p) · GW(p)
Also, a sidenote - I tend to think of Pearl-style conditional independence methods as being related to instrumental variables and thus being a multivariate generalization of these sorts of methods. But I'm not entirely sure. Any thoughts on that?