Hauke Hillebrandt's Shortform
post by Hauke Hillebrandt (hauke-hillebrandt) · 2023-07-07T12:39:06.698Z · LW · GW · 5 commentsContents
5 comments
5 comments
Comments sorted by top scores.
comment by Hauke Hillebrandt (hauke-hillebrandt) · 2025-02-24T15:30:25.019Z · LW(p) · GW(p)
Is OpenAI gaming user numbers?
Gdoc here https://docs.google.com/document/d/1os0WNmJ-O1eEGeKr543nkemnXbTmYkE2sC-t51c9OE4/edit?tab=t.0
Some have questioned OpenAI's recent weekly user numbers:[1]
Feb '23: 100M[2]
Sep '24: 200M[3] of which 11.5M paid, Enterprise: 1M[4]
Feb '25: 400M[5] of which 15M paid, 15.5M[6] / Enterprise: 2M
One can see:
- Surprisingly, increasingly faster user growth
- While OpenAI converted 11.5M out of the first 200M users, they only got 3.5M users out of the most recent 200M to pay for ChatGPT
Where did that growth come from? It's not from apps: the ChatGPT iOS app only has ~353M downloads total[7] and Apple's Siri integration only launched in December.[8] Users come from developing countries.[9] For instance, India is now OpenAI's second largest market, by number of users, which have tripled in the past year.[10]
- Many complain about increasingly aggressive message rate limits for free ChatGPT accounts, notionally due to high compute costs. But maybe this is a feature and not a bug: especially in poor countries, people create multiple accounts to get around the message and image generation limits.[11],[12] OpenAI incentivizes this: they no longer ask for phone numbers during sign up.
- Many new users might also use ChatGPT via WhatsApp[13] (a collaboration with Meta) perhaps using flip phones. OpenAI no longer asks for an email address during sign up.[14]
- You can also use ChatGPT search without signing up at all now.[15]
What counts as a user? True, ChatGPT grew faster than the fastest growing company ever, but social media has a much stronger network effect 'lock in' consumers longterm, whereas users will presumably switch AI chatbots much faster if a cheaper product becomes available. Many use ChatGPT merely as a writing assistant.[16] While consumer markets for social media can be winner-take-all, enterprise customers, while having doubled recently, will be less loyal and will switch if competitors offer a cheaper product.[17]
So maybe there's some very liberal counting of user numbers going on. Valuation goes up. Meanwhile hundreds of OpenAI's current and ex-employees are cashing out.[18]
Also, competition has caught up and so, Microsoft, which owns half of OpenAI, wants others to invest.[19] Yet, OpenAI CFO just said $11B in revenue is 'definitely in the realm of possibility' in 2025 (they're at ~$4B year-on-year currently) to get $40B from Softbank investment at a ~$300B valuation.[20] More recently this dropped to $30B and they scrambling to find others to co-invest in Stargate.
This is the standard playbook- recent examples include Roblox, which also inflated user numbers,[21] and Coinbase, which used to be lax with their KYC for obvious reasons and had inflated user numbers (it's also literally a plot point in Succession).
Also cf:
The market expects AI software to create trillions of dollars of value by 2027 AI stocks could crash [1] The Generative AI Con
[2] ChatGPT sets record for fastest-growing user base - analyst note | Reuters
[3] OpenAI says ChatGPT's weekly users have grown to 200 million | Reuters
[4] OpenAI hits more than 1 million paid business users | Reuters
[5] OpenAI tops 400 million users despite DeepSeek's emergence
[7] ChatGPT's mobile users are 85% male, report says | TechCrunch
[8] Apple launches its ChatGPT integration with Siri.
[9] https://trends.google.com/trends/explore?date=today 5-y&q=chatgpt&hl=en
[10] India now OpenAI's second largest market, Altman says | Reuters
[11] Anyone else have multiple accounts so they don't have to wait to use gpt 4o and also so each one can have a separate memory : r/ChatGPT
[12] https://incogniton.com/blog/how-to-bypass-chatgpt-limitations
[13] ChatGPT is now available on WhatsApp, calls: How to access - Times of India
[14] OpenAI tests phone number-only ChatGPT signups | TechCrunch
[15] ChatGPT drops its sign-in requirement for search | The Verge
[16] [2502.09747] The Widespread Adoption of Large Language Model-Assisted Writing Across Society
[17] Satya Nadella – Microsoft’s AGI Plan & Quantum Breakthrough.
[18] Hundreds of OpenAI's current and ex-employees are about to get a huge payday by cashing out up to $10 million each in a private stock sale | Fortune
[19] Microsoft Outsources OpenAI's Ambitions to SoftBank
[20] OpenAI CFO talks possibility of going public, says Musk bid isn't a distraction
[21] Roblox: Inflated Key Metrics For Wall Street And A Pedophile Hellscape For Kids – Hindenburg Research
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-02-24T21:19:53.577Z · LW(p) · GW(p)
Feb '23: 100M[2]
Sep '24: 200M[3] of which 11.5M paid, Enterprise: 1M[4]
Feb '25: 400M[5] of which 15M paid, 15.5M[6] / Enterprise: 2M
One can see:
- Surprisingly, increasingly faster user growth
- While OpenAI converted 11.5M out of the first 200M users, they only got 3.5M users out of the most recent 200M to pay for ChatGPT
This user growth seems neither surprising nor 'increasingly faster' to me. Isn't it just doubling every year?
That said, I agree based on your second bullet point that probably they've got some headwinds incoming and will by default have slower growth in the future. I imagine competition is also part of the story here.
↑ comment by isabel (IsabelJ) · 2025-02-24T22:01:44.395Z · LW(p) · GW(p)
taking the dates literally, the first doubling took 19 months and the second doubling took 5 months, which does seem both surprising and increasingly fast.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-02-24T23:43:59.287Z · LW(p) · GW(p)
Oh yeah my bad, I didn't notice that the second date was Sep instead of Feb
comment by Hauke Hillebrandt (hauke-hillebrandt) · 2023-07-07T12:39:06.781Z · LW(p) · GW(p)
AI labs should escalate the frequency of tests for how capable their model is as they increase compute during training
Inspired by ideas from Lucius Bushnaq, David Manheim, Gavin Leech, but any errors are mine.
—
AI experts almost unanimously agree that AGI labs should pause the development process if sufficiently dangerous capabilities are detected. Compute, algorithms, and data, form the AI triad—the main inputs to produce better AI. AI models work by using compute to run algorithms that learn from data. AI progresses due to more compute, which doubles every 6 months; more data, which doubles every 15 months; and better algorithms, which half the need for compute every 9 months and data every 2 years.
And so, better AI algorithms and software are key to AI progress (they also increase the effective compute of all chips, whereas improving chip design only improves new chips.)
While so far, training the AI models like GPT-4 only costs ~$100M, most of the cost comes from running them as evidenced by OpenAI charging their millions of users $20/month with a cap on usage, which costs ~1 cent / 100 words.
And so, AI firms could train models with much more compute now and might develop dangerous capabilities.
We can more precisely measure and predict in advance how much compute we use to train a model in FLOPs. Compute is also more invariant vis-a-vis how much it will improve AI than are algorithms or data. We might be more surprised by how much effective compute we get from better / more data or better algorithms, software, RLHF, fine-tuning, or functionality (cf DeepLearning, transformers, etc.). AI firms increasingly guard their IP and by 2024, we will run out of public high-quality text data to improve AI. And so, AI firms like DeepMind will be at the frontier of developing the most capable AI.
To avoid discontinuous jumps in AI capabilities, they must never train AI with better algorithms, software, functionality, or data with a similar amount of compute than what we used previously; rather, they should use much less compute first, pause the training, and compare how much better the model got in terms of loss and capabilities compared to the previous frontier model.
Say we train a model using better data using much less compute than we used for the last training run. If the model is surprisingly better during a pause and evaluation at an earlier stage than the previous frontier model trained with a worse algorithm at an earlier stage, it means there will be discontinuous jumps in capabilities ahead, and we must stop the training. A software to this should be freely available to warn anyone training AI, as well as implemented server-side cryptographically so that researchers don't have to worry about their IP, and policymakers should force everyone to implement it.
There are two kinds of performance/capabilities metrics:
- Upstream info-theoretic: Perplexity / cross entropy / bits-per-character. Cheap.
- Downstream noisy measures of actual capabilities: like MMLU, ARC, SuperGLUE, Big Bench. Costly.
AGI labs might already measure upstream capabilities as it is cheap to measure. But so far, no one is running downstream capability tests mid-training run, and we should subsidize and enforce such tests. Researchers should formalize and algorithmitize these tests and show how reliably they can be proxied with upstream measures. They should also develop a bootstrapping protocol analogous to ALBA, which has the current frontier LLM evaluate the downstream capabilities of a new model during training.
Of course, if you look at deep double descent ('Where Bigger Models and More Data Hurt'), inverse scaling laws, etc., capabilities emerge far later in the training process. Looking at graphs of performance / loss over the training period, one might not know until halfway through (the eventually decided cutoff for training, which might itself be decided during the process,) that it's doing much better than previous approaches- and it could look worse early on. Cross-entropy loss improves even for small models, while downstream metrics remain poor. This suggests that downstream metrics can mask improvements in log-likelihood. This analysis doesn't explain why downstream metrics emerge or how to predict when they will occur. More research is needed to understand how scale unlocks emergent abilities and to predict. Moreover, some argue that emergent behavior is independent of how granular a downstreams evaluation metrics is (e.g. if it uses an exact string match instead of another evaluation metric that awards partial credit), these results were only tested every order of magnitude FLOPs.
And so, during training, as we increase the compute used, we must escalate the frequency of automated checks as the model approaches the performance of the previous frontier models (e.g. exponentially shorten the testing intervals after 10^22 FLOPs). We must automatically stop the training well before the model is predicted to reach the capabilities of the previous frontier model, so that we do not far surpass it. Alternatively, one could autostop training when it seems on track to reach the level of ability / accuracy of the previous models, to evaluate what the trajectory at that point looks like.
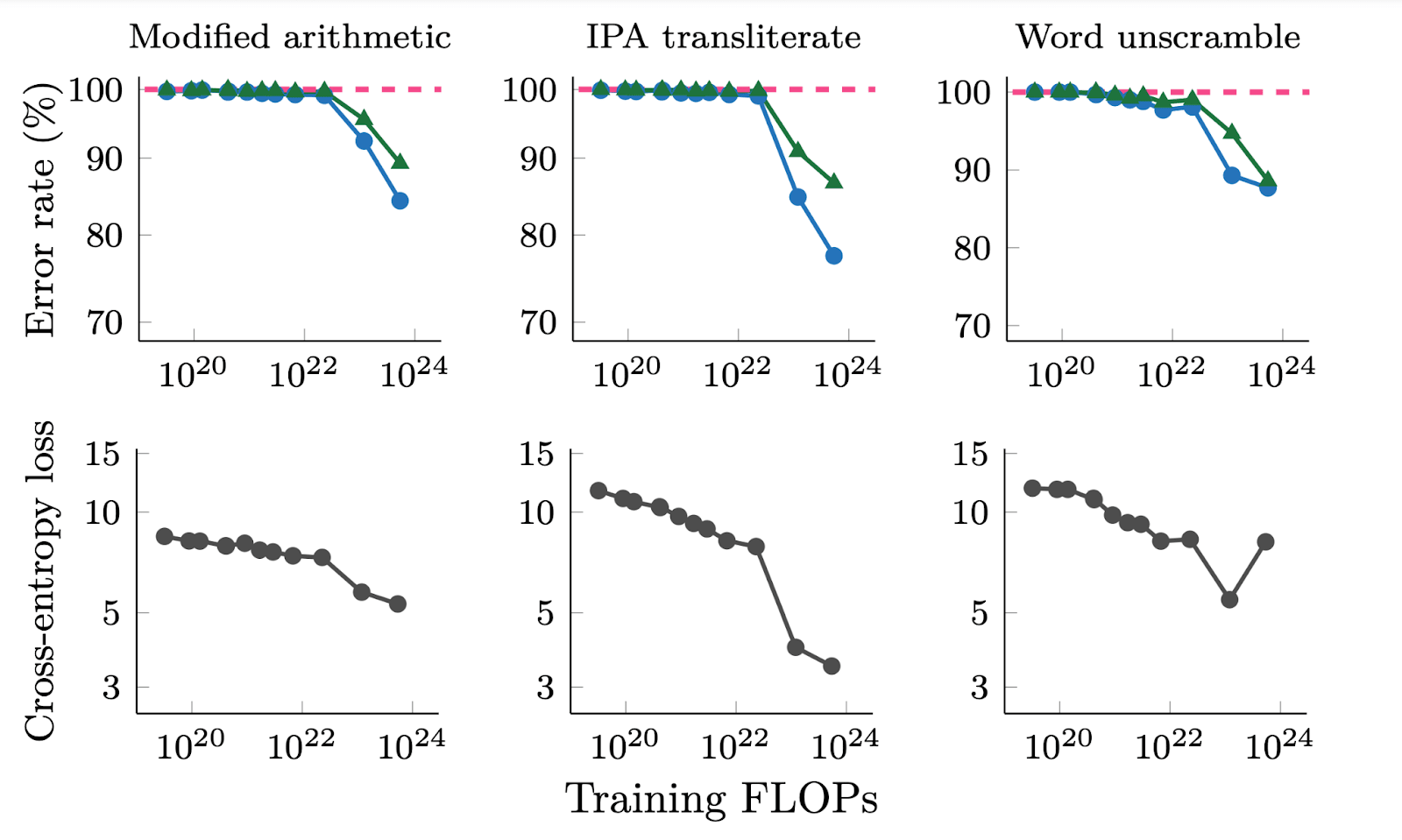
Figure from: 'Adjacent plots for error rate and cross-entropy loss on three emergent generative tasks in BIG-Bench for LaMDA. We show error rate for both greedy decoding (T = 0) as well as random sampling (T = 1). Error rate is (1- exact match score) for modified arithmetic and word unscramble, and (1- BLEU score) for IPA transliterate.'
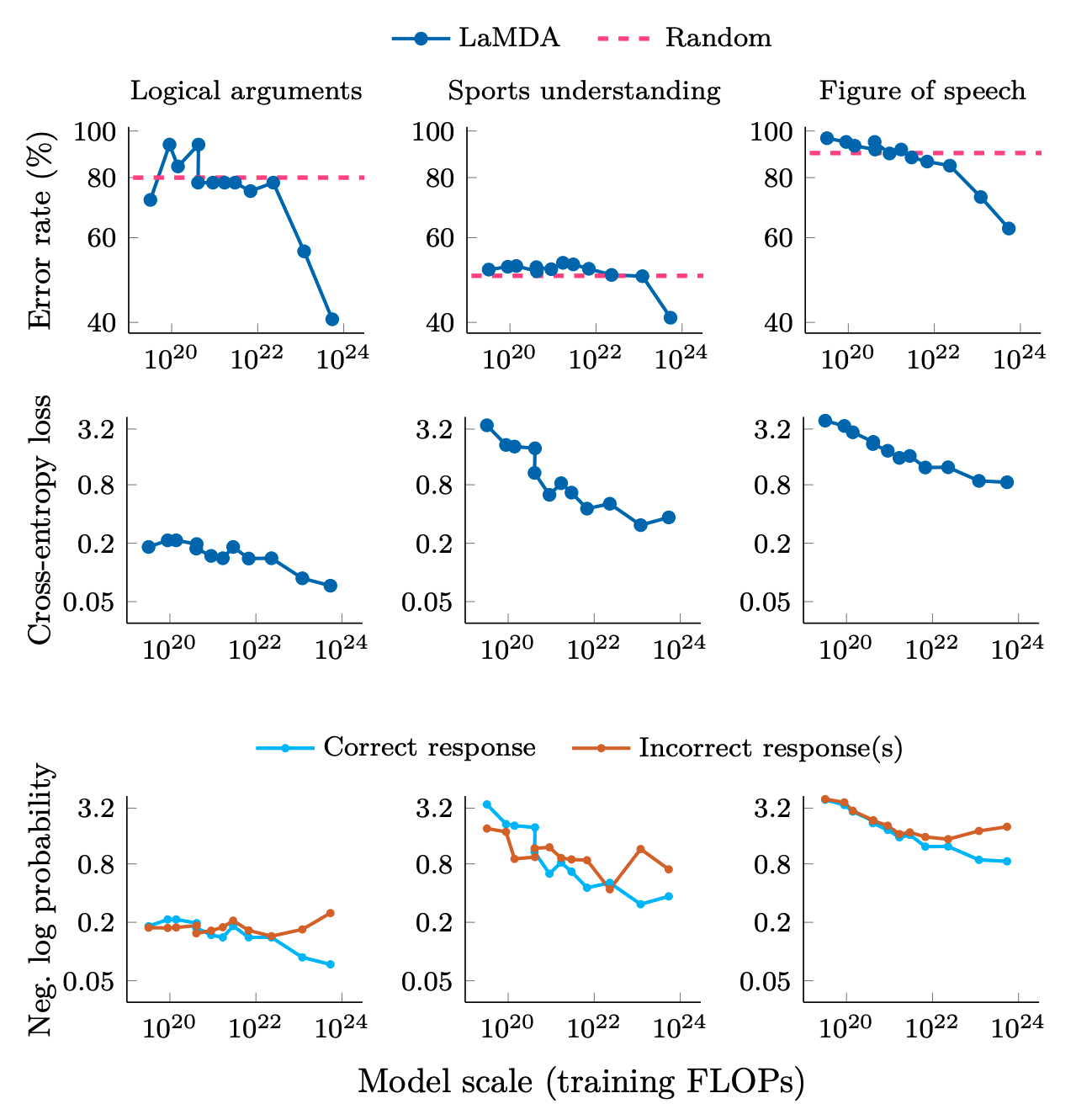
Figure from: 'Adjacent plots for error rate, cross-entropy loss, and log probabilities of correct and incorrect responses on three classification tasks on BIG-Bench that we consider to demonstrate emergent abilities. Logical arguments only has 32 samples, which may contribute to noise. Error rate is (1- accuracy).'