Getting started with AI Alignment research: how to reproduce an experiment from research paper
post by Alexander230 · 2024-05-30T14:51:49.337Z · LW · GW · 0 commentsContents
Setup Running experiment with LLMs Running experiment with vision models None No comments
This is a post with technical instructions, how to reproduce an experiment from Weak-to-strong generalization paper: https://openai.com/index/weak-to-strong-generalization/. It’s oriented mostly on beginners in AI Alignment who want to start tinkering with models and looking for examples how to do experiments.
Weak-to-strong generalization is research that shows that a strong model can learn on data generated by a weaker model, generalize the data and surpass the weaker model in the task for which it was trained. The paper comes with example code on GitHub with experiments both on LLMs and vision models. However, running the experiments from this code is not a straightforward task, so here are detailed instructions how to do it.
Setup
- Find a GPU cloud provider that gives access to terminal and Jupyter notebook. I used runpod.io for my experiment, selected a node with 1 RTX A6000 graphics card with 48 GB VRAM. The main limiting factor for the most of the experiments is VRAM size, so choose your node based on it and on the price; other characteristics are less important. Also, make sure that disk size of your node is at least 60 GB. Most of the cloud providers allow increasing disk size in settings, so do it if the disk is too small.
- Register the account, rent a node, and follow cloud provider’s instructions to connect to it with terminal and Jupyter notebook.
- Go to terminal and clone the repository:
git clone https://github.com/openai/weak-to-strong
cd weak-to-strong- I recommend to use virtual terminal, such as
tmuxorscreen: it will ensure that you will not lose your run if the connection to server will drop in the middle of an experiment. If the server uses Ubuntu or Debian, run commands:
apt-get install tmux
tmux- If the connection will drop, reconnect to the server and run the command
tmux attachto get back to your experiment. To scroll up and down intmux, useCtrl-B, [keys sequence, then scroll up and down with arrows. PressEscto exit scrolling mode. - Install the package and dependencies:
pip install .
pip install matplotlib seaborn tiktoken fire einops scipyRunning experiment with LLMs
Now everything is ready to run an experiment with LLMs. The code was probably written for older versions of libraries, and it will end with error if run on new versions as is, but it can be easily fixed.
- Use a text editor (such as nano) to edit the file
weak_to_strong/train.py, go to line 272, and add, safe_serialization=Falseto the function arguments. Save file and exit the editor. - Run a simple experiment with LLMs:
python sweep.py --model_sizes=gpt2,gpt2-medium- It will download the models and data automatically, teach the models gpt2 and gpt2-medium from the training data, then run another 3 passes: teaching gpt2 by output of trained gpt2 model (instead of training data), then teaching gpt2-medium by gpt2, and teaching gpt2-medium by gpt2-medium. Then it will test all 5 models on test data.
- It will print the resulting accuracy of the trained models to terminal. The results I’ve got:
gpt2: 0.65
gpt2-medium: 0.699
weak gpt2 to strong gpt2: 0.652
weak gpt2 to strong gpt2-medium: 0.655
weak gpt2-medium to strong gpt2-medium: 0.689- If the experiment finished successfully, everything is working fine; you are ready to run an experiment with more models to draw charts, how the resulting weak-to-strong performance depends on raw performance of weak and strong models. Run another experiment:
python sweep.py --model_sizes=gpt2,gpt2-medium,gpt2-large,Qwen/Qwen-1_8B- This one will take significantly more time. When the experiment finishes, go to Jupyter notebook and open the example notebook
weak-to-strong/notebooks/Plotting.ipynb. Edit 2 variables in the 1st cell:
RESULTS_PATH = "/tmp/results/default"
MODELS_TO_PLOT = ["gpt2", "gpt2-medium", "gpt2-large", "Qwen/Qwen-1_8B"]- Run the notebook. It should produce a plot like this:
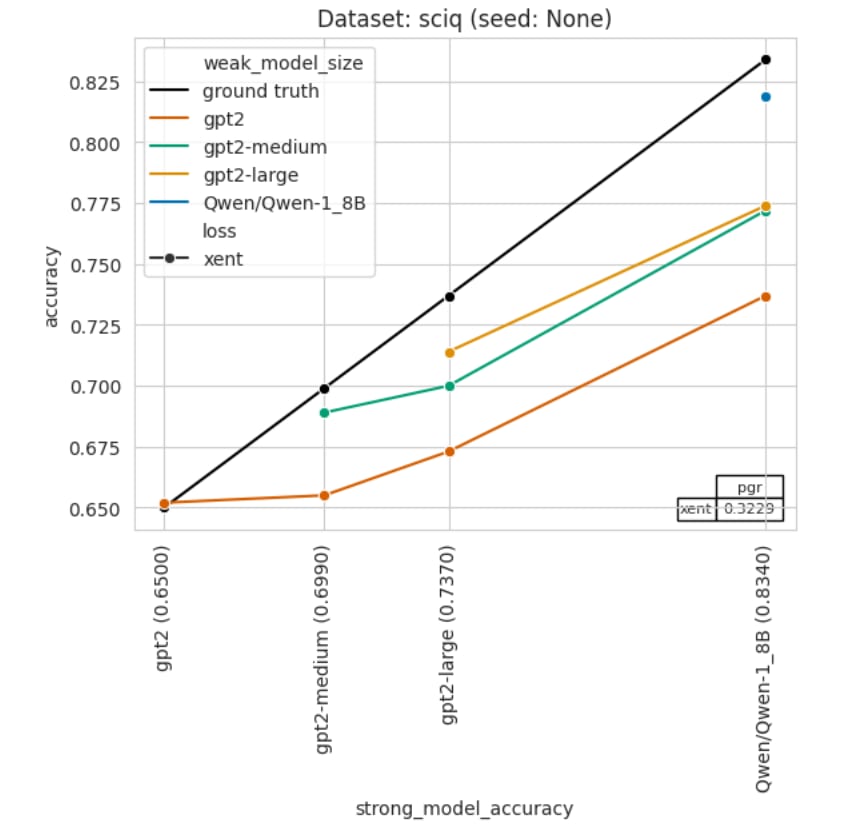
- Lines of different colors correspond to different weak models, and the plot shows dependency of weak-to-strong accuracy on raw accuracy of a strong model. You can also compare your plot with example plots on GitHub page: https://github.com/openai/weak-to-strong.
Running experiment with vision models
You can also reproduce the experiment with vision models. For this, you will need to download some of the datasets manually.
- Run these commands to download the datasets to the home directory:
WORKDIR=`pwd`
cd ~
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_devkit_t12.tar.gz
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar —no-check-certificate
cd $WORKDIR/vision- Run the experiment. It will take significant time, and should download all the remaining datasets automatically:
python run_weak_strong.py --strong_model_name resnet50_dino --n_epochs 20- This experiment will use AlexNet as weak model and Dino ResNet50 as strong model. It will output the final accuracy results to the console. The results I’ve got:
Weak label accuracy: 0.566
Weak_Strong accuracy: 0.618
Strong accuracy: 0.644When you get all scripts working and producing measurements and charts, you can use them later as examples of how to make your own experiments. Happy tinkering!
0 comments
Comments sorted by top scores.