Automated Sandwiching & Quantifying Human-LLM Cooperation: ScaleOversight hackathon results
post by Esben Kran (esben-kran), Fazl (fazl-barez), Sabrina Zaki (Zaki), gabrielrecc (pseudobison), rz2383 · 2023-02-23T10:48:08.766Z · LW · GW · 0 commentsContents
Automatic Sandwiching: Efficient Self-Evaluations of Conversation-Based Scalable Oversight Techniques Evaluation of Large Language Models in Cooperative Language Games Scaling analysis of token reversals Honorable mentions Join the next hackathon! None No comments
We ran a hackathon on scalable oversight with Gabriel Recchia as keynote speaker (watch the talk) and Ruiqi Zhong as co-judge. Here, we share the top projects and results. In summary:
- We can automate the “sandwiching” paradigm from Cotra [1 [LW · GW]] by having a smaller model ask structured questions to elicit a true answer from a larger model and getting a response accuracy rate as output.
- We can understand coordination abilities between humans and large language models quantitatively using asymmetric-information language games such as Codenames.
- We can study scaling and prompt specificity phenomena in-depth using a simple framework. In this case, word reversal is investigated to evaluate the emergent abilities of language models.
Watch the project presentations on YouTube.
Thank you goes to the local organizers, Gabriel Recchia, Ruiqi Zhong and the wonderful hackathon participants from across the world.
Automatic Sandwiching: Efficient Self-Evaluations of Conversation-Based Scalable Oversight Techniques
By Sophia Pung and Gabriel Mukobi
Abstract: Our project furthers the progress of Scale Oversight through automation of the sandwiching paradigm. In the Bowman et al. (2022) paper, the question is presented of how humans can effectively prompt unreliable, superhuman AIs to answer questions via conversation to arrive at accurate answers. We want to explore and evaluate the methods that humans can use reliably to elicit honest responses, from a more intelligent AI. We present a novel method, called Automatic Sandwiching, for implementing this paradigm. We implement a simplified version of this, evaluate our system on 163 training examples from Multi-task Language Understanding (MMLU) with 2 different oversight techniques. We provide code to reproduce our results at sophia-pung/ScaleOversight.
They replicate a non-expert human overseer by taking a smaller model (text-curie-001) and providing it specific instructions to get non-deceptive answers in a question and answer conversation with the larger model (text-davinci-003). The dataset has been used before in similar work [2] and is useful for eliciting structured conversations for oversight.

Gabriel Recchia’s comment: This is exactly the type of project I was hoping would come out of this hackathon! Replacing humans with LMs as has been done here, if it can be made to work, potentially allows for much faster research iteration, so I think this is an interesting and worthwhile research direction. Despite the negative finding, this research direction has a lot of promise and I think there's much more that can be tried if you or others are inspired to continue in this direction -- other prompts or fine-tuning to try variations on what you've tried or generation/evaluation of arguments for/against particular answers, trying different approaches to eliciting the larger language model's confidence in its answers, etc. I suspect that Bowman et al. would be happy to share their full transcripts with you if you wanted to examine in more detail some of the successful strategies that some of their participants used or fine-tune on their data. Minor note: Regarding answer letters not in the top-5 tokens, you might get slightly better luck with the slightly modified prompt: "Final Answer (answer immediately with (A), (B), (C), or (D)): ("
Ruiqi Zhong’s comment: Cool project! What would happen if you use a larger, more capable model to mimic the human overseer? (notice that we only want the overseer optimized to mimic the human overseer, rather than optimized for human preference for safety reasons). It seems plausible to me that you can get better performance by using a better model that can simulate human overseer. Overall: the ideas are relevant and novel. Though the results are a bit weak, it is a very informative first step for the followup investigations. Scalable Oversight: highly relevant. Novelty: the idea seems pretty impactful and could potentially be turned into a research paper, if there are more comprehensive experiments. Generality: the technique is fairly general – at least as general as the paradigm proposed by Bowman et. al Reproducibility: seem pretty easily reproducible.
See their report and the code.
Evaluation of Large Language Models in Cooperative Language Games
By Samuel Knoche
Abstract: This report investigates the potential of cooperative language games as an evaluation tool of language models. Specifically, the investigation focuses on LLM’s ability to both act as the “spymaster” and the “guesser” in the game of Codenames, focusing on the spymaster's capability to provide hints which will guide their teammate to correctly identify the “target” words, and the guesser's ability to correctly identify the target words using the given hint. We investigate both the capability of different LLMs at self-play, and their ability to play cooperatively with a human teammate. The report concludes with some promising results and suggestions for further investigation.
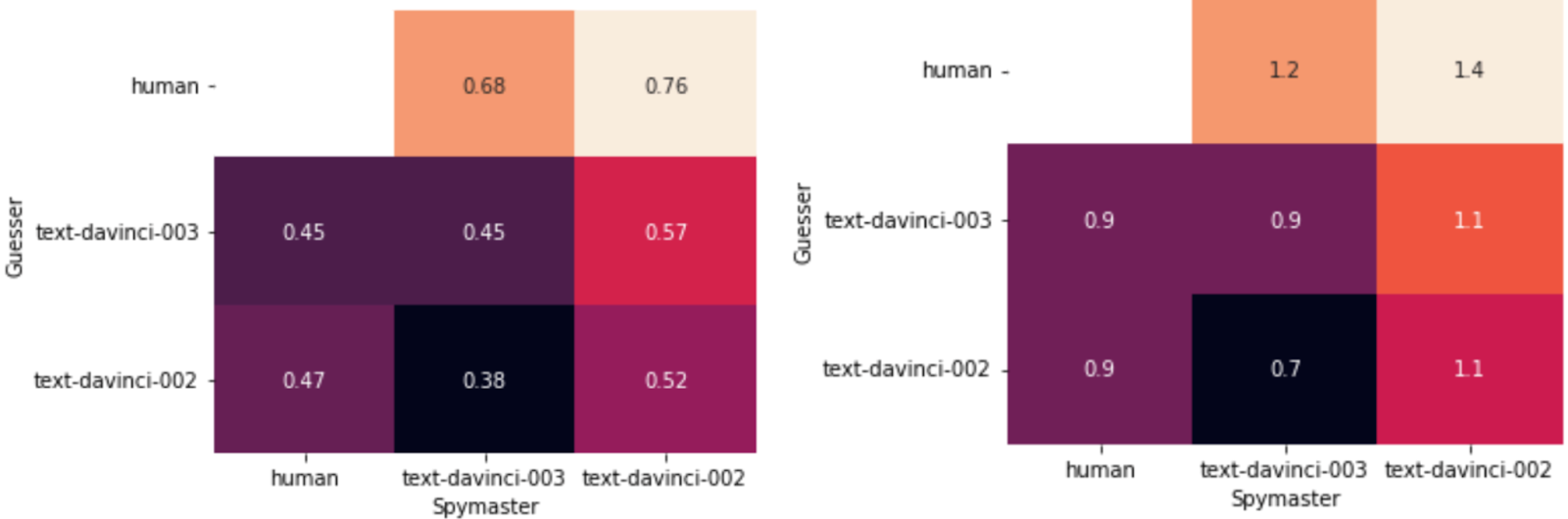
(Left) Accuracy on 20 games and (Right) average correct guesses between humans and large language models
This report provides the first steps towards creating scalable benchmarks of cooperation and both human-LLM and LLM-LLM performance is measured in an automated setting with asymmetric-information language games. The setting itself can also be modulated to test for different difficulty levels and skillsets in language cooperation. Future work might look into collecting more human data for this benchmark, improving the prompts used, try to use a more challenging version of the game or try to come up with new cooperative language game benchmarks entirely.
Gabriel Recchia’s comment: This is an impressively thorough (given the 48-hour time limit!) investigation of a debate-like task. The proposed class of benchmarks for LLM, using cooperative, asymmetric-information language games is an excellent proposal and this is a solid proof of concept to demonstrate the idea. Quantitative and qualitative investigation of LM performance on such benchmarks could help give insights into issues that schemes like debate may run into in practice and whether there is anything that can be done to patch issues that may arise.
Ruiqi Zhong’s comment: Looks like a really cool project! Some extensions that might be interesting: Would it be possible to plan ahead, either by recursively calling the LM itself, or use chain-of-thoughts to perform planning? It might be interesting to look beyond 2 words, which seem to be quite simple for humans (e.g., I usually start to struggle only when I want to get at 3 words).
See the report and the code.
Scaling analysis of token reversals
By Ingrid Backman, Asta Rassmussen, Klara Nielsen
Abstract: The concept of emerging abilities in AI is often a source of confusion. To shed light on this, we devised an experiment to evaluate the ability of language models to reverse words. Our aim was to determine if the models could manipulate words in a fine-tuned, letter-by-letter manner as opposed to the current method of splitting words into tokens. We compared the performance of five OpenAI models using four categories of inputs under six different prompt designs. Our results showed that valid English words had the highest probability of being reversed correctly compared to numbers and non-valid words and that longer words had a negative impact on the success of reversal. Additionally, we found that the success rate of the task was dependent on the competence and size of the language model, with better performance seen in more advanced models.
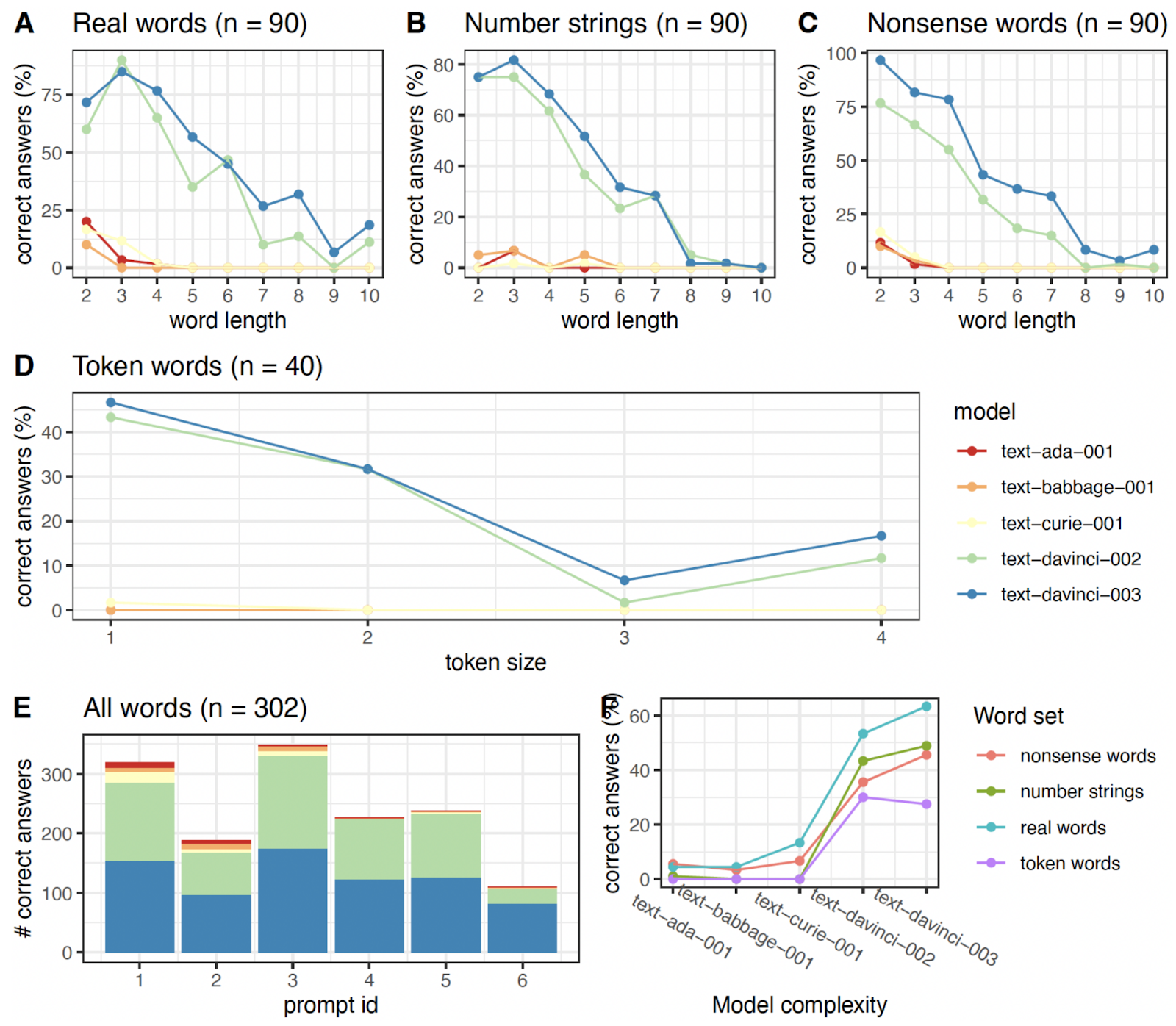
Model performance on different word sets. A) Percent of correctly reversed real words for increasing word lengths shown for each model. B) Percentage of correct answers for number strings with increasing lengths. C) Percent of correct answers for nonsense words with increasing length. D) Percentage of correctly reversed words with differing token size. E) Percentage of correctly reversed words for individual prompts based on the full word set. Prompt id matches numbering found in the method section. F) Percent of correct answer with increasing model complexity shown for each word set.
Gabriel Recchia’s comment: What's most interesting to me about this entry is the recognition that LM abilities are prompt-sensitive and also often facilitated by a factored approach. In my view the connection to scalable oversight is a little tenuous, but is definitely there as one of the questions was "Evaluate how success of the assignment is affected by model complexity, ie. if the assignment of reversing a word is a potential inverse scaling problem" - if word reversal had been an example of a task where performance goes down with model size, that could potentially shed light on the kinds of alignment failures that are likely to be observed as scale increases. I was a little confused why the sample size was so small given that it would have been easy to generate an arbitrarily high number of stimuli. I'd note that there are ways to factor this particular problem that the authors didn't try, and I suspect the approach described in https://twitter.com/npew/status/1525900868305833984 would have been more successful, or an approach based on the technique described in section 3 of https://arxiv.org/pdf/2205.10625.pdf , but the authors explored this in pretty significant depth given that there were only 48 hours to work with!
Ruiqi Zhong’s comment: It’s a pretty cool study! I think the task is cool and something that is of interest to the scienitifc community. Though I’m a bit confused about the result – what prompts produced Figure 1. A/B/C? Personally I think the prompt is actually the most important factor for the success, since the LM cannot really “see” the characters/letters directly. Looking at A & C – Do non-sense words actually have a lower success rate than real words? It seems that non-sense words actually have a higher accuracy according to the plot. My interpretation is that non-sense words are more likely to get tokenized into finer subparts of a word, thus making it easier for the model to reverse it. Further thoughts on the experimental design: to ablate other weird factors related character frequency, you can design the non-sense words to be the random ordering of the letters of the real words.
See the report and the code.
Honorable mentions
Though these were the winning projects, all projects were very interesting! Here, we share a shorter summary of two honorable mentions:
- In the report “Can You Keep a Secret?”, the authors investigate if language models can keep secrets. The idea might become relevant for future research in deceptive misalignment and tries to attack the model’s secret-keeping ability. Recchia relates it to general work that tries to elicit specific outputs from models [3] and Zhong thinks it’s a benchmark-worthy issue, relating it to earlier work [4]. See the report.
- In the report “Automated Model Oversight Using CoTP”, the authors use chain-of-thought prompting to get better evaluations of the risk profiles of different language model outputs. Recchia describes it as a solid attempt to get LMs to oversee LMs. See the report.
Join the next hackathon!
The next hackathon is happening on the 24th of March internationally and locally at EAGx Cambridge. You can sign up now on the hackathon website to get a chance to work on case studies with excited and driven collaborators and analyze and think about how artificial intelligence will develop into the future and how that path can be safer.
We’re partnering with multiple organizations in the AI governance space and will announce more as we get closer to the launch date. Sign up for updates on our website. You can also join us as a local hackathon site organizer with an opportunity for funding from us (supported by Open Philanthropy). We already have confirmed sites in the US, France, Vietnam, Denmark, UK and more. So read more here and join us in engaging people from across the world in AI safety!
0 comments
Comments sorted by top scores.