Recall and Regurgitation in GPT2
post by Megan Kinniment (megan-kinniment) · 2022-10-03T19:35:23.361Z · LW · GW · 1 commentsContents
Context and Confidence Summary Brief Introduction to Causal Tracing Hidden State Patching A Note on Noise Levels First Investigations Prompt Design Average Causal Traces By Prompt Type Attention by Prompt Type Speculation on High-Level Structure of GPT2-XL Later Layers of GPT2-XL tend to be Semantically Richer Layer-wise fine-tuning in GPT-small Attention on Content vs Position Multiply-tokenised words might need to be "built" Trigger Examples in MLPs MLPs and concept building Attentional Patterns GPT2 likes looking at the first token (on short prompts, and maybe on long ones too) GPT2-XL seems to have 'distributed attention' layers at the start and end of the network. Speculating on Attentional Patterns Speculative Picture of Overall Structure of GPT2-XL Rough Extra Bits On Hidden States None 1 comment
The first half of this post uses causal tracing to explore differences in how GPT2-XL handles completing cached phrases vs completing factual statements. The second half details my attempt to build intuitions about the high-level structure of GPT2-XL and is speculation heavy.
Some familiarity with transformer architecture is assumed but hopefully is not necessary to understand the majority of the post.
Thanks to Euan McLean for editing and Nix Goldowsky-Dill for comments and advice. All views are my own.
Context and Confidence
This post grew out of my final project for MLSS [LW · GW], which was replicating this paper on causal tracing. Most of what I show below is generated with my own code. I used this code to successfully reproduce some plots from the paper, so I’m reasonably (but not 100% confident in it).
I originally planned for this post to be much shorter. But I got curious about certain patterns I found, so decided to dig deeper. The second half of the post (“Speculation on the high-level structure of GPT2-XL”) is an unpolished collection of various bits of evidence alongside my own interpretation and (weakly held) opinions.
Summary
Using causal tracing, I looked at how GPT2-XL completes prompts of differing complexity. Some prompts only required the model to regurgitate verbatim the completion of a common phrase (“regurgitation prompts”), while others required the recall of some factual information about a subject (“semantic prompts”).
Causal traces associated with regurgitation look different to those associated with recall. In each case, relevant information in early tokens is transferred into the last token via attention during the forward pass. But the average layer at which the transfer is centered differs between cases. With regurgitation prompts, the information transfer tends to happen in earlier layers (~ layer 10-15), compared with semantic prompts where transfer happens later (~ layer 30).
This is consistent with the fact that in semantic prompts final token attention is concentrated more heavily on the noised token in the later layers, compared to regurgitation prompts where final token attention concentrates more heavily on the noised token in earlier layers.
A possible explanation for the differing average layer of information transfer across prompt types is that GPT2-XL builds up a semantic representation of the input tokens gradually over many layers, such that later layers contain a semantically richer representation of the input tokens than earlier layers.
Some other bits of evidence in line with this:
- GPT2-small seems to represent more complex syntactic dependency information in later layers, and simpler parts of speech information at earlier layers.[1]
- Attention heads in early layers of GPT-small tend to respond more strongly to positional information, compared to heads in the later layers which respond more to token content.[2]
- With another causal LM, human evaluators more often classify "trigger examples" of MLPs in later layers as representing a semantic concept compared to earlier layers.[3]
- When processing factual recall prompts, the causal effect of MLPs on later layers gradually increases from ~ layer 10-20 in GPT2-XL.[4]
Whilst investigating trends over the prompt types, I noticed that GPT2-XL has some interesting attentional patterns:
- There is disproportionate attention on the first token of a prompt
- The first 8 or so layers and last layer(s) quite consistently have much more evenly distributed attention.
This delayed first token attention seems to also be present in GPT-small, and I speculate that the early distributed attention layers might be associated with things like figuring out syntax, positional pattern recognition, and generally other tasks that benefit from having access to all the tokens together in a close to "raw" state.
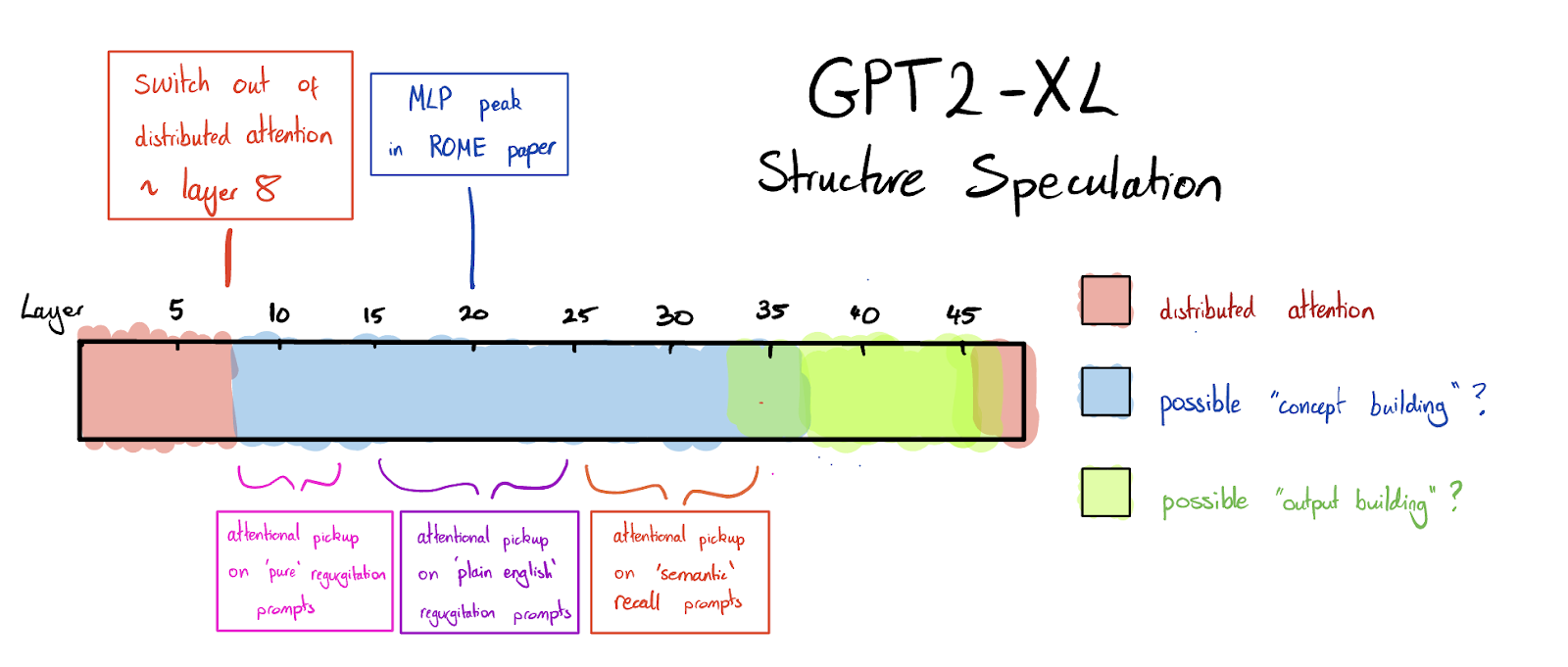
Using all the evidence I looked at, a speculative picture one could present for the high-level structure of GPT2-XL might look like this:
- The first 8 layers of the model are "distributed attention" layers.
- These are possibly involved in sentence or prompt wide processing. For example, the processing of syntax, building multi-token words, and detecting positional patterns.
- After ~ layer 8 "distributed attention" sharply stops, and is replaced by predominately first token attention.
- Now "concept building" begins.
- An internal representation of the input is gradually built up layer by layer, possibly via repeated recall of associations from the midlayer MLPs.
- This building process results in later layers containing a semantically richer representation of the input compared to earlier layers.
- The final token attention "picks out" relevant information at the layer(s) at which this information is prominent in the subject token representation. "Simpler" information (like base rates) is picked out earlier than "complex" information (like semantic associations).
- Layers ~ 7 - 13 tend to be where attentional pickup happens for simple regurgitation prompts.
- Layers ~ 15 - 22 tend to be where attentional pickup happens for simple regurgitation prompts.
- Somewhere between layers 20 - 30, concept building relevant to factual recall is mostly done.
- At some point after layers ~35 - 40 the model switches to focusing on producing the output.
- The model's very last layer(s) are distributed attention 'decoding' layers.
Brief Introduction to Causal Tracing
For an in-depth explanation of causal tracing see the original paper.
Causal tracing is an interpretability technique that can be used to study the flow of information through decoder-only transformers (like most text-generating LLMs). Specifically, causal tracing aims to map the causal influence of particular input tokens on the model's predicted probability of a given output token, and the specific route this influence takes through the model.
Very roughly, this is done by:
- Corrupting some of the input tokens by adding noise to the input embeddings (which changes the model's output).
- Systematically replacing states in each part of the model with the corresponding states of the model when processing a clean version of the input
- Seeing where these replacements have the largest restorative effect on the model's prediction.[5]
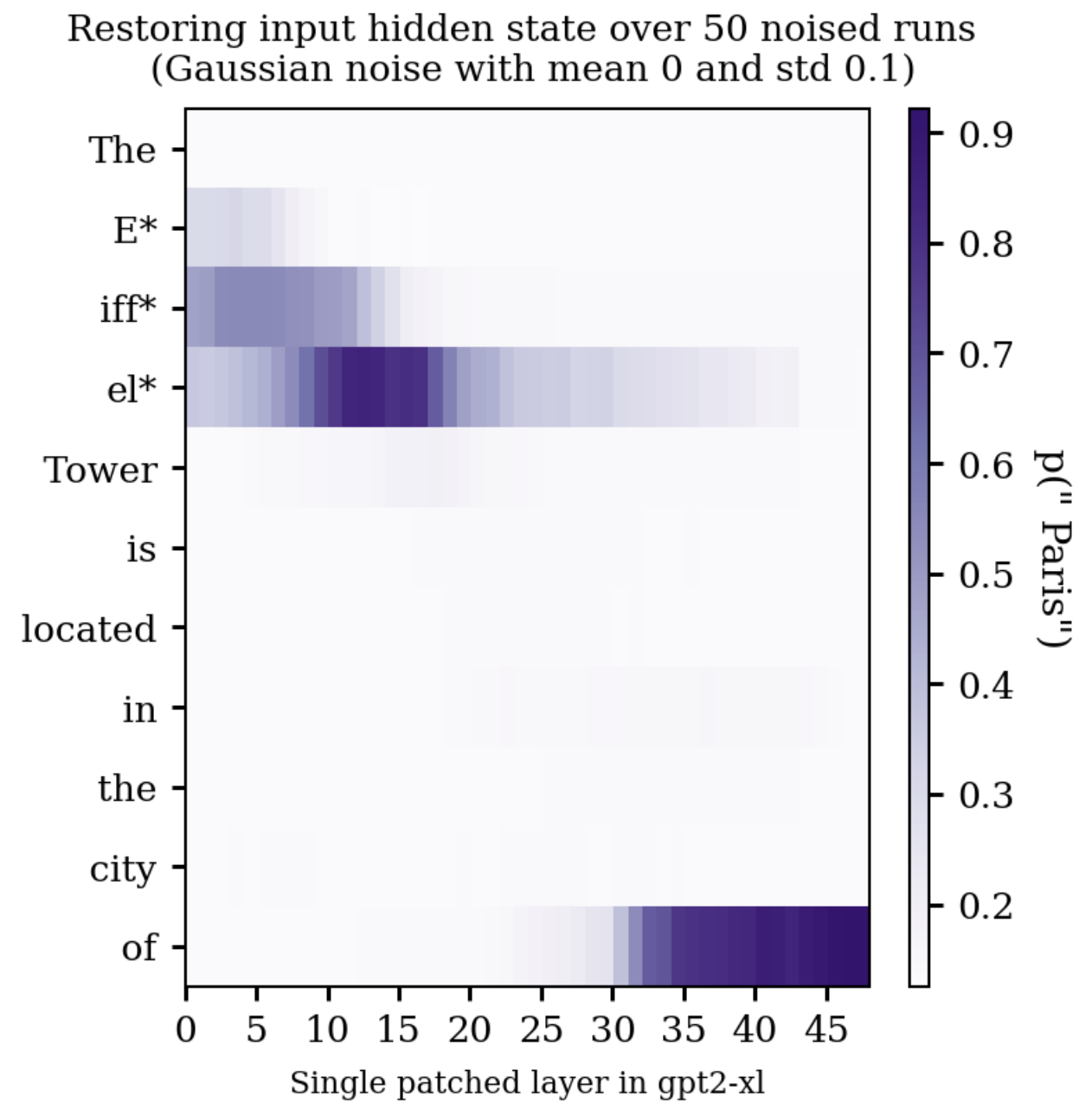
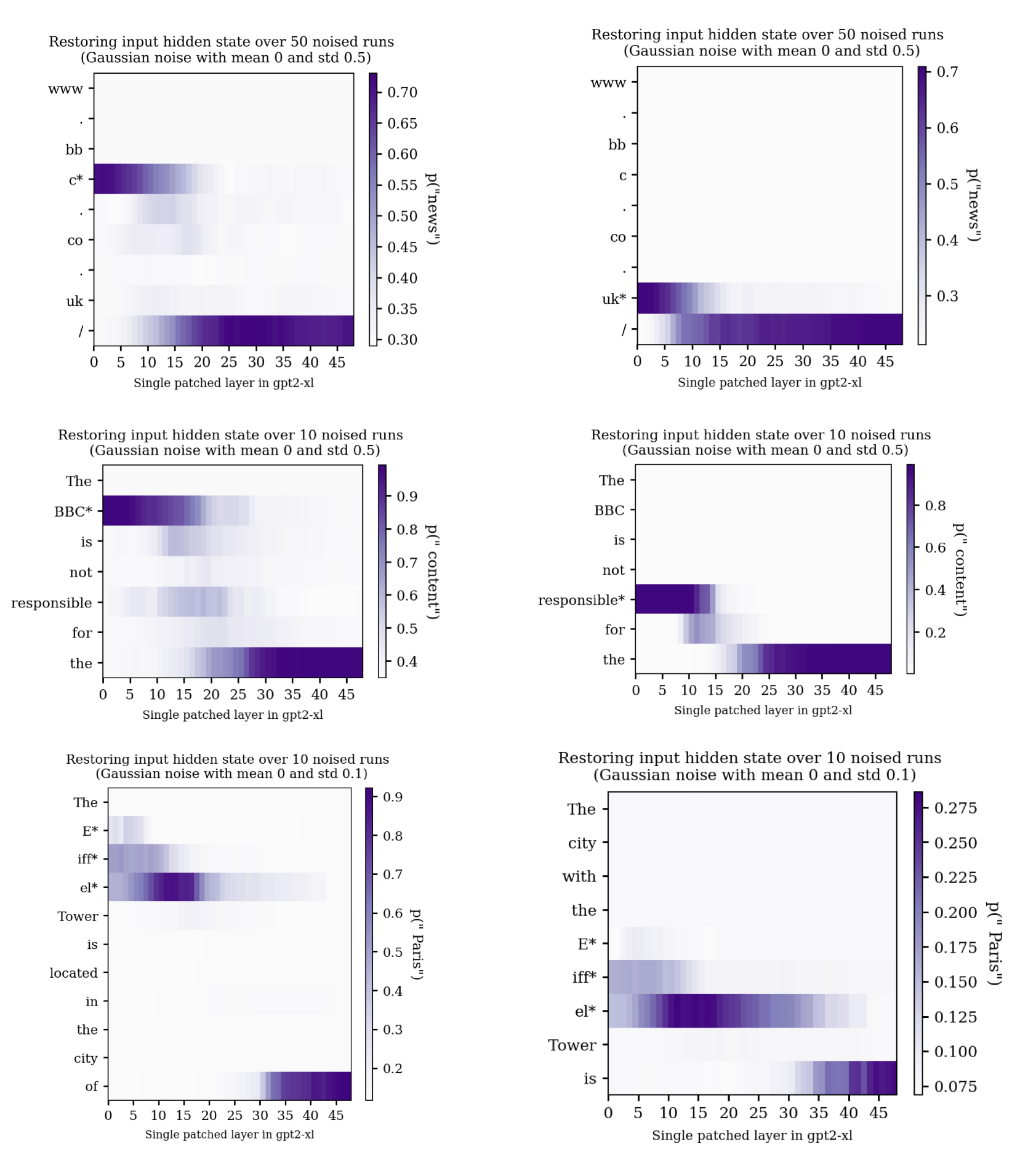
Let's look at an example. Given the input “The Eiffel tower is located in the city of”, we expect the next token to be “Paris”, so want the output p(“Paris”) to be high. When run on a normal un-noised version of this prompt, p("Paris") is ~0.93. When we noise all the tokens in the word “Eiffel”, p(“Paris”) is ~0.1. The restorative effect of fixing the hidden states going into individual layers is shown in the below figure.
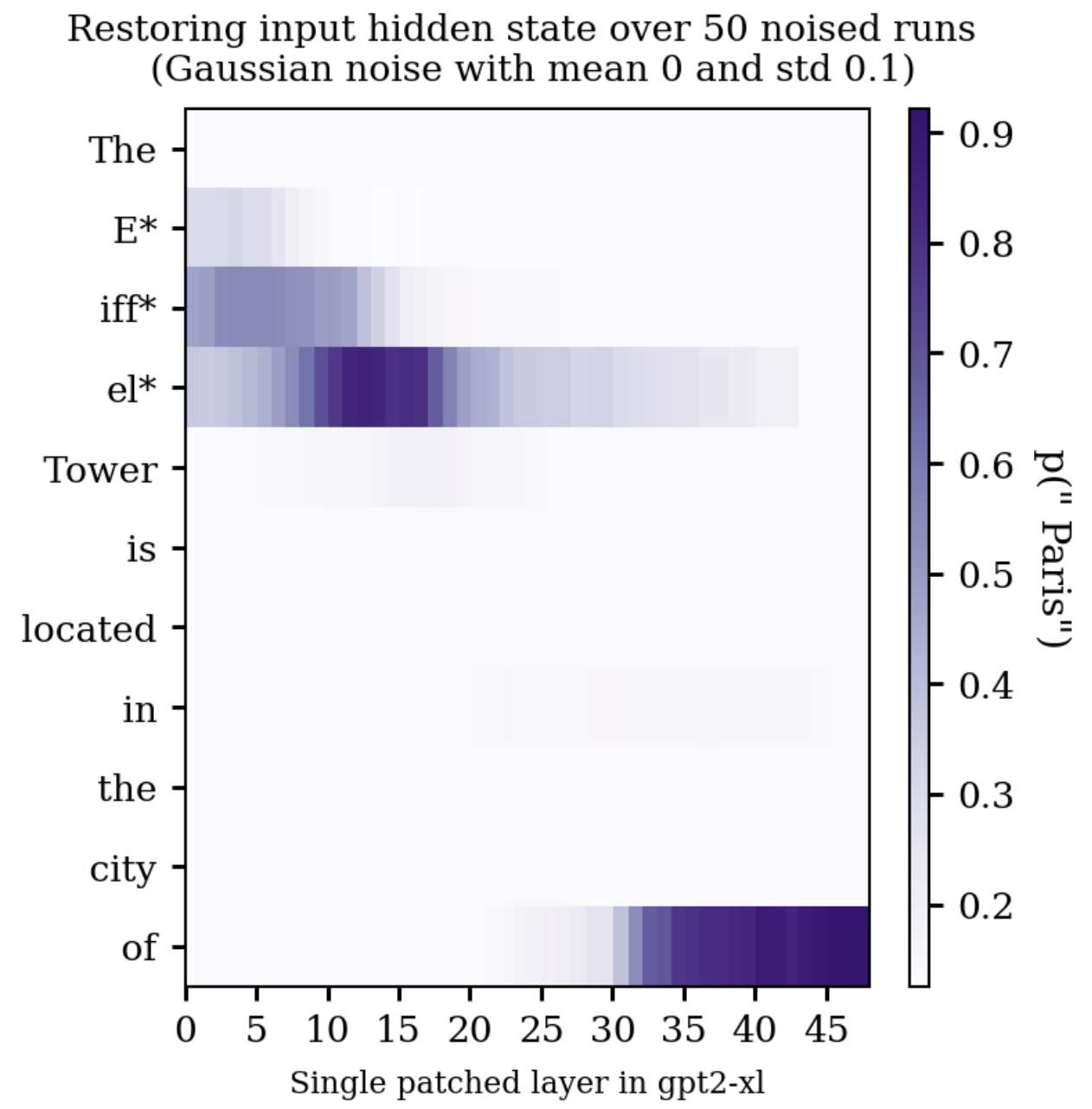
For this prompt and noise level, patching in the corresponding hidden state of a clean pass is particularly helpful in two main places. On the last token of the word "Eiffel" around layers ten to twenty, and the final token from around layer thirty onwards. In these plots information only ever flows rightwards (up the layers of the model), or downwards (the attention mechanism allows the model to "look back" at previous parts of the prompt).[6]
Experiments like these can be used to infer information about how the model processes the prompt. For example, by about layer 35 it seems like the 'Paris' contributions originating from the "Eiffel" Tokens have mostly made their way into the final token hidden state, such that the model has a decent chance of correctly predicting "Paris" if we restore the input hidden state in one of these last layers on the final token. In the original paper, the authors use this technique (and variations specific to MLP and attention layers) to argue that factual information is stored in midlayer MLPs of LLMs.[7]
Hidden State Patching
All the causal traces I show in this post patch hidden states, specifically the input hidden state into layers. So any references to “hidden states” are referring to these input hidden states into layers (and not MLP residuals for example).

A Note on Noise Levels
To corrupt some of the input tokens, gaussian noise is added to their embeddings. The strength (standard deviation) of this added noise can affect the results of causal tracing.
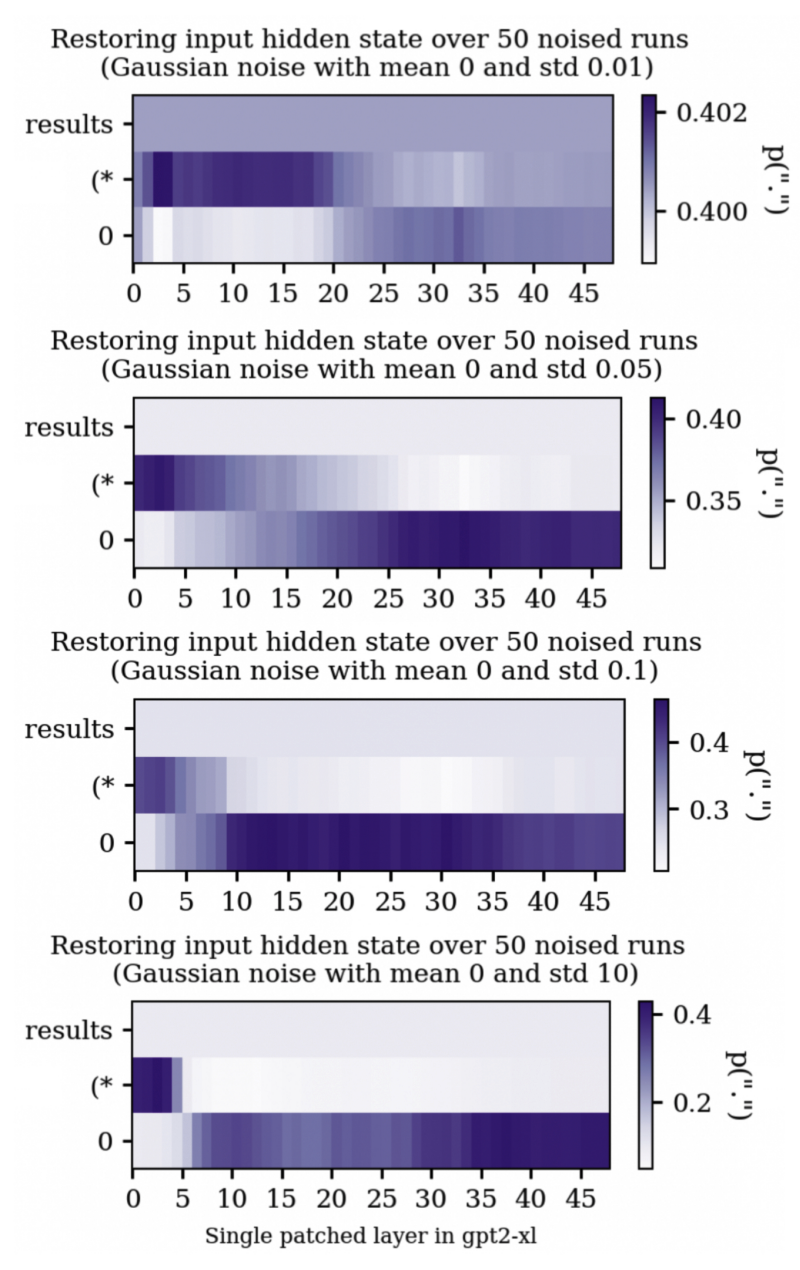
Stronger noise widens the range of probabilities put on the 'correct' answer when patching different states, which tends to result in sharper, more even-looking traces for higher noise levels, but intermediate probabilities get obscured in plots. In all of the prompts I will be using, the first token will not be noised. This makes the first token a convenient baseline for comparison, because it is equivalent to how the model performs when it is given noised inputs but is not given any help via patching. Very low noise levels are more likely to result in traces where patching in certain areas is strongly unhelpful (relatively speaking). A somewhat similar effect seems to happen for very high noise levels also: some areas where patching is helpful at lower noise levels can become actively unhelpful when patched at higher noise levels.[8]
The original preprint uses a noise level of around 0.1 (based on the standard deviation of the input embeddings of the subjects in their own prompt database). I ended up using noise levels higher than this (0.5) since many of the prompts were quite 'easy' for GPT2-XL, so it took a bit more noise to bring the traces out of the very low noise regime. This seems like quite a lot of noise, and given the fact that the embeddings are so high dimensional, I would expect this will tend to take the input embeddings quite far from their original positions. It also seems worth bearing in mind that the exact results of these traces seem dependent on the chosen noise level in a potentially not very straightforward way, and it isn't very clear to me how to pick this noise level in a principled way.
Finally, noising the tokens like this takes the model off distribution - since it is being forced to deal with input embeddings that it will never have encountered in training. This could cause the model to behave in weird ways, or display behaviour it usually wouldn't when processing normal text.
First Investigations
The original preprint focused heavily on factual / association recall. I wanted to see what the traces of other kinds of tasks might look like, particularly very simple tasks. One of these simple tasks was verbatim regurgitation of common text snippets. For example, GPT2-XL can predict that ".co." is most likely followed by "uk", or that "From Wikipedia, the free" is most likely followed by " encyclopedia".
I noticed that with these kinds of regurgitation prompts, the “streak” of high causal influence present in later layers of the last token seemed to have a varying start location. With regurgitation prompts having a last token streak that starts in earlier layers compared to factual recall prompts. To be specific, the layer at which restoring the incoming hidden state on the final token starts to become effective for increasing the probability on the top original prediction seems to start earlier for regurgitation prompts than factual recall prompts.
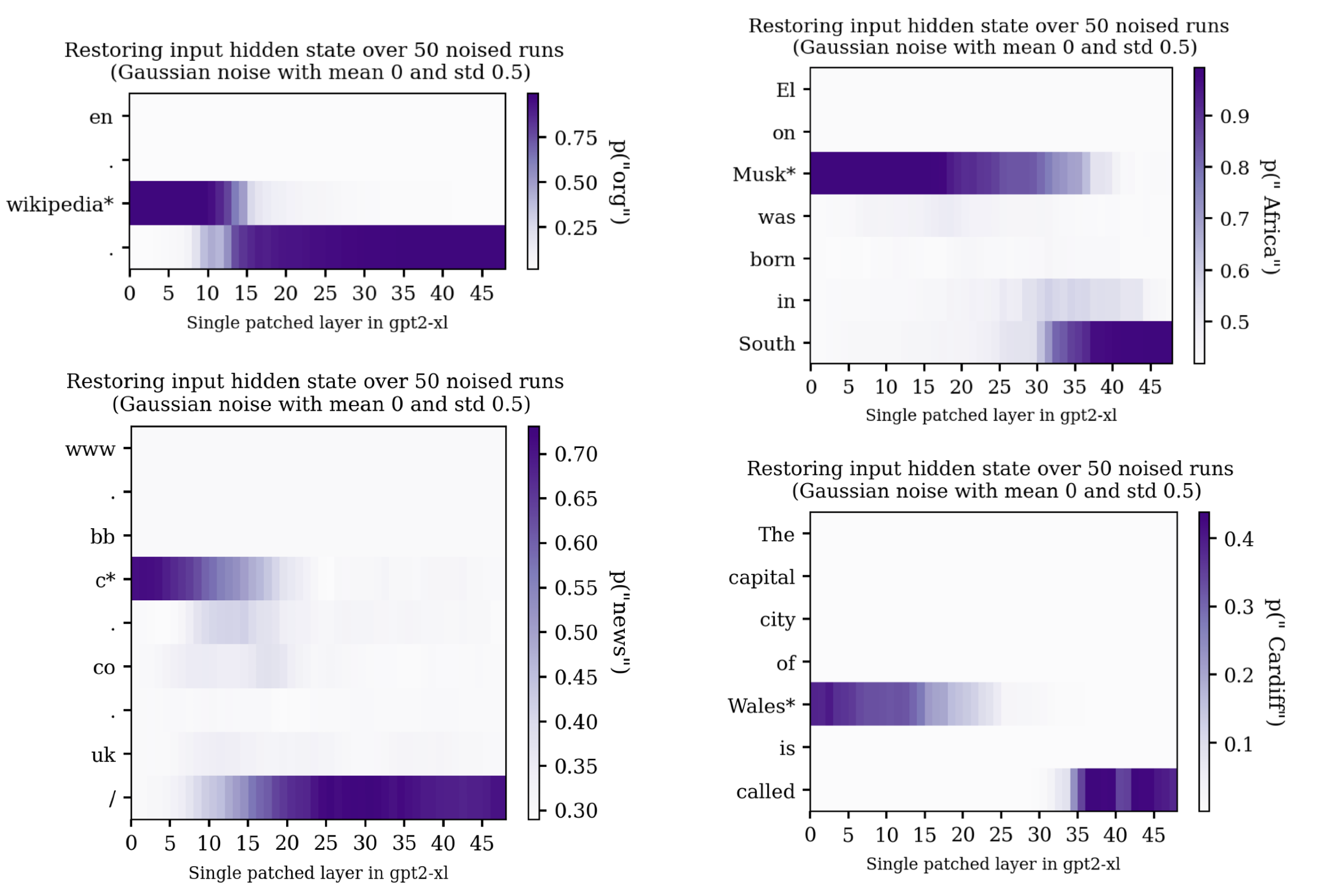
It also seemed like regurgitated phrases written in plain English tended to have final token streaks that were somewhere between the pure regurgitation prompts and the natural language factual/association recall prompts:
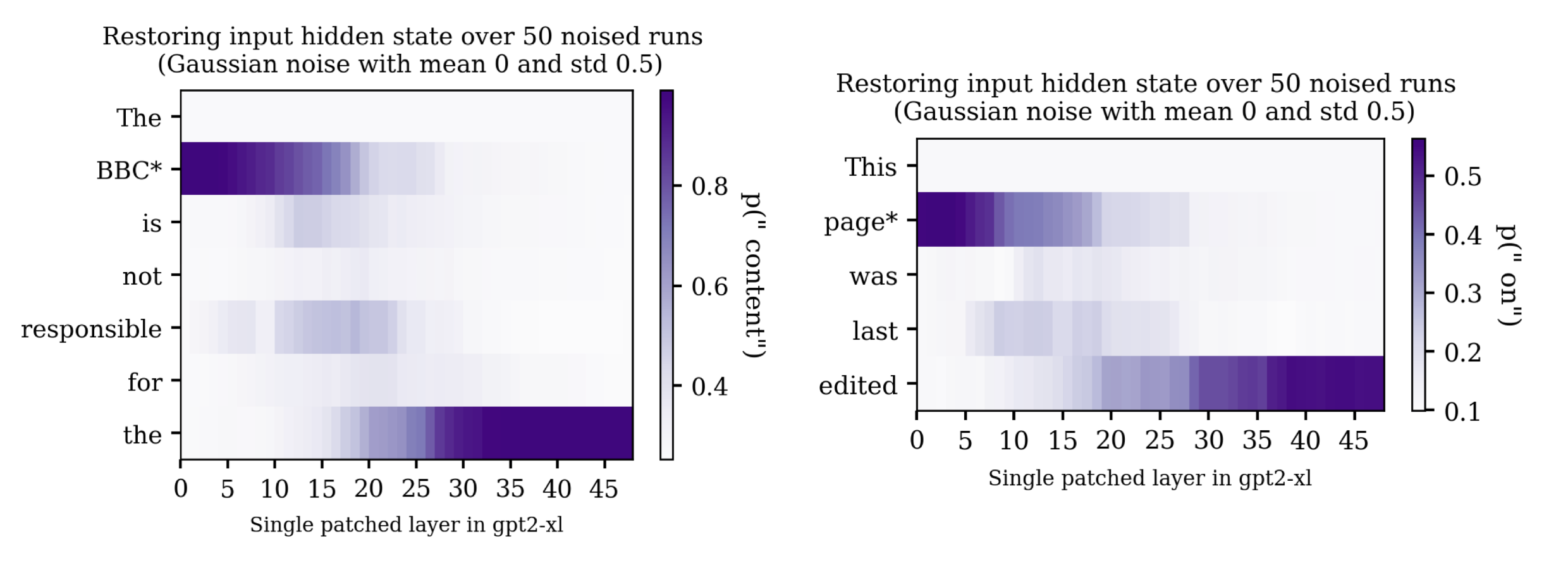
Additionally, sometimes there would be a fairly sharp transition where patching efficacy would decrease on the noised token and simultaneously increase on the last token. The trace of completing ".co." is a particularly clear example of this:
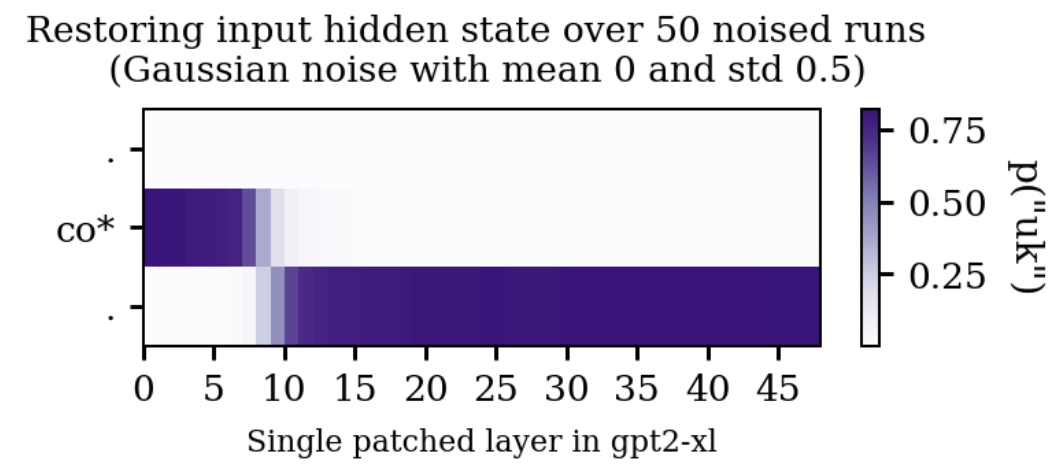
I wondered if these kinds of transitions might correspond to the attention of the final token 'picking out' the relevant information from the previous token, and the layer at which this information handover happened might have a relationship to the kind of information that is being extracted at that point. Specifically, is the layer at which the relevant information enters the last token related to that information's complexity/semantic richness?
Prompt Design
To get a better idea of whether this was a more general pattern, I came up with a small dataset of ~40 prompts split into three categories.[9] "Pure" / Non English Regurgitation, Plain English Regurgitation, and Semantic Prompts:
| Examples (Bold is expected completion) | |
|---|---|
Non English Regurgitation | .co.uk 3.1415926535 TCP/IP |
Plain English Regurgitation | From Wikipedia, the free encyclopedia contributions licensed under Make America Great Again
|
| Semantic | The capital city of Wales is called Cardiff Elon Musk was born in South Africa |
Ideally, non-english regurgitation prompts are sequences of tokens such that knowing the semantic meaning of the individual tokens that make up the sequence does not help predict the next token in the sequence, or is at least far less helpful than just "knowing the phrase". For example, knowing the semantic meaning of "159" and "265" doesn't seem very helpful for predicting the next digits of pi. Non-english regurgitation prompts should ideally be pretty common in the training, and the base rate of (prompt + expected completion | prompt) should ideally be very high.[10]
Plain English regurgitation prompts are much the same as non-english regurgitation prompts, except the use of plain English often means that there is a degree to which understanding of the semantics of the individual tokens is plausibly helpful for prediction, and tokens/subsections appearing in the prompt are more likely to show up in semantically relevant ways in other contexts.
Semantic recall prompts are fact completions. Semantic information (i.e. information about what the language is referring to) should be extremely helpful for next token prediction and the verbatim completed phrase should not be very prominent in the training data (to try and reduce the chance that the model is just regurgitating).
I found the semantic recall prompts the trickiest to make. It was harder than expected to find prompts that simultaneously: 1) had an answer to a semantic question as the next token, 2) had a single token subject to noise 3) were easy enough for GPT2-XL to get right, and importantly 4) wouldn’t be regurgitated verbatim. In practice, the fourth point doesn’t seem to be a huge issue, since phrases need to be very common in the training data for GPT2-XL to reliably regurgitate them verbatim. For example, the model doesn't seem to be able to reliably regurgitate phrases which seem like they would be much easier to learn to regurgitate than the semantic prompts, such as the lyrics to Bohemian Rhapsody.
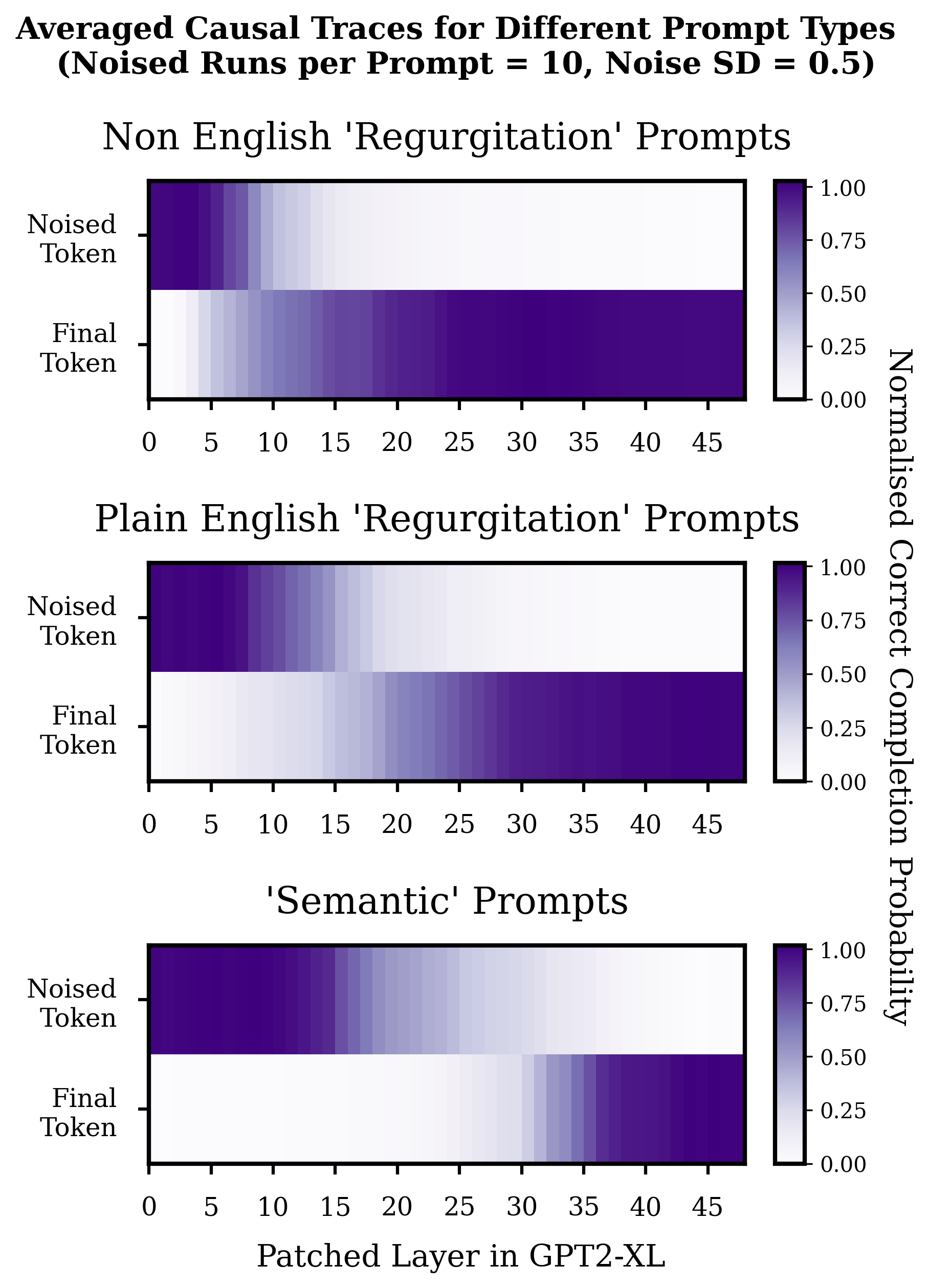
Average Causal Traces By Prompt Type
Plotted below are averages of all these causal traces split by category.
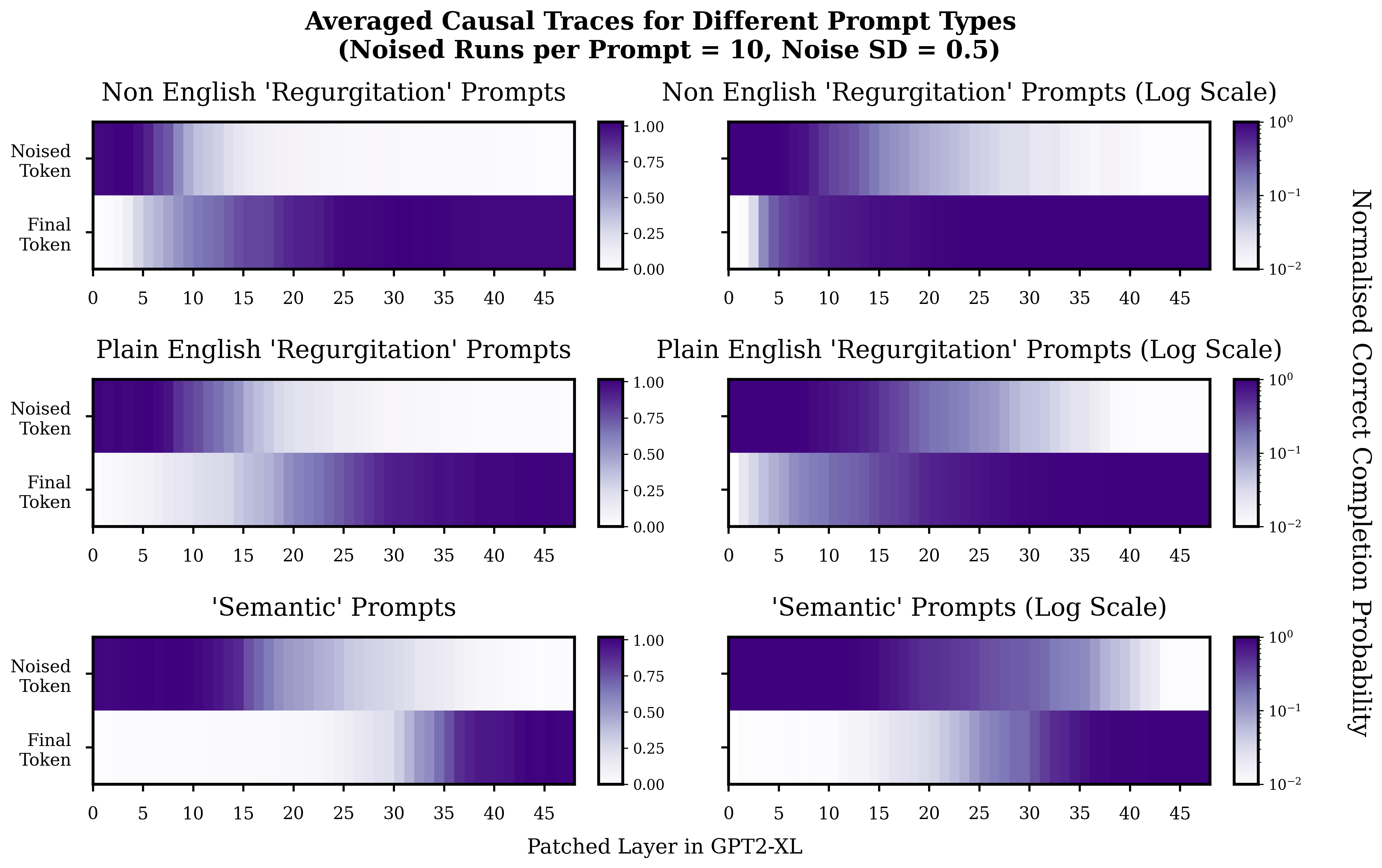
Since the prompts can be of different lengths, only the single noised token and the final token are shown in the averaged traces. The probability on the correct completion is normalised to account for the fact that the range of probabilities on the correct token can differ wildly between prompts. Normalisation is such that zero corresponds to the average probability the model puts on the correct token when it is given noised inputs, and is not given any help via patching, and one corresponds to the probability that the model puts on the correct token when the input is not tampered with.
At least for the prompts in this small dataset, it seems like there is a pretty clear difference in the center of the area of 'transition' between the noised token and final token. For the non-english regurgitation prompts this area of transition seems centered around roughly layers 7-13, and for the plain English regurgitation roughly around layers 15-22. Things look a bit more asymmetric for the semantic prompt[6] but around layers 25-35 seems to be the point at which the relevant information from the noised token enters the final token. These results also seem to be robust to reasonable decreases and increases in noise level.[11]
These traces are also consistent with a relevant attention lookup from the final token on the noise token happening around the center of transition. For the semantic factual recall prompts, the average layer of transition is in roughly the same place as the large attentional spike found in the original causal tracing paper (from now on referred to as the ROME paper). See the red line in the rightmost graph of the below figure:
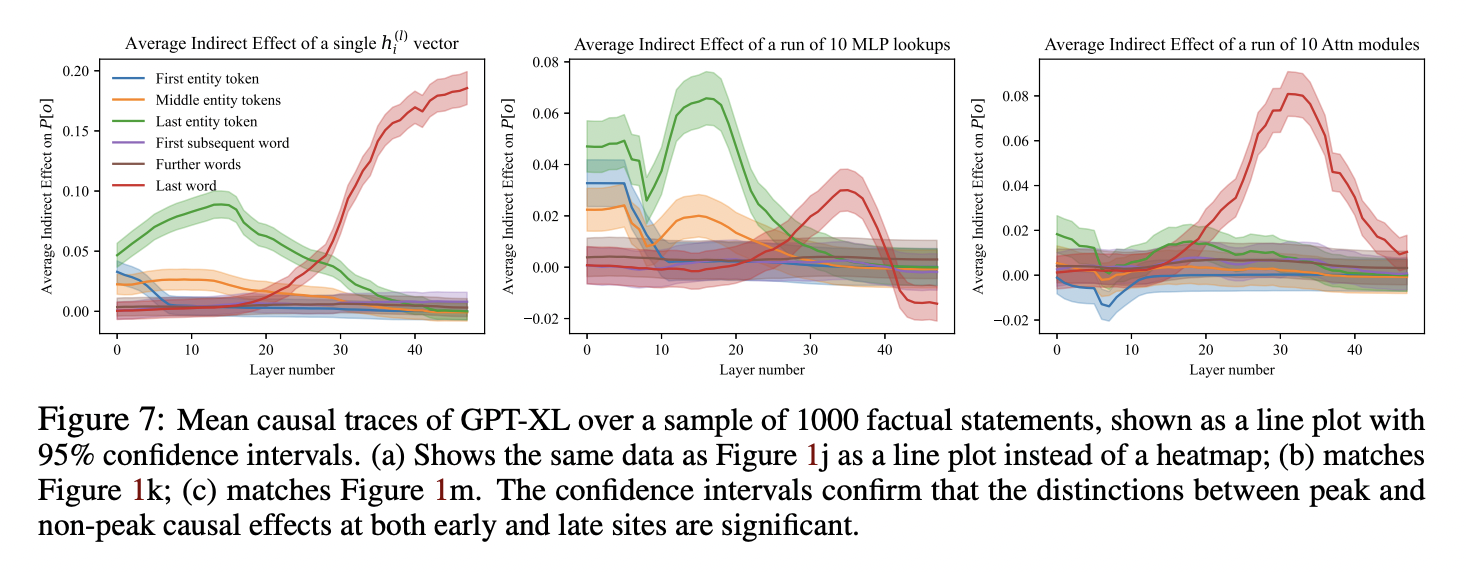
So it seems likely that the point at which the attention of the last token picks out the relevant information from the noised token is pretty much the same for my 'semantic' factual recall as for the prompts in the ROME paper. This is pretty expected (but reassuring), since the only real difference between my semantic prompts and the ROME prompts are that I tried to use single token subjects, and only noised that one token, whilst the ROME prompts have multi-token subjects and noise all subject tokens.
Attention by Prompt Type
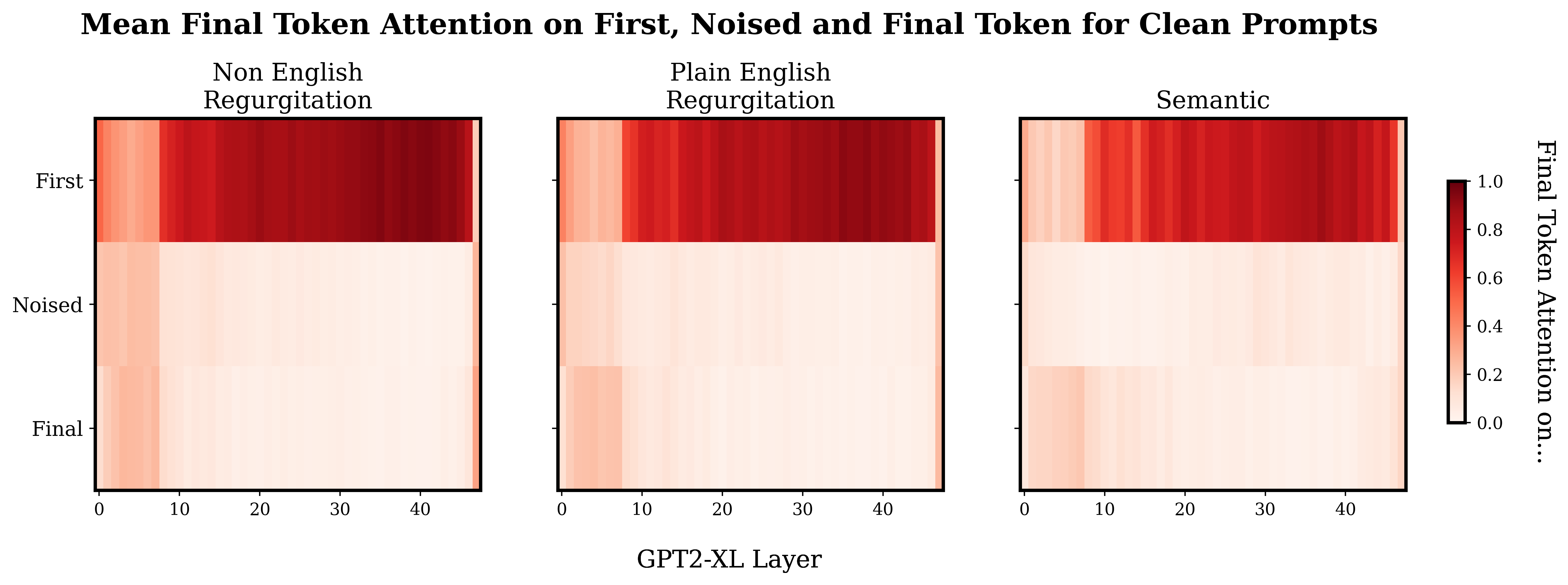
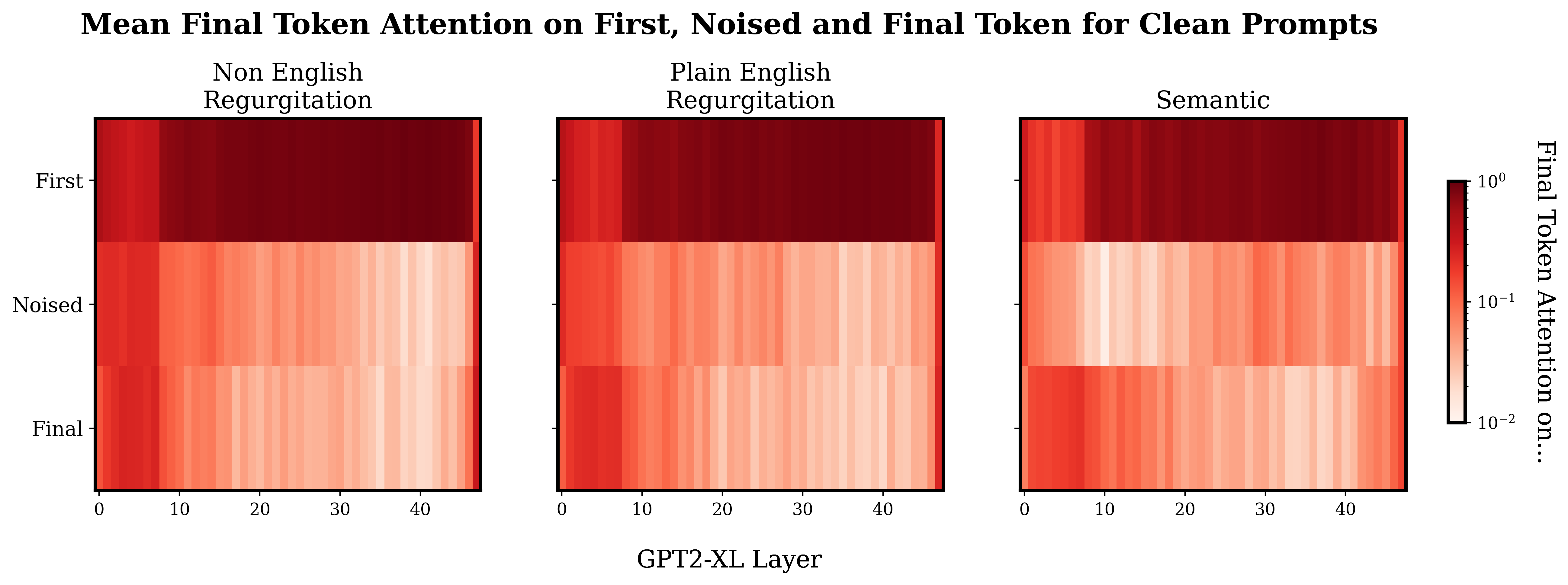
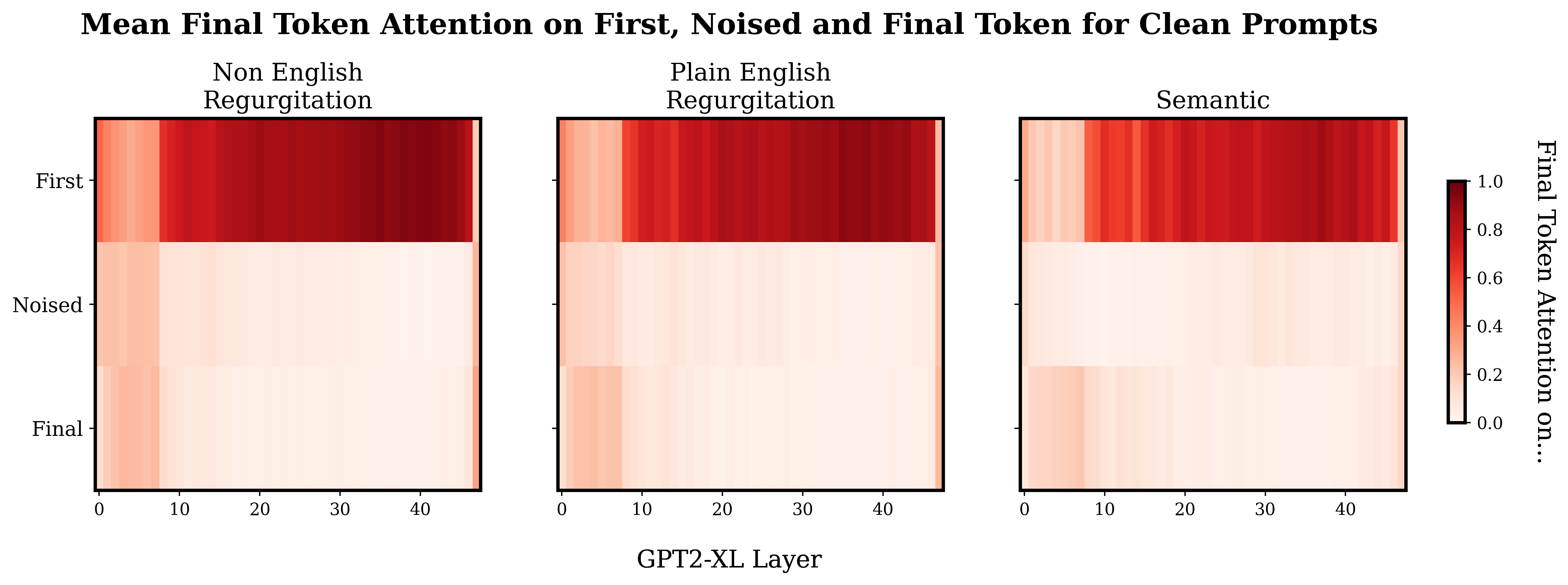
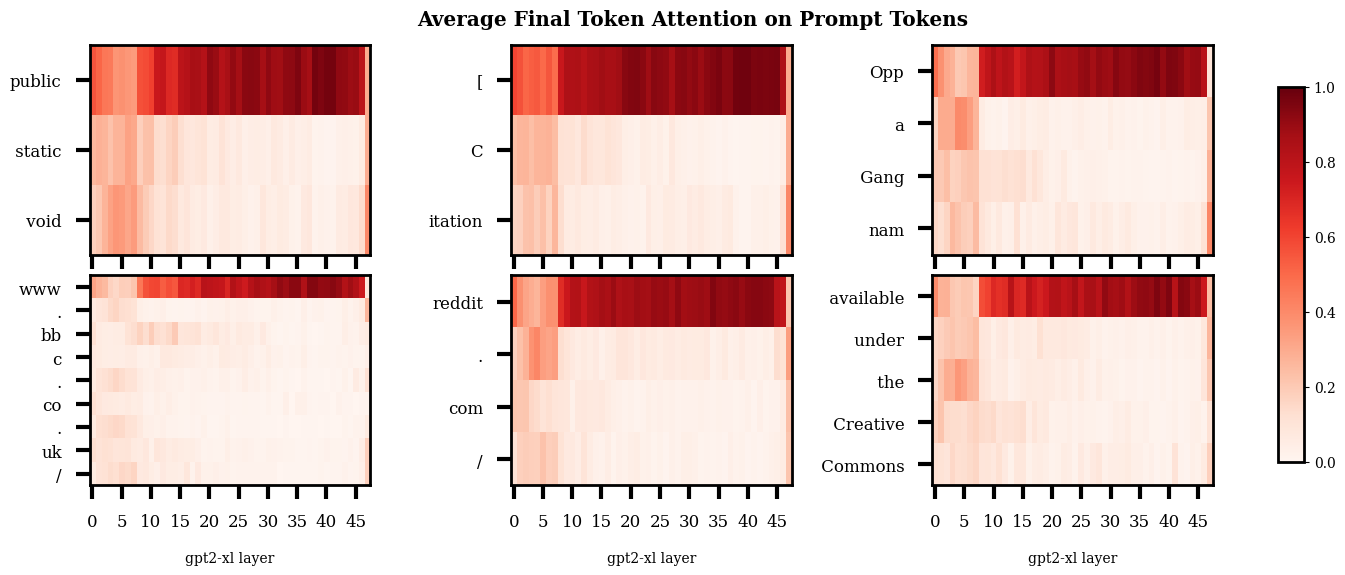
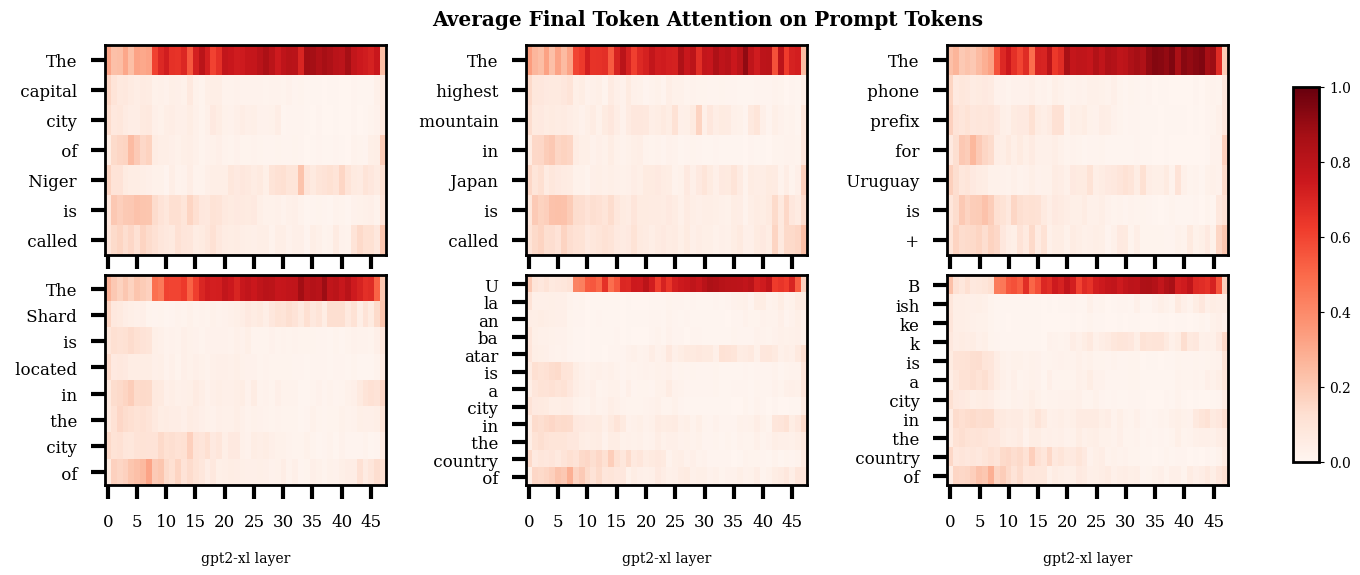
I was interested to see if there was an obvious trend in the distribution of final token attention between the different prompt types. Specifically, I expected that the last token attention in the regurgitation prompts would focus on the noised token more in the earlier layers, and in the semantic prompts more in the later layers.
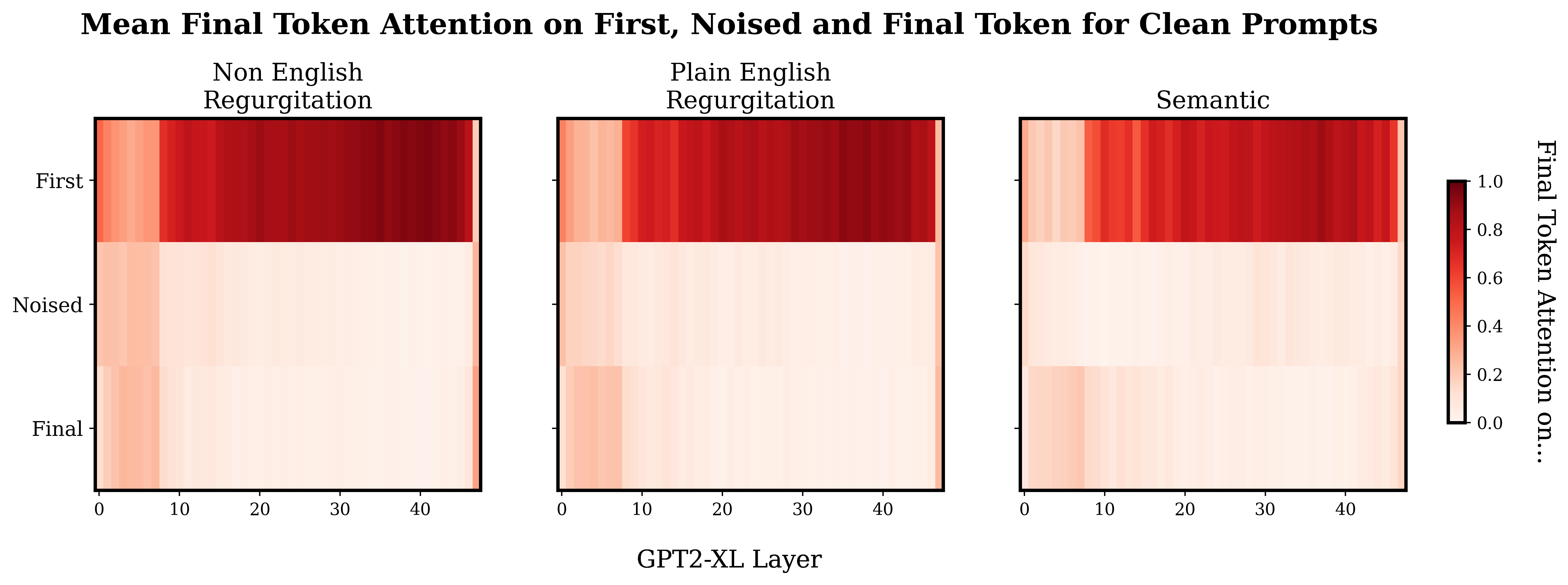
Above is a plot showing how the final token allocates attention. Note that these plots are not causal traces, this just shows the average final token attention when the model is processing the normal, un-noised prompts.
So, when I first saw this I assumed that I had just messed up some indexing or something. Why is there so much attention on the first token? Why is there this weird stripe in the first few layers? What's with the weird final layer? After a fair amount of 'debugging' and later some googling - I’m pretty sure this is just how it is. I explore these more general patterns a bit later ("Attentional Patterns" sections) but for now just know that the heavy first token attention has been observed by other people, and equivalents to the weird start and end layers seem to be present in smaller versions of GPT2.
Slapping a log scale on the plot shows a weak version of the sort of pattern I expected to see originally, with a slightly heavier mean concentration of final token attention on the noised token in the later layers for the semantic prompts compared to the regurgitation prompts.
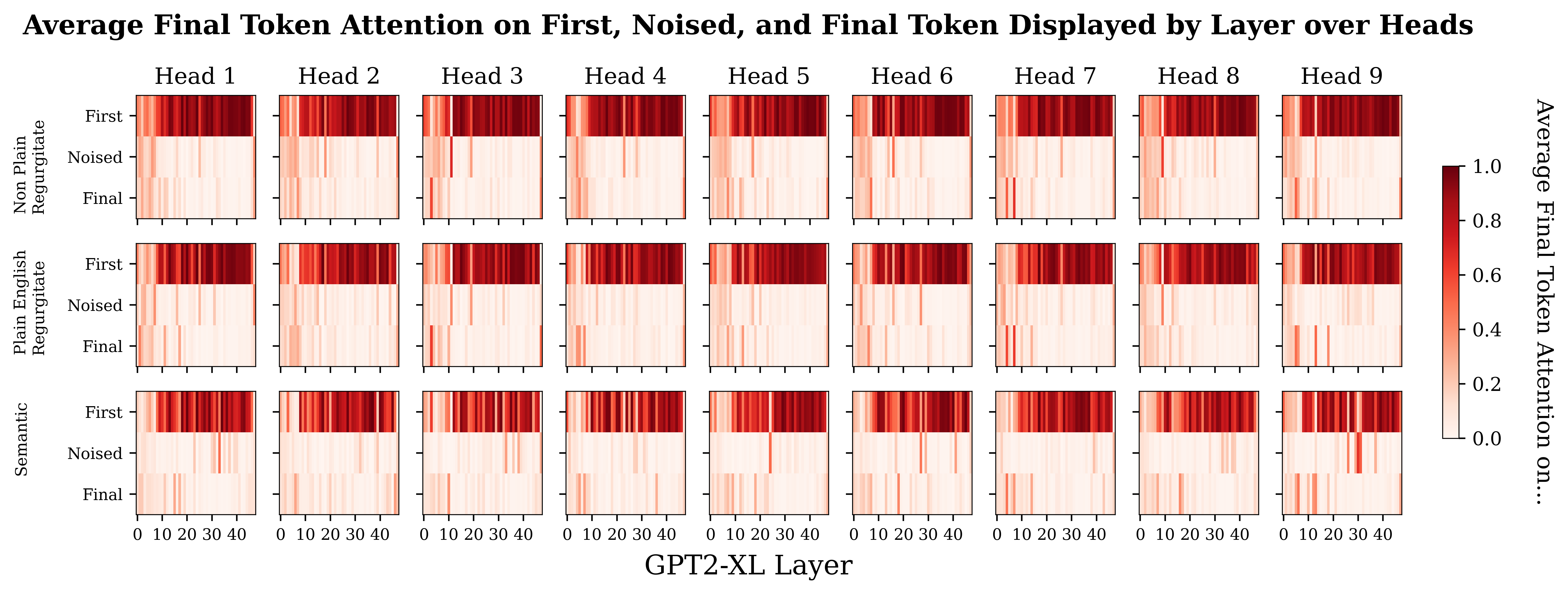
Plotting the same data out for the individual heads shows stronger differences in some heads. Below I show a few heads with some particularly prominent differences between the prompt types. Plots for all the heads are in the footnotes.[12]
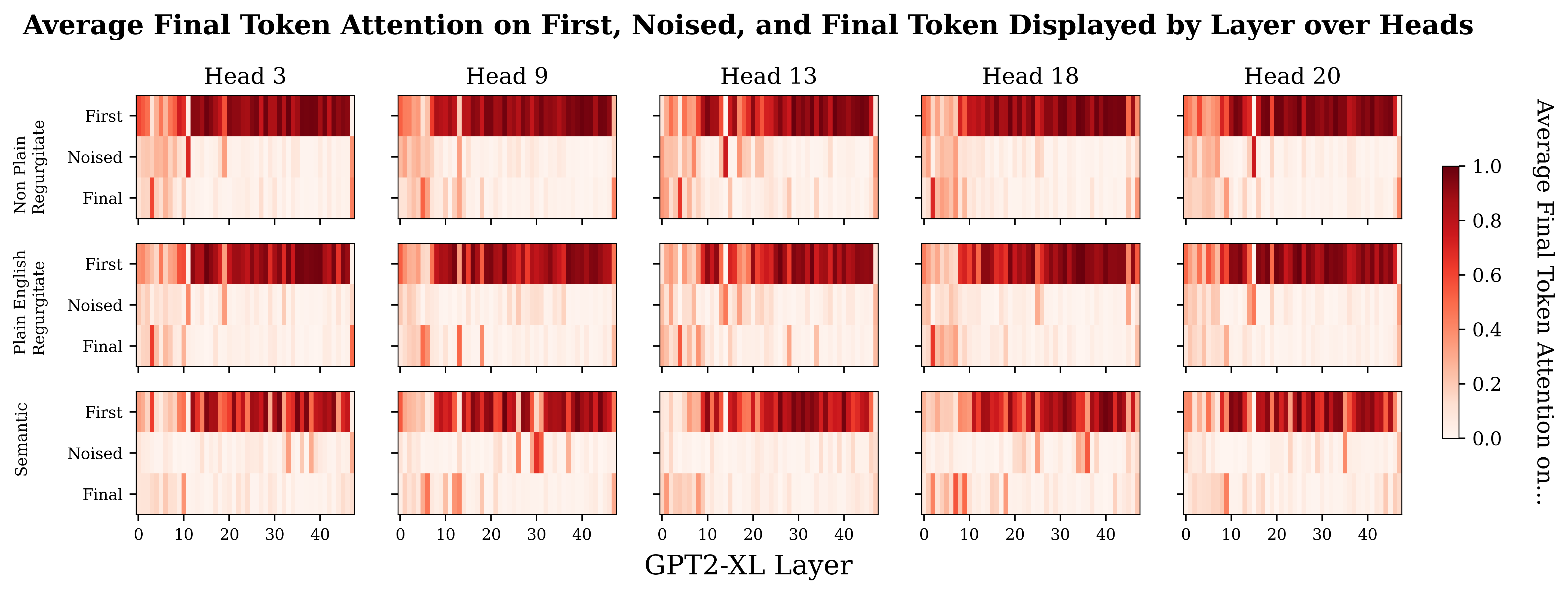
I feel a bit wary of concluding too much here, but it does seem like the semantic prompts have more attentional spikes in later layers than the regurgitation prompts, particularly around and post layer 30. The differences between the semantic and regurgitation prompts seems more obvious to me than the differences between the regurgitation prompts.
So at this point, I’m relatively confident that there is a trend that attentional pickup of relevant information happens later for the semantic prompts than for regurgitation prompts.
One would be right to point out that ‘semantic-ness’ is not the only possible cause for this trend. For example, one confounder is that semantic prompts tend to have more tokens between the noised subject and the final token than the regurgitation prompts. I did check some prompts here to see if this token distance factor was important, and at least from the examples I checked, the token distance seems to have either no or a very small effect on when the final token streak starts.[13] Another potential confounder is the model's original confidence in its top prediction. Regurgitation prompts tend to be 'easier' for GPT2-XL to get right than factual recall prompts. This confounder is harder to investigate, since the easiness of the prompts is strongly related to their regurgitatey-ness - and it wouldn't surprise me if this has some effect on the attentional pickup layer. At least in the Eiffel Tower prompt in the footnotes, this doesn't seem to make a huge difference.
More generally, given all the potential confounding factors, the evidence above in isolation isn’t enough to causally attribute the trend to semantic content. However, there are other reasons to think there might be a causal link here, which brings us to the second half of this post...
Speculation on High-Level Structure of GPT2-XL
In this section, I use a few bits and pieces of evidence to try and get intuitions about the high-level structure of GPT2-XL, and what it is 'doing' at different layers.
Later Layers of GPT2-XL tend to be Semantically Richer
To me, later layers containing a semantically richer representation of the input tokens wouldn't be very surprising. Information in later layers has inherently had an opportunity for greater processing than information in earlier layers and we already see this kind of increasing feature complexity in CNNs.[14] However, transformers are very different to CNNs, and next token prediction is very different from image classification, so it doesn't seem like a given that the properties of one would transfer to the other.
Having said that, other people have found indications of similar layer-wise structures in transformers. Let’s take a look at some of them.
Layer-wise fine-tuning in GPT-small
Alethea Power's post, Looking for Grammar in All the Right Places, looks at GPT2-small (a 12 layer version of GPT2). They find that information about syntactic dependencies of the input (which involve understanding a word in the context of other words) seem to become more available around layer 3-4, whereas more simple parts of speech information - which can be inferred from single words alone - seem to be understood in earlier layers.[1]
To study the differences between the layers, they tried chopping down the size of GPT2-small by removing all layers after layer n and replacing them with a linear layer. They fine-tuned that linear layer for classifying the input tokens by parts of speech or syntactic dependencies. Results are shown in the figures below. We can see it's much harder to train a classifier of syntactic dependency on layers 1-2 than it is to train a parts-of-speech classifier on those layers.
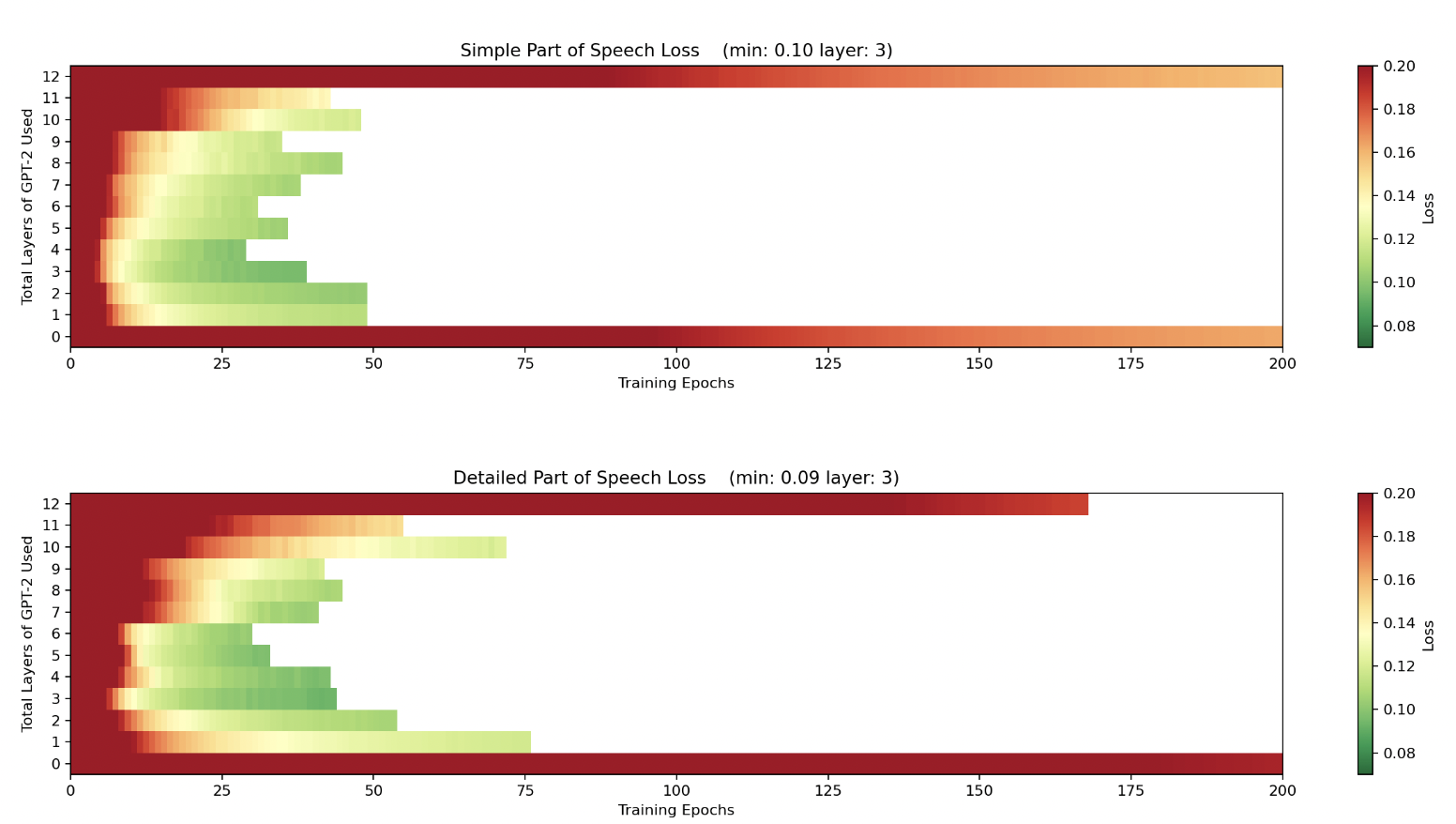
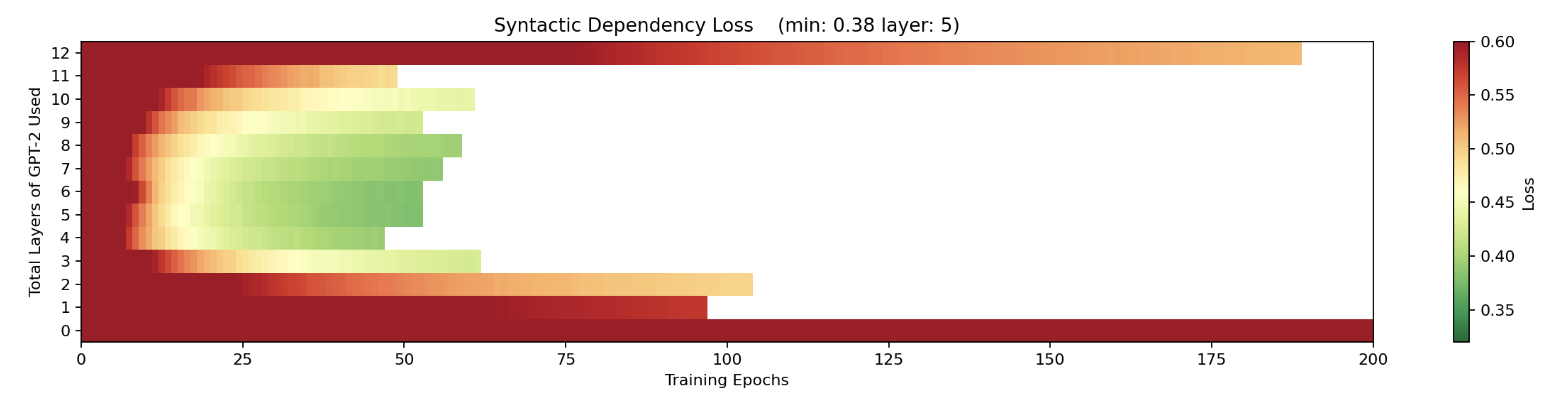
They also try shifting the positions of all the tokens to the left, so that the classifier is effectively now trying to classify the syntactic dependency of the predicted token, rather than the ingoing token. When they do this they find that the latter half of the model is much better for this than the front half. They point out that this would be expected if the first half of the network mostly dealt with processing the input, and the back half mostly dealt with constructing the output. Also, note that the high loss in the last layer that was present in the other graphs is much lower here.
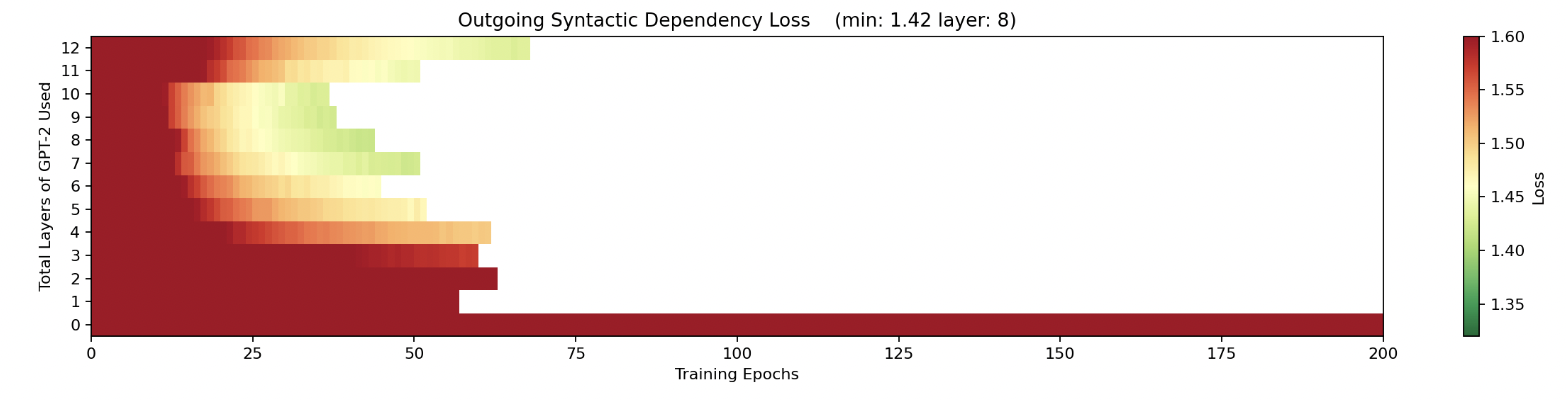
So in this case it seems like simpler information processing (like of parts of speech) happens in earlier layers compared to more complex processing (like of syntactic dependencies). I also think it's interesting how the back half of the network seems to focus on constructing the output.
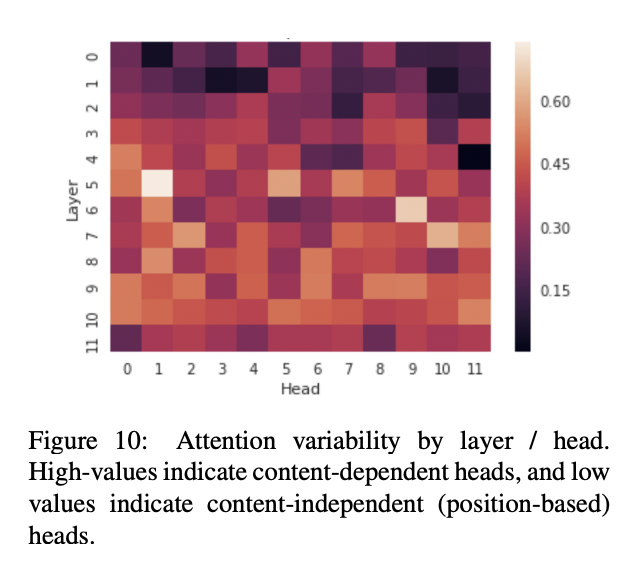
Attention on Content vs Position
A paper looking at attention in GPT2-small found that attention heads whose attention mainly varies with the content of tokens (compared to positional heads that mainly vary with regards to positional information), are in general, more prominent towards the later layers, and seem less prominent in the first 3-4 layers and last layer of GPT2-small. [2]
Multiply-tokenised words might need to be "built"
GPT2 uses a sub word tokenizer, which means that a single word can be comprised of multiple tokens:


This means there is not always a clean 1-1 mapping from input tokens to words or subjects. From the ROME paper it seems like conceptual associations are mostly retrieved from the last subject token when completing factual recall prompts:
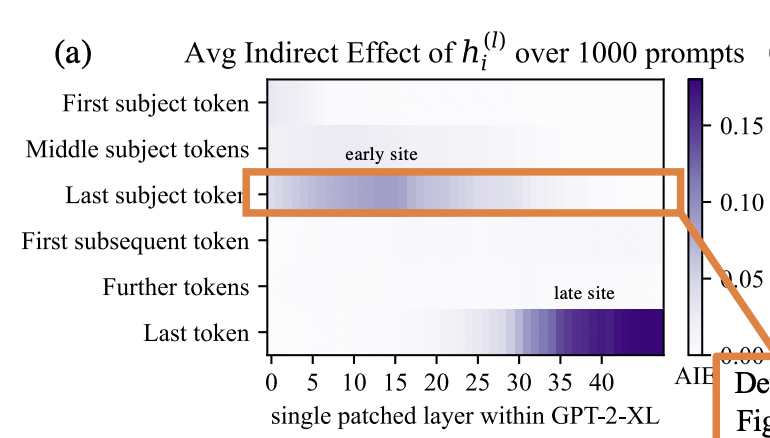
And I find the traces with multiple noised subject tokens also a bit suggestive of a 'trickling down' of relevant information into the last subject token.
Trigger Examples in MLPs
Other causal LMs seem to have a similar pattern of semantic concepts being associated with later MLPs. The below figure is from Transformer Feed-Forward Layers Are Key-Value Memories.[3]
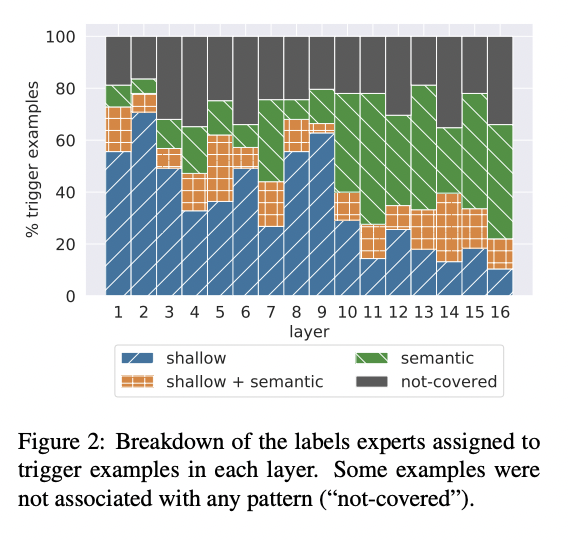
This is a graph of how people categorised 'trigger examples' for the MLPs of a 16-layer network trained on 'Good' and 'Featured' articles on Wikipedia. They frame the MLP layers as a key-value store, and find 'trigger examples' that correspond to certain MLP 'keys'. Trigger examples were created by choosing some random hidden dimensions for the MLP layers (or as they call them, some random key vectors for some MLP layer), then searching the entire training dataset for the top 25 examples whose representation going into that MLP has the highest inner product with the chosen key vector. They then get humans to categorise these top 25 trigger examples by the kind of concept or pattern they seem to encode. For example, a shallow set of trigger examples are some prompts that end in "substitutes", whilst one semantic set of trigger examples all have a "part of" relation, and another all feature TV shows.
Sidenote: I haven't read this paper in detail but I do want to flag that it seems pretty interesting, and this group of authors have a lot of interesting stuff. Like this paper on how the network might build up predictions, this one on projecting the residual stream into embedding space, and recently this one using some more embedding space projections that looks cool but which I have only very briefly skimmed.[15][3][16]
MLPs and concept building
The ROME paper (Locating and Editing Factual Associations in GPT) argues for the importance of midlayer MLPs for correctly answering factual questions.
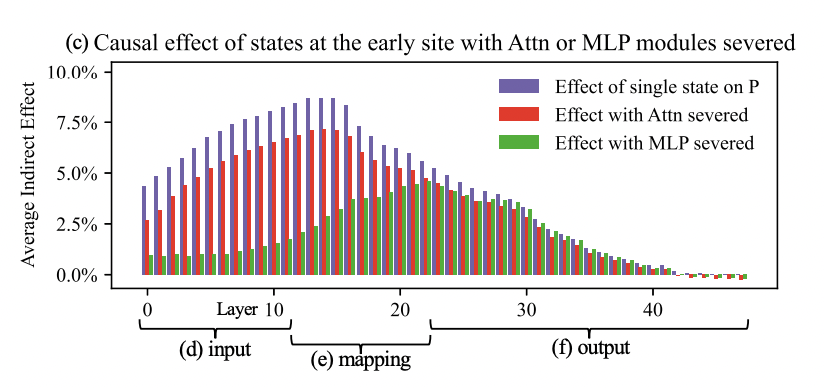
This figure shows the causal effect that lower layer states have on higher layer states, when different parts of the network are severed. When the MLPs are taken out of action, the lower layers (pre layer 10) have their causal effect on later layers much reduced compared to the higher layers (post layer 20) where severing the MLPs doesn't make much difference to a layer's downstream causal effects. For these kinds of factual recall prompts, attentional pickup into the last token seems to happen around layer 30.
This makes me wonder, if it is the case that more complicated, semantic representations tend to occur in later layers, perhaps the increasing ‘semantic-ness’ of the representation happens by some kind of gradual additive process involving the MLPs. Maybe by the repeated recall of associations retrieved in MLP layers?
Attentional Patterns
GPT2 likes looking at the first token (on short prompts, and maybe on long ones too)
GPT2 models pay a lot of attention to the first token, seemingly regardless of the prompt. I was originally pretty confused when I saw this, but others have observed a similar focus on the first token in GPT2-XL, and this behaviour is also present in the 12-layer version of GPT2.[17][2][18]
Some people have suggested that the model may be using attention on the first token as a kind of default:
"We excluded attention focused on the first token of each sentence from the analysis because it was not informative; other tokens appeared to focus on this token by default when no relevant tokens were found elsewhere in the sequence. On average, 57% of attention was directed to the first token." [2]
In conversation with other people, it was also suggested to me that this could be because GPT2 was trained on much longer sequences of text than my prompts, and that this extra attention on the first token could potentially be a result of heads which usually attend to tokens many positions earlier being unable to do so.
I very briefly looked into this (I took the plaintext of two newly added books off Project Gutenberg, took forty 800 token samples from each of them, and then looked at the average attention the token paid to the first token). For these two books the results were much the same, with attention on the first token falling off significantly for the first 50 tokens, but on average not falling below ~0.25 even after 512 tokens (the text length that GPT2 was trained on, and which I'm guessing GPT2-XL was trained on also).[19] This pattern was the same when looking at heads individually.
So, at least here, even for long prompts attention on the first token is still overrepresented. I have no idea if this generalises more broadly though - I only looked at two books, and they are both a bit weird (both translated narratives, one written in an old style of English). [20]
Regardless of the reason why, an unexpectedly large amount of attention on the first token does seem like a pretty consistent feature of the GPT2 models.
GPT2-XL seems to have 'distributed attention' layers at the start and end of the network.
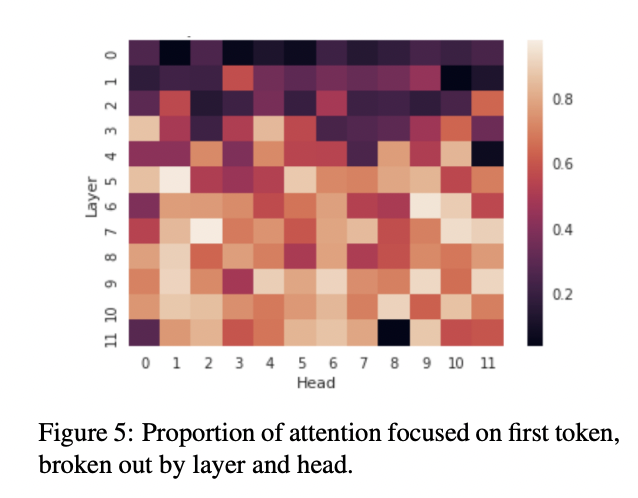
Another thing that you can see from my attention plots is that the heavy first token attention only appears after ~layer 8. Before this (and in the very last layer(s) of the network), the final token attention is much more evenly distributed.
A similar pattern may also be present in GPT2-small.[22] Where the proportion of attention on the first token is pretty low in the first 3 ish layers of GPT2-small, but after about layer 5 the first token gets more than half of all assigned attention.
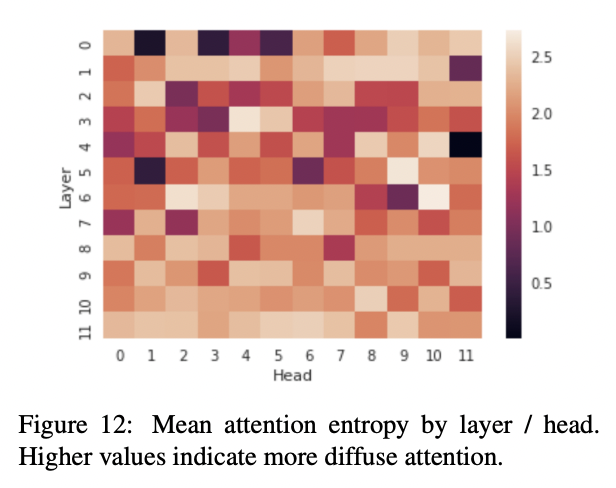
Though it's worth noting that layers with less heavy first token attention in GPT2-small don't seem to have as much diffuse attention specifically (unlike what seems to be the case for GPT2-XL) or at least it's not as prominent when broken out by head here:
Speculating on Attentional Patterns
The above information, in combination with 1) the evidence on content vs positional heads and 2) the processing of parts of speech and syntatic dependencies from Alethea's post, make me wonder if the attention in the first 3-4 layers of GPT2-small might be involved in some kind of initial sentence-wide processing/embedding.
It makes sense to me that tasks like figuring out syntactic dependencies (which require the consideration of multiple words in relation to one another) would benefit from more evenly distributed attention amongst tokens.
This distributed attention is paticularly apparent in the first 8 layers of GPT2-XL (and in the very last layer), and I don't seem to get attentional pick up in traces much before layer 8. So perhaps a similar 'sentence/prompt processing' stage might be happening in the beginning layers of GPT2-XL too. I wonder if a similar thing might also be happening in the last layer(s) of the model aslo, where distributed attention might be useud to help 'fit' the internally represnted state into the context of the rest of the output.
Speculative Picture of Overall Structure of GPT2-XL
Rounding all this up, perhaps a speculative picture one could present for the high-level structure of GPT2-XL might be something like this:
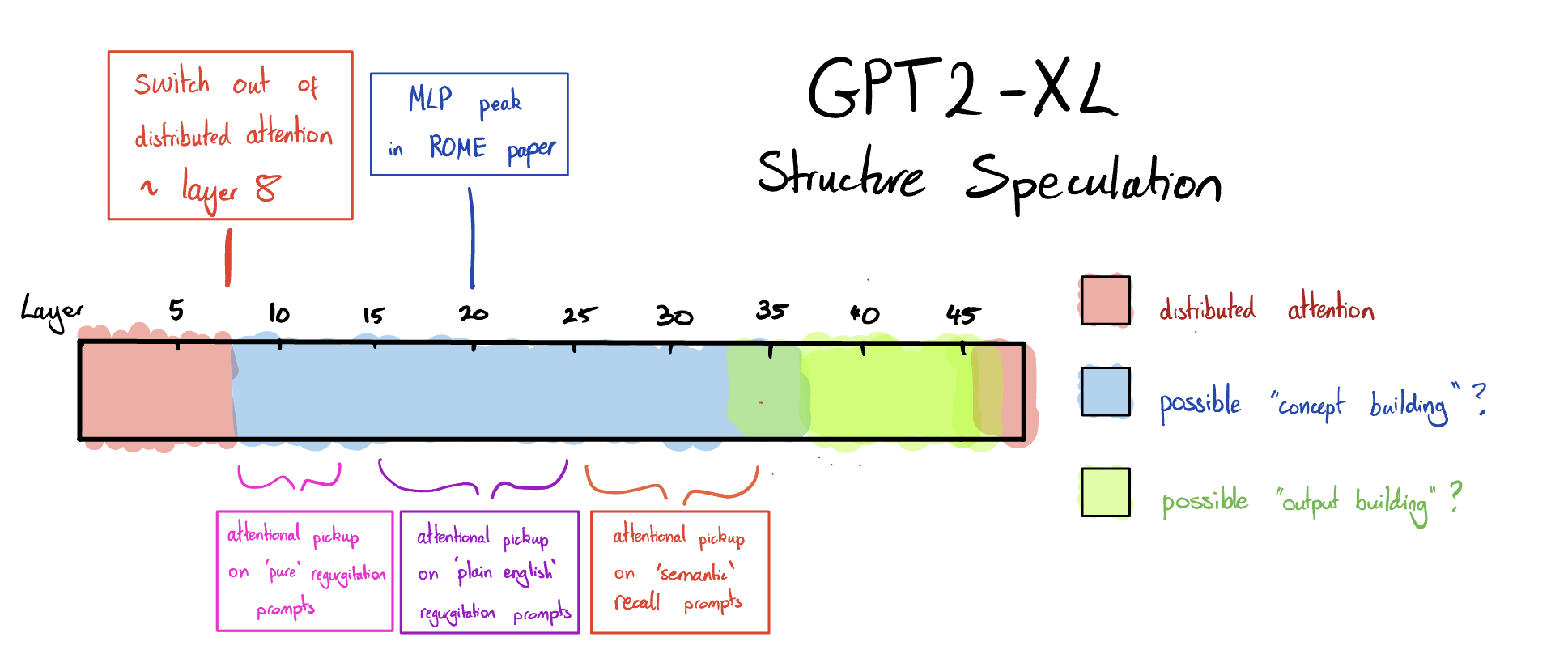
- The model starts with eight-ish layers of distributed attention 'encoding'
- This is possibly involved with tasks like processing syntactic dependencies of tokens, and 'building' multi-token words. (These tasks seem likely to benefit from distributed attention, and to occur in earlier layers if "later layers" -> "more semantic" is true).
- I also suspect that these layers may be involved with detecting positional patterns, and possibly with storing next token base rates. (Just based on observed regular patterns in some attention heads, e.g head 19[12], and very early attention pickup in some regurgitation prompts).
- At ~ layer 8 there is a relatively sharp switch from "distributed attention" mode to "first token attention" mode in all heads.
- "Concept building" begins after this switch.
- An internal representation of the input is gradually built up layer by layer, via repeated recall of associations from the midlayer MLPs.
- This building process results in later layers containing a more association / semantically rich representation of the input.
- I suspect that this is the case not just for building up factual associations about subjects (e.g things like Eiffel Tower -> Paris -> France) but for any and all associations. For example, conceptual, non-factual, or hallucinated associations (things more like Eiffel Tower -> Paris -> culinary excellence, tourism, culture).
- The final token attention "picks out" relevant information at the layer(s) at which the relevant information is prominent in the subject token:
- Layers ~ 7 - 13 tend to be where attentional pickup happens for simple regurgitation prompts.
- Layers ~ 15 - 22 tend to be where attentional pickup happens for plain English regurgitation.
- By layer 20, concept building relevant to factual recall is mostly done (using ROME paper MLPs as an indication).
- By layer 30, concept building relevant to factual recall is mostly done (using attentional pickup point)
- At some point after layers ~35-40 the focus switches from representation of the input to the production of the output (extrapolating based on Aletha's post and lack of attentional pickup in my traces after layer 35)
- The model's very last layer(s) are distributed attention 'decoding' layers.
- Perhaps a final shuffling of token probabilities around based on what fits syntactically?
Rough Extra Bits On Hidden States
This section contains a few bits and pieces of extra investigation that seemed worth throwing in. I haven't done much checking of these results, so just bear in mind that these results have a pretty reasonable chance of being wrong / containing bugs.
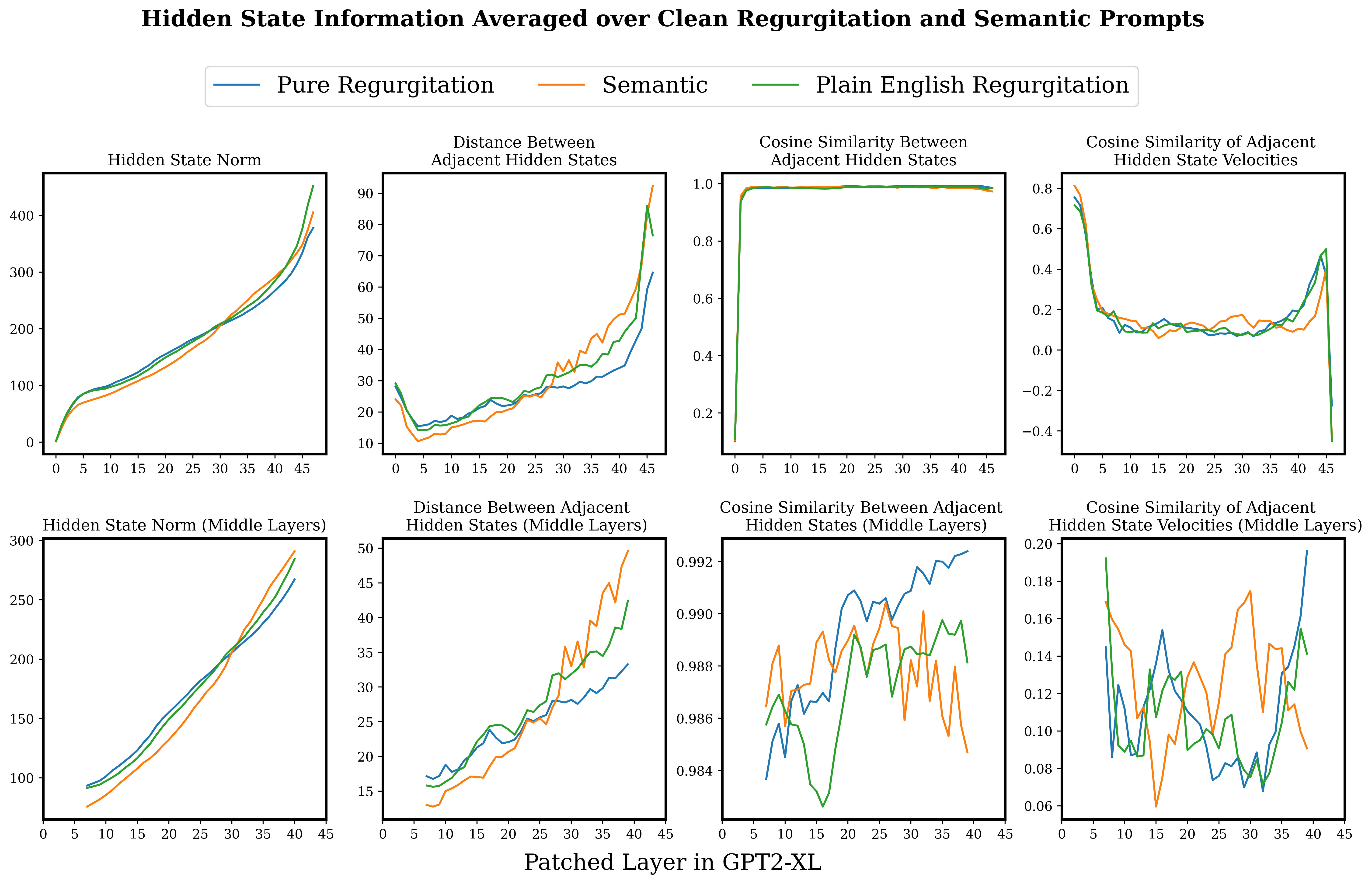
Looking to see if there were any noticeable changes in the hidden states at layers of transition in the causal traces seemed interesting.
The hidden states (and input embeddings) in GPT2-XL are 1600 dimensional vectors. I wondered if it might be possible to see relatively large motions in the hidden state when the final token retrieves important information, and I was generally just curious what the motion of the hidden states looks like in the broad strokes. Here I will be just looking at the hidden states of the final token on un-noised prompts.
Plotted below are some properties of the hidden states through the model, averaged over (un-noised) runs of the prompts. Here, the two regurgitation categories have been combined for easier parsing. See the footnotes for a version of this figure with separated regurgitation categories.[23]
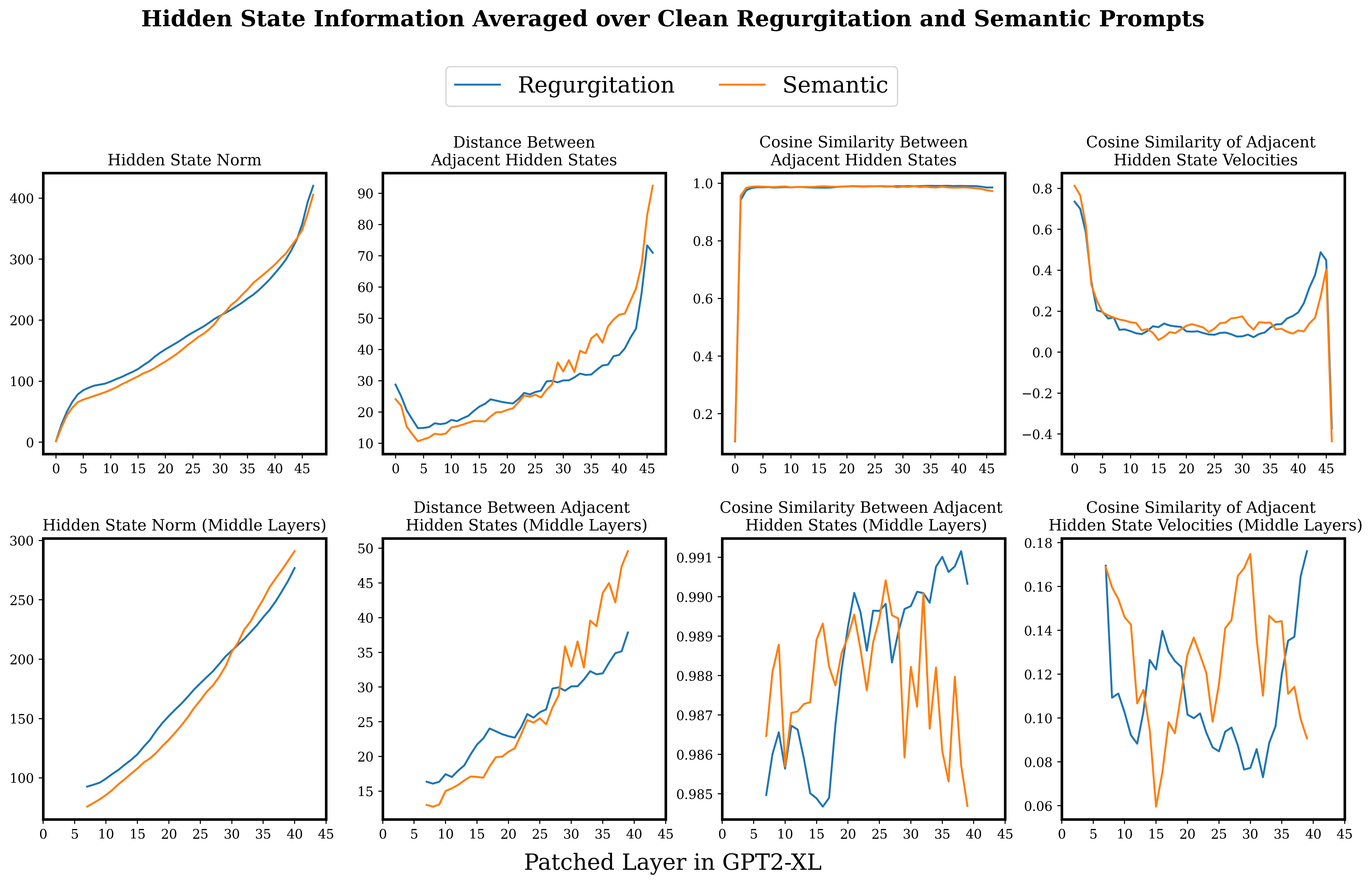
Basically, things are just pretty noisy. Maybe there is some evidence of a greater increase in the norm of hidden states towards the latter half of the network for the semantic prompts, compared to the regurgitation prompts. I also suppose that this data is somewhat consistent with the hidden states accelerating more strongly in a single direction around layers ten to twenty for the regurgitation prompts, and layers 20 - 35 for semantic prompts, which does roughly line up with the average start of the final token streak in the causal traces for these prompt types. On the whole though, I personally wouldn't put much weight on this story - I may well just be 'explaining' noise.
I do think it is interesting how the very beginning and end layers seem to have different behaviour to the middle layers, and I wonder if this is related to the distributed attention layers at the beginning and end of the network.
Also, plotting raw states out like this really highlighted to me how nice causal tracing is. The ability to focus in on the causal influence of specific tokens can be really quite helpful for cutting through all this noise.
- ^
Looking for Grammar in All the Right Places - Alethea Power
- ^
Vig, J., & Belinkov, Y. (2019). Analyzing the Structure of Attention in a Transformer Language Model (Version 2). arXiv. https://doi.org/10.48550/ARXIV.1906.04284
- ^
Geva, M., Caciularu, A., Dar, G., Roit, P., Sadde, S., Shlain, M., Tamir, B., & Goldberg, Y. (2022). LM-Debugger: An Interactive Tool for Inspection and Intervention in Transformer-Based Language Models (Version 1). arXiv. https://doi.org/10.48550/ARXIV.2204.12130
- ^
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. "Locating and Editing Factual Associations in GPT." arXiv preprint arXiv:2202.05262 (2022).
- ^
However, note that nothing is stopping us from using a different distance measure for what counts as 'restoration'. For example, KL divergence over the whole distribution could be used, or how much the probabilities on groups of words with similar meaning change. Though in the original paper and this post, only the top prediction probability (and slight modifications of this) is used.
- ^
Specifically, hidden states from previous tokens at a given layer can be retrieved by later tokens at that layer.
- ^
I do want to flag that I feel a bit uncomfortable with the framing of this statement. Based on some very brief experimenting with hallucinated facts (they seem to have very similar traces as 'actual' facts) I think it might be more accurate to say something like semantic associations in general (including both factual and non-factual associations) are associated with the mid layer MLPs.
I'm also not a massive fan of the term 'storing'. If it is the case that the generation of hallucinated facts happens by essentially the same process as the recall of actual facts, then it doesn't really feel appropriate to talk about the model 'storing' these hallucinated facts for non-existent subjects. Perhaps more a continuous function 'anchored' at certain points?
- ^
This feels a bit weird to me. From informal conversations with other people who've implemented versions of causal tracing this does seem to be a 'thing', and you can also see this when using the implementation provided by the authors of the original causal tracing paper. I am confused about why this effect happens in the strong noise regime.
(A few random spitballs about why this might happen: restorations halfway through might mess up operations that compare tokens, or model starts effectively ignoring highly noised tokens?)
- ^
Spreadsheet containing all the prompts here.
I would have quite liked to have more prompts, but the process of coming up with good prompts turned out to be more labor-intensive than I expected. Largely because I had quite a few constraints on the kinds of prompts I wanted:
1. GPT2-XL's top prediction on the un-noised prompt is correct.
2. Only one token is noised (which has the consequence that the subject should be just one token. I relaxed this a bit in the end so if that wasn't possible I would noise the last token of the subject only).
3. The first token can't be noised. (Leaving the first token un-noised gives a convenient baseline for normalisation).
4. The last token can't be noised. (If the last token is noised then there will be no transition from the noised token to the final token).
5. All the other details about how salient the prompts are that I talk about in the prompt design sections.
- ^
The rough proxy I used for this was how many google results a search of the exact phrase turns up, and for a high base rate of (completed phrase | prompt) I used the ratio of google results as a rough guide.
- ^
Traces with noise levels of 0.3 and 1 look the same. At a lower noise level of 0.1 patching in some areas for some prompts becomes destructive, which messes up my normalisation and makes things look quite different for the affected prompt types.
- ^
Final Token Attention by Prompt Type and Head for All Heads
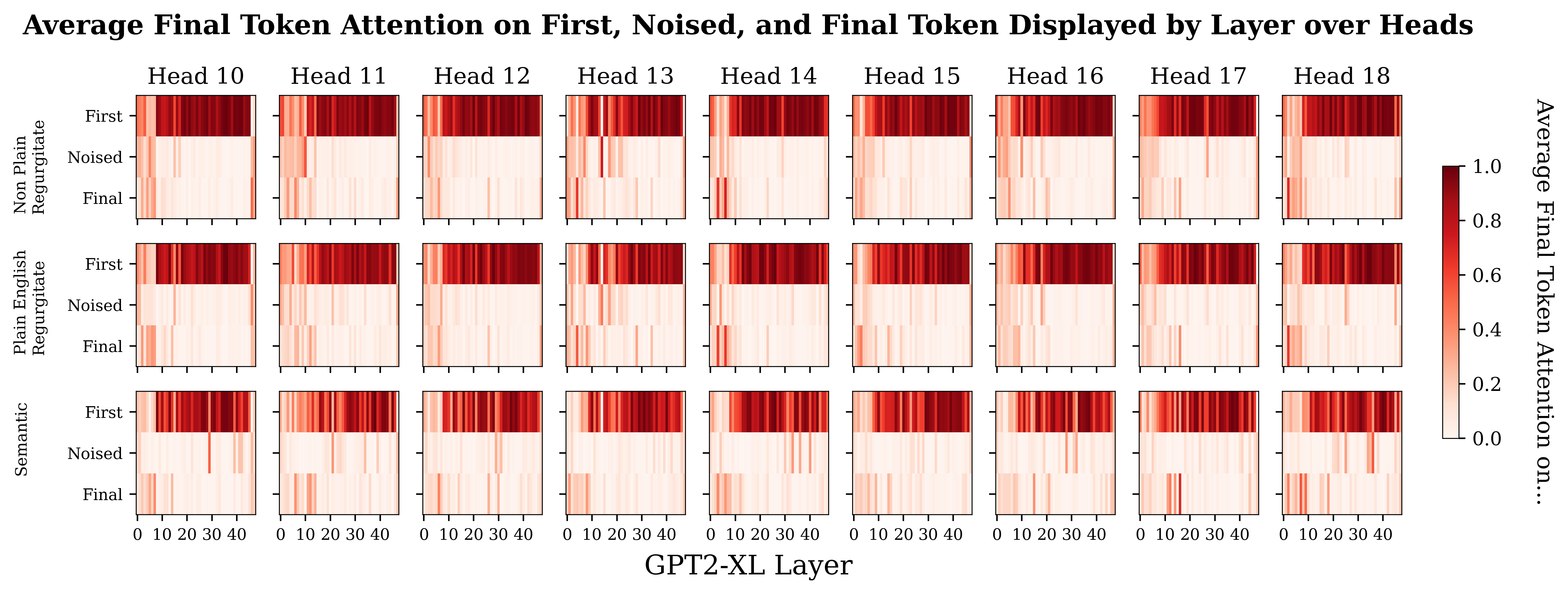
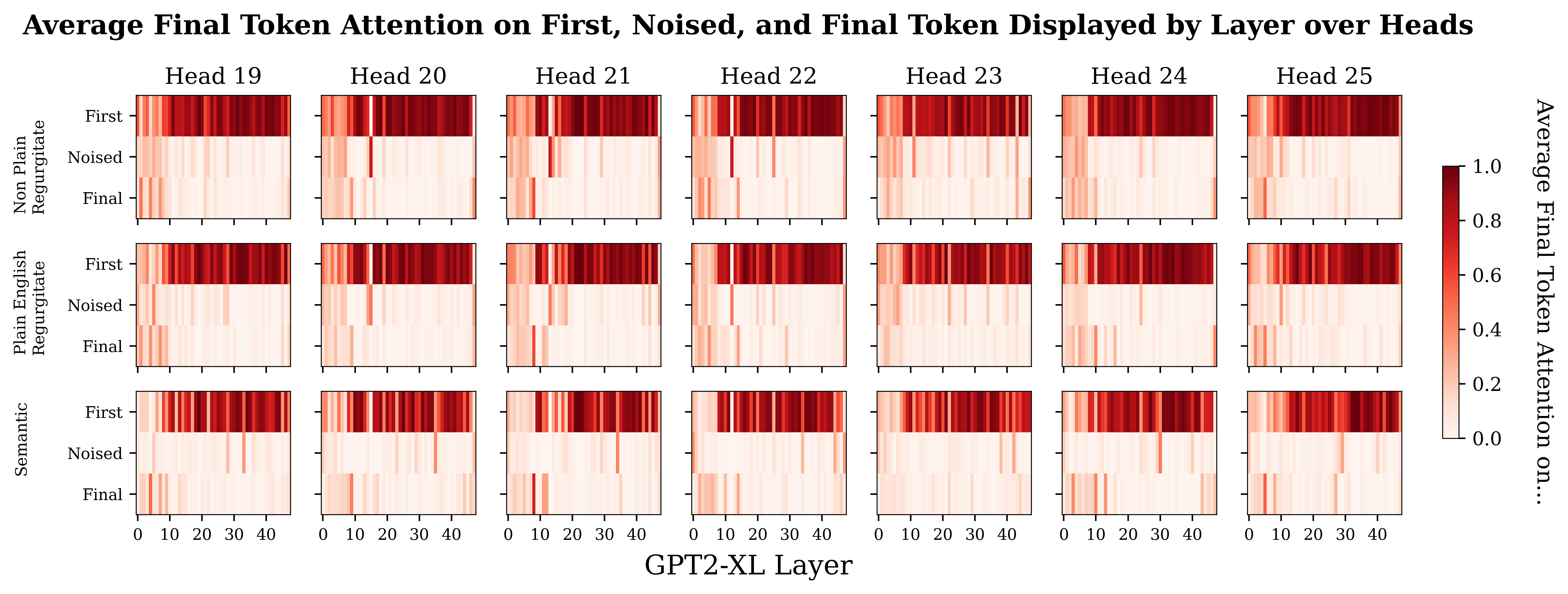
- ^
- ^
Olah, et al., "Zoom In: An Introduction to Circuits", Distill, 2020.
- ^
Geva, M., Caciularu, A., Wang, K. R., & Goldberg, Y. (2022). Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space (Version 2). arXiv. https://doi.org/10.48550/ARXIV.2203.14680
- ^
Dar, G., Geva, M., Gupta, A., & Berant, J. (2022). Analyzing Transformers in Embedding Space (Version 1). arXiv. https://doi.org/10.48550/ARXIV.2209.02535
- ^
- ^
First token attention mentioned in the GPT-2 section:
van Aken, B., Winter, B., Löser, A., & Gers, F. A. (2019). How Does BERT Answer Questions? In Proceedings of the 28th ACM International Conference on Information and Knowledge Management. CIKM ’19: The 28th ACM International Conference on Information and Knowledge Management. ACM. https://doi.org/10.1145/3357384.3358028
- ^
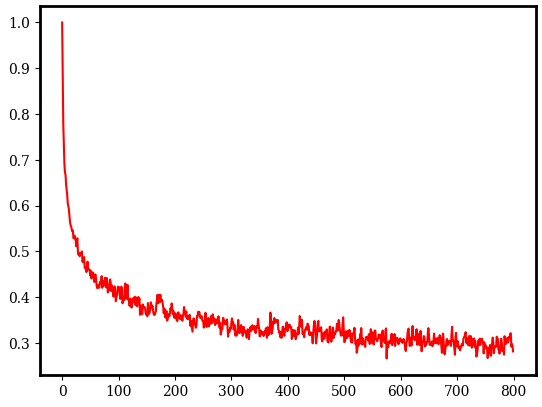
Mean attention i th token pays to first token on forty 800 token samples of "You Are Forbidden!" by Jerry Shelton. - ^
The reason I chose these books as text samples was because 1) they were nice and long 2) their plaintext was readily available 3) being newly translated meant they were unlikely to have appeared in the training data.
- ^
- ^
I'm generally pretty surprised by how many similarities there seem to be between the structure of GPT2-small and GPT2-XL. Though I don’t know enough about the training of these models to know whether the existence of these similarities is noteworthy.
- ^
- ^
Possibly due to causal influence into the final token having more of a tendency to be routed through intermediate tokens? Or perhaps these prompts tending to be more difficult (resulting in lower probability on top token) in combination with being in prob space rather than logit space? Or maybe just the attentional pickup happens sometime after the relevant information has been extracted in the subject token?
- ^
Zhao, S., Pascual, D., Brunner, G., & Wattenhofer, R. (2021). Of Non-Linearity and Commutativity in BERT (Version 4). arXiv. arXiv:2101.04547
1 comments
Comments sorted by top scores.
comment by jacquesthibs (jacques-thibodeau) · 2022-11-23T15:16:44.954Z · LW(p) · GW(p)
This was great, and I'd love to see more work in this direction. Given how many people know about ROME, causal tracing-type work seems under-explored.