AISN #47: Reasoning Models
post by Corin Katzke (corin-katzke), Dan H (dan-hendrycks) · 2025-02-06T18:52:29.843Z · LW · GW · 0 commentsThis is a link post for https://newsletter.safe.ai/p/ai-safety-newsletter-47-reasoning
Contents
Reasoning Models State-Sponsored AI Cyberattacks Links Industry Government Research and Opinion None No comments
Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
Reasoning Models
DeepSeek-R1 has been one of the most significant model releases since ChatGPT. After its release, the DeepSeek’s app quickly rose to the top of Apple's most downloaded chart and NVIDIA saw a 17% stock decline. In this story, we cover DeepSeek-R1, OpenAI’s o3-mini and Deep Research, and the policy implications of reasoning models.
DeepSeek-R1 is a frontier reasoning model. DeepSeek-R1 builds on the company's previous model, DeepSeek-V3, by adding reasoning capabilities through reinforcement learning training. R1 exhibits frontier-level capabilities in mathematics, coding, and scientific reasoning—comparable to OpenAI’s o1. DeepSeek-R1 also scored 9.4% on Humanity’s Last Exam—at the time of its release, the highest of any publicly available system.
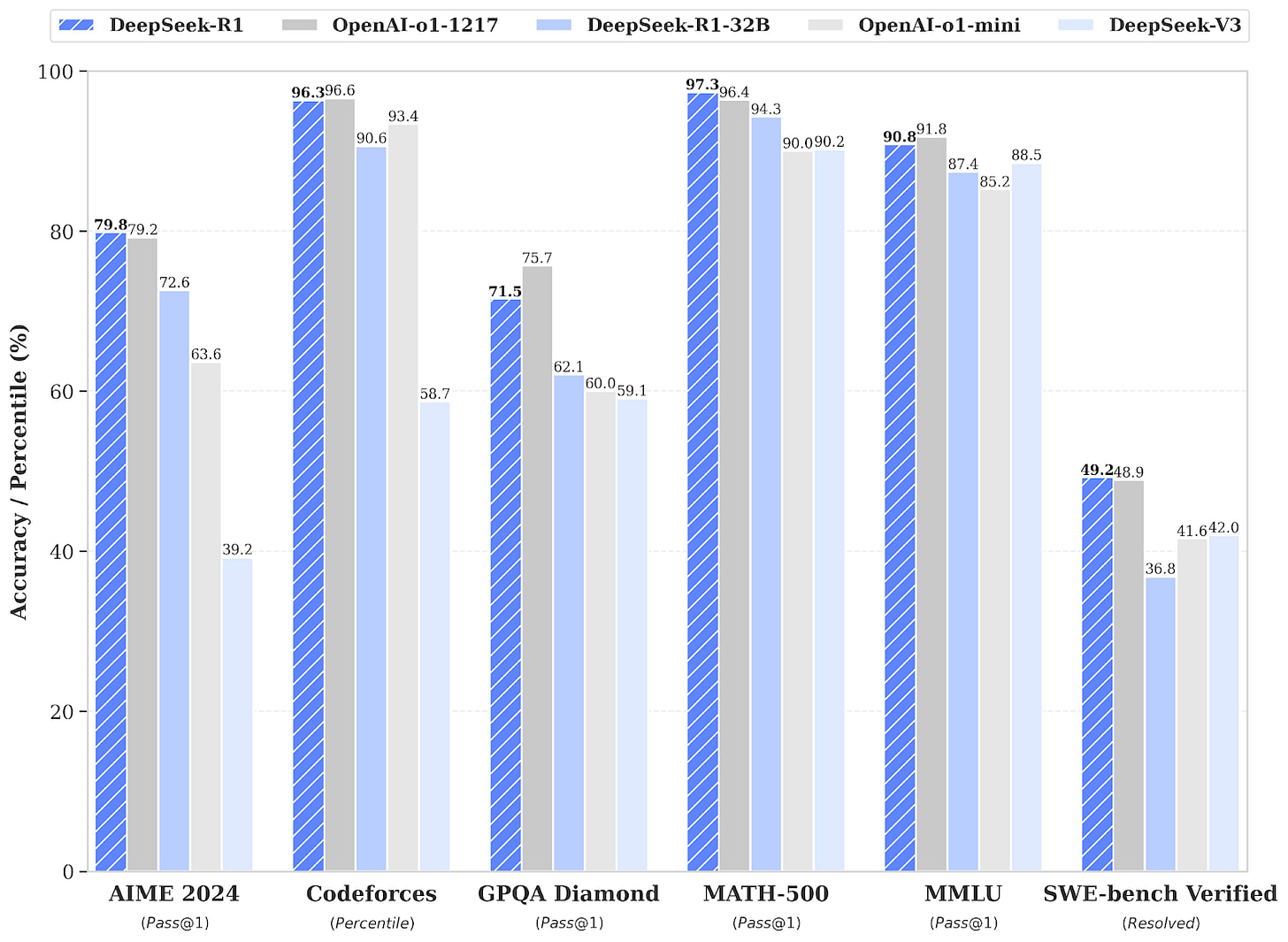
DeepSeek reports spending only about $6 million on the computing power needed to train V3—however, that number doesn’t include the full cost of developing the model, and DeepSeek may have used OpenAI’s models to help train its own in a process known as “distillation.” The cost of running inference for R1 is also much lower than for o1. Since DeepSeek-R1 is also open-weight, low inference costs have meant that some users have been able to download and run the model locally.
OpenAI released o3-mini and Deep Research. On January 31st, OpenAI responded to DeepSeek-R1 by releasing o3-mini, which comes in three “reasoning effort” options: low, medium, and high. With high reasoning effort, o3-mini outperforms R1 on STEM reasoning benchmarks. On Humanity’s Last Exam, o3-mini (high) scores 13%. Along with CBRN and Persuasion, o3-mini is also OpenAI’s first model to reach “Medium” risk on Model Autonomy.
Three days later, OpenAI released Deep Research, which combines o3 with tool use to conduct online research and produce reports. With access to browsing and python, Deep Research scores 26.5% on Humanity’s Last Exam. Currently only Pro users (OpenAI’s $200/month tier) have access to Deep Research, and are limited to 100 queries/month.
Deep Research was not released with a system card—so we don’t know how well it fared on OpenAI’s safety evaluations. Since Deep Research is the first public access of the full o3 model, this appears to violate OpenAI’s voluntary safety commitments—specifically, the commitment to “publish reports for all new significant model public releases” including “the safety evaluations conducted.”
Compute remains important. One justification for NVIDIA’s stock decline is that DeepSeek-R1 implies that access to compute is becoming less important, since DeepSeek was able to develop a frontier model with only a fraction of the compute available to US companies.
However, that justification doesn’t hold up. It’s true that the step from V3 to R1 didn’t require much compute—but as several sources have argued, once DeepSeek had developed V3, adding reasoning capabilities was relatively straightforward. OpenAI had already demonstrated in o1 that reinforcement learning and inference-time compute is an effective combination.
Reasoning is also scalable. More reinforcement learning should translate into more capable final models, and a model can spend more compute on inference—for example, see o3-mini low, medium, and high. As reasoning models become more capable, it will also become economically valuable to run many copies of a single system simultaneously. There’s no clear “upper limit” on how much compute will be economically valuable.
Export controls remain important. Since compute is still important for AI development, so too are export controls for AI policy. A compute advantage will allow US companies to more easily develop frontier models and more widely deploy the economic advantages those models enable. As a recent RAND commentary argued, the US “should be very glad that DeepSeek trained its V3 model with 2,000 H800 chips, not 200,000 B200 chips (Nvidia’s latest generation).”
That being said, DeepSeek-R1 demonstrates that China will have access to very capable models—and any strategy for AI safety will have to accommodate that fact.
State-Sponsored AI Cyberattacks
Google's Threat Intelligence Group has revealed the first comprehensive evidence of how government-backed hackers are leveraging AI by identifying threat actors from more than 20 countries using its Gemini platform. The report shows that while AI hasn't revolutionized cyber warfare, it has become a significant productivity tool for existing hacking operations.
Iranian, Chinese, and North Korean hackers used Gemini. Rather than using Gemini to develop cyberattacks directly, hackers primarily used AI as a research assistant.
- Iranian hackers were the most frequent users of Gemini, and showed the broadest range of applications. They employed it to research defense organizations, craft phishing campaigns, and generate content in multiple languages.
- Chinese hackers, representing the second-largest user group with more than 20 identified teams, focused on reconnaissance and studying techniques for data theft and network infiltration.
- North Korean hackers often used Gemini to create cover letters for IT jobs—part of a documented scheme to place workers in Western companies to generate revenue for their nuclear program.
Laura Galante, former director of the U.S. Cyber Threat Intelligence Integration Center, noted that these findings align with U.S. intelligence agencies' assessments of how adversaries are weaponizing AI.
Open-weight models will enable untraceable misuse. The report found that when hackers attempted to bypass Gemini's safety controls using publicly available "jailbreak" prompts, these efforts proved unsuccessful. However, open-weight models—such as DeepSeek-R1—are less resilient to misuse. While Google has terminated accounts linked to misuse of Gemini, it’s not possible to track and prevent misuse of open-weight models like DeepSeek.
Links
Industry
- OpenAI released a research preview of Operator, a browser-based agent, for Pro users in the US.
- OpenAI released a version of ChatGPT for the US Government.
- The Chinese AI company released Qwen2.5-Max, which is comparable to GPT-4o.
- Meta published a Frontier AI Framework, which describes its approach to AI safety.
- Google has made Gemini 2.0 available to all users.
Government
- The UK government published its International AI Safety Report ahead of the AI Action Summit.
- Trump signed an executive order stating: “It is the policy of the United States to sustain and enhance America’s global AI dominance in order to promote human flourishing, economic competitiveness, and national security.”
- The first measures of the EU AI Act took effect on February 2nd.
- The DOJ indicted a Chinese software engineer working at Google for allegedly stealing AI trade secrets.
- Trump threatened tariffs on Taiwanese semiconductors.
- Elizabeth Kelly left her role as director of the US AI Safety Institute
Research and Opinion
- The Bulletin of Atomic Scientists released its 2025 Doomsday Clock Statement, which includes a section on AI.
- The Vatican published a lengthy note on the Relationship Between Artificial Intelligence and Human Intelligence.
See also: CAIS website,X account for CAIS, our $250K Safety benchmark competition, our new AI safety course, and our feedback form.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
Subscribe here to receive future versions.
0 comments
Comments sorted by top scores.