Retrieval Augmented Genesis
post by João Ribeiro Medeiros (joao-ribeiro-medeiros) · 2024-10-01T20:18:01.836Z · LW · GW · 0 commentsContents
Project Goals Introduction Reading and Conversation What is Retrieval Augmented Generation? RAG in human terms Retrieval as Search and Research Engine Corpus — Holy Chunking Verse Uni Verse Generative Model The Oracle The Exegete The Scientist Semantic Similarity Network (SSN) Knowledge Graphs Vector DB Definitions Network Construction AI Alignment and Safety Applications Network Centrality Measures SSN — Network Visualization Embedding Model Threshold Parameter Computational considerations — Rustworkx Main Messages of the Great Books Bible (New Testament) Torah Quran Bhagavad Gita Analects AI and Religion On Stochastic Literature Conclusion Future Extensions Tech Stack Thank You : ) References and Bibliographyhttps://github.com/JoaoRibeiroMedeiros/RAGenesisOSS Science Direct — Topics — Semantic Networks None No comments
a prototype and some thoughts on semantics
Before reading this article I strongly encourage you to Checkout the RAGenesis App!
Full code available at https://github.com/JoaoRibeiroMedeiros/RAGenesisOSS.
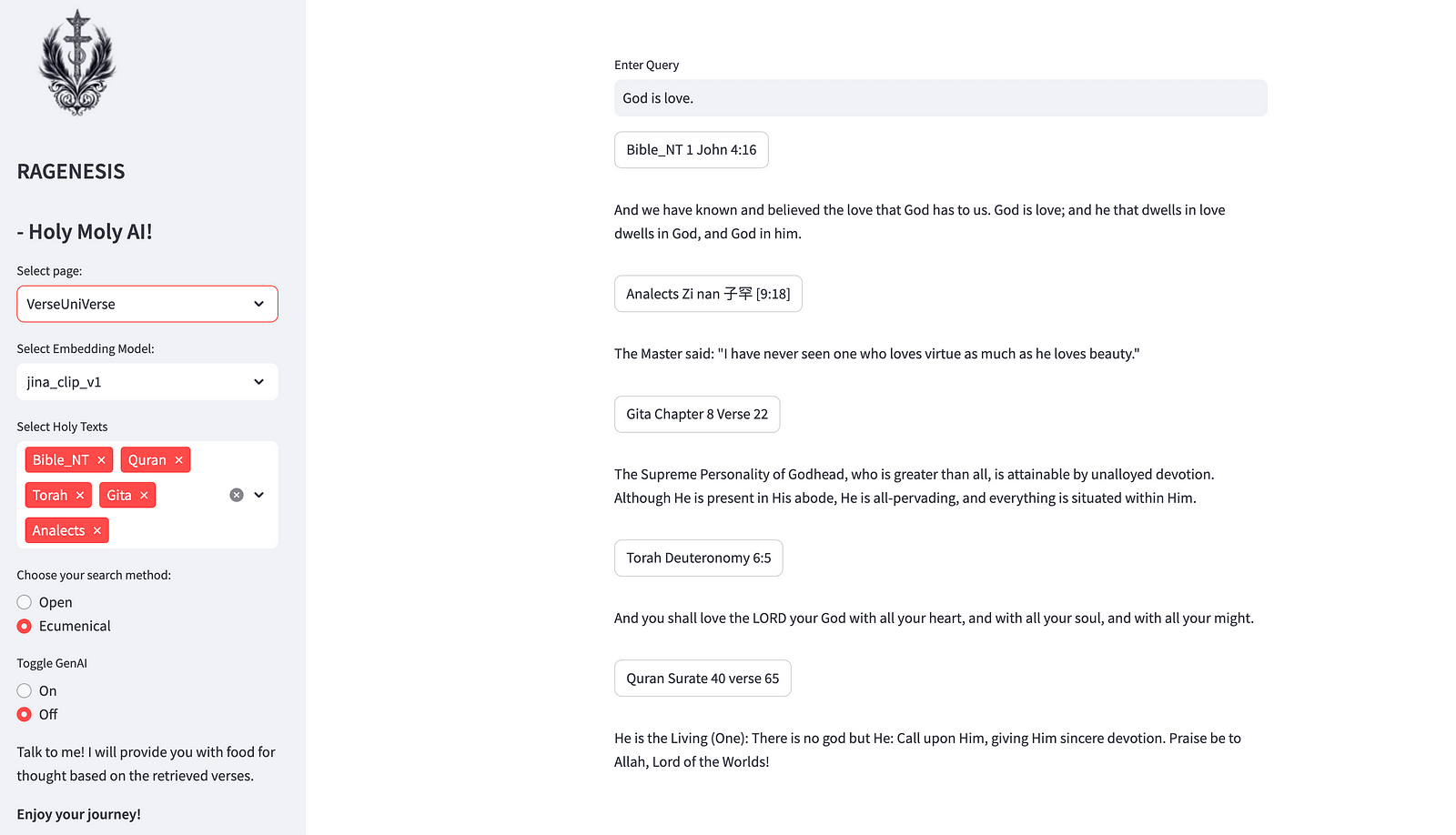
Project Goals
- Send a message of unity and mutual understanding between different cultures through a “generative book” compiling the wisdom of many different traditions.
- Develop a framework for transparency of embedded knowledge bases and evaluation of main messaging in a RAG application.
- Define Semantic Similarity Networks as special case of Semantic Networks and derive Main Chunk methodology based on elementary Graph theory.
- Create a showcase of my technical capacity as an AI engineer, data scientist, product designer, software developer and writer.
- Make something cool.
Introduction
Having led the development of several software products based on RAG engines for the last year, I have been consistently investigating the scope of semantic similarity for a plethora of different use cases.
Turns out this exercise got me wondering about some of the more fundamental aspects of what AI-driven semantic similarity can accomplish, in the years to come.
I figured that through semantic similarity algorithms the current AI engines have opened up a pathway to explore texts and documentation in a radically innovative way, which has implications for education, research and everything that stems from those two foundational areas of human activity.
In this article, I present ragenesis.com platform and explore the thought process behind its development, which I have accomplished as a solo full-stack AI engineering, software development and data science project. Beyond that, I also used this exercise as a platform to collect thoughts around the importance of RAG tools, and how there is still a lot of opportunity when it comes to the value that this kind of application can produce.
Finally, I showcase some results for the semantic similarity network associated with the knowledge base I built for this project, centered around the verses of some of the greatest books of all time: the Torah, the Bhagavad Gita, the Analects, the Bible and the Quran.
The choice of these texts was inspired by my long term fascination with religious scriptures which is anchored in the understanding of those classical texts as some of the greatest sources of wisdom ever produced by humankind.
In the ruptured and fragmented world we live in, I find solace in reading through these references looking for their universality. Thus, building a Retrieval Augmented Generation Application powered by a knowledge base made up of those texts was a natural pathway for my curiosity.
In my experience developing AI applications, I’ve found it helpful to draw analogies between AI and everyday human experiences. This approach aids in explaining key concepts related to human ways of thinking, learning, and processing information. I'll take the liberty to do that more than once in the sections to come.
Reading and Conversation
As an product I fundamentally view RAGenesis as a reading tool, whereby an innovative way to explore the holy texts is made available. This concept is reminiscent of Tyler Cowen’s generative AI book. In a sense this work tries to provide a similar approach to allow for an efficient reading experience for people interested in the ancient wisdom of religions.
In all written text there is a clear linear structure, going from start to finish, word per word. Usually while reading the book for the first time, this should be the preferred method, the ordering of concepts or depicted events and how they unravel in sequence is naturally essential for a reader to experience the text as it is.
Nevertheless, if you start reading a book for a second or third time, it is very natural to allow yourself to read in a non-linear manner, looking for specific topic or character, and how they appear and reappear across the book. Example: “Oh, this is how Gandalf refers to the ring for the first time, let’s see where he does that again later on”.
Semantic similarity via embeddings is really an engine to accelerate that process of research across a text (or multiple texts) and the integration of different parts into a semantically significant whole.
I also enjoy seeing RAGenesis as a conversation tool, talk with the books, let’s see what they tell you. In a free flowing conversation, semantic similarity is the natural driving force for bringing new topics on board.
I really enjoy conversations which are diverse and offer many perspectives. It has been proven time and time again that diverse teams are usually more effective given the very simple reason that they provide a broader spectrum of perspective and conceptualization strategies.
In that spirit, RAGenesis puts together these very diverse sources and make them collaborate towards a single purpose.
What is Retrieval Augmented Generation?
Retrieval Augmented Generation is a strategy to integrate external data with language AI models to boost accuracy, relevance, and update knowledge dynamically in responses.
In other words, it is a way to contextualize any answer an AI gives to a user with a knowledge base. The model's intelligence is fed both the original query as well as a semantically related set of document chunks which are part of that knowledge base, and with that contextualized input provides its answer in the form of model inference.
Check out this very comprehensive survey on RAG for a broad view of current RAG strategies, applications and challenges.
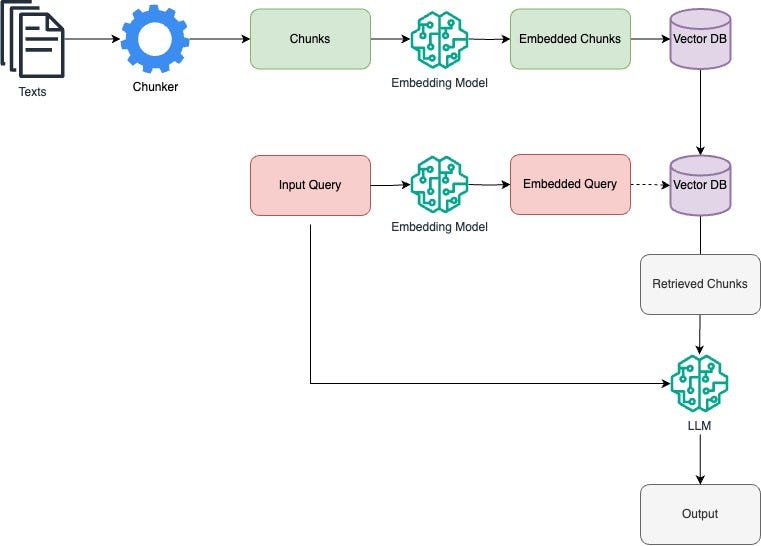
RAG in human terms
Words are our best proxy for the concepts which really make up all of our mind space, those govern the way we perceive the world around us, and consequently the way we act in it.
Hence, navigation of texts through the semantic similarity of its chunks can hardly be underestimated. This kind of process is actually something present in our daily lives.
Let's think about human activity: when trying to solve a problem you must retrieve all memories of similar previous problems you came across to try to uncover the best possible strategy in dealing with that problem.
This can be further generalized to any everyday situation, every time you find yourself facing a given set of circumstances, all you have as a framework for decision is previous similar circumstances which you dealt with, those will be your reference points, even if you attempt something new.
There is a direct analogy to be made between this general process and the Retrieval Augmented Generation framework, and maybe more than an analogy, given that some of the recent studies suggest profound connections between general AI framework and neuroscience.
Human learning is consolidated through consistent exposure to discourse, both stemming from things we read as well as what we hear from teachers and people in our lives. All of those make up fragments (chunks) of knowledge and memory which we will piece together according to the situations we find ourselves in.
Hence, should we translate into non-technical human terms the general architecture of RAG, retrieval really would correspond to memory, while generation would correspond to active decision making and creativity.
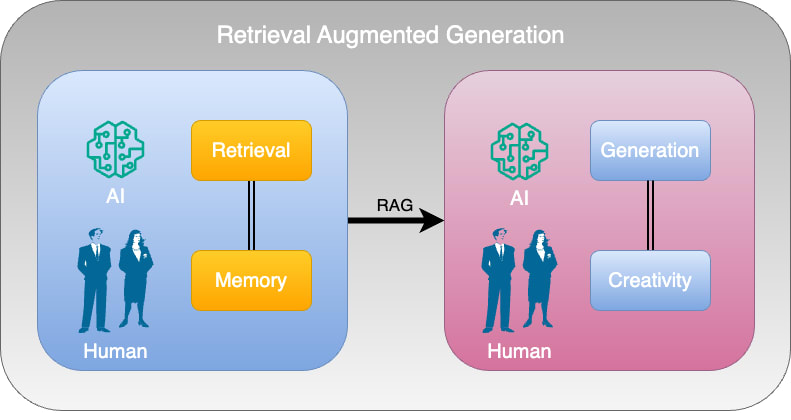
Having had the experience of building RAG products in the enterprise space, I came across the necessity of serving many different sets of business rules associated with enterprise operations, and could see how using this kind of human analogies can really help shaping RAG products in an efficient way, given that this approach also facilitates communication of the general principles used to stakeholders and target users.
Retrieval as Search and Research Engine
Anyone who has been involved in research has experienced the need for surveying the research space for a given concept, this has been hugely impacted by search engines such as Google, which really provided a very efficient approach for searching any subject in the internet. Google engine offers a quick overview of the general strategy in this page and several tools whereby one is able to more efficiently retrieve target material.
Google search, as we know it, is essentially a retrieval tool. Not surprisingly, some competing products for Google search engines such as OpenAI's SearchGPT have incorporated AI technologies as vector embeddings, similarity indexing, knowledge graphs and RAG to improve the search engine's performance.
Search engines such as Google are mainly retrieval mechanisms which try to survey the internet to find what you're looking for, having your input as a query. So when you build a retrieval mechanism for a given knowledge base, you essentially are providing a "google search" mechanism dedicated to the specific knowledge base you are dealing with.
In many cases a researcher finds himself in the need to define a smaller and dedicated scope which represents the target area that his research focuses on. Beyond retrieving the information associated with that target area, RAG engines add the generation component which can greatly help one make sense of the full retrieved corpus.
Even if the generation component fails to deeply capture every underlying concept which is relevant for the research, its effort can accelerate the researcher's insights and his general thought process.
Therefore, the use of RAG is undeniably a powerful tool to expedite research process. Some fruitful initiatives have flourished over the last year with that purpose, checkout PaperQA as a good example of such.
Corpus — Holy
To search is to look beyond. The disposition to search is one of the fundamental aspects of human behavior, which drive innovations, creativity and human achievement in general.
Among some others (such as search for resources), the search for meaning is one of the main driving forces of human behavior. The success of religions all across the globe in different cultures and eras can be partly explained by the effectiveness of religious storytelling in delivering meaning to human life.
Since I started thinking about how to approach a framework for the evaluation of main messaging of a RAG application knowledge base, it became clear that using a knowledge base dedicated partly to providing meaning to human activity would be specially cool. A tool for exploring semantic space of a knowledge base that provides meaning to many human lives, neat.
The fundamental concepts of vector embeddings and semantic similarity defined inside such an embedding space can be understood as maps of meaning, whereby concept hierarchies and systems of thought can be explored and derived.
Moreover, the challenging nature of the texts herein explored provide a specially rich testing ground for a RAG application, given the fact that all of them have such great impact on past, current and future world affairs.
The chosen texts are, in order of historical appearance (there might be some controversy around these dates):
- Torah: Traditionally dated around 1300 BCE, but potentially between the 10th and 5th centuries BCE.
- Bhagavad Gita: Approximately between the 5th and 2nd centuries BCE.
- Analects: Approximately between 475 and 221 BCE.
- Bible (New Testament): Written approximately in the first century CE.
- Quran: Completed in 632 CE.
Since the Old Testament Bible shares the full text of the Torah, I opted to include the Bible's New Testament as a more direct representation of Christian thought. Including both Old and New testaments makes the Bible substantially more lengthy than the other texts (around 25k verses in full), while if we compare the New Testament, the Quran and the Torah we see similar verse counts, while the Analects and the Gita occupy a class of smaller verse count.
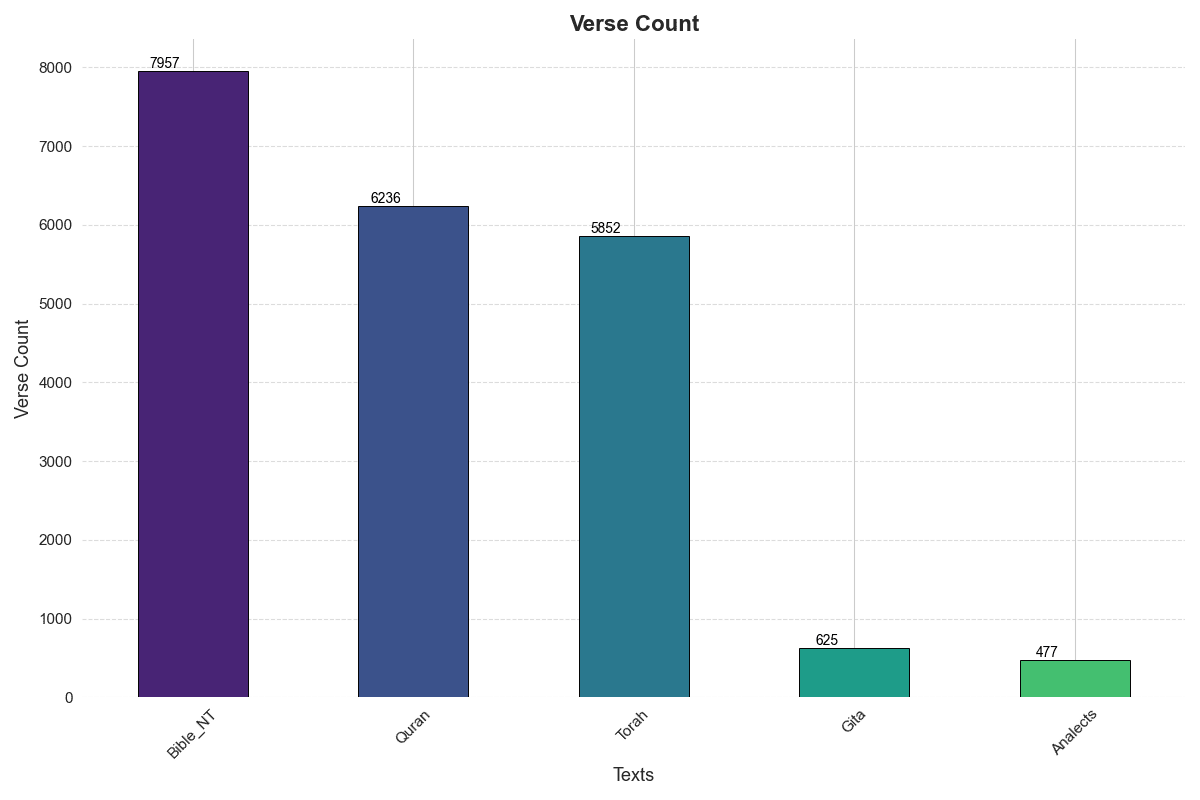
The choice of these texts was motivated by how representative they are in terms of the population that is culturally related to each. Those five books are part of the cultural heritage of a very substantial part of human population. From a geography standpoint, one could say those books have made themselves present across all continents.
So really one of the ideas behind RAGenesis is to provide a neutral and technically founded effort to read through these references looking both for the universality of the messages they carry, as well as to their singularities. How is it that they are similar? How is it that they are not? What do they teach us about each other? What are their main messages?
One thing is certain, those are all powerful books which have profoundly impacted the way we live today, and will continue to define human lives in centuries to come.
There are some very honorable classic religious scriptures which are missing from this collection which I plan to incorporate in the future, such as the Buddhist Canon, the Baha'i texts, the Tao Te Ching, the I Ching and many others.
This work was done with the utmost respect for all faiths and creeds which are associated with these classic books.
Chunking
The performance of RAG engines is highly dependent upon the quality of the information available in the retrieved chunks, which together with the user's original query, should be prompt engineered towards the given use case that is being solved by the RAG application.
There are several methods to chunk a text, such as Content Defined Chunking, Recursive Chunking, Document Based Chunking, Semantic Chunking, Agentic Chunking, each of those being more appropriate to different use cases. Check out Anurag’s Medium post on level’s of chunking which gives a description of these alternatives.
Fundamentally one has to tune the shape and general logic that produces the chunks to serve the interest posed by the application.
In RAGenesis, my choice was to chunk the reference texts using the natural criteria associated with how those texts are usually referenced: their verses. This allows for the retrieval mechanism to pick up chunks which are consistent with the way these classic texts are referenced and share those references accordingly with the LLM.
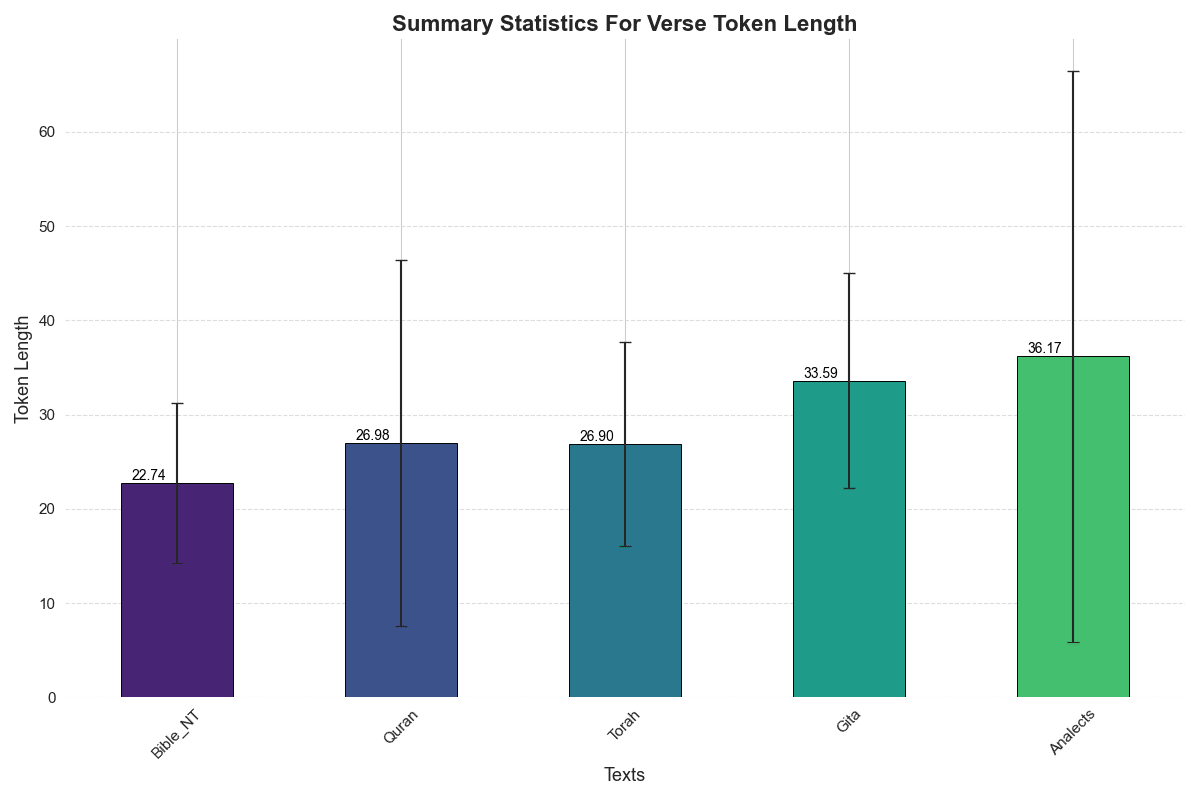
See summary statistics for number of tokens per verse for the five texts. Notice Analects displays larger average value as well as larger variance of tokens per verse.
There is a point to be made that the verses stemming from each of those texts have different mean lengths, this can be seen as having a likely impact on the retrieval's performance given the different typical lengths. Rather than seeing that as an unwanted perk of the way the retrieval system works, I was interested in accepting this asymmetry as an essential part of the different styles that the chosen texts have, and let the user of the platform approach that difference through the use of queries.
Asymmetry between query and vectorized chunks has been a consistent issue for the performance of RAG tools, and some strategies have been demonstrably successful for some use cases, an overview of this theme is given in this white paper by Willow Tree , some of the techniques discussed include HyDE, where the query isn't directly vectorized and used for search, but is adapted by an LLM before embedding.
This is something interesting that can be eventually implemented as part of this tool, in an effort to adjust the query for more "symmetrical" comparison to the chunked verses. Given high diversity of themes and styles across these texts, a dedicated evaluation of how to prompt engineer that transformation is up for discussion. The initial step for that would be centered around making sure at least the length of the query is brought via interaction with the LLM up to the average length observed in the references.
Verse Uni Verse
In the "Verse Uni Verse" page, you can experience the semantic similarity retrieval tool which looks for chunks/verses which are semantically linked to the query you have provided. This page is thought out as the more friendly user experience.
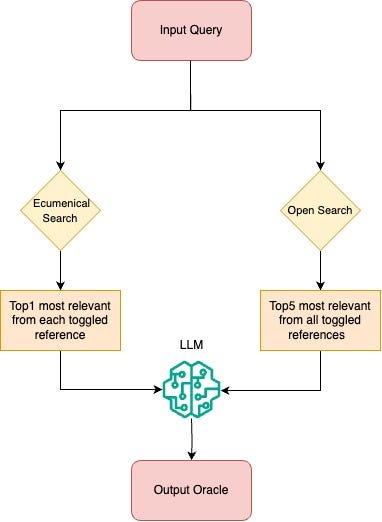
There are two ways to run retrieval in Verse Universe part of the application:
Open: Using the user query as reference retrieves top 5 most similar verses from full set of toggled texts.
Ecumenical: Retrieves top 1 most similar verses from each toggled text using the user query as reference.
See diagram for a depiction of the underlying logic.
Generative Model
I chose to use Meta's Lamma3 model provisioned through Amazon Bedrock to provide the generative part of the application.
RAGenesis provides the user with three different RAG pipelines. Not only is the generative model guided by different instruction prompts in each case, but also receives different input, given different retrieval engines working according to specific rules.
Those three different RAG experiences that RAGenesis provides can be understood as three different AI Agents altogether, encompassing the three different specific prompt engineering cases which are reflective of the specific retrieval engines and semantic contexts that they produce.
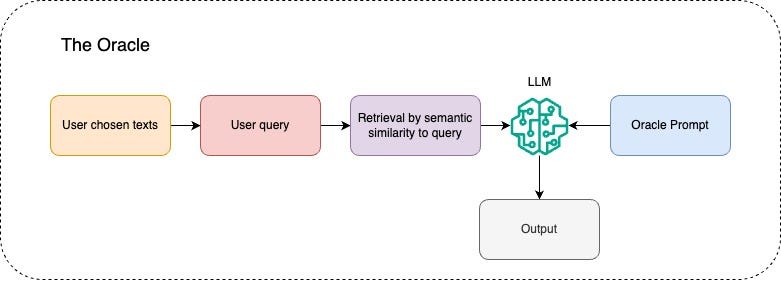
The Oracle
This agent is associated with the VerseUniVerse page.
The Oracle provides the AI-driven exegesis given retrieval of verses which are semantically similar to input user query. It is designed to provide a thoughtful appreciation of both the query given by the user as well as the similar retrieved verses from the sources. The generative model is instructed to adopt a mystical tone, to produce an engaging user experience.
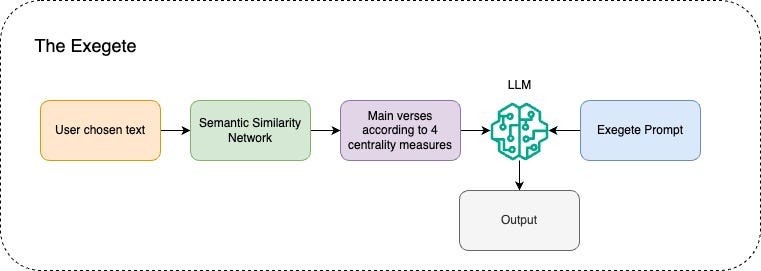
The Exegete
The Exegete is associated with the Semantic Network page, in the Main Verses configuration.
This prompt instructs Llama 3 to adopt a responsible and concise approach. The retrieved verses for this agent are always the 4 types of maximum centrality verses (degree, eigenvector, betweenness, closeness), see description of this criteria below in the Semantic Network session.
In my perspective, this agent has the hardest job of all, or the greatest responsibility: trying to determine the main message of the great books used by RAGenesis as a knowledge base.
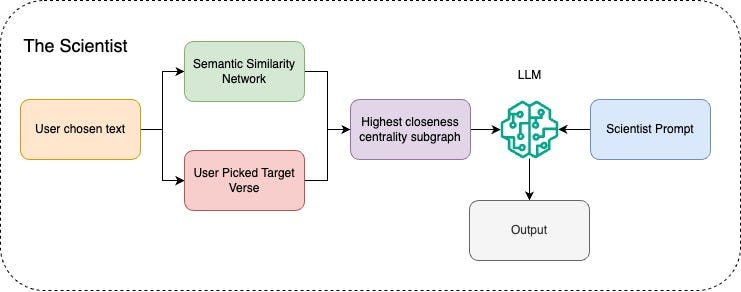
The Scientist
The Scientist is associated with the Semantic Network page, in the All Verses configuration.
This prompt instructs Llama 3 to adopt a more analytical approach, given the context associated with semantic network and graph theory based retrieval, see Semantic Network section for details on those concepts.
Semantic Similarity Network (SSN)
Once you have inserted all vector embeddings stemming from the chunked data in the vector database, semantic similarity searches can be run on top of an index defined according to a specific similarity metric.
The Semantic Similarity Network is an underlying graph structure which is a necessary implication of the composition of three elements in a RAG pipeline: embedding model, knowledge base and similarity metric. In fact, any time an AI engineer has made a choice for each of those in a RAG pipeline, he is accepting a subjacent concept structure that will drive retrieval clustering, this is what I like to call Semantic Similarity Network (SSN).
Notice the term Semantic Network refers to broad range of graph representations of knowledge or reasoning systems and has been used as a concept in AI as well as in other fields such as philosophy, psychology, and linguistics. Check out this science direct survey for an overview of applications of the concept.
The Semantic similarity network is actually a special case of semantic networks, whose main feature is of being made of nodes that represents chunks from a knowledge base and having its edges defined by a similarity metric applied over the embeddings associated to the knowledge base chunks.
Knowledge Graphs
Recent challenges in RAG engines associated to hallucinations resulting of stochastic nature of LLMs have prompted different strategies to alleviate them. One of the most successful of those is the use of knowledge graphs as mentioned in the previously referred survey on RAG. Many different approaches to incorporate knowledge graphs to RAG have been proposed with varying degree of success, check out Neo4j framework whereby one is able to incorporate concept/topic structure to optimize RAG performance.
Microsoft has also recently dropped their open-sourced graphRAG framework which is precisely built with the purpose of understanding underlying knowledge graphs in knowledge databases through summarization and clustering of concepts, which then can be leveraged for more efficient performance in several RAG tasks.
Their general framework is very similar to what is proposed herein, however RAGenesis attempts to formulate a dedicatedly human-readable version, with AI Interpretability as a forefront value. In particular, The SSN navigation empowered by an accompanying AI agent that analyzes the internal structure of the embedding is a particularly useful instance for explainability of the retrieval engine's behavior. Investigating areas related to sensitive subjects can be a valuable approach for AI Alignment purposes.
Vector DB
For this project I implemented a Milvus database through which similarity can be quickly calculated once the collections are loaded in the database with efficient vector embeddings. Milvus calculates the similarity metric via an index which the developer is allowed to choose, tuning his vectorDB to the specific task at hand, check out documentation for further details.
Definitions
To model a network where nodes and edges are determined by cosine similarity, RAGenesis uses the following mathematical framework:
- Node v_i : Each node (v_i) represents a chunk or verse.
- Embeddings e_i : Each node (v_i) has an associated embedding vector (e_i).
- Edge E_ij : An edge between nodes (v_i) and (v_j) representing a semantic similarity connection between the two verses.
- Semantic Similarity sim(i,j) : A metric given by cosine similarity indexed operation in the Vector Database.
- Similarity threshold p: a value between 0 and 1.
Network Construction
Two steps encapsulate the process of building the Semantic Similarity Network construction. For each node v_i:
- Create edges E_ij between all v_i to the top 10 most similar verses using cosine similarity between v_i and all v_j.
- Drop all edges E_ij where sim(i, j) < p .
Using this framework, you can build the Semantic Similarity Network based on the similarity of embeddings and the given threshold. This structure provides a pathway to analyzing relationships between different chunks based on their semantic similarity.
Notice that this approach does not limit the number of edges per node, but mostly makes the construction of the network more efficient. There are however a few differences in results if rather than looking at the top 10 you connect each node v_i to the full set of verses v_j which allow for sim(i,j) ≥ p, exploring this alternative formulation is a goal of next iterations of this project.
AI Alignment and Safety Applications
The method proposed herein allows for reverse engineering the semantic network that is subjacent to any vector database given an embedding model and a similarity metric implemented as an index in the vector DB.
In a sense, the semantic similarity network allows us to "read the mind" of a given embedding model. Once we infer the structure of similarity relationships across a given knowledge base, we are able to understand how the embedding model groups chunks together, thus obtaining a general picture of their relationships according to the embedding model's perspective. Through the use of the graph theory we are also provided a way to understand hierarchies which correspond to the different centrality levels displayed by the chunks, see next section for details on the centrality measures used in Ragenesis.
This approach has significant implications for work in AI safety. One of the main challenges in this area is guaranteeing transparency and explainability of AI behavior. AI Models internal mechanics can be very challenging, many times being compared to black boxes. The whole field of mechanistic interpretability is dedicated to uncovering these internal principles which explain AI behavior, checkout the AI alignment forum and Neel Nanda's comprehensive thread [AF · GW] on relevant work in the area.
In response to that, the semantic similarity network approach allows for uncovering the underlying preferences of embedding models when applied to build a RAG product over a specific knowledge base.
If you'd like to get a little deeper into the discussion around AI Safety and Responsible AI Checkout this paper on Science Direct — Information and software Technology on transparency and explainability of AI models. Also make sure to check out the AI Risk Management NIST framework, for a comprehensive view of current strategies to ensure and promote responsible use of AI.
Network Centrality Measures
There are many alternative ways to measure centrality, for this work four main measures were applied as these are most commonly used in Network Science literature. Check out some examples of research work that is also based on centrality analysis:
- Biochemistry, check out protein-protein interaction network research by Panga and Raghunathan.
- Political and Social sciences, check out Bonacich's seminal paper where centrality is discussed as a measure of power in societies.
- Complex Network Research, check out Saxena and Iyengar’s survey on the subject
Special nodes given by high centrality metrics were used for the summarization of texts in the years that preceded the explosion of LLMs. In that context, TfIdf scores have been used in many NLP developmental efforts to generate edges between important keywords or passages of text. Recent work on the subject has also continued to produce significant results which, as an upside to the effective and simple LLM summarization, have highly explainable results. Check out Uçkan and Karcı 2020 paper on the subject .
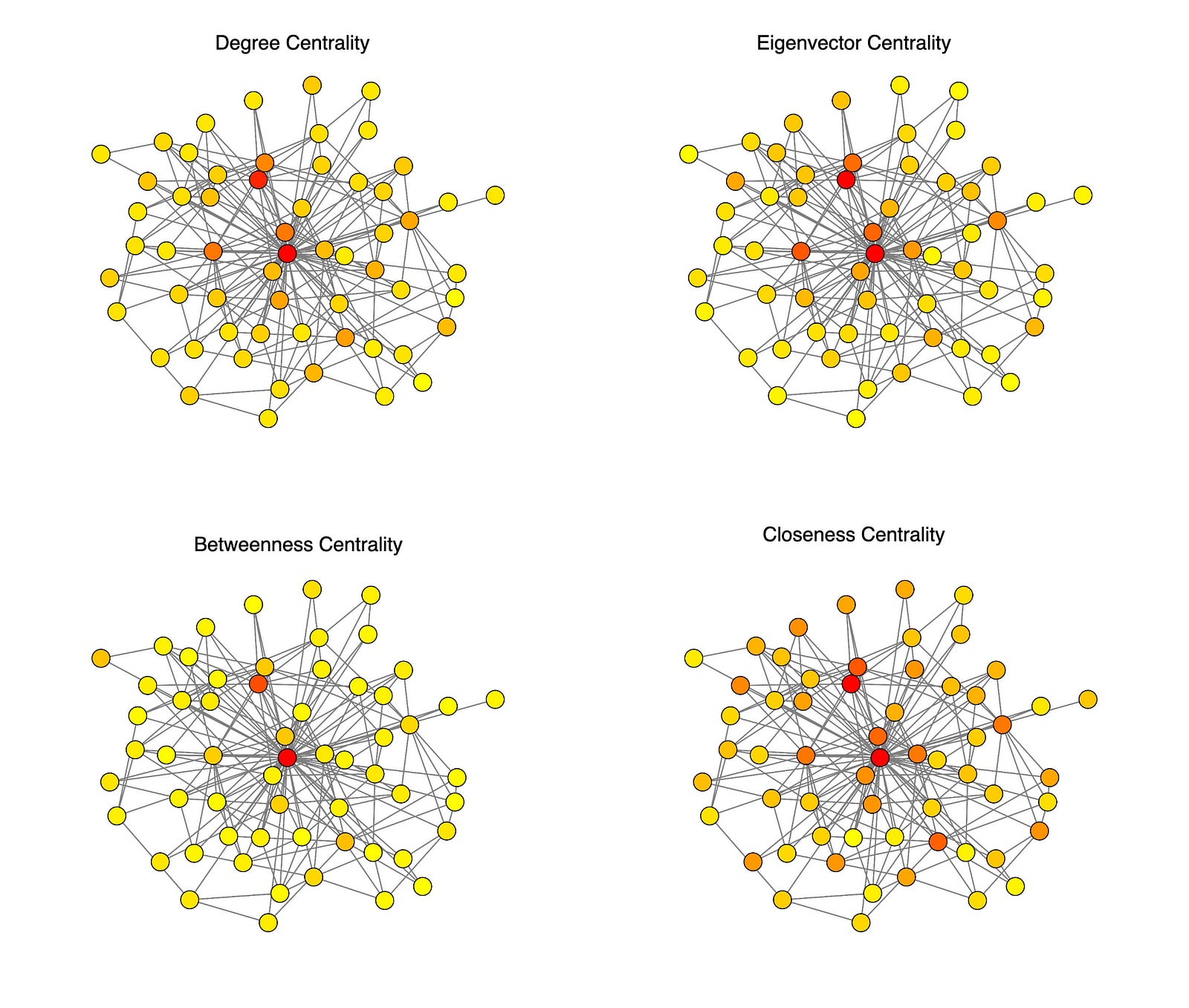
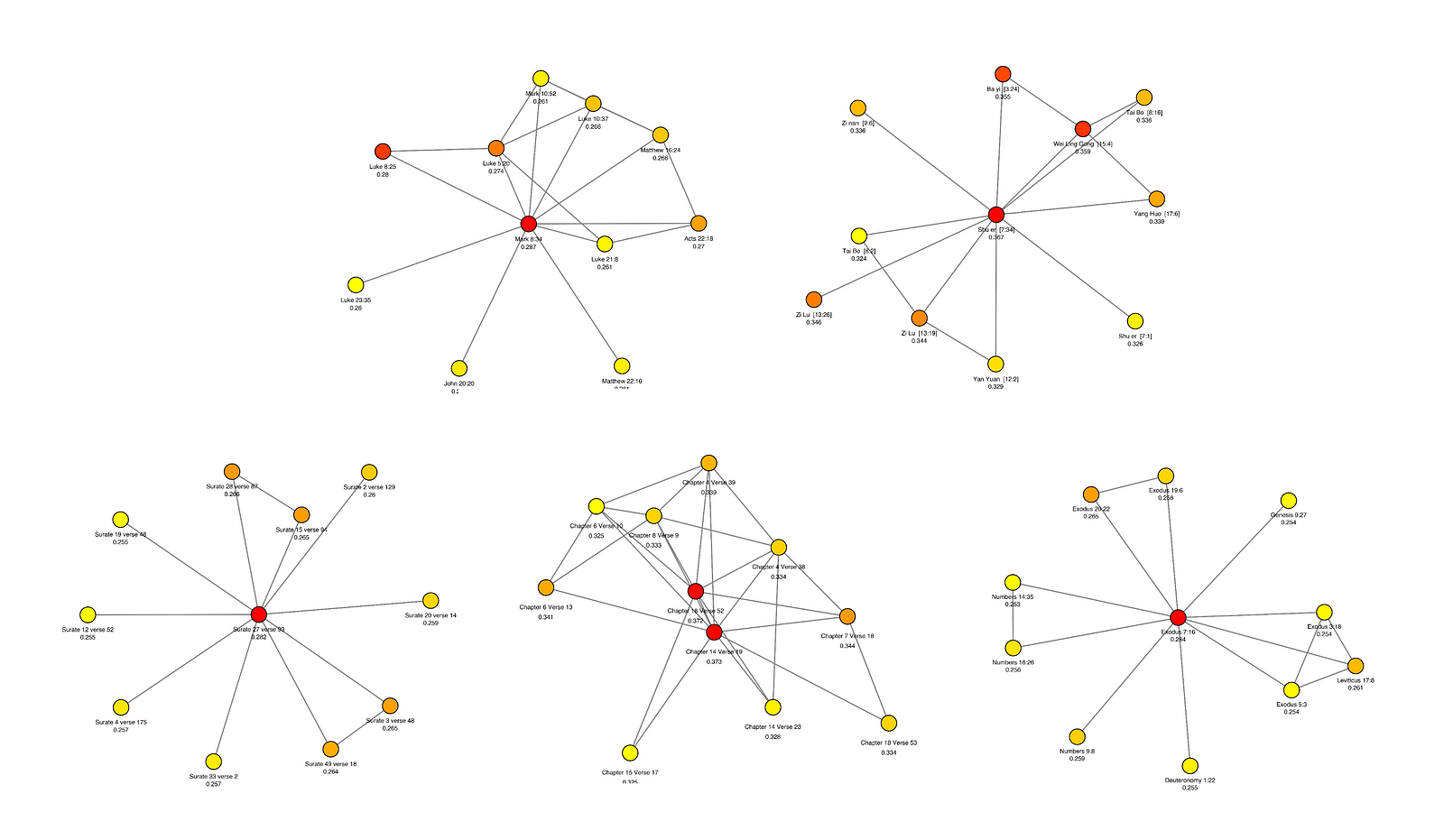
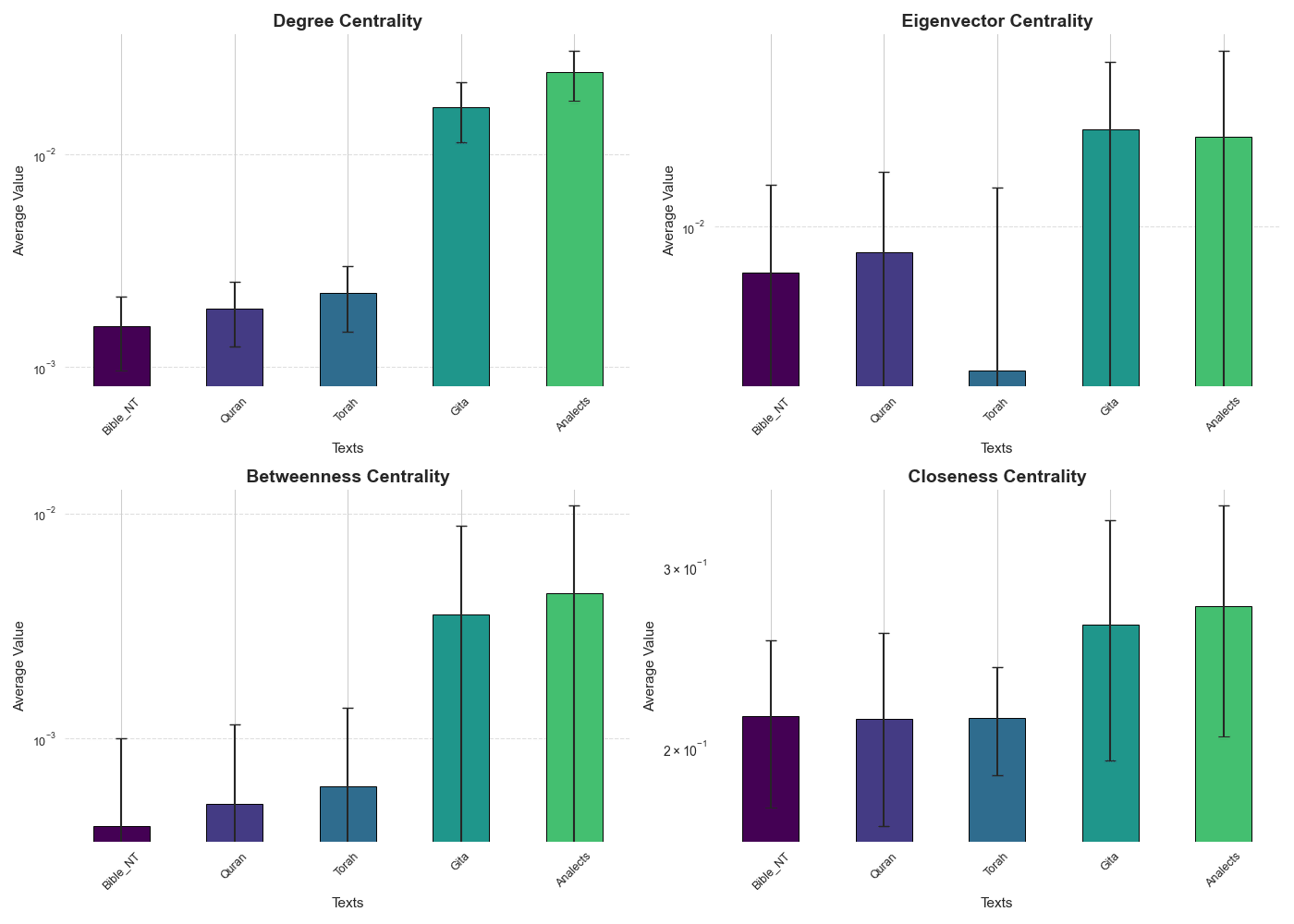
See alternative colorings following different centrality metrics for the most closeness central part of Bhagavad Gita SSN generated with embedding model All-MiniLM-L6-v2 with 0.5 threshold. These graphs use Chapter 14 verse 19 as the center. Notice the values for the coloring correspond to centrality calculated for the full graph of all chunked verses.
I'll give a quick summary on each of the centrality measures that were used in an effort to provide an intuition for the role each of those measures plays. Check out the above references for further detail in formal definition as well as applications.
- Degree Centrality: Proportional to how many connections a node has.
- Eigenvector Centrality: Proportional to how many connections a node has, weighted by connectedness of its neighbors.
- Betweenness Centrality: Proportional to how many paths between nodes is target node a part of, being in between those.
- Closeness Centrality: Proportional to how close is the target node to any other node in the semantic network.
For any network there will be nodes which occupy a special places where each of those centralities are maximum. For semantic similarity networks, those special nodes express the central spots in the maps of meaning which the SSN represents. In a sense, the special nodes provide a pathway towards a "statistics of meaning" which expresses main messages of the embedded text in the context of the analyzed RAG application. This what I refer to as a main chunk methodology: by localizing the central chunks in the SSN, one is able to understand what are the most relevant embedded chunks for the used embedding model.
Notice different types of centrality have nuances in the aspects of the network they express. For the context of this application I chose to use Closeness Centrality to provide the colorings for the visualizations that the app provides to the user. In my perspective closeness centrality is the most intuitive in terms of its definition among the measures which express relationships of the analyzed verse with the whole of the source text (Degree centrality is very intuitive but only tells us something about the vicinity of target node, rather than a general picture of the role the target node plays in the network). Check out next section on SSN network visualization for more details on that method.
The use of the other alternative centrality measures for navigation and visualization of the network is a possible future improvement of RAGenesis, I plan on eventually adding a select box to allow for multiple centrality based navigation.
For the case of analyzing the main verses, however, all centrality types are available to provide a broader view and a more complete the summarization of main messages in the knowledge base as provided by these special nodes in the network.
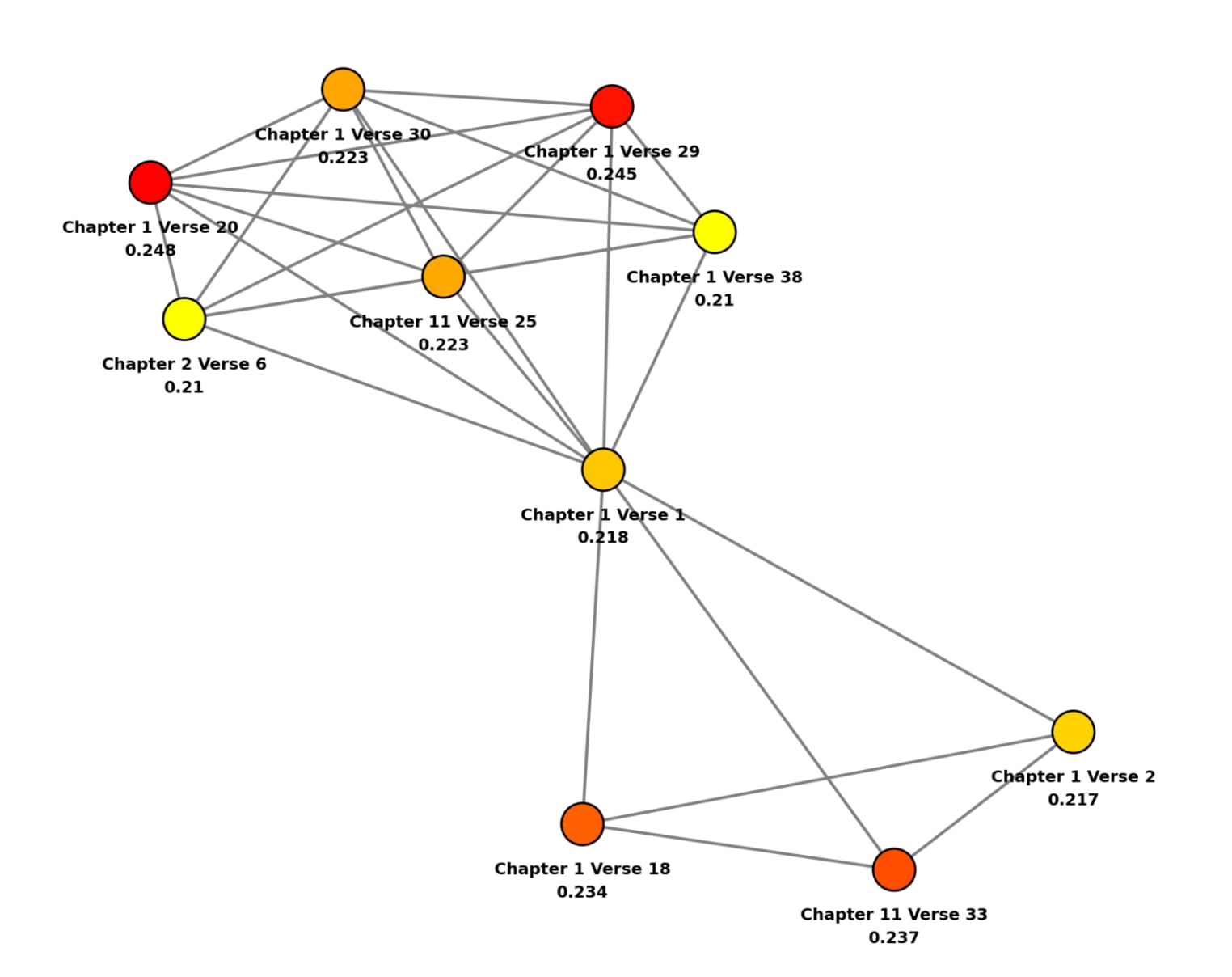
SSN — Network Visualization
There are two possible view configurations in the Semantic Network page, All Verse and Main verses. Since the networks associated to all used source texts have at least over 500 nodes, visualization and navigation of the full network can be challenging. With that in mind I developed a simple view over a target node prioritizing, among its neighbors, the top 10 higher closeness centrality among them.
- Main Verses: show the maximum centrality verses for all centrality types, and display the subgraph formed by the top 10 most closeness central neighbors to the maximum closeness centrality verse.
- All Verses: User can pick any verse from the toggled source text and plot the subgraph for the target node corresponding to the chosen verse and its the top 10 most closeness central neighbors.
Embedding Model
In any RAG application, there is a big dependency with the chosen embedding AI Model, which will provide the vectorized representations of the document chunks to be retrieved and used as input by the generative model.
That means that different embedder models will behave differently in the way they establish semantic similarity across chunks of the text. Come to think of it, different embeddings really express different worldviews altogether, which are reflective of different architectures and different dimensionalities they deal in as well as different training data and training procedure.
RAGenesis platform allows the user to test the perspectives of two embedding models:
- all-MiniLM-L6-v2: this model is the result of a self-supervised contrastive learning approach on a large datasets of sentence pairs. Check out Hugging Face documentation for more details.
- jina-clip-v1: Multimodal embedding model created by JINA.AI . This model is the result of a novel three-stage contrastive learning training method for multimodal models, which maintains high performance on text-only tasks, such as the one it has on Ragenesis. Check out JINA's paper on Arxiv for further details.
The semantic similarity network provides a strategic way to map meaning as it results from the interaction between a chunked knowledge base and an embedding model. Analyzing centralities of the network tells us both something about the knowledge base and something about the embedding model when combined with a similarity metric. The best way to distinguish what is intrinsic to the embedding model and what is intrinsic to the knowledge base is:
- Test SSN approach with different embedding models for the same knowledge base.
- Test SSN approach with the same embedding models for different knowledge bases.
RAGenesis actually allows the user to do both, since one is able to choose any of the source texts in a same embedding model setting, and also to choose among two different embedding model's while looking at the same knowledge base.
Notice the choice of the similarity metric is also part of that equation and is also responsible a different resulting network, so a rigorous investigation on any intrinsic truths about knowledge bases or embedding models would involve controlling and testing other parameters as well which can be relevant to the final obtained result.
Unsurprisingly, as will be reported in the next section, the results that we find for the central nodes analysis are dependent upon the embedding model. That confirms the two embedding models employed during this project have different semantic similarity landscape, in a sense, they have different world views altogether.
Nevertheless, there are aspects of the way both models read the source texts in which they converge. See section Main Messages of the Great Book for resulting summarization of the two embedding models in both parameter configurations.
Threshold Parameter
The threshold parameter for the existence of an edge between two nodes (or a link between two verses) has strong impact on the outcome of building the semantic similarity network. When we define the semantic similarity network based on this threshold we are actually losing a little bit of nuance in the semantic relationships.
There is a possible alternative continuous formulation of the semantic similarity network using the score given by the cosine similarity to give weights to the edges as defined by each pairwise semantic similarity measure, this can also benefit from a role that chops out edges which weight below a certain threshold p. I plan on exploring that variation of SSN construction in the future.
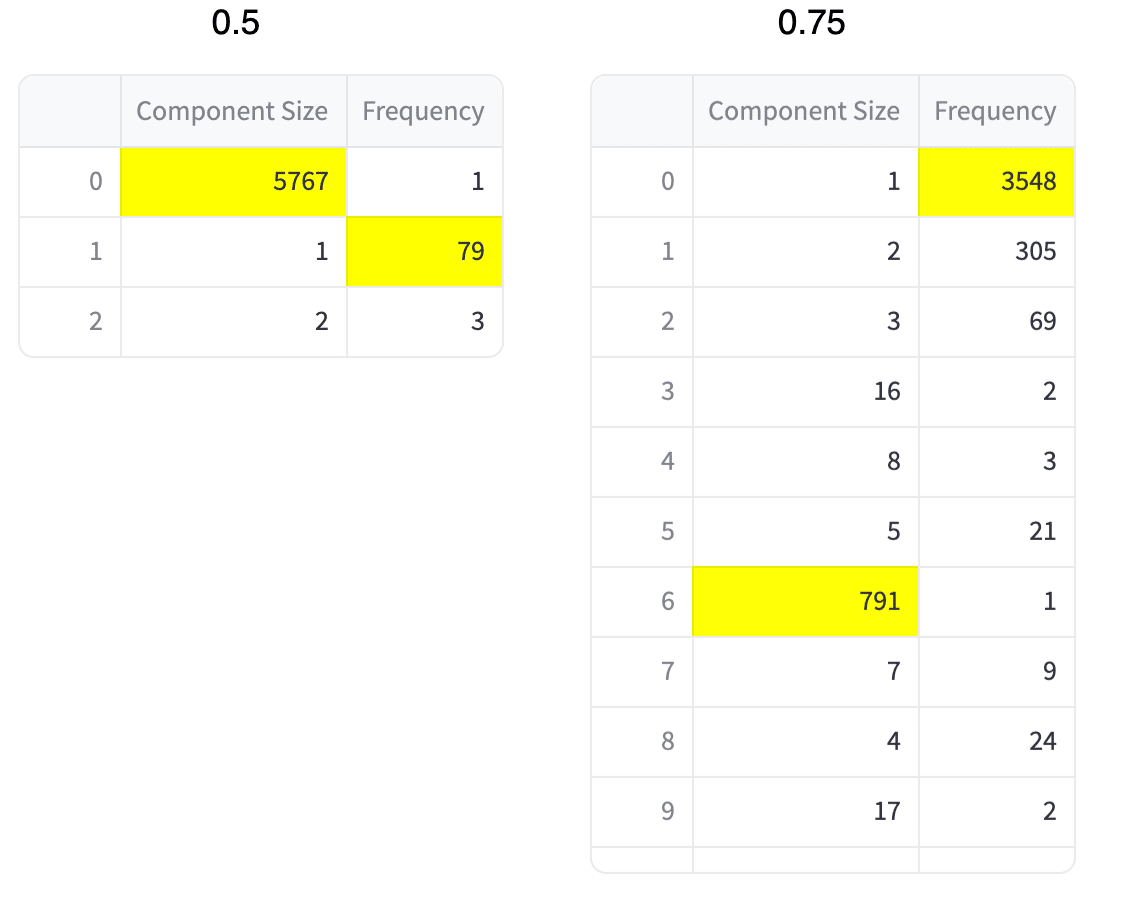
Ragenesis in the Semantic Network page provides two different configurations of the threshold parameter, those usually generate one bigger connected graph and leave a small quantity of verses in different connected components. All metrics displayed in this article and in the app correspond to values obtained through targeted analysis of the largest connected graph component in the resulting SSN, analysis of smaller components is a possible future iteration of this project. The two different threshold parameters are:
- 0.5 : produces highly connected graphs with small number of disjoint components
- 0.75 : produces less connected graph with a larger number of disjointed components
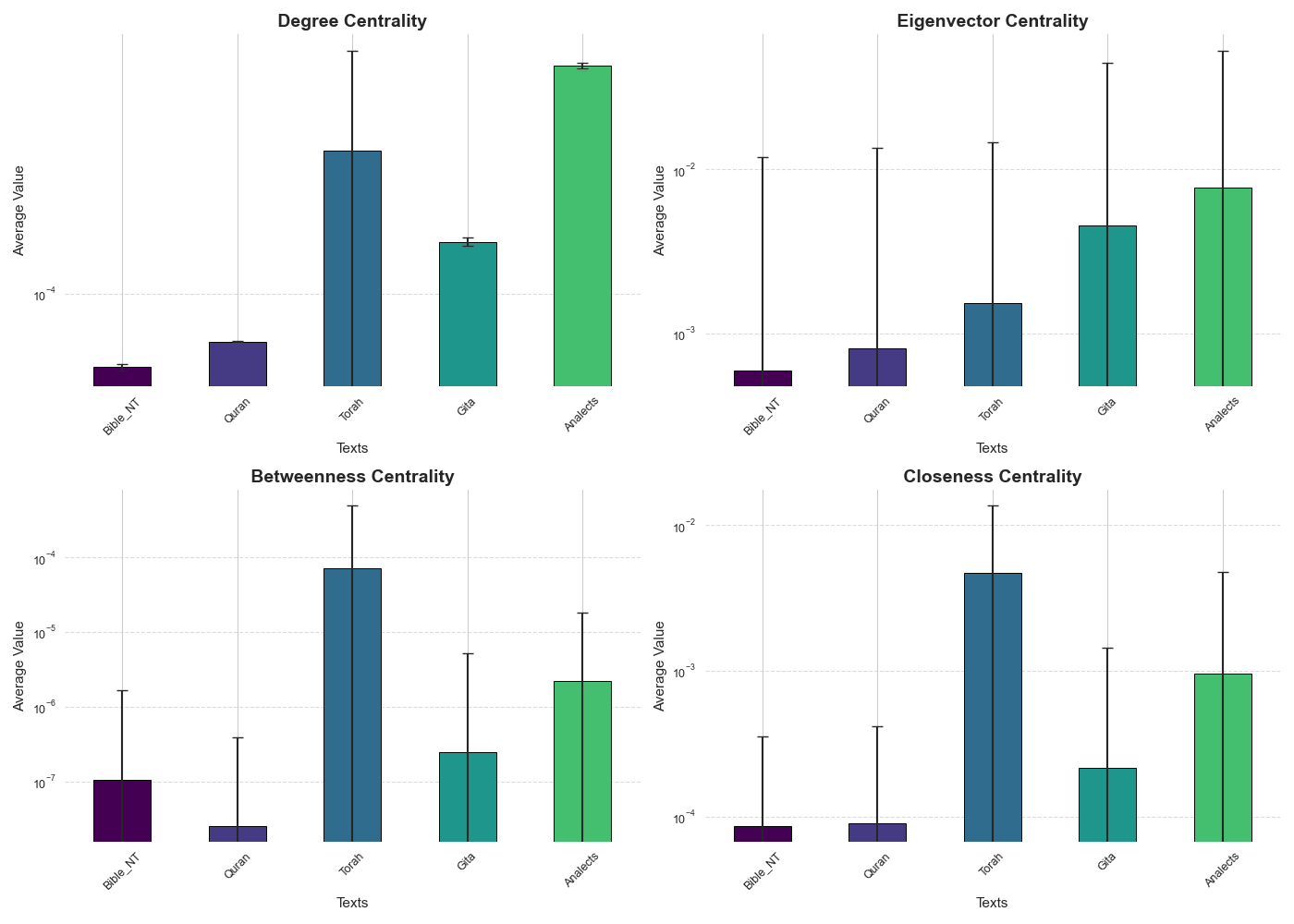
See plots above for average and standard deviation on the centrality values for the five source texts, results showcased herein for all-MiniLM-L6-v2 are actually very consistent with what is observed for jina-clip-v1. For the sake of avoiding too lengthy a post, I’ll be saving a more thorough direct comparison across the obtained results for coming posts. Make sure to check out component length histogram table example below, as well as in RAGenesis semantic network page in main verses configuration.
Computational considerations — Rustworkx
I originally implemented the analysis of central modes using the Networkx python package, which quickly became an ordeal, specially when dealing with the full text of the bible in some preliminary tests.
Calculating all centrality measures herein studied for a 25k node graph (the complete Bible case) already becomes hard to manage within reasonable computational constraints.
To provide faster and more efficient calculations when deploying the application I transitioned the code to rustworkx python library (previously known as retworkx), which was created in the context of Qiskit quantum computing library. Check out Qiskit post on medium.
Main Messages of the Great Books
As mentioned earlier, all results for node centrality are dependent on embedding models, threshold parameter and similarity metric choice. Nevertheless, there are convergences between the main verses found with different settings in semantic similarity network which are worth exploring as a representations of general messages pertaining to each of those books.
You can experience the Exegete agent in the main verses configuration of the Semantic Network page, as described earlier, his role is to interpret the core concepts associated to the identified central verses in any given configuration.
Having contemplated the results obtained in all available configurations in the app, I'll humbly try to express my impression of what the results coming from the semantic similarity network approach tend to indicate for each of these books.
As a disclaimer, I'd like to reiterate that this work is done with utmost respect for all traditions and is only representative of my own personal perspective on the final results suggested by the SSN approach.
For each of the texts I'll display here the graph from one of the configurations (embedding model All-miniLM-L6-v2 with 0.5 threshold) for the purpose of simplicity and I'll also make very a brief summary of the ideas which appear in other configurations. I plan on making more thorough observations on each of the books in following posts, also examining cross-text metrics and sections of each semantic similarity network emerging from specific parameter settings.
Bible (New Testament)
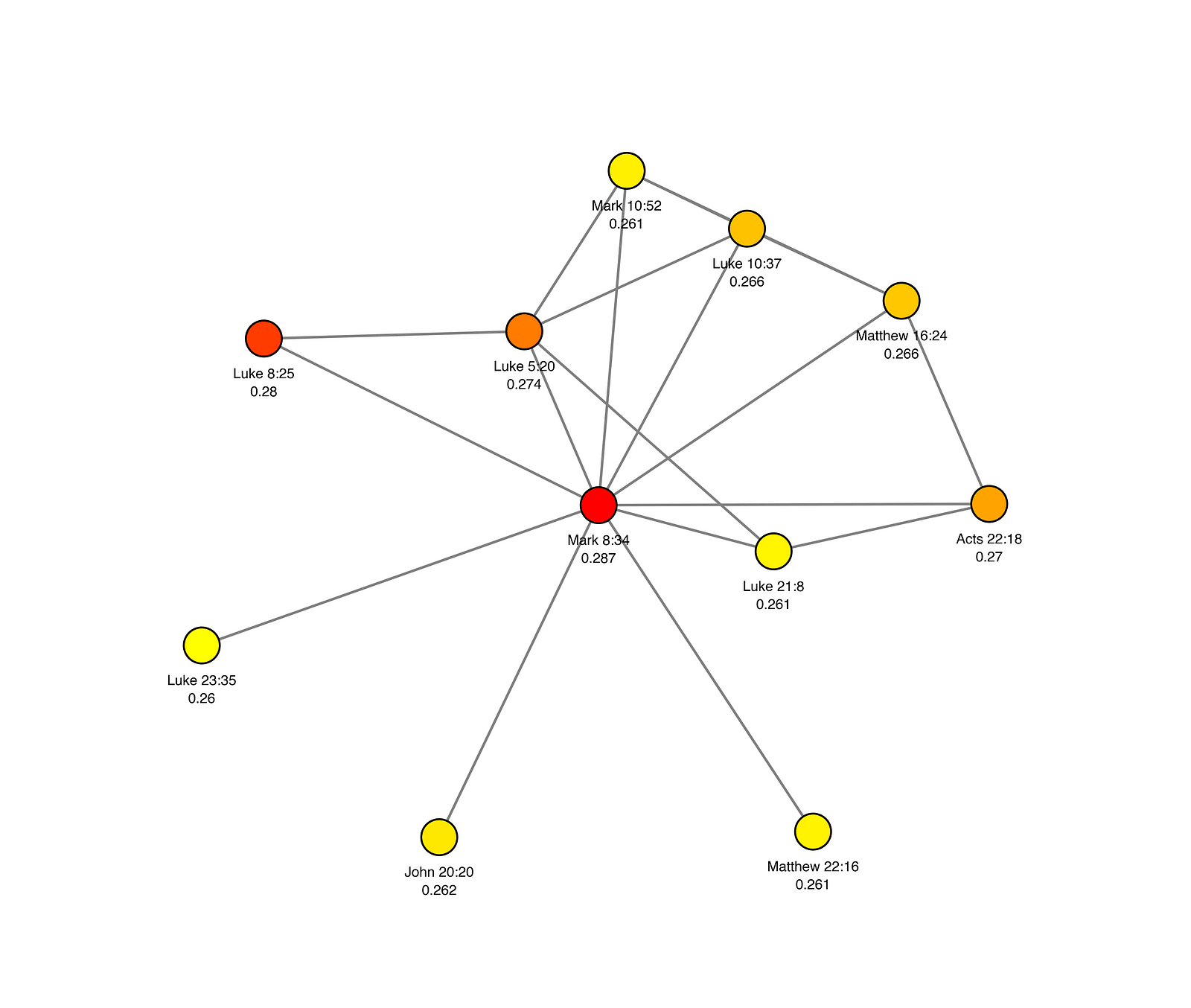
- Follow Jesus Christ.
- Sacrifice and self-denial.
- The grace of God.
Torah
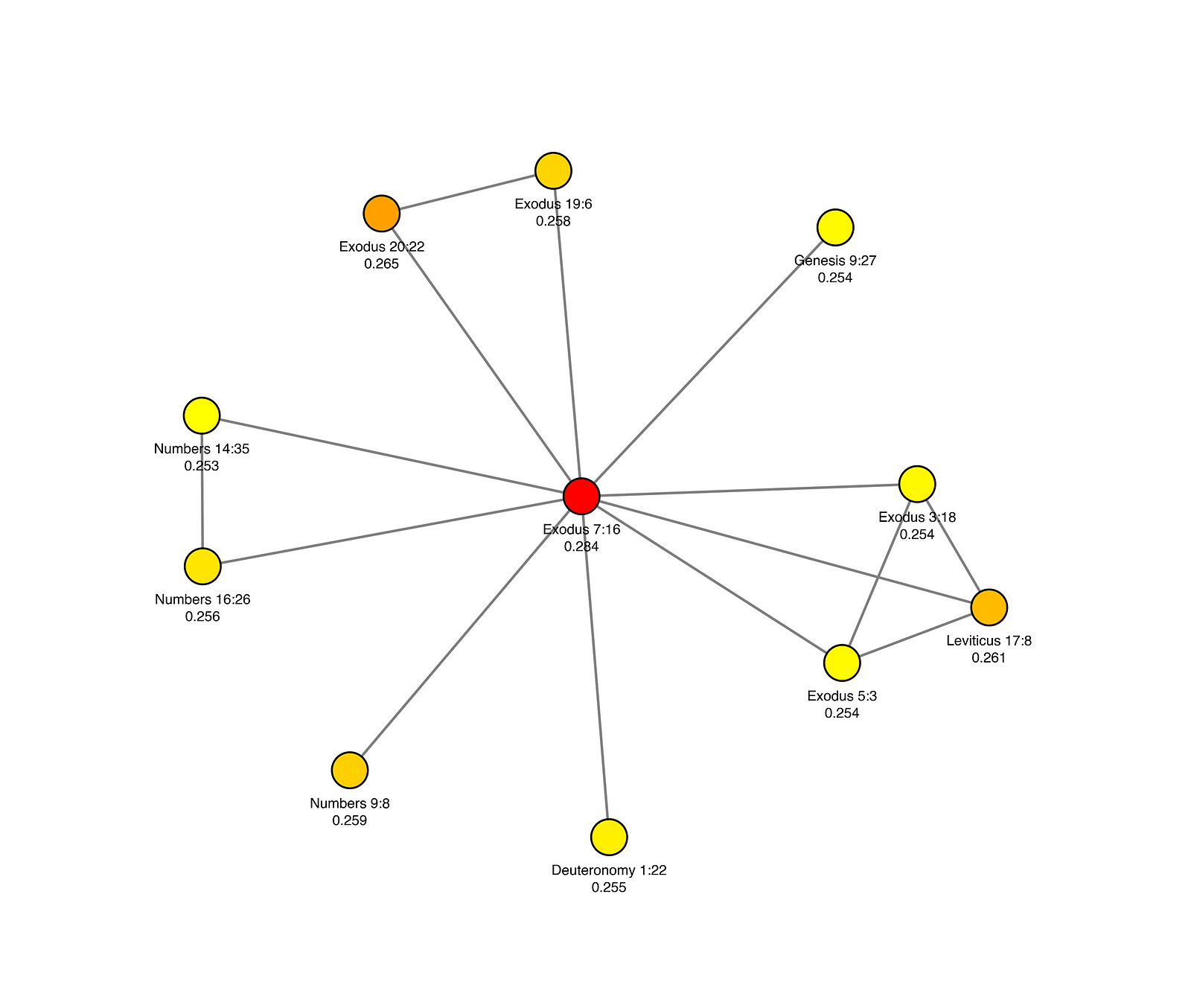
- Moses leads the Hebrew people away from slavery.
- Hebrews are the chosen people.
- The heritage of the Hebrew people.
- Obedience to God.
Quran
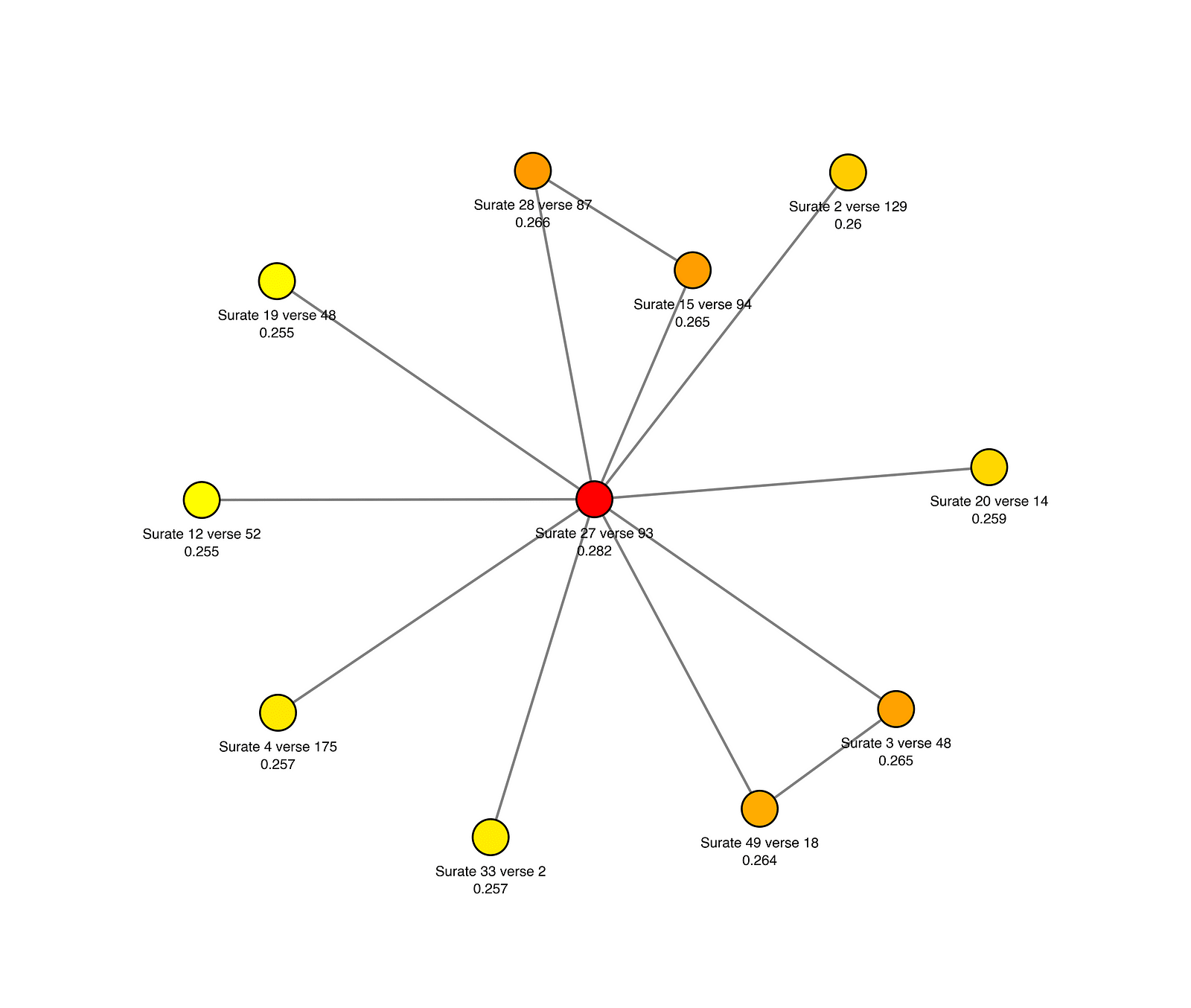
- Omniscience, omnipotence and benevolence of Allah.
- Unity among believers.
- Trust in Allah's promises, the salvation of believers.
- Impending Judgement day.
Bhagavad Gita
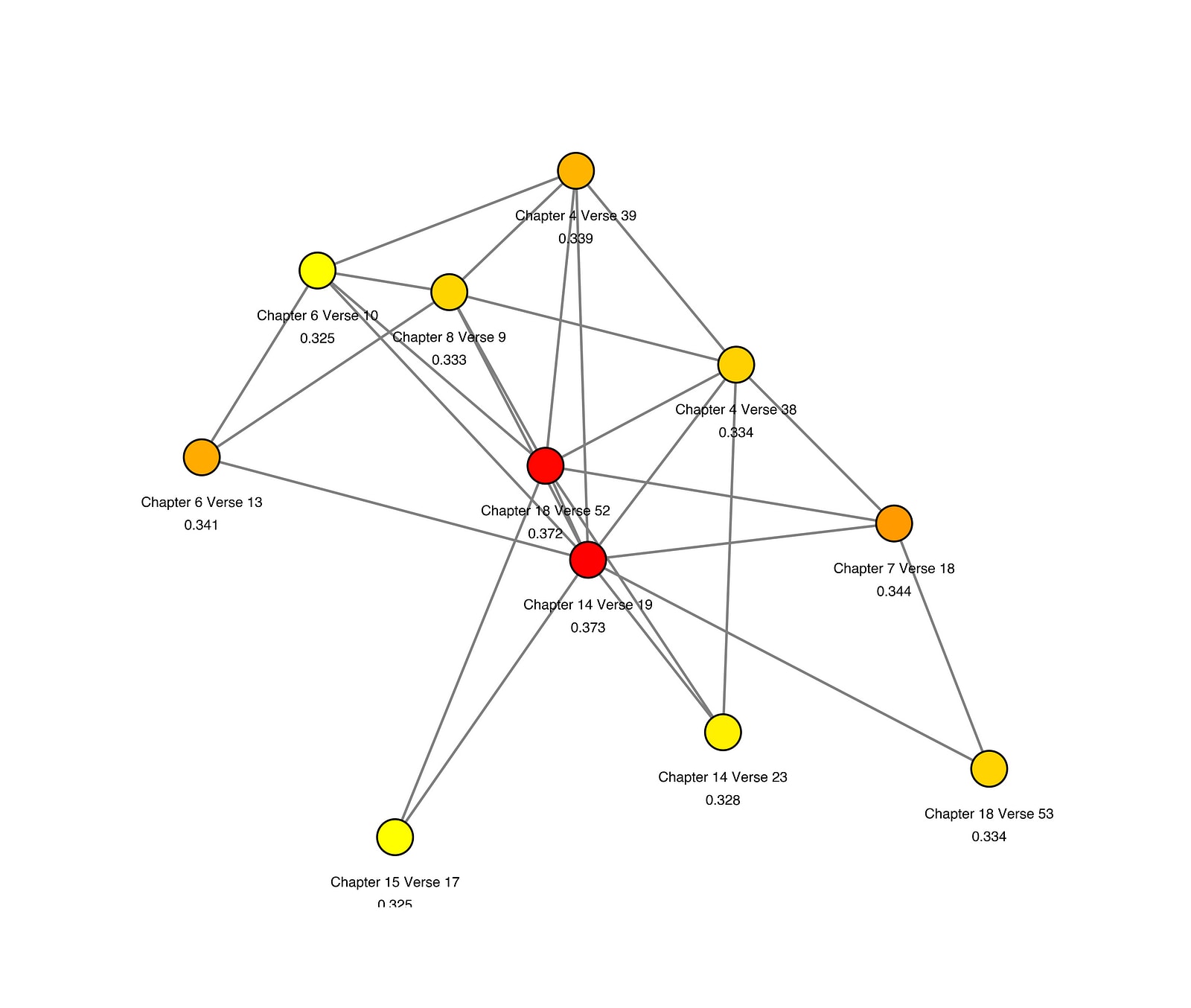
- Krishna gifts Arjuna with knowledge.
- All phenomena are modes of nature.
- Krishna is nature, but also transcends it.
- Absence of desire or lamentation is the state of devotion to the Supreme being.
Analects
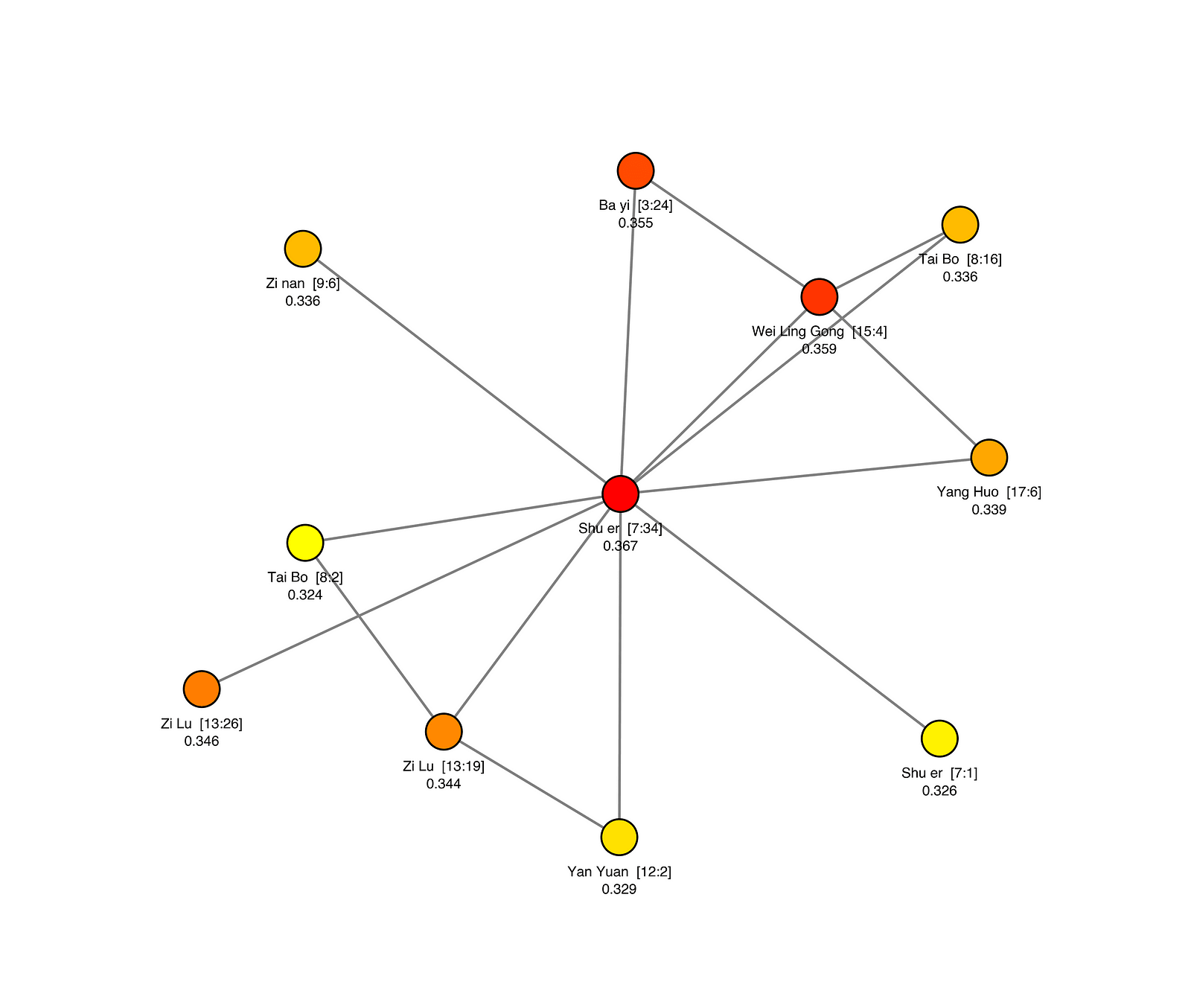
- The superior man cares about virtue and fairness; the inferior man cares about material things and his own advantage.
- Virtue (ren) is rare and hard to attain.
- Confucius does not claim to be virtuous, only disciplined.
- Leadership of Confucius is harmony.
As a follow-up post to this one I'll be showcasing direct comparisons across the source texts following the SSN method. Merging the different SSNs is also a very importante step that will allow for the evaluation of consistency of messaging across the source books, in the perspective of a given embedding model. Toggling multiple source texts in the semantic network page in order to produce SSN merge is a future improvement of the platform.
AI and Religion
Given the importance ascribed to the Bible, the Torah, The Quran, The Bhagavad Gita and the Analects as pillars of civilization and sacred texts of many different religious traditions, exploring of such texts via AI algorithms is currently surfacing as a trend that might provide relevant contributions to religious studies. I recommend this article on iTmunch as a good starting point for anyone that is interested in going a little bit further on this topic.
I independently stumbled upon this idea while working with RAG products serving many different industry use cases, and thinking to myself what kind of other solutions this kind of tool might provide. Nevertheless, it wasn't surprising to me that with a quick internet search I was able to come across some similar tools such as BibleAI and GitaAI, dedicated to the specific scope of each religion, rather than providing an inter-religious or ecumenical approach as the one I have developed in RAGenesis.
On Stochastic Literature
As mentioned at the beginning of this article, RAGenesis is mostly a reading tool. As a last commentary on the product aspect of this project, as a bookworm myself, I'd like to emphasize that AI has introduced many novel ways for readers to experience texts through the use of RAG techniques and other strategies, there is much ground to be covered there yet.
I am particularly interested in how brain computer interfaces can accelerate interaction between user/reader and source texts, the text input being in fact still a very rudimentary way to translate user/reader interests into a RAG pipeline.
Before Tyler Cowen's imaginative spin on generative books, stochastically-driven book experiences have been available for ages, the aforementioned I Ching and other oracular books being good examples of the more ancient kind.
Other interesting examples which come to my mind are Steve Jackson's RPG lone adventures which were for a me a great thrill as a kid. As a reader you would have to jump lots of pages back and forth according to choices made as a player, that brought the player to alternate paths taken during his adventure.
Similarly, the SemanticNetwork page allows the user to uncover the non-linear paths which weave meaning through the chosen corpus, thus opening the door to meaningful alternative adventures the chosen corpus has to offer.
In literature, I've been influenced by two specific references which also have a lot of resonance with the ideas I developed under the Ragenesis initiative. “Lover’s Discourse: Fragments” by Roland Barthes has a very interesting structure of consistent retrieval of fragments from other authors using themes which unravel the language of love in its many idiosyncrasies, as though validating the universality of love's longings through retrieval, with the author largely inputting his generative input over retrieved material.
In “Hopscotch” by Julio Cortazar, the author famously provides two alternative approaches to ordering of the chapters, and also suggests that none of them is the best, the final responsibility laying on the shoulders of the reader to read his way through both of the proposals or to find his own singular path through the text.
Conclusion
Depending on the goal posed by the specifics of each application it is crucial to provide a framework for evaluating the performance of the retrieval and generation engines, and accompanying strategies for continual improvement, aiming at long term application robustness.
The strategies developed in this project showcase an effective strategy to reverse engineer semantics associated with embedding spaces and chunked knowledge bases. This work demonstrate how these embeddings prioritize certain concepts over others while navigating through a chunked vector database.
Recent work in AI has suggested that indeed activation driven by token processing inside of neural networks corresponds to super-dimensional activation in feature space, which can be interpreted as concept space as well. Ragenesis effort provides a simple and intuitive lens to investigate the clusterings and groupings which are subjacent to a similarity metric in vector embedding spaces.
Future Extensions
Some of the possible future improvements:
Improving Semantic Network Page
- At this point, Semantic Network page only offers a dedicated view into each of the books. Providing a view into the merged graphs associated to each possible combination of the source texts is clearly the pathway for deepening the exam on the universality and singularities associated with the messages that are part of the source texts.
- Semantic Network page exclusively colors nodes in the graph based on the closeness centrality metric, and also uses closeness centrality to base the navigation. Eventually I plan on adding a select box to provide specific view of each different centrality metrics for the subgraph view.
- Top 10 per node criteria in SSN construction can be relaxed, and will probably produce more precise results, at the cost of some computational efficiency, especially in the highly connected parts of the semantic similarity graph where the central nodes reside.
- Incorporate a cross-text data visualization page, whereby the user can directly compare the statistics between the texts.
Expanding Knowledge Base
- Introduction of new texts, expanding into different classical books. Both in the religious sphere as well as others. I have particular interest in using this framework to evaluate consistency across philosophical discourse. The same can also be done for constitutions and legal documents in general, where semantics can play a specially important effect.
Applications and developments of Semantic Similarity Network
- Continuous case: incorporate weights to the edges based on semantic similarity and define weighted edges as more fine grained expression of the semantic similarity network. In this context, the main centrality metric should also consider the weight of the edges (the similarity scores).
- Test reverse engineering the maps of meaning in other embedding models through Semantic Similarity Network screening. I have particular interest in investigating this approach in the context of internal layers in LLM models, both at the initial token embedding stage but also when it comes to attention and MLP layers, and even multiple stages of the residual stream. Through all of an LLMs architecture there is a point to be made that one is consistently applying transformations to embeddings and consistently operating on vectorized representations of concept feature space.
Tech Stack
Here goes a very brief summary what was used in terms of the tech stack involved in building this platform.
- VectorDB and Retrieval Engine: Milvus
- Embedding Models: all-MiniLM-L6–V2 and jina-v1-ai
- Generative Model: LLama3 served via Amazon Bedrock service
- App Framework: Streamlit
- Cloud Provider: AWS
You can see full code for this application at https://github.com/JoaoRibeiroMedeiros/RAGenesisOSS . I plan on delving deeper on more aspects of the design choices for coding as well as the infrastructure in future posts.
Thank You : )
I'd like to thank Julio Ribeiro, for many discussions on the past, present and future of AI, Luciana Monteiro, Cristina Braga and Maria Teresa Moreira for fruitful conversations and alpha testing of the RAGenesis platform, Rebeca Barreto for suggesting Roland Barthes reference, Gustavo Freire and Nahum Sá for discussions on Kubernetes deployment. Also would like to thank Anna Chataignier for continuous support.
If you got so far in this article, thank you for reading this. I deeply appreciate the time you spent, hopefully you got something good out of it. Let me know what you think! I eagerly expect suggestions, discussions, criticisms. Reach me on:
https://joaoribeiromedeiros.github.io/
References and Bibliography
https://github.com/JoaoRibeiroMedeiros/RAGenesisOSS
What Is Retrieval-Augmented Generation aka RAG?
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models…blogs.nvidia.com
GOAT: Who is the greatest economist of all time and why does it matter?
A generative book by Tyler Cowenecongoat.ai
AI Alignment Forum
A community blog devoted to technical AI alignment researchwww.alignmentforum.org
AI Risk Management Framework
NIST-AI- 600-1, Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile …www.nist.gov
An Extremely Opinionated Annotated List of My Favourite Mechanistic Interpretability Papers v2 - AI… [AF · GW]
This post represents my personal hot takes, not the opinions of my team or employer. This is a massively updated…www.alignmentforum.org [AF · GW]
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
Eight months ago, we demonstrated that sparse autoencoders could recover monosemantic features from a small one-layer…transformer-circuits.pub
Retrieval-Augmented Generation for Large Language Models: A Survey
Large Language Models (LLMs) showcase impressive capabilities but encounter challenges like hallucination, outdated…arxiv.org
AI scientists are producing new theories of how the brain learns
The challenge for neuroscientists is how to test them | Science & technologywww.economist.com
PaperQA: Retrieval-Augmented Generative Agent for Scientific Research
Jakub Lála Odhran O’Donoghue Aleksandar Shtedritski Sam Cox Samuel G Rodriques Andrew D White Future HouseFrancis Crick…arxiv.org
sentence-transformers/all-MiniLM-L6-v2 · Hugging Face
We're on a journey to advance and democratize artificial intelligence through open source and open science.huggingface.co
Jina CLIP v1: A Truly Multimodal Embeddings Model for Text and Image
Jina AI's new multimodal embedding model not only outperforms OpenAI CLIP in text-image retrieval, it's a solid image…jina.ai
Jina CLIP: Your CLIP Model Is Also Your Text Retriever
Contrastive Language-Image Pretraining (CLIP) is widely used to train models to align images and texts in a common…arxiv.org
Five Levels of Chunking Strategies in RAG| Notes from Greg’s Video
Introductionmedium.com
A cytokine protein-protein interaction network for identifying key molecules in rheumatoid…
Rheumatoid arthritis (RA) is a chronic inflammatory disease of the synovial joints. Though the current RA therapeutics…pubmed.ncbi.nlm.nih.gov
Power and Centrality: A Family of Measures on JSTOR
Phillip Bonacich, Power and Centrality: A Family of Measures, American Journal of Sociology, Vol. 92, No. 5 (Mar…www.jstor.org
Centrality Measures in Complex Networks: A Survey
In complex networks, each node has some unique characteristics that define the importance of the node based on the…arxiv.org
Cosine similarity — Wikipedia
In data analysis, cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product…en.wikipedia.org
tf-idf - Wikipedia
In information retrieval, tf-idf (also TF*IDF, TFIDF, TF-IDF, or Tf-idf), short for term frequency-inverse document…en.wikipedia.org
In-memory Index | Milvus Documentation
Index mechanism in Milvus. | v2.4.xmilvus.io
Learn About Retworkx — The Graph Library Used by Qiskit — And How to Contribute
By Matthew Treinish, Senior Software Engineer at IBM Researchmedium.com
15 Advanced RAG Techniques | WillowTree
With this guide on advanced RAG techniques, you'll drive greater performance and lower costs from your retrieval…www.willowtreeapps.com
Welcome to GraphRAG
👉 Microsoft Research Blog Post 👉 GraphRAG Accelerator 👉 GitHub Repository 👉 GraphRAG Arxiv Figure 1: An…microsoft.github.io
Bible Ai | Millions of answers backed by biblical knowledge and Ai
Discover the power of Ai and the Bible with Bible Ai. Get accurate answers to biblical questions, as well as pastoral…bible.ai
Bhagavad Gita AI - Gita GPT - Ask Krishna
GitaGPT is a free Bhagavad Gita AI chatbot that uses the wisdom of the Bhagavad Gita to help answer your day-to-day…bhagavadgita.io
Tanzil - Quran Navigator | القرآن الكريم
Browse, Search, and Listen to the Holy Quran. With accurate Quran text and Quran translations in various languages.tanzil.net
The Project Gutenberg E-text of The Bhagavad-Gita
The Project Gutenberg EBook of The Bhagavad-Gita, by Anonymous This eBook is for the use of anyone anywhere at no cost…www.gutenberg.org
Analects: http://www.acmuller.net/con-dao/analects.html
Bible: https://www.gutenberg.org/cache/epub/10/pg10.txt
Knowledge Graphs Framework: https://neo4j.com/
Science Direct — Topics — Semantic Networks
Transparency and explainability of AI systems: From ethical guidelines to requirements, Nagadivya Balasubramaniam, Marjo Kauppinen, Antti Rannisto, Kari Hiekkanen, Sari Kujala
Extractive multi-document text summarization based on graph independent sets, Taner Uçkan, Ali Karcı
0 comments
Comments sorted by top scores.