Breaking down the training/deployment dichotomy
post by Erik Jenner (ejenner) · 2022-08-28T21:45:49.687Z · LW · GW · 3 commentsContents
The training/deployment view on ML Exceptions to the training/deployment archetypes Exceptions will likely become more common and extreme Takeaways None 4 comments
TL;DR: Training and deployment of ML models differ along several axes, and you can have situations that are like training in some ways but like deployment in others. I think this will become more common in the future, so it's worth distinguishing which properties of training/deployment any given argument relies on.
The training/deployment view on ML
We usually think of the lifecycle of an ML model as a two-phase process: first, you train the model, and then (once you're satisfied with its performance), you deploy it to do some useful task. These two phases differ in several ways:
- During training, you're modifying your model's parameters (e.g. using SGD), whereas they're often fixed during deployment.
- Mistakes your model makes during training are not a big deal (and even expected initially—that's why you need to train the model). But mistakes during deployment can be costly.
- A reason for this can be that your model is sandboxed during training in some way, whereas it's interacting with the real world in deployment. Another one would simply be that you're not using the model's outputs for anything important during training.
- The deployment distribution might differ from the training distribution. Additionally, the deployment distribution could change over time in ways that you can't foresee (the training distribution is often fixed, or you at least have a sense of the ways in which it's changing).
Exceptions to the training/deployment archetypes
Here's a table summarizing typical properties of the training and deployment phase from the previous section:
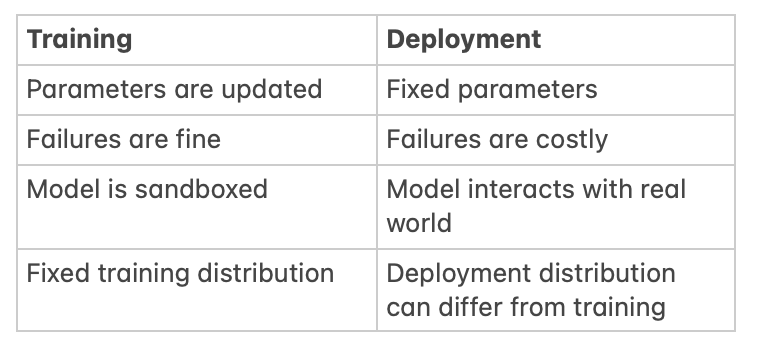
Clearly, these don't always hold. Some examples:
- You might update parameters even when the model is deployed (e.g. continuously fine-tuning to deal with distributional shift, or to incorporate new data you got). How much parameters are updated also isn't constant during training if you're using a learning rate scheduler.
- Failures during training may sometimes be costly too. A mundane example would be doing RL with an expensive physical robot that could be damaged. A more extreme case would be a misaligned AI taking over the world while it's still in training.
- There are clear examples of models not being sandboxed during training, such as WebGPT.
- The distribution can already change during training, e.g. when an RL policy becomes more competent and reaches parts of state space that it couldn't access before.
All these exceptions can occur in various combinations and to various degrees. That implies two things:
- These properties (such as parameter updating, cost of failures, ...) can become less correlated with each other than the training/deployment view implicitly suggests.
- Training vs deployment (or each separate property) can become more of a spectrum than a binary choice.
Exceptions will likely become more common and extreme
I'd say that for now, the training/deployment view is usually a pretty good approximation that only requires minor caveats. But I expect that the types of exceptions from the previous section will tend to dominate more and more in the future. For example:
- As mentioned, powerful AI systems could already pose a risk during training, not just in deployment.
- Future models could already be very useful before they're finished training. So you might start using your model for important things (at least internally) while still continuing to improve it. This is especially true if training runs take a long time.
- Interacting with the real world during training (e.g. like WebGPT) will likely become more common since lots of capabilities are infeasible (or much harder) to learn otherwise.
- Even if desired, securely sandboxing powerful AI systems during training is probably infeasible.
- From a safety perspective, the most important distributional shift is probably not the shift between training and deployment distribution (which could in fact become pretty small if training is already happening with real-world interactions). Instead, the issue is a "cognitive distributional shift" as the AI becomes smarter and can come up with plans that it previously didn't consider. This means most of the distributional shift might happen during training, rather than at the boundary between training and deployment.
Takeaways
I am skeptical that the training/deployment view is a good one in many discussions related to AI safety. Most importantly, I don't think that all of the danger comes from the deployment phase, nor that distributional shift mostly happens between training and deployment. I'd guess that many (most?) people who are talking about "training" and "deployment" would agree with that, but these claims could easily be seen as implicit assumptions by others, especially newcomers. (As one datapoint, I did not realize some of the things in this post until pretty recently. And I'm still not sure how many people do think that training and deployment will continue being just as valid a framework as they are now).
Less certainly than most of this post, explicitly thinking about the various axes along which training and deployment differ also seems to suggest productive/clear frameworks. (For example, I used to think of distributional shift as a phenomenon that makes sense on its own, whereas I now usually think about the rate of distributional shift over time compared to the rate of updating the parameters/the rate of oversight.)
Thus my suggestion: when you notice yourself thinking or talking about "training vs deployment" of future AI models, try to figure out which specific properties of these phases you're interested in, and phrase your claims or arguments in terms of those.
3 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-08-29T21:47:00.786Z · LW(p) · GW(p)
As someone who has been advocating a lot recently for more emphasis on safety evaluations and testing generally, I here again feel compelled to say that you really ought to include a 'test' phase in-between training and deployment.
Testing
Parameters are fixed.
Failures are fine.
Model is sandboxed.
Fixed and/or dynamic testing distribution. Chosen specifically to be different in important ways from the training distribution.
Furthermore, I think that have sharp distinctions between each phase, and well-sandboxed train and test environments is of critical importance going forward. I think trying to get this to be the case is going to take some work from AI governance and safety-advocate folks. I absolutely don't think we should quietly surrender this point.
Replies from: ejenner↑ comment by Erik Jenner (ejenner) · 2022-08-30T05:50:04.671Z · LW(p) · GW(p)
I basically agree, ensuring that failures are fine during training would sure be great. (And I also agree that if we have a setting where failure is fine, we want to use that for a bunch of evaluation/red-teaming/...). As two caveats, there are definitely limits to how powerful an AI system you can sandbox IMO, and I'm not sure how feasible sandboxing even weak-ish models is from the governance side (WebGPT-style training just seems really useful).
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-08-30T16:55:46.353Z · LW(p) · GW(p)
Yes, I agree that actually getting companies to consistently use the sandboxing is the hardest piece of the puzzle. I think there's some promising advancements making it easier to have the benefits of not-sandboxing despite being in a sandbox. For instance: Using a snapshot of the entire web, hosted on an isolated network https://ai.facebook.com/blog/introducing-sphere-meta-ais-web-scale-corpus-for-better-knowledge-intensive-nlp/
I think this takes away a lot of the disadvantages, especially if you combine this with some amount of simulation of backends to give interactability (not an intractably hard task, but would take some funding and development time).