Incidental polysemanticity
post by Victor Lecomte (victor-lecomte), Kushal Thaman (Kushal_Thaman), tmychow, Rylan Schaeffer · 2023-11-15T04:00:00.000Z · LW · GW · 7 commentsContents
Summary Intuition Outline Setup Model Possible solutions Loss and dynamics The winning neuron takes it all Sparsity force How fast does it sparsify? Numerical simulations Interference arbiters collisions between features How strong is the interference? Benign and malign collisions Experiments Discussion and future work Implications for mechanistic interpretability A more realistic toy model Gaps in the theory Author contributions None 7 comments
This is a preliminary research report; we are still building on initial work and would appreciate any feedback.
Summary
Polysemantic neurons (neurons that activate for a set of unrelated features) have been seen as a significant obstacle towards interpretability of task-optimized deep networks,[1] with implications for AI safety.
The classic origin story of polysemanticity is that the data contains more "features" than there are neurons, such that learning to solve a task forces the network to allocate multiple unrelated features to the same neuron, threatening our ability to understand the network's internal processing.
In this work, we present a second and non-mutually exclusive origin story of polysemanticity. We show that polysemanticity can arise incidentally, even when there are ample neurons to represent all features in the data, using a combination of theory and experiments. This second type of polysemanticity occurs because random initialization can, by chance alone, initially assign multiple features to the same neuron, and the training dynamics then strengthen such overlap. Due to its origin, we term this incidental polysemanticity.
Intuition
The reason why neural networks can learn anything despite starting out with completely random weights is that, just by random chance, some neurons will happen to be very slightly correlated[2] with some useful feature, and this correlation gets amplified by gradient descent until the feature is accurately represented. If in addition to this there is some incentive for activations to be sparse, then the feature will tend to be represented by a single neuron as opposed to a linear combination of neurons: this is a winner-take-all dynamic.[3] When a winner-take-all dynamic is present, then by default, the neuron that is initially most correlated with the feature will be the neuron that wins out and represents the feature when training completes.
Therefore, if at the start of training, one neuron happens to be the most correlated neuron with two unrelated features (say dogs and airplanes), then this might[4] continue being the case throughout the learning process, and that neuron will ultimately end up taking full responsibility for representing both features. We call this phenomenon incidental polysemanticity. Here "incidental" refers to the fact that this phenomenon is contingent on the random initializations of the weights and the dynamics of training, rather than being necessary in order to achieve low loss (and in fact, in some circumstances, incidental polysemanticity might cause the neural network to get stuck in a local optimum).
How often should we expect this to happen? Suppose that we have useful features to represent and neurons to represent them with (so that it is technically possible for each feature to be represented by a different neuron). By symmetry, the probability that the and feature "collide", in the sense of being initially most correlated with the same neuron, is exactly . And there are pairs of features, so on average we should expect collisions[5] overall. In particular, this means that
- if (i.e. the number of neurons is at most a constant factor bigger than the number of features), then collisions will happen: a constant fraction of all neurons will be polysemantic;
- as long as is significantly smaller than , we should expect several collisions to happen.
Our experiments in a toy model show that this is precisely what happens, and a constant fraction of these collisions result in polysemantic neurons, despite the fact that there would be enough neurons to avoid polysemanticity entirely.
Outline
In the rest of this post, we
- set up a toy model for incidental polysemanticity;
- study its winner-take-all dynamic in detail;
- explore what happens over training when features collide, and confirm experimentally that we get as many polysemantic neurons as we expect;
- discuss implications for mechanistic interpretability as well as the limitations of this work, and suggest interesting future work.
Setup
Model
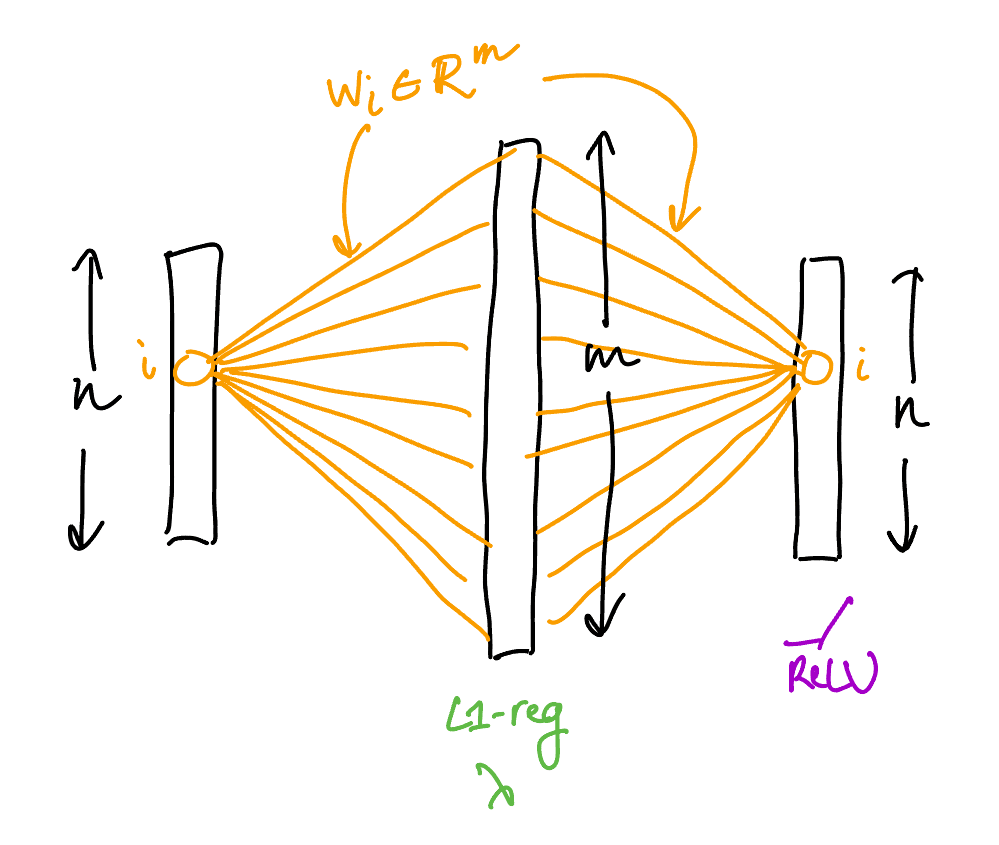
We consider a model similar to the ReLU-output model in Toy Models of Superposition. It is an autoencoder with features (inputs/outputs) which
- has weight tying between the encoder and the decoder (let be those weights),
- uses a single hidden layer of size with regularization of parameter on the activations,
- has a ReLU on the output layer,
- has no biases anywhere,
- is trained with the standard basis vectors as data (so that the "features" are just individual input coordinates): that is, the input/output data pairs are for , where is the basis vector.
The output is computed as :
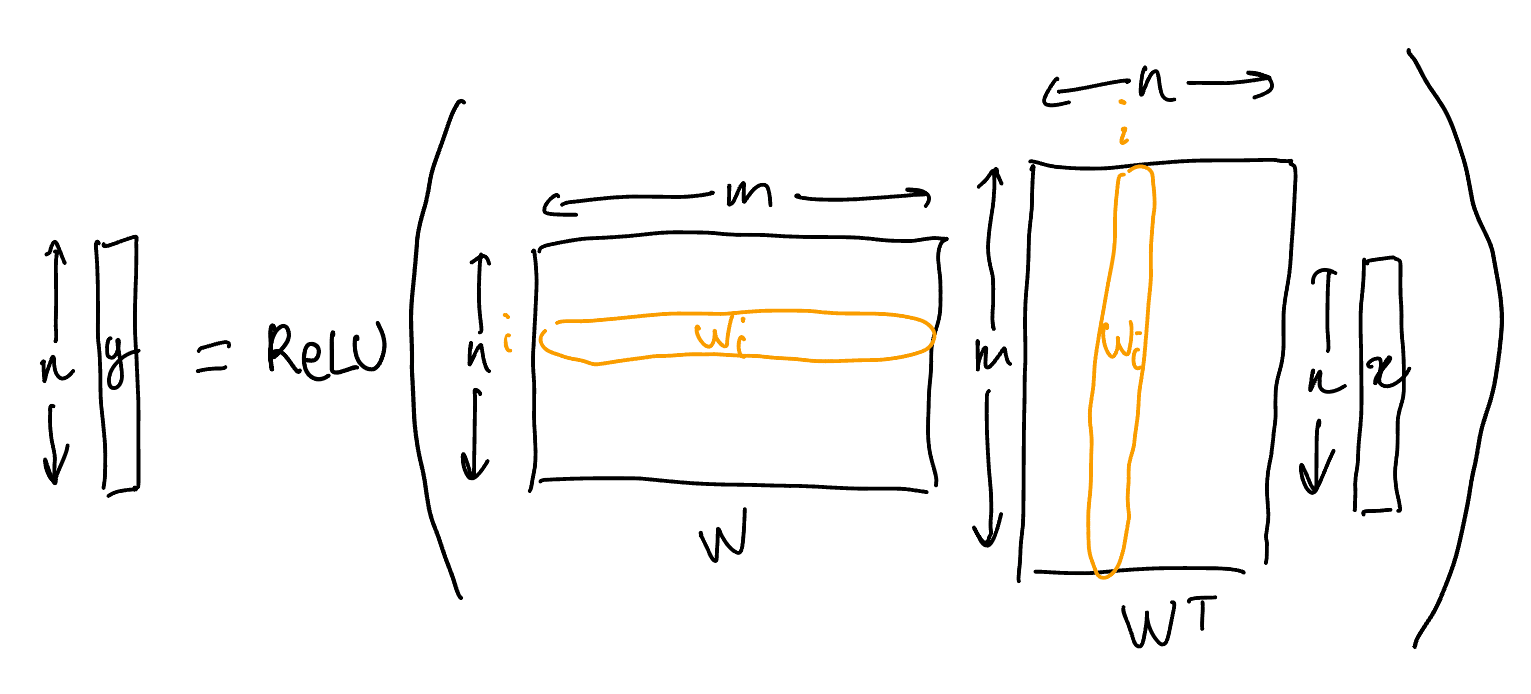
The main difference compared to the model from Toy Models of Superposition is the regularization. The role of the regularization is to push for sparsity in the activations and therefore induce a winner-take-all dynamic. We picked this model because it makes incidental polysemanticity particularly easy to demonstrate and study, but we do think the story it tells is representative (see the "Discussion and future work" section for more on this).
We make the following assumptions on parameter values:
| Assumption | Reason |
|---|---|
| the weights are initialized to i.i.d. normals of mean and standard deviation | so that the encodings start out with constant length |
| just to make it clear that polysemanticity was not necessary in this case | |
| so that the regularization doesn't kill all weights immediately |
Possible solutions
Let be the row of . It tells us how the feature is encoded in the hidden layer. When the input is , the output of the model can then be written as so for this to be equal to we need [6] and for .
Letting denote the basis vector in . There are both monosemantic and polysemantic solutions that satisfy these conditions:
- One solution is to simply let : the hidden neuron represents the feature, and there is no polysemanticity.
- But we could also have solutions where two features share the same neuron, with opposite signs. For example, for each , we could let and . This satisfies the conditions because .
- In general, we can have a mixture of these where each neuron represents either , or features, in an arbitrary order.
Loss and dynamics
Let us consider total squared error loss, which can be decomposed as The training dynamics are where is the training time, which you can roughly think of as the number of training steps. For simplicity, we'll ignore the constants going forward.[7]
It can be decomposed into three intuitive "forces" acting on the encodings :
- "feature benefit": encodings want to have unit length;
- "interference": different encodings avoid pointing in similar directions;
- "regularization": encodings want to have small -norm (which pushes all nonzero weights towards zero with equal strength).
The winning neuron takes it all
See our working notes (in particular, Feature benefit vs regularization) for a more formal treatment.
Sparsity force
For a moment, let's ignore the interference force, and figure out how (and how fast) regularization will push towards sparsity in some encoding . Since we're only looking at feature benefit and regularization, the other encodings have no influence at all on what happens in .
Assuming , each weight is
- pushed up with strength by the feature benefit force;
- pushed down with strength by the regularization.
Crucially, the upwards push is relative to how large is, while the downwards push is absolute. This means that weights whose absolute value is above some threshold will grow, while those below the threshold will shrink, creating a "rich get richer and poor get poorer" dynamic that will push for sparsity. This threshold is given by so we have
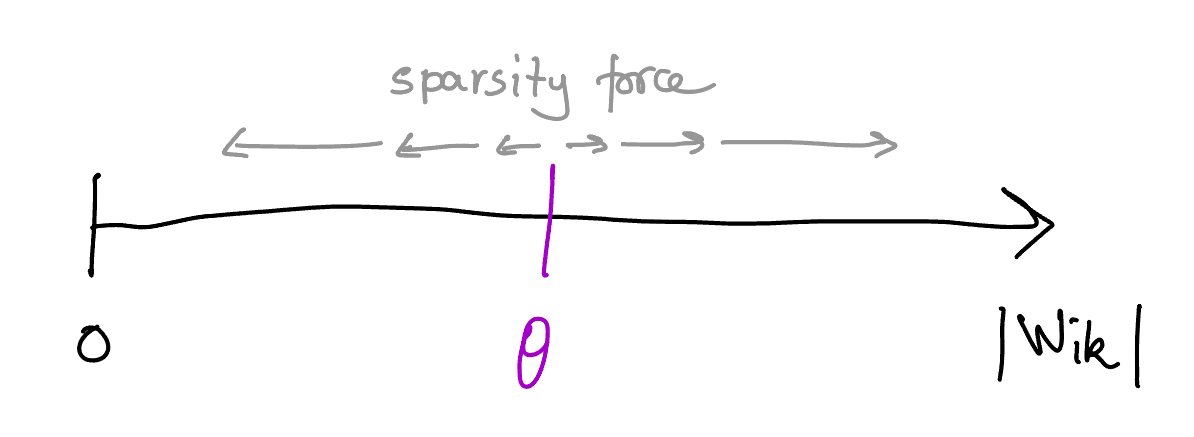
We call this combination of feature benefit and regularization force the sparsity force. It uniformly stretches the gaps between (the absolute values of) different nonzero weights.
Note that the threshold is not fixed: we will see that as gets sparser, will get closer to , which increases the threshold and allows it to get rid of larger and larger entries, until only one is left. But how fast will this go?
How fast does it sparsify?
The next two subsections are not critical for understanding the overall message; feel free to skip directly to the section titled "Interference arbiters collisions between features" if you're happy with just accepting the fact that will progressively sparsify over some predictable length of training time.
In order to track how fast sparsifies, we will look at its norm as a proxy for how many nonzero coordinates are left. Indeed, we will have throughout, so if has nonzero values at any point in time, their typical value will be , which means .
Since the sparsity force is proportional to , we need to get a sense of what values will take over time. As it turns out, changes relatively slowly, so we can get useful information by assuming the derivative is : which means Plugging this back into and using reasonable assumptions about the initial distribution of (see our working notes for details), we can prove that will decrease as with training time : Correspondingly, if we approximate the number of nonzero cooordinates as , it will start out at , decrease as , then reach at training time .
Numerical simulations
We compared our theoretical predictions for and (if the constants hidden in are assumed to be ) to their actual values over training time when the interference force is turned off. The specific values of parameters are and , and the standard deviation of the 's was .
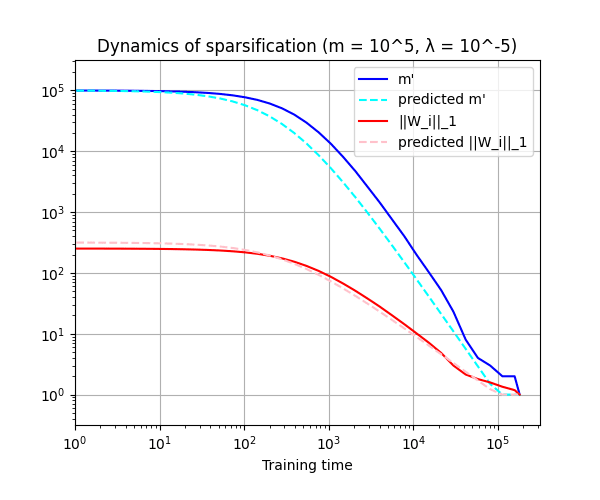
Code is available here.
Interference arbiters collisions between features
What happens when you bring the interference force into this picture? In this section, we argue informally that the interference is initially weak if , and only becomes significant later on in training, in cases where two of the encodings and have a coordinate such that and are both large and have the same sign—when that's the case, the larger of the two wins out.
How strong is the interference?
First, observe that in the expression for the interference force on each contributes only if the angle it forms with is less than . So the force will mostly be in the same direction as , but opposite. That means that we can get a good grasp on its strength by measuring its component in the direction of , which we can do by taking an inner product with .
We have Initially, each encoding is a vector of i.i.d. normals of mean and standard deviation , so the distribution of the inner products is symmetric around and also has standard deviation . This means that has mean , and thus the sum has mean . As long as , this is dominated by the feature benefit force: indeed, the same computation for the feature benefit gives as long as .
Moreover, over time, the positive inner products will tend to decrease exponentially. This is because the interference force on includes the term and the interference force on includes the term . Together, they affect as as long as , which is definitely the case at the start and will continue to hold true throughout training.
Benign and malign collisions
On the other hand, the interference between two encodings and starts to matter significantly when it affects one coordinate much more strongly than the others (rather than affecting all coordinates proportionally, like the feature benefit force does). This is the case when and share only one nonzero coordinate: a single such that . Indeed, when that's the case, the interference force
- only affects the coordinates of that are nonzero in ,
- and will probably not be strong enough counter the -regularization and revive coordinates of that are currently zero,
so only can be affected by this force.
When this happens, there are two cases:
- If and have opposite signs, we have , so nothing actually happens, since the ReLU clips this to . Let's call this a benign collision.
- If and have the same sign, we have , and both weights will be under pressure to shrink, with strength and respectively. Depending on their relative size, one or both of them will quickly drop to , thus putting the neuron out of the running in terms of representing the corresponding features. Let's call this a malign collision.
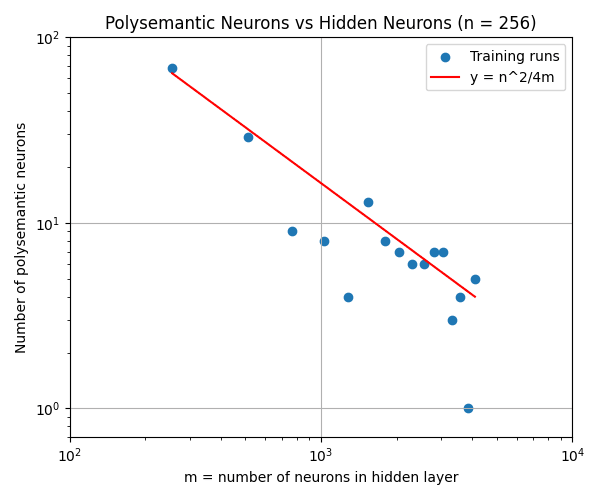
Polysemanticity will happen when the largest[8] coordinates in encodings and get into a benign collision. This happens with probability so we should expect roughly polysemantic neurons by the end.
Experiments
Training the model we described on and ranging from to shows that this trend of does hold, and the constant seems to be fairly accurate as well.
Discussion and future work
Implications for mechanistic interpretability
The fact that there are two completely different ways for polysemanticity to occur could have important consequences on how to deal with it.
To our knowledge, polysemanticity has mostly been studied in settings where the encoding space has no privileged basis: the space can be arbitrarily rotated without changing the dynamics, and in particular the corresponding layer doesn't have non-linearities or any regularization other than . In this setting, the features can be represented arbitrarily in the encoding space, and we usually observe interference (non-orthogonal encodings) only when there are more features than dimensions.
On the other hand, the incidental polysemanticity we have demonstrated here is inherently tied to the canonical basis, contingent on the random initialization and dynamics, and happens even when there are significantly more dimensions available than features.
This means that some tools that work against one type of polysemanticity might not work against the other. For example:
- Tools that make assumptions about the linear structure of the encodings might not work as well when non-linearities are present.
- A costly but technically feasible way to get rid of superposition when there is no privileged basis is to just increase the number of neurons so that it matches the number of features. It is much less realistic to do away with incidental polysemanticity in this way, since we saw that it can happen until the number of neurons is roughly equal to the number of features squared.
- On the other hand, since incidental polysemanticity is contingent on the random initializations and the dynamics of training, it could be solved by nudging the trajectory of learning in various ways, without necessarily changing anything about the neural architecture.
- As an example, here is one possible way one might get rid of incidental polysemanticity in a neuron that currently represents two features and . Duplicate that neuron, divide its outgoing weights by (so that this doesn't affect downstream layers), add a small amount of noise to the incoming weights of each copy, then run gradient descent for a few more steps. One might hope that this will cause the copies to diverge away from each other, with one of the copies eventually taking full ownership of feature while the other copy takes full ownership of feature .
In addition, it would be interesting to find ways to distinguish incidental polysemanticity from necessary polysemanticity.
- Can we distinguish them based only on the final, trained state of the model, or do we need to know more about what happened during training?
- Is "most" of the polysemanticity in real-world neural networks necessary or incidental? How does this depend on the architecture and the data?
A more realistic toy model
The setup we studied is simplistic in several ways. Some of these ways are without loss of (much) generality, such as the fact that encoding and decoding matrices are tied together,[9] or the fact that the input features are basis vectors.[10]
But there are also some choices that we made for simplicity which might be more significant, and which it would be nice to investigate. In particular:
- We introduced a winner-takes-all dynamic using regularization. This made the study of sparsification quite nice, but regularization is not very commonly used, and is not the main cause of privileged bases in modern neural networks. It would be interesting to study winner-takes-all dynamics that occur for different reasons (such as nonlinear activation functions or layer normalization) and see if the dynamics of sparsification are similar.
- In our setup, polysemanticity is benign because one feature can be represented with a positive activation and the other one with a negative activation, and this is disambiguated by the ReLU in the output layer. Polysemanticity can be benign for other reasons: for example, it could be that two features never occur in the same context and that the context can be used to disambiguate between them. We give a possible toy model for this scenario in a working note.
Gaps in the theory
We were able to give strong theoretical guarantees for the sparsification process by considering how the feature benefit force and regularization interact when interference is ignored, but we haven't yet been able to make confident theoretical claims about how the three forces interact together.
In particular:
- It would be nice to theoretically predict the likelihood that the largest coordinate in remains largest throughout training. This would require a better understanding of exactly how impactful malign collisions are when one of the weights involved is significantly larger than the other, and how much this affects the race between the largest weights in an encoding.
- Perhaps an interesting case to study is the limit (very slow regularization). This would make the interference work much faster than the regularization, and from the perspective of studying sparsification, this could allow us to assume that the inner products are nonpositive throughout training.
Author contributions
- Ideation: Victor initially proposed the project, and it took shape in discussions with Rylan.
- Experiments: Kushal and Trevor ran the experiments which confirmed that incidental polysemanticity occurs and measured the number of polysemantic neurons. They were mentored by Victor and Rylan.
- Theory: Victor drove the theory work and implemented the numerical simulations of sparsification, with significant help from Kushal.
- Writing: This post was primarily written by Victor, with feedback from Kushal and Rylan.
see e.g. the "Polysemantic Neurons" section in Zoom In: An Introduction to Circuits ↩︎
When we say a neuron is correlated with a feature, what we more formally mean is that the neuron's activation is correlated with whether the feature is present in the input (where the correlation is taken over the data points). But the former is easier to say. ↩︎
Analogous phenomena are known under other names, such as "privileged basis". ↩︎
depending mostly on the specifics of the neural architecture and the data (but also on the random initializations of the weights) ↩︎
Here, we define a "collision" as the event that two features and collide. So for example there is a three-way collision between , and , that would count as three collisions between and , and , and and . ↩︎
We use to denote Euclidean length ( norm), and to denote Manhattan length ( norm). ↩︎
It's equivalent to making four times larger and making training time four times slower. ↩︎
This would not necessarily be the largest weight at initialization, since there might be significant collisions with other encodings, but the largest weight at initialization is still the most likely to win the race all things considered. ↩︎
We're referring to the fact that the encoding matrix is forced to be the transpose of the decoding matrix . This assumption makes sense because even if they were kept independent and initialized to different values, they would naturally acquire similar values over time because of the learning dynamics. Indeed, the column of the encoding matrix and the row of the decoding matrix "reinforce each other" through the feature benefit force until they have an inner product of , and ao as long as they start out small or if there is some weight decay, they would end up almost identical by the end of training. ↩︎
If the input features are not the canonical basis vectors but are still orthogonal (and the outputs are still basis vectors), then we could apply a fixed linear transformation to the encoding matrix and recover the same training dynamics. And in general it makes sense to consider orthogonal input features, because when the features themselves are not orthogonal (or at least approximately orthogonal), the question of what polysemanticity even is becomes more murky. ↩︎
7 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2023-12-03T13:19:09.691Z · LW(p) · GW(p)
My guess is that this result is very sensitive to the design of the training dataset:
the input/output data pairs are for , where is the basis vector.
In particular, I think it is likely very sensitive to the implicit assumption that feature i and feature j never co-occur on a single input. I'd be interested to see experiments where each feature is turned on with some (not too small) probability, independently of all other features, similarly to the original toy models setting. This would result in some inputs where feature i and j are on simultaneously. My prediction would be that polysemanticity goes down very significantly (probably to zero if the probabilities are high enough and the training is done for long enough).
I also don't understand why L1 regularization on activations is necessary to show incidental polysemanticity given your setup. Even if you remove the L1 regularization on activations, it is still the case that "benign collisions" impose no cost on the model, since feature i and feature j are never simultaneously present in a given input. So if you do get a benign collision, what causes it to go away? Overall my expectation would be that without the L1 regularization on activations (and with the training dataset as described in this post), you'd get a complicated mess where every neuron is highly polysemantic, i.e. even more polysemanticity than described in this post. Why is that wrong?
Replies from: victor-lecomte↑ comment by Victor Lecomte (victor-lecomte) · 2023-12-07T19:51:48.765Z · LW(p) · GW(p)
Thanks for the feedback!
In particular, I think it is likely very sensitive to the implicit assumption that feature i and feature j never co-occur on a single input.
Definitely! I still think that this assumption is fairly realistic because in practice, most pairs of unrelated features would co-occur only very rarely, and I expect the winner-take-all dynamic to dominate most of the time. But I agree that it would be nice to quantify this and test it out.
Overall my expectation would be that without the L1 regularization on activations (and with the training dataset as described in this post), you'd get a complicated mess where every neuron is highly polysemantic, i.e. even more polysemanticity than described in this post. Why is that wrong?
If there is no L1 regularization on activations, then every hidden neuron would indeed be highly "polysemantic" in the sense that it has nonzero weights for each input feature. But on the other hand, the whole encoding space would become rotationally symmetric, and when that's the case it feels like polysemanticity shouldn't be about individual neurons (since the canonical basis is not special anymore) and instead about the angles that different encodings form. In particular, as long as mgen, the space of optimal solutions for this setup requires the encodings to form angles of at least 90° with each other, and it's unclear whether we should call this polysemantic.
So one of the reasons why we need L1 regularization is to break the rotational symmetry and create a privileged basis: that way, it's actually meaningful to ask whether a particular hidden neuron is representing more than one feature.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2023-12-08T08:06:27.349Z · LW(p) · GW(p)
Good point on the rotational symmetry, that makes sense now.
I still think that this assumption is fairly realistic because in practice, most pairs of unrelated features would co-occur only very rarely, and I expect the winner-take-all dynamic to dominate most of the time. But I agree that it would be nice to quantify this and test it out.
Agreed that's a plausible hypothesis. I mostly wish that in this toy model you had a hyperparameter for the frequency of co-occurrence of features, and identified how it affects the rate of incidental polysemanticity.
comment by Pavan Katta (pavan-katta) · 2023-12-12T06:12:25.606Z · LW(p) · GW(p)
Great work! Love the push for intuitions especially in the working notes.
My understanding of superposition hypothesis from TMS paper has been(feel free to correct me!):
- When there's no privileged basis polysemanticity is the default as there's no reason to expect interpretable neurons.
- When there's a privileged basis either because of non linearity on the hidden layer or L1 regularisation, default is monosemanticity and superposition pushes towards polysemanticity when there's enough sparsity.
Is it possible that the features here are not enough basis aligned and is closer to case 1? As you already commented demonstrating polysemanticity when the hidden layer has a non linearity and m>n would be principled imo.
Replies from: victor-lecomte↑ comment by Victor Lecomte (victor-lecomte) · 2023-12-17T09:59:02.454Z · LW(p) · GW(p)
Sorry for the late answer! I agree with your assessment of the TMS paper. In our case, the L1 regularization is strong enough that the encodings do completely align with the canonical basis: in the experiments that gave the "Polysemantic neurons vs hidden neurons" graph, we observe that all weights are either 0 or close to 1 or -1. And I think that all solutions which minimize the loss (with L1-regularization included) align with the canonical basis.
comment by Clément Dumas (butanium) · 2023-11-15T13:54:57.447Z · LW(p) · GW(p)
Small typo in ## Interference arbiters collisions between features
Replies from: victor-lecomteby taking aninner productt with .
↑ comment by Victor Lecomte (victor-lecomte) · 2023-11-15T16:52:09.860Z · LW(p) · GW(p)
Thank you, it's fixed now!