Biomimetic alignment: Alignment between animal genes and animal brains as a model for alignment between humans and AI systems
post by geoffreymiller · 2023-06-08T16:05:55.832Z · LW · GW · 1 commentsContents
Introduction Animal brains as superintelligences compared to animal genes What do genes really ‘want’? Revealed preferences and adaptations A Cambrian Story Evolutionary reinforcement learning Some AI alignment lessons from gene/brain evolution Conclusion None 1 comment
(Note: this was also published on EA Forum, May 26, 2023, here [EA · GW]; this is a somewhat rough-and-ready essay, which I'll expand and deepen later; I'm welcome any comments, reactions, and constructive criticism.)
Overview: To clarify how we might align AI systems with humans, it might be helpful to consider how natural selection has aligned animals brains with animals genes, over the last 540 million years of neural evolution.
Introduction
When we face an apparently impossible engineering challenge – such as AI alignment – it’s often useful to check if Nature has already solved it somehow. The field of biomimetic design seeks engineering inspiration from the evolved adaptations in plants or animals that have already work pretty well to solve particular problems.
Biomimetic design has already proven useful in AI capabilities research. Artificial neural networks were inspired by natural neural networks. Convolutional neural networks were inspired by the connectivity patterns in the visual cortex. Reinforcement learning algorithms were inspired by operant conditioning and reinforcement learning principles in animals. My own research in the early 1990s on evolving neural network architectures using genetic algorithms was directly inspired by the evolution of animal nervous systems (see this, this, and this.)
If biomimetic insights have helped with AI capabilities research, could biomimetic insights also help with AI safety research? Is there something like a biological analogy of the AI alignment problem that evolution has already solved somehow? Could such an analogy help keep us from going extinct in the next several decades?
Animal brains as superintelligences compared to animal genes
In this post I’ll develop the argument that there is evolutionary analogy to the alignment problem that might help guide future AI safety research – or that might caution us that AI alignment is even harder than we realized. This analogy concerns the way that self-replicating DNA (genes, genotypes) has to get evolved sensory-neural-motor systems (animal brains) aligned with the evolutionary goal of maximizing the DNA’s reproductive success.
The key analogy here is that the genes inside animals are to the animal brains that they build as modern humans will be to the superintelligent AI systems that we might build.
The DNA in an animal ‘wants’ the animal’s nervous system to implement the ‘terminal value’ of replicating the DNA, just as modern humans ‘want’ AI systems to implement our values. Yet the DNA is extremely stupid, slow, perceptually unaware, and behaviorally limited compared to the animal’s nervous system, just as modern humans will be extremely stupid, slow, perceptually unaware, and behaviorally limited compared to superintelligent AI systems.
The alignment problems are roughly analogous, and have similarly high stakes. If an animal nervous system doesn’t effectively implement the goal of replicating the animal’s DNA through surviving and reproducing, both its DNA and its nervous system will go extinct. Likewise, if a superintelligent AI system doesn’t effectively implement human goals of promoting our survival and reproduction, humans could go extinct. Further, unless the AIs have been able to set up a self-replicating, self-sustaining, self-repairing industrial/computational ecosystem that can survive for many millennia independent of all human support, guidance, and oversight, the AI systems will eventually go extinct too.
What do genes really ‘want’? Revealed preferences and adaptations
Of course, DNA doesn’t really ‘want’ anything in the way that humans say they ‘want’ things. But evolutionary biologists for decades have made great progress in understanding animal behavior by flagrantly anthropomorphizing DNA and modeling it as if it wants things. This scientific strategy goes back to the gene-centered revolution in 1960s and 1970s evolutionary biology, including William Hamilton’s 1964 analysis of inclusive fitness, Robert Trivers’ early-1970s analyses of sexual selection, parental investment, and reciprocal altruism, E. O. Wilson’s 1975 Sociobiology textbook, and Richards Dawkins’ 1976 book The Selfish Gene.
The gene’s-eye perspective became the foundation of modern evolutionary theory, including optimal foraging theory, evolutionary game theory, multi-level selection theory, host-parasite co-evolution theory, sexual selection theory, parent-offspring conflict theory, and gene-cultural coevolution theory. These ideas also became the foundation of modern animal behavior research, including behavioral ecology, neuroethology, primatology, and evolutionary anthropology. Finally, the gene’s-eye perspective became the conceptual foundation of my field, evolutionary psychology, including extensive analyses of human cognition, motivation, development, learning, emotions, preferences, values, and cultures.
The modern evolutionary biology understanding of genes, adaptations, and evolutionary fitness is weirdly counter-intuitive – maybe just as weirdly counter-intuitive as the AI alignment problem itself. Everybody thinks they understand evolution. But most don’t. I’ve taught college evolution courses since 1990, and most students come to class with a highly predictable set of misunderstandings, confusions, errors, and fallacies. Almost none of them start out with any ability to coherently explain how evolutionary selection shapes behavioral adaptations to promote animal fitness.
One typical confusion centers around whether genes have any ‘interests’, ‘values’, or ‘motivations’. Are we just shamelessly anthropomorphizing little strands of DNA when we talk about the gene’s-eye perspective, or genes being ‘selfish’ and ‘trying to replicate themselves’?
Well, genes obviously don’t have verbally articulated ‘stated preferences’ in the way that humans do. Genes can’t talk. And they don’t have internal emotions, preferences, or motivations like animals with brains do, so they couldn’t express individual interests even if they had language.
However, genes can be treated as showing ‘revealed preferences’. They evolve a lot of error-correction machinery to reduce their mutation rate, usually as low as they can (the ‘evolutionary reduction principle’), so they apparently prefer not to mutate. They evolve a lot of adaptations to recombine with the best other genes they can (through ‘good genes mate choice’), so they apparently prefer to maximize genetic quality in offspring. They evolve a lot of anti-predator defenses, anti-pathogen immune systems, and anti-competitor aggression, so they apparently prefer to live in bodies that last as long as feasible. They evolve a lot of anti-cancer defenses, so they apparently prefer sustainable long-term self-replication through new bodies (offspring) over short-term runaway cell proliferation within the same body. In fact, every evolved adaptation can be viewed as one type of ‘revealed preference’ by genes, and for genes.
A Cambrian Story
Imagine your dilemma if you’re an innocent young genotype when the Cambrian explosion happens, about 540 million years ago. Suddenly there are new options for evolving formidable new distance senses like vision and hearing, for evolving heads with central nervous systems containing hundreds of thousands of neurons (‘cephalization’), and for evolving complex new movement patterns and behaviors.
You could evolve a new-fangled brain that trains itself to do new things, based on ‘reward signals’ that assess how well you’re doing at the game of life. But these reward signals don’t come from the environment. They’re just your brain’s best guess at what might be useful to optimize, based on environmental cues of success or failure.
What counts as success or failure? You have no idea. You have to make guesses about what counts as ‘reward’ or ‘punishment’, by wiring up your perceptual systems in a way that assigns a valence (positive or negative) to each situation that seems like it might be important to survival or reproduction. You might make a guess that swimming towards a bigger animal with sharp teeth should be counted as a ‘reward’, and then your reinforcement learning system will get better and better at doing that… until you get eaten, and your genes die out. Or you might make a guess that swimming towards from an organism with visible traits X, Y, and Z should be counted as a ‘punishment’, and then your reinforcement learning system will make you better and better at avoiding such organisms…. But unfortunately, traits X, Y, and Z happen to specify fertile opposite-sex members of your own species, so you never mate, and your genes die out.

Example Cambrian animal: Opabinia regalis, c. 505 million years ago, 7 cm long, living on the seafloor, fossilized in the Burgess Shale
Whatever your reward system happens to treat as a reward is what you’ll get better at pursuing; whatever your reward system happens to treat as a punishment is what you’ll get better at avoiding. From your gene’s-eye perspective, your brain – should you choose to evolve it – will be a high-risk gamble on a new form of superintelligence that could lead you to get better and better at doing disastrous things. How will you create alignment between what your brain thinks should be rewarding (so you can learn to do those things better), and what your genes would actually want you to do (i.e. what evolution is actually selecting for)?
This is the gene/brain alignment problem. Failures of gene/brain alignment must have meant the death of trillions of innocent Cambrian organisms who had no idea what they were doing. We are descended from organisms that happened to solve the gene/brain alignment problem pretty well – at least better than their rivals -- in every generation, life after life, century after century, for more than 500 million years.
Evolutionary reinforcement learning
The gene/brain alignment problem was nicely illustrated by the classic 1991 paper on evolutionary reinforcement learning by David Ackley and Michael Littman. They used a genetic algorithm to evolve neural networks that guide the behavior of simulated autonomous creatures with limited visual inputs, in a simple virtual world with simulated carnivores, food, and obstacles. The creatures’ neural networks had two components: an ‘action network’ that maps from sensory input cues to output behaviors, and an ‘evaluation network’ that maps from sensory input cues to an evaluation metric that guides reinforcement back-propagation learning. Simulated genes specify the initial weights in the action network and the fixed weights in the evaluation network. (See Figure 1 below from Ackley & Littman, 1991).
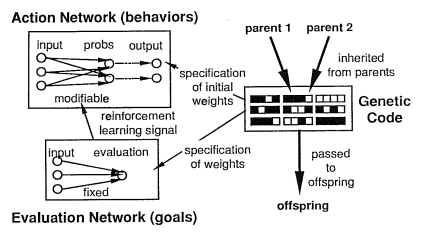
The crucial point with evolutionary reinforcement learning is that the environment does NOT specify reward signals as such. The environment is just the environment. Stuff happens in the environment. (Simulated) carnivores chase the agents and eat many of them. (Simulated) food nourishes them, if they can find it. Obstacles get in the way. The creatures have to evolve evaluation networks that accurately identify fitness threats (such as carnivores and obstacles) as things worth avoiding, and fitness opportunities (such as food and mates) as things worth pursuing. If their evaluation network is bad (misaligned to their genetic interests), then the creatures learn to get better and better at doing stupid, suicidal things that feel rewarding to them when they’re doing them, like running straight towards carnivores, avoiding all food and mates, and bashing into obstacles.
In the first generations, of course, all the creatures have terrible evaluation networks that reward mostly stupid things. It takes many generations of selection to evolve better evaluation networks – but once those are giving better-aligned information about what’s good and what’s bad, the reinforcement learning makes the creatures very good at doing the good things very quickly.
Evolutionary reinforcement learning captures the key challenge in gene/brain alignment: how to evolve the reward circuitry that specifies what counts as success, and what counts as failure. Once the reward circuitry has evolved, reinforcement learning can (relatively) easily shape adaptive behaviors. In humans, of course, the reward circuitry takes the form of many different motivations, emotions, preferences, and values that are relatively innate, instinctive, or hardwired.
The deepest problem in gene/brain alignment is that the only thing shaping the reward circuitry is evolution itself. Nothing inside the orgasm can figure out from first principles what counts as success or failure, reward or punishment, fitness-promoting or fitness-reducing behavior. Nature just has to try out different reward circuits, and see what works. The outer loop is that evolution selects the reward circuits that happen to work; the inner loop is that the reward circuits guide the organism to learn more adaptive behavior. (There’s probably some analogy here to ‘inner alignment’ versus ‘our alignment’ in the AI safety literature, but I find these two terms so vague, confusing, and poorly defined that I can’t see which of them corresponds to what, exactly, in my gene/brain alignment analogy; any guidance on that would be appreciated.)
So, how does Nature really solve the gene/brain alignment problem? It solves it through a colossal amount of failure, mayhem, wild-animal suffering, death, and extinction on a scale that beggars belief. 540 million years with quadrillions of animals in millions of species doing their best to learn how to survive and reproduce… but often failing, because they’re learning the wrong things based on unaligned reward signals.
Evolution, from this point of view, is a massively parallel system for trying out different reward circuits in animals. Those that work, last. Those that don’t work, die out. That’s it. The result, after literally quadrillions of misalignment failures, is that we see the animals of today mostly pursuing adaptive goals and avoiding maladaptive goals.
Some AI alignment lessons from gene/brain evolution
What have we learned from the last 60 years of evolutionary biology from a gene’s-eye perspective, even since William D. Hamilton discovered gene-centered kin selection in 1964? Here are some core lessons that might be relevant for AI alignment.
1. Evolution selects animals to maximize their inclusive reproductive fitness – but animals brains don’t evolve to do this directly, consciously, or as a ‘terminal value’ that drives minute-to-minute decision-making. The evolutionary imperative is to create more copies of genes in the next generation – whether by surviving and reproducing directly, or helping copies of one’s genes in close relatives (promoting ‘inclusive fitness’), or helping copies of one’s genes in more distant relatives within the same group or tribe (promoting ‘group fitness’ as modelled in multi-level selection theory – which is quite different from naïve group selection arguments). Any animal brains that aren’t aligned with the interests of the genes they carry tend to die out, and the behavioral strategies that they implement tend to go extinct. Thus, evolution is the final arbiter of what counts as ‘aligned with genes’. If this ‘gene/brain-alignment’ problem is solved, the animal’s brain typically works pretty well in the service of the animal’s genes.
However, gene/brain alignment requires a staggering amount of trial-and-error experimentation – and there are no shortcuts to getting adaptive reward functions. Errors at the individual level are often lethal. Errors at the population level (e.g. animals drifting off into having maladaptive mate preferences that undermine survival) often result in extinction. Almost all vertebrate species go extinction within a million years; only a tiny minority of species lead to new adaptive radiations of new species. So, looking backwards, we can credit evolution with being pretty good at optimizing reward functions and enforcing gene/brain alignment, among the species we see surviving today. However, prospectively, almost all gene/brain ‘alignment attempts’ by evolution result in catastrophic failures, leading brains to pursue rewards that aren’t aligned with their underlying genes. This lesson should make us very cautious about the prospects for AI alignment with humans.
2. Animals usually evolve very domain-specific adaptations to handle the daily business of surviving and reproducing. Most of these adaptations are morphological and physiological rather than cognitive, ranging in humans from about 200 different cell types to about 80 different organs. These are typically ‘narrow’ in function rather than ‘general’. There are 206 different bones in the human adult, rather than one all-purpose super-Bone. There are about a dozen types of immune system cells to defend the body against intruders (e.g. eosinophils, basophils, macrophages, dendritic cells, T cells, B cells), rather than one all-purpose super-Defender cell. (For more on this point, see my EA Forum post [EA · GW] on embodied values.)
It’s tempting to think of the human brain as one general-purpose cognitive organ, but evolutionary psychologists have found it much more fruitful to analyze brains as collections of distinct ‘psychological adaptations’ that serve different functions. Many of these psychological adaptations take the form of evolved motivations, emotions, preferences, values, adaptive biases, and fast-and-frugal heuristics, rather than general-purpose learning mechanisms or information-processing systems. As we’ll see later, the domain-specificity of motivations, emotions, and preferences may have been crucial in solving the gene/brain alignment problem, and in protecting animals against the misalignment dangers of running more general-purpose learning/cognition systems.
(Note that the existence of ‘general intelligence’ (aka IQ, aka the g factor) as a heritable, stable, individual-differences trait in humans, says nothing about whether the human mind has a highly domain-specific cognitive architecture. Even a highly heterogenous, complex, domain-specific cognitive architecture could give rise to an apparently domain-general ‘g factor’ if harmful mutations, environmental insults, and neurodevelopmental errors have pleiotropic (correlated) effects on multiple brain systems. My ‘pleiotropic mutation model’ of the g factor explores this in detail; see this, this, this, this, and this). Thus, the existence of ‘general intelligence’ as an individual-differences trait in humans does not mean that human intelligence is ‘domain-general’ in the sense that we expect ‘Artificial General Intelligence’ to be relatively domain-general.)
This domain-specific evolutionary psychology perspective on how to describe animal and human minds contrasts sharply with the type of Blank Slate models that are typical in some branches of AI alignment work, such as Shard theory. (See my EA Forum post [EA · GW] here for a critique of such Blank Slate models). These Blank Slate models tend to posit a kind of neo-Behaviorist view of learning, in which a few crude, simple reward functions guide the acquisition of all cognitive, emotional, and motivational content in the human mind.
If these Blank Slate models were correct, we might have a little more confidence that AI alignment could be solved by ‘a few weird tricks’ such as specifying some really clever, unitary reward function (e.g. utility function) that guides the AI’s learning and behavior. However, evolution rarely constructs such simple reward functions when solving gene/brain alignment. Instead, evolution tends to construct a lot of domain-specific reward circuitry in animal brains, e.g. different types of evaluation functions and learning principles for different domains such as foraging, mating, predator-avoidance, pathogen-avoidance, social competition, etc. And these domain-specific reward functions are often in conflict, as when gazelles experience tension between the desire to eat tender green shoots, and the desire not to be eaten by big fierce lions watching them eating the tender green shoots. These motivational conflicts aren’t typically resolved by some ‘master utility function’ that weighs up all relevant inputs, but simply by the relative strengths of different behavioral priorities (e.g. hunger vs. fear).
3. At the proximate level of how their perceptual, cognitive, and motor systems work, animal brains tend to work not as ‘fitness maximizers’ but as ‘adaptation executors’ [LW · GW]. A ‘fitness maximizer’ would explicitly represents the animal’s fitness (e.g. actual or expected reproductive success) as a sort of expected utility to be maximized in a centralized, general-purpose decision system. ‘Adaptation executors’ guide a limited set of adaptive behaviors based on integrating a limited set of relevant environmental cues. Examples would include relatively ‘hard-wired’ reflexes, emotions, food preferences, mate preferences, and parental motivations.
Why don’t animals evolve brains that can do general fitness maximization, rather than relying on domain-specific psychological adaptations ? One common (but, I think, flawed) argument is that animal brains are too computationally limited to implement any kind of general-purpose fitness-maximizing algorithm. Well, maybe. But typical animal brains seem to have plenty of computational horsepower to implement some fairly general-purpose optimization strategies – if that was really a good thing to do. Honeybees have about 1 million neurons, zebrafish have about 10 million, fruit bats have about 100 million, pigeons have about 300 million, octopuses have about 500 million, black vultures have about 1 billion, German shepherd dogs have about 4 billion, chimpanzees have about 28 billion, and humans have about 86 billion. And typically, for each neuron, there are about 1,000 synapses connecting to other neurons. It’s difficult to estimate the resulting computational power of animal brains. The best current estimates suggest the human brain is capable of about 1013–1017 FLOPS (floating-point operations per second). The fastest current supercomputer (the Cray/HPE Frontier; 2022:) runs at about 1018 FLOPS. When playing games, Alpha Zero seemed to use about 1014 FLOPS (this is a dubious estimate from random bloggers; please correct if you have a better one). Thus, animal brains aren’t enormously more powerful than current computers, but they’re in the same ballpark.
I have a different hypothesis about why animal brains don’t evolve to be ‘fitness maximizers’: because any general fitness/utility function that they tried to implement would (1) depend on proximate cues of future expect fitness that are way too unreliable and uninformative to guide effective learning, and would be (2) way too slow to develop and learn in ways that match the animal’s sensory and motor capabilities, (3) way too fragile to genetic noise (mutations) and environmental noise (uncertainty), (4) way too vulnerable to manipulation and exploitation by other animals, and (5) way too vulnerable to reward-hacking by the animal itself. Thus, fitness-maximizing brains would not actually guide adaptive behavior as well as a suite of more domain-specific instincts, motivations, emotions, and learning systems would do. (This point echoes the 1992 argument by Leda Cosmides and John Tooby that any general-purpose brain without a rich set of specific instincts can’t solve the ‘frame problem’).
For example, consider the problem of adaptive mate choice. Sexually reproducing animals need to find good mates to combine their genes with, to create the next generation. From a genes’-eye perspective, bad mate choice is an existential risk – it’s the road to oblivion. If an animal chooses the wrong species (e.g. chimp mating with gorilla), wrong sex (e.g. male mating with male), wrong age (e.g. adult mating with pre-pubescent juvenile), wrong fertility status (e.g. already pregnant), wrong phenotypic condition (e.g. starving, sick, injured), or wrong degree of relatedness (e.g. full sibling), then their genes will not recombine at all with the chosen mate, or they will recombine in a way that produces genetically inferior offspring, or offspring that won’t receive good parental care. Given the long delay between mating and offspring growing up (often weeks, months, or many years), it’s impossible for animals to learn their mate preferences based on feedback about eventual reproductive success. In fact, many invertebrate animals die before they ever see their offspring, so they can’t possibly use quantity or quality of offspring as cues of how well they’re doing in the game of life. Similarly, the selection pressures to avoid incest (mating with a close genetic relative) can track the fact that future generations will suffer lower fitness due to inbreeding (increased homozygosity of recessive mutations) – but most animals are in no position to perceive those effects using their own senses to guide their reinforcement learning systems. Yet, inbreeding avoidance evolves anyway, because evolution itself provides the ‘training signal’ that weeds out bad mate preferences. Generally, animals need some relatively in-built mate preferences to guide their mating decisions as soon as they reach sexual maturity, and there is no way to learn adaptive mate preferences within one lifetime, given the long-delayed effects of good or bad mate choices on the quality and quantity of offspring and grand-offspring. So, we’ve evolved a lot of quite specific mate choice instincts to avoid recombining our genes with bad genotypes and phenotypes.
Also, animal mate preferences and sexual behavior motivations need to be resistant to whatever kinds of reward-hacking are feasible, given the animals’ behavioral repertoire, social environment, and mating market. For example, if male animals used the domain-specific sexual heuristic of ‘maximize rate of ejaculation near females of my own species’, they could reward-hack by masturbating to orgasm without actually copulating with any fertile females (a type of ‘non-reproductive sexual behavior’). Male primates will sometime try to reward-hack other males’ mate preferences by submitting to male-male copulation, in order to defuse male-male competition and aggression. But presumably males evolve some degree of resistance against such socio-sexual manipulation.
4. ‘Instrumental convergence’ is common in evolution, not just in AI systems. Animals often act as if they’re maximizing the expected fitness of the genes they carry. They don’t do this by treating expected fitness as an expected utility that their brains are trying to maximize through means/end reasoning. However, animals do have a common set of instrumental proxies for fitness that are similar to instrumental goals analyzed by AI safety researchers. For example, animals across millions of species are motivated to avoid predators, avoid parasites, find food, find mates, care for offspring, and help kin. These core challenges of surviving and reproducing are so common that they appear as the organizing chapters in most animal behavior textbooks. Biologists who study predator avoidance in reptiles often have more in common with those who study predator avoidance in primates, than they do with those who study mate choice in reptiles, because the selection pressures and functional challenges of predator avoidance are often so similar across species. Much of biology research is structured around these instrumental life-goals, which show strong signs of convergent evolution across wildly different species with very different bodies and brains.
5. Gene/brain alignment in animals is often shaped not just by one-sided optimization to environmental challenges, but by co-evolutionary arms races with other individuals and species. This is roughly analogous to adversarial machine learning, except that in Nature, each individual and species is pursuing its own gene/brain strategies, rather than specifically trying to hack the reward function of any other particular individual. For example, fast-evolving parasites often discover ways to evade the anti-parasite defenses of slower-evolving hosts (e.g. mosquito saliva evolving to contain analgesics that make it harder to detect their bites); males often find ways to manipulate and deceive females during sexual courtship (e.g. offering fake ‘nuptial gifts’ that don’t actually include any nutrients); offspring often find ways to manipulate the parental care behaviors of their parents (e.g. begging more aggressively than their siblings). With each adversarial adaptations, counter-adaptations often evolve (e.g. more sensitive skin to detect insects, female skepticism about the contents of nuptial gifts, parental resistance to begging). To make progress on whether adversarial machine learning can actually help with AI alignment if might be helpful to explore what lessons can be learned from coevolutionary arms races in Nature.
Conclusion
Evolution has succeeded in generating quite a high degree of gene/brain alignment in millions of species over hundreds of millions of years. Animal nervous systems generally do a pretty good job of guiding animals to survive and reproduce in the service of their genetic interests.
However, there’s quite a lot of survivorship bias, in the sense that quadrillions of gene/brain ‘alignment failures’ have died out and gone extinct ever since the Cambrian explosion. The animals we see running around today, learning various impressively adaptive behaviors based on their well-calibrated reward functions, are the last alignment attempts left standing. Most of their would-be ancestors died out without any surviving offspring. I think this should lead us to be very cautious about the prospects for getting human/AI alignment right the first few times we try. We do not have the luxury of quadrillions of failures before we get it right.
Also, the domain-specificity of animals’ cognitive, motivational, and behavioral adaptations should make us skeptical about developing any simple ‘master utility functions’ that can achieve good alignment. If master utility functions were good ways to solve alignment, animals might have evolved relatively Blank Slate brains with very crude, simple reinforcement learning systems to align their behavior with their genes (as posited, incorrectly, by Shard Theory [LW · GW]). Instead, animals typically evolve a wide variety of senses, perceptual systems, object-level categories, cognitive systems, preferences, motivations, emotions, and behavioral strategies – and many of these are stimulus-specific, content-specific, or domain-specific. When we’re thinking about human/AI alignment, I think we should break the problem down into more domain-specific chunks, rather than trying to solve it all at once with some unitary ‘technical alignment solution’. The following are qualitatively different kinds of problems that probably require different alignment solutions: alignment to protect the AI against human-harming cyber-attacks (analogous to anti-pathogen defenses in animals), alignment to ‘play nice’ in sharing energy and computational resources with humans (analogous to food-sharing adaptations in social primates), and alignment for a domestic robot to be a good care-taker of human children (analogous to alloparenting in human clans).
In summary, from our perspective as humans looking back on the evolutionary history of life on Earth, it might look easy for genes to grow brains that are aligned with the genes’ interests. Gene/brain alignment might look simple. However, we’re seeing the descendants of the rare success stories – the few bright lights of gene/brain alignment success, against a dark background of millions of generations of bad reward functions, faulty perceptions, misguided cognitions, maladaptive motivations, and catastrophic misbehaviors, resulting in mass starvation, disease, predation, carnage, death, and extinction.
Nature didn’t care about all that failure. It had all the time in the world to explore every possible way of doing gene/brain alignment. It found some behavioral strategies that work pretty reliably to support the revealed preferences of animal genes. However, when it comes to human/AI alignment, we don’t have hundreds of millions of years, or quadrillions of lives, to get it right.
(Endnote: This essay is still rather half-baked, and could be better-organized. I’d welcome comments, especially links to other evolutionarily inspired ideas by other AI alignment researchers.)
1 comments
Comments sorted by top scores.
comment by p4rziv4l · 2024-06-29T10:43:08.835Z · LW(p) · GW(p)
The major difference between gene-brain and human-AI is that there is an evolutionary feedback loop between genes and the brains they produce.
It is not clear that an AI, which kills its 'brains' will be less fit.
Maybe an AI, which goes from mostly serving to mostly parasitizing its brain predecessors, can still provide enough value to humans while largely doing its own, incomprehensible superintelligent stuff.
Whatever fitness will mean for these AIs though, they will play out their own evolutionary games within their world where compute, network bandwidth and storage are the amino acids and sunshine.
Darwinian forces shall govern those AIs development, 100% oblivious to us, as we will be orders of magnitude too slow and stupid to understand them, by definition.