Composition Circuits in Vision Transformers (Hypothesis)
post by phenomanon (ekg) · 2024-11-01T22:16:11.191Z · LW · GW · 0 commentsContents
Idea Why do you suspect these exist? What now? Update: None No comments
Idea
I just wanted to make a quick post to get this idea out there, I'll hope to do a more thorough explanation later, and experiments after that.
Basically, I hypothesize that Vision Transformers have mechanisms that I call composition circuits, which operate like induction circuits in text transformers. They begin with a mechanism akin to the previous token head in text transformers. I call this a modular attention head. It works like the previous token head, except it attends to patch embeddings (~aka "tokens") around the candidate token in multiple directions around the token of interest. We know heads like this exist in early ViT layers. We don't necessarily know they perform the functionality I propose.

The second portion of the composition circuit is the, you guessed it, composition head (if you don't why this is supposedly obvious, the second head of an induction circuit is called the induction head. I'm not sure who would be reading this post who doesn't already know about induction heads, but if anyone is reading this post, I'll be happy). I haven't looked for these, but what they would do is combine the results compiled by the modular attention head. For example, if the modular attention head grabs (x-1,y-1) ... (x+1,y+1) w/ (x,y) the center token coord, the composition head just moves all the relevant features from those embeddings to the embedding at (x,y).
Why do you suspect these exist?
The primary fact motivating this hypothesis is the embedding layer of the Vision Transformer. I recently started doing some work training SAEs/etc, for Prisma, and I figured I should start thinking about what to expect from ViTs relative to text transformers. The primary observation I made was that whereas text transformers use a tokenizer/embedding matrix to convert a sentence into the embedding sequence/residual stream, a vision transformer uses d_resid convolutional kernels (of a size in (inverse) proportion to the desired patch size). So, whereas text is defined relativistically for TeTs (yep), for ViTs, the network essentially has to pick the d_resid most useful convolutional kernels it can think of and begin with all patches as a vector of features indicating their responsiveness to these kernels. So you begin the network with some very low-level information communicating spacial (edges, corners, donuts, etc.) and color-space (is it red?) properties and that's it. Yet, by the end of the network, if one were to plug in said ViT to CLIP or a VLM, it would yield high-level abstractions such as "a dog running on a hill in the sun". That all is to say, the network begins with a low-level patch features vector, and ends with a global and abstract representation of the image.
With that in mind, I suspect these exist because there must be some mechanism by which the model converts kernel-based image features to broader concept representations, and I suspect the composition circuit or something like it is how that happens.
Let's continue the example from above, where we have our modular attention head taking information from the patches (x-1,y-1) to (x+1,y+1) surrounding the (x,y) token. In the above image, this looks like several patches near the head of the grasshopper. So, let's say a few are broadly defined as <has green, long diagonal>, <white, background>, ...<green, sideways u shape>, and we have this modular attention head all report that these patches are near x,y. Then, I would hypothesize, in some future layer that there's a head that transfers all these tokens to the center token, from which you have all that grasshopper head info in one token. And afterwards perhaps there's an MLP feature or two that says, "oh yeah, this combo of features is a grasshopper, write it down".
To put it more succinctly, it's clear that Vision Transformers must both synthesize low-level spacial information and reason about the concepts represented by such patches broadly, and I suspect a composition circuit is the mechanism that allows this behavior.
What now?
I hope to have some time in the next few days to hunt for these circuits in ViTs. Ideally what I'd find is the composition circuit, and even better, a composition circuit plus an MLP function that reasons with such information to provide higher level conceptual features. So that would look like feeding in images and looking at attention head activations, and then training SAEs on the layer (or a layer beyond) where the composition head lies.
If you want to talk about this, email me at ethankgoldfarb@gmail.com or dm me on the open source mechint slack (Ethan Goldfarb)
Update:
Here's a printout of the attention heads for a forward pass on this image of a jeep/large car/truck:
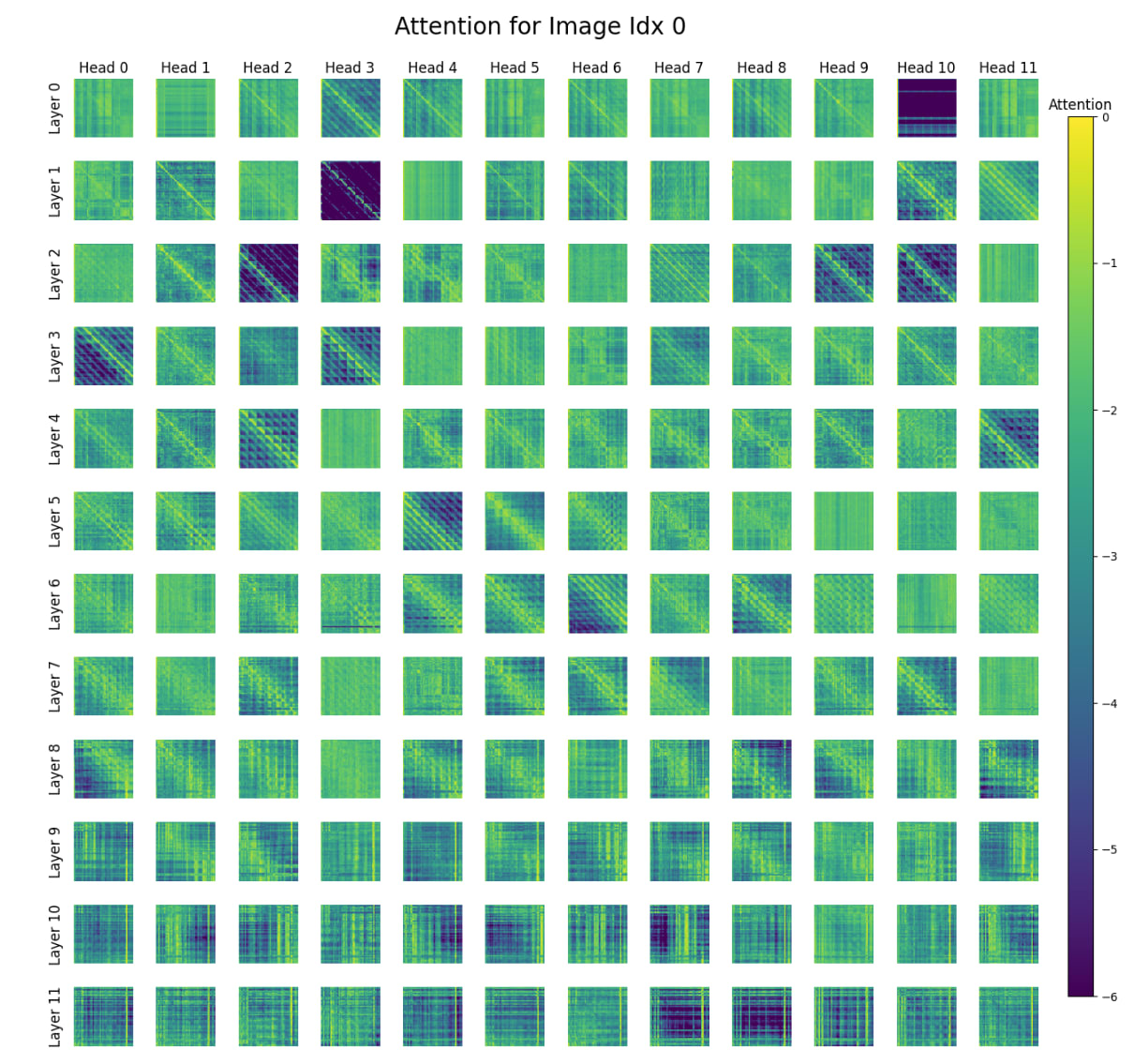
The primary trend I'd like to point to in support of the composition head hypothesis (broadly - this is more justified to be a statement on "local processing early, global processing later", which is a necessary but not sufficient condition in composition heads) is the shift from the highly visible attention matrix bands concentrated around the center in early layers to much more global information sharing patterns from layer 8 or 9 onwards. The lack of a strong set of center bands in the last 3-4 layers seems to indicate to me local information is no longer nearly as relevant.
I may train some SAEs on this network and run forward passes to try and identify abstracting behavior in the MLP layers. Whereas induction heads are pretty straightforward to identify (create a case of induction, look at the head that fires on the inductive cases), it seems a bit trickier to find this kind of head if it does exist. I think what I actually may do is find an abstraction feature/neuron in the MLP and then try to find a head that moves information to the patch that feature fires on.
0 comments
Comments sorted by top scores.