"Open Source AI" is a lie, but it doesn't have to be
post by jacobhaimes · 2024-04-30T23:10:11.963Z · LW · GW · 5 commentsThis is a link post for https://jacob-haimes.github.io/work/open-source-ai-is-a-lie/
Contents
Open Source AI What is Open Source AI? Wait… why are groups saying that their models are open source when they aren’t? Ok, so what do people mean when they refer to “open source” AI, at the time I am writing this article (April 2024)? What do we do about it? Acknowledgements None 5 comments
NOTE: This post was updated to include two additional models which meet the criteria for being considered Open Source AI.
As advanced machine learning systems become increasingly widespread, the question of how to make them safe is also gaining attention. Within this debate, the term “open source” is frequently brought up. Some claim that open sourcing models will potentially increase the likelihood of societal risks, while others insist that open sourcing is the only way to ensure the development and deployment of these “artificial intelligence,” or “AI,” systems goes well. Despite this idea of “open source” being a central debate of “AI” governance, there are very few groups that have released cutting edge “AI” which can be considered Open Source.

The term Open Source was first used to describe software in 1998, and was coined by Christine Peterson to describe the principles that would guide the development of the Netscape web browser. Soon after, the Open Source Initiative was founded with the intent to preserve the meaning of Open Source. The group wrote the Open Source Definition (OSD), and even made an unsuccessful attempt to obtain a trademark for the term.
The OSD isn’t very long, but here’s an even shorter version of the definition: the program must include source code,[1] and the license for the software cannot restrict who uses it, what it is used for, or how it is used; it cannot constrain the manner in which the software is distributed, and it cannot prohibit modification of the software.
Quickly, Open Source garnered massive support, and either directly produced or significantly contributed towards many of the software advances that have been seen since then. Some well-known Open Source projects are the coding languages Python and PHP, the browsers Mozilla Firefox and Chromium (which Google Chrome is built on top of), the database management system MySQL, the version control system Git, and the Linux operating system.
Open Source gained traction because it is practically valuable to many different stakeholders. In general, these attributes can be broadly summarized by saying that open source projects…
- facilitate rapid scientific progress,
- improve functionality and reliability,
- increase security and safety through transparency, and
- promote user control, inclusivity, and autonomy.
Importantly, each of these items is highly dependent on meaningful access. That is to say, if the software were difficult to investigate, modify, or repurpose, these traits would not be as prevalent.
Because Open Source projects have continually demonstrated these characteristics over the past quarter century, the label of Open Source is strongly associated with these characteristics as well.
Open Source AI
Advanced machine learning models, often referred to as “AI,” cannot be fully described by source code, in practice. Instead, models are defined with three components: architecture, training process, and weights.
Architecture refers to the structure of the neural network that a model uses as its foundation, and it can be described with source code. This architecture itself, however, is not enough information for meaningful transparency and reproducibility. As the term “machine learning” suggests, a process is conducted for the model to learn information; it is called the training process.
Although the training process, in theory, can be wholly defined by source code, this is generally not practical, because doing so would require releasing (1) the methods used to train the model, (2) all data used to train the model, and (3) so called “training checkpoints” which are snapshots of the state of the model at various points in the training process. At this point, cutting-edge models are being trained on a massive scale, with the “[m]edian projected year in which most publicly available high-quality human-generated text will be used in a training run” being 2024. For context, the largest training run consisting of only textual input that has already occurred was approximately 44,640 Gigabytes.[2] It simply isn’t possible to store such a large volume of data for every model separately, but without doing so, independent verification of training data is practically impossible.
Finally, we get to the weights. When applied to the correct architecture, weights are functionally similar to an executable file or machine code. For traditional programs, the executable file is what the computer uses to know what to do, but such a file is not human-readable in a practical sense. Along the same lines, weights determine the methods that a model uses to produce its output, but the weights themselves are not yet fully understood. The field of Mechanistic Interpretability is making progress on this task, but right now we do not know how to comprehensively understand why a model behaves in a given manner. In other words, model weights, which in turn prescribe model behavior, cannot be described by source code.
All this is to say that “AI” models don’t fit nicely into the preexisting Open Source Definition (OSD). The Open Source Institute recognized this, and began working towards an Open Source AI Definition (OSAID), in late 2022 – for context, that was just before the public launch of ChatGPT. This definition is still a work in progress, with the first version scheduled to be published in October of 2024. This means that, formally, there isn’t yet a definition for the term “Open Source AI.”
To many, this may come as a shock, because the idea of open source AI is not only commonplace, but a controversial subject when it comes to regulation. This discrepancy points towards a number of questions:
What is Open Source AI?

Although we can’t say what it is definitively, because the OSAID isn’t published yet, we can use the working version as a starting point.[3] First, let’s take OpenAI’s recent addition to the GPT family, GPT-4, as an example. GPT-4 is not open source – virtually no artifacts other than the GPT-4 Technical Report are publicly available. Meta’s Llama3 model is also not open source, despite the Chief AI Scientist at the company, Yann LeCun, frequently proclaiming that it is. In fact, Stefano Maffuli, the Executive Director of the OSI, authored a post explicitly calling this misnomer out. Llama3 is licensed with a custom agreement written by Meta, explicitly for the purpose of licensing the model.[4] The license explicitly prohibits its use for some users[5] and restricts how the model can be used. Google Deepmind’s Gemma model is licensed in a similar manner, meaning that it isn’t Open Source either.
Mistral’s models are also not open source, but in a slightly more nuanced manner. Instead of releasing all artifacts describing their models, Mistral licensed the model weights using the Apache 2.0 license, which meets the requirements for a license to be Open Source. Unfortunately, however, no other artifacts were released. As a result, Mistral’s models can be used as-is by anyone, but the transparency that should go hand-in-hand with Open Source is no longer present.
As a final example, BLOOMZ, a model developed by BigScience Workshop is also not Open Source. The model is licensed under the Responsible AI License (RAIL) License,[6] which does impose some restrictions on the use of the model. While these restrictions are not necessarily a bad thing to have, they do prevent the model from obtaining the official Open Source label.
Based on the current OSAID, the following models can be considered Open Source AI:
Wait… why are groups saying that their models are open source when they aren’t?
As stated previously, Open Source is strongly associated with increased fairness, inclusivity, safety, and security. Tech companies like Meta and Mistral want to use this to their advantage; by calling their models “open source,” they inflate the perception of their work as a public good without much cost to themselves.
For example, the founder of Mistral stated multiple times that the company’s competitive advantage is the data that they use to train models, and how they filter and generate that data. Although the weights of their models are made public, very little information is given regarding the data that was used to train the model. By tagging these models as “open source” without sharing any meaningful information about training data, the company gets to appear populist without sacrificing its competitive advantage. This behavior devalues the meaning of the Open Source label, and exploits the open source community for free labor.
It’s more than just public relations benefits too, both companies lobbied for reduced regulations for so called “open source” models, and their efforts seems to be working.[7]
Ok, so what do people mean when they refer to “open source” AI, at the time I am writing this article (April 2024)?
Regrettably, the answer to this question is not perfectly clear. Everyone is assuredly referring to some selection of models that meets certain criteria along this spectrum of openness, but where the line is drawn is up for interpretation. Of course, this has made meaningful discussion about the issue much more difficult.
What do we do about it?
Short answer: understand how corporations are using this ambiguity to their advantage, stop calling models like Llama3, Mixtral, and Gemma open source, and call the companies out on their influence campaign.
Longer answer: even though we shouldn’t be calling these models Open Source, they are substantially more transparent than the fully closed models of OpenAI or Anthropic. To clarify this space, I propose the following naming convention:
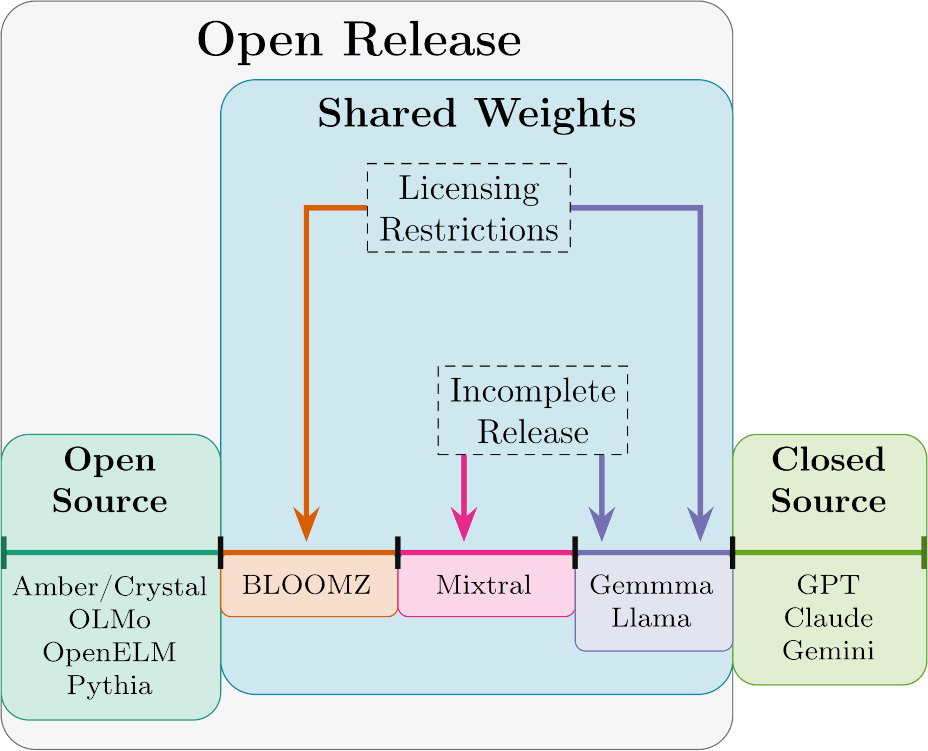
Open Source models – The OSAID is currently being drafted by the Open Source Initiative in a transparent manner, so the working OSAID can be used for the purposes of defining truly open source models. Currently, the only models that fall into this category are Amber and Crystal from the LLM360 group, OLMo from the Allen Institute for AI, OpenELM from Apple Inc., and Pythia from EleutherAI. The paper “Opening up ChatGPT: tracking openness of instruction-tuned LLMs” provides a very useful online table[8] with information on many chat models, and is a useful tool for understanding the manner in which the models are actually transparent.
Shared Weights models – Describes all AI models which released their weights in some low-barrier capacity. Most current models claiming to be open source fall into this category.
Open Release models – Encompasses both Open Source AI, as defined by OSAID, and Shared Weights Models. This term can be useful when discussing security concerns.
Closed Source models – For completeness, we will also explicitly define Closed Source models. These include models referred to as “black box” or “API” access; while people can use the models, the only individuals who can run the model are its owners. Queries can be screened and monitored. Sending queries through the API typically costs money.
It is important to note, I am not saying that Shared Weights models are a negative net contribution to society. In fact, I think that the release of currently available Shared Weights models has significantly advanced the field of AI safety. This article is not about the pros and cons of open source, I will leave that for future work.
Acknowledgements
A special thank you to Brian Penny, Dr. Peter Park and Giuseppe Dal Pra for reviewing the article and providing their input. This work was made possible through AISC Winter 2024.
- ^
The source code of a program is the file, written in a human-readable coding language, that defines how that program operates. To create an executable file, (aka. a binary file), the source code is compiled into machine code.
- ^
How I got that number: Epoch says that the largest amount of data used to train a single model is approximately 9 trillion words; they also say that the Common Crawl dataset has 100 trillion words. Wikipedia reports the most recent version of the Common Crawl to be 454 Tebibytes = 464,896 Gigabytes.
🠖 454 TiB * .09 = 44640.17 GB - ^
It is worth noting that the OSAID leans heavily on the Model Openness Framework which was published by White et al. in March of 2024. The group that conducted this research is called the Generative AI Commons, and is funded through the Linux Foundation. The Model Openness Framework already has a domain registered for their pending tool, isitopen.ai.
- ^
This is also an issue, but it is far less pressing, and more just annoying.
- ^
Namely, the license prohibits Llama3’s use by Meta’s competitors, and anyone who might make a significant amount of money off of it.
- ^
Yes, I know the title has the word license in it twice, that’s how it’s written, don’t @ me.
- ^
Although I am by no means a legal expert, I believe that the special provisions made for Open Source models are described entirely in the EU AI Act recital 104.
- ^
It is important to note that this table is only for instruction-tuned LLMs, meaning that base models which were not instruction-tuned do not appear on the list. The paper which accompanied this table, “Opening up ChatGPT: Tracking openness, transparency, and accountability in instruction-tuned text generators” was released as a preprint in mid 2023, and published for the Conversational User Interfaces conference in December of 2023. It does appear to have been updated since the conference, as OLMo now appears on this list. I am not sure how frequently it is updated.
5 comments
Comments sorted by top scores.
comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2024-05-12T20:05:22.159Z · LW(p) · GW(p)
Meta’s Llama3 model is also *not *open source, despite the Chief AI Scientist at the company, Yann LeCun, frequently proclaiming that it is.
This is particularly annoying because he knows better: the latter two of those three tweets are from January 2024, and here's video of his testimony under oath in September 2023: "the Llama system was not made open-source".
Replies from: jacobhaimes↑ comment by jacobhaimes · 2024-05-23T19:29:46.631Z · LW(p) · GW(p)
I have heard that this has been a talking point for you for at least a little while; I am curious, do you think that there are any aspects of this problem that I missed out on?
comment by Anish Tondwalkar (anish-tondwalkar) · 2024-05-16T23:24:25.498Z · LW(p) · GW(p)
Thanks for writing this and for the diagram, which I think is clearer than anything I've seen that's attempted to clarify this mess.
That said, the terminology remains fantastically confusing.
> Mistral’s models are also not open source, but in a slightly more nuanced manner. Instead of releasing all artifacts describing their models, Mistral licensed the model weights using the Apache 2.0 license, which meets the requirements for a license to be Open Source. Unfortunately, however, no other artifacts were released. As a result, Mistral’s models can be used as-is by anyone, but the transparency that should go hand-in-hand with Open Source is no longer present.
IIUC, this means that Mistral's models are both Open Source (in the sense of the license being an Open Source license), and Open Source AI (in the sense that they adhere to the OSAID --- the first question in the OSAID FAQ is "Why is the original training dataset not required?"), but it is not classified as Open Source according to the classification scheme used in the diagram. Perhaps we need a 5th term to make these clearer?
↑ comment by jacobhaimes · 2024-05-23T19:23:14.672Z · LW(p) · GW(p)
Thanks for responding! I really appreciate engagement on this, and your input.
I would disagree that Mistral's models are considered Open Source using the current OSAID. Although training data itself is not required to be considered Open Source, a certain level of documentation is [source]. Mistral's models do not meet these standards, however, if they did, I would happily place them in the Open Source column of the diagram (at least, if I were to update this article and/or make a new post).
comment by Remmelt (remmelt-ellen) · 2024-05-04T09:08:12.437Z · LW(p) · GW(p)
Although the training process, in theory, can be wholly defined by source code, this is generally not practical, because doing so would require releasing (1) the methods used to train the model, (2) all data used to train the model, and (3) so called “training checkpoints” which are snapshots of the state of the model at various points in the training process.
Exactly. Without the data, the model design cannot be trained again, and you end up fine-tuning a black box (the "open weights").
Thanks for writing this.