Neural Scaling Laws Rooted in the Data Distribution
post by aribrill (Particleman) · 2025-02-20T21:22:10.306Z · LW · GW · 0 commentsThis is a link post for https://arxiv.org/abs/2412.07942
Contents
No comments
This is a linkpost for my recent research paper, which presents a theoretical model of power-law neural scaling laws.
Abstract:
Deep neural networks exhibit empirical neural scaling laws, with error decreasing as a power law with increasing model or data size, across a wide variety of architectures, tasks, and datasets. This universality suggests that scaling laws may result from general properties of natural learning tasks. We develop a mathematical model intended to describe natural datasets using percolation theory. Two distinct criticality regimes emerge, each yielding optimal power-law neural scaling laws. These regimes, corresponding to power-law-distributed discrete subtasks and a dominant data manifold, can be associated with previously proposed theories of neural scaling, thereby grounding and unifying prior works. We test the theory by training regression models on toy datasets derived from percolation theory simulations. We suggest directions for quantitatively predicting language model scaling.
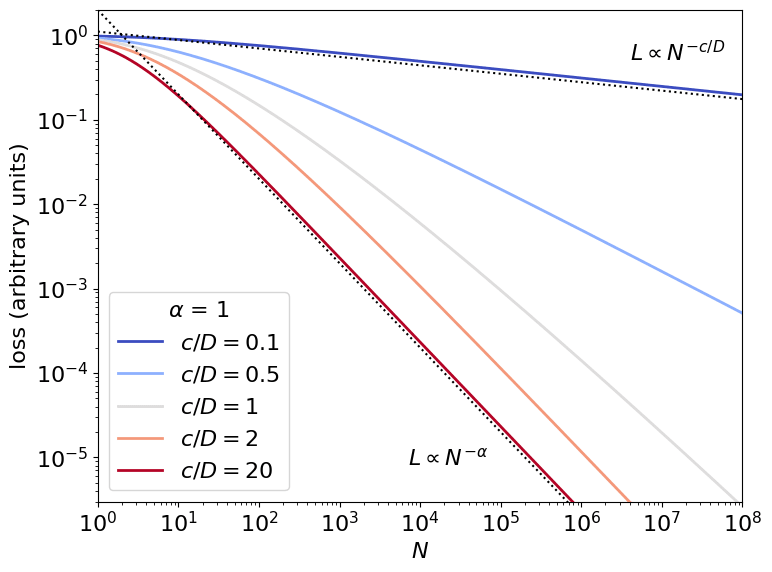
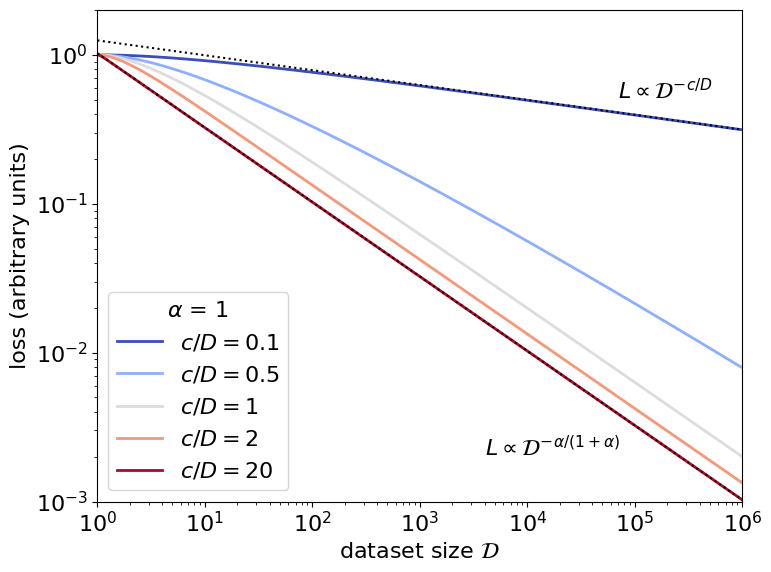
The theory is motivated by a general-purpose learning system for which optimal performance is determined by generic data distributional structure. The model uses percolation theory from physics to provide a first-principles, emergent description of natural datasets, which consist either of a dominant low-dimensional data manifold or of discrete power-law-distributed clusters. This work grounds and unifies two previously proposed explanations for power-law neural scaling laws: nonparametric function approximation of an intrinsically low-dimensional data manifold and sequential learning of power-law-distributed discrete subtasks (“quanta”).
Going forward, I hope to build on this work by testing its predictions using more realistic toy models; exploring how its implied dataset structure may be relevant for mechanistic interpretability; and extending the theory to a nonergodic setting, which could enable in-context learning. My hope is that this research provides a foundation to help us better understand the structure of world models learned by AI systems.
0 comments
Comments sorted by top scores.