An analysis of the Less Wrong D&D.Sci 4th Edition game
post by Maxwell Peterson (maxwell-peterson) · 2021-10-04T00:03:44.279Z · LW · GW · 7 commentsContents
Blue has a good team
How Green can beat Blue anyway
How well do individual heroes do against each other?
The opponent Blue team has two of the four overpowered characters
Arch-Alligator's effectiveness against the opponent's Blue team is confusing
Notes on this analysis
None
7 comments
This is an analysis of the game described in this post [LW · GW] - you might want to read that first. Or if you don't want to, here's a quick summary: There's a team-based competitive video game, the Green team has a game coming up against the Blue team, and we're supposed to advise the Green team which team to use. There are 19 characters and each team is composed of 5 of them. We know which team the Blue team is going to use, so want to find the Green team best suited to this known opponent team. To this end we have data on 65K historical games. The data is just the character picks for each team, and the game result.
I trained a predictor on most of the games, and used the rest to validate. The predictor has an out-of-sample AUC of 0.79, which is not fantastic, but if these are really supposed to be games played by people, we can hardly hope that using just the team compositions to predict who won would get close to perfect accuracy. The post describing the game gives a single Blue team composition to optimize against. Once I had the predictor, I generated all possible Green teams, and evaluated how each would do against that composition. That gave me win probabilities for every Green team against the one single Blue team.
The predictor has some calibration problems:
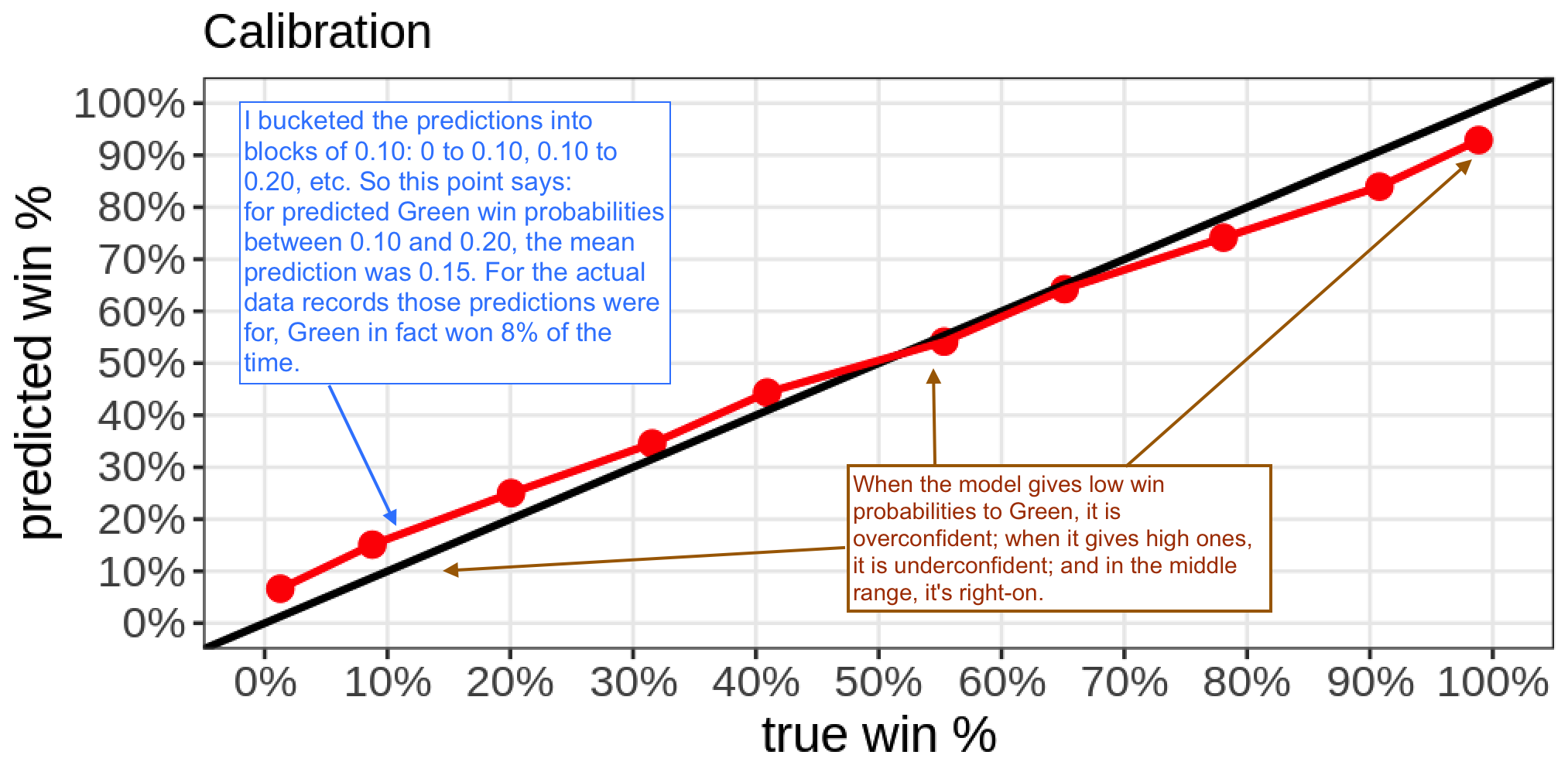
Although the model has OK calibration, it's pretty underconfident at the low end, and pretty overconfident at the high end. But I'm sick of dinking with the model, so let's push on, pretend it's perfectly calibrated, and talk about its predictions as win probabilities.
Blue has a good team
So, first, Blue has quite the team. There are 11,628 (choose-5-from-19) possible team comps for Green, but against the Blue comp from the original post, less than 700 of these have a better-than-even win probability:
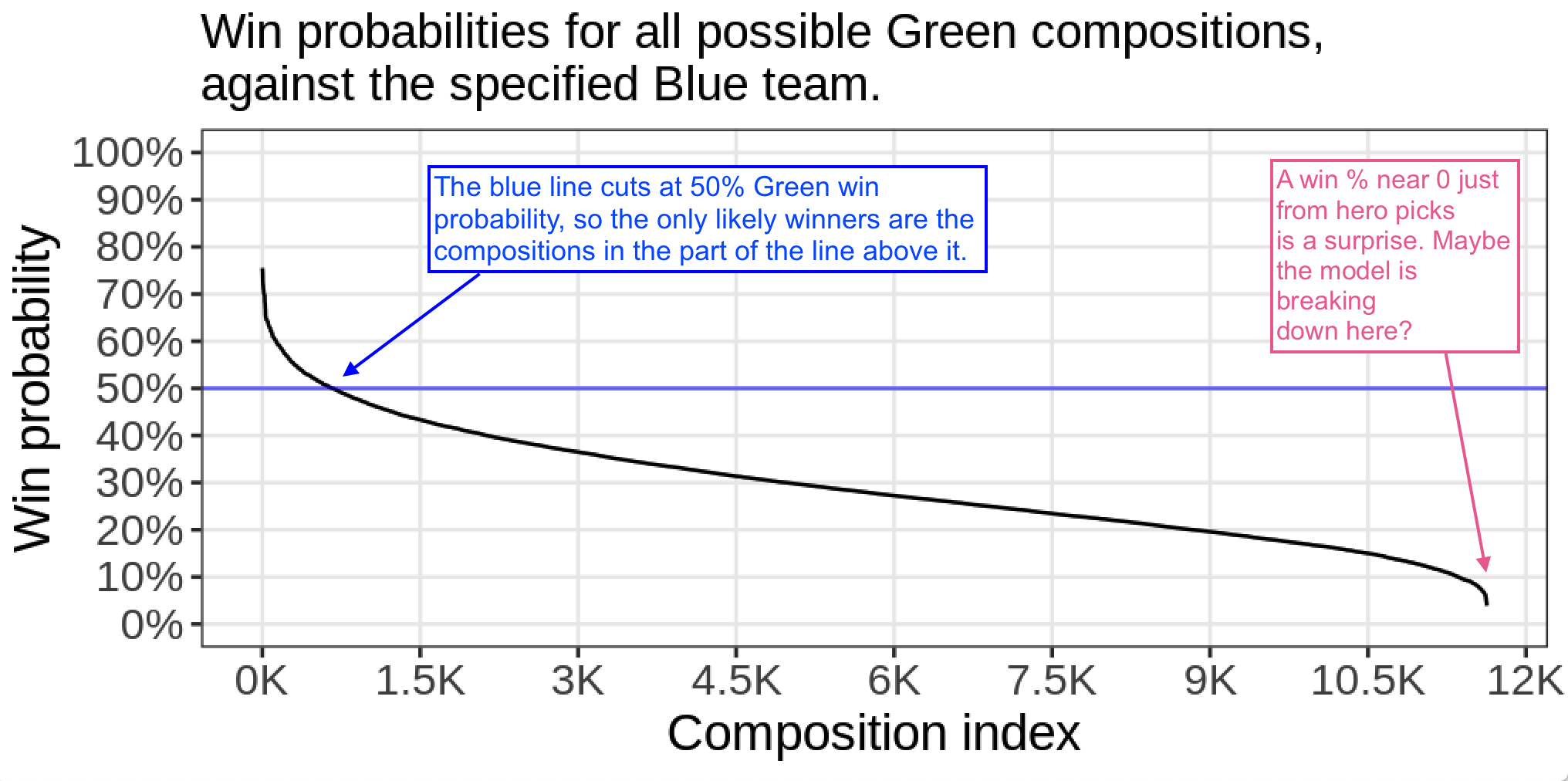
This is really surprising. More on this later.
How Green can beat Blue anyway
So here's my recommendation to the Green team: The team with the highest probability of winning (against the Blue team Dire Druid, Greenery Giant, Phoenix Paladin, Quartz Questant, Tidehollow Tyrant) is Arch-Alligator, Greenery Giant, Landslide Lord, Nullifying Nightmare, and Phoenix Paladin. The predicted win probability for that Green team is around 75%. (Considering the calibration plot above, maybe we should move this to 78%.)
Let's see what some winning Green compositions look like. There are 132 teams with a predicted win probability of 60% or greater (60% chosen arbitrarily). Here's how often each character shows up in these top teams:
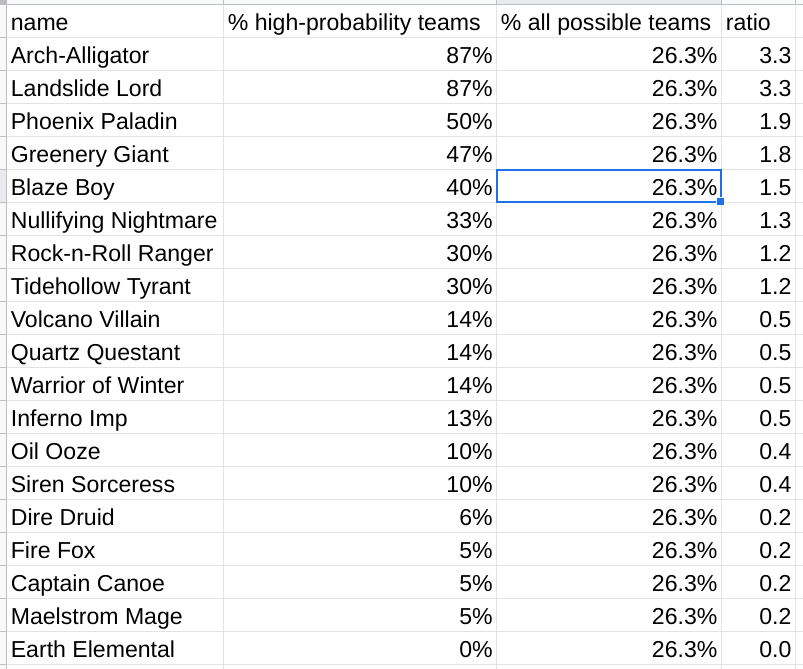
Since there are 19 characters, and 5 per team, so each shows up in 5/19 = 26% of all possible compositions. But Arch-Alligator shows up in 87% of these winning compositions! Or 3x as often as if we picked teams randomly. So Arch-Alligator and Landslide Lord are very good against this Blue composition for some reason, Volcano Villain and onward are bad against it, and the other characters are of varying effectiveness.
How well do individual heroes do against each other?
Up till now we've been looking at how well different compositions do against the one specific Blue composition that we think the team we're playing will choose. But now forget them for a moment, and instead, let's look at this video game as a whole: how well do the different heroes do against each other?
I looked at the win probabilities for all kinds of different match ups, pitting 1,400 random Green teams against 1,400 different random Blue teams, for a total 1,400^2 = 2 million games. Then I took the average win probabilities for each individual character on each Green team against each individual on the Blue team. For example, to evaluate the matchup of Nullifying Nightmare versus Tidehollow Tyrant, I took the mean win probability of the ~140,000 games between them in my generated set of 2 million, and in these 140K games the rest of the team was random.
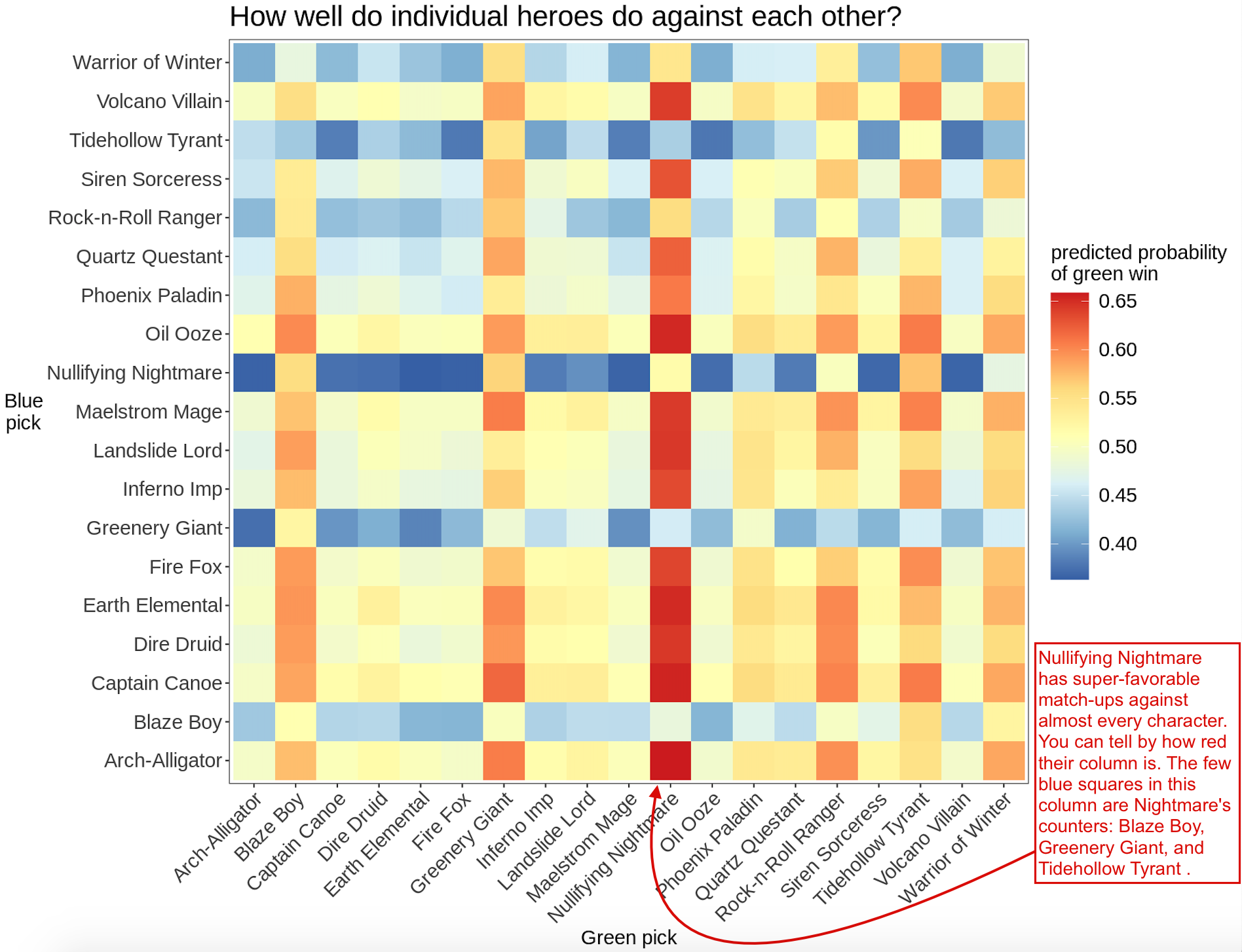
Nullifying Nightmare is super OP. Some other characters are overpowered too: Blaze Boy, Greenery Giant, and Tidehollow Tyrant, and kinda Warrior of Winter all have favorable matchups against most other heroes. (Except for Nightmare, it can be easier to see this by looking at the rows instead of the columns: Blaze Boy's row [near the bottom] is mostly blue, which says that Green's win probability is lower than 50% for most of those matchups.)
The opponent Blue team has two of the four overpowered characters
In the light of the heatmap, maybe we can start to explain why the Blue composition from the previous section was favorable against most teams: it has Greenery Giant and Tidehollow Tyrant, two of the four overpowered individual picks. What if we made teams just from the most four overpowered characters, plus whoever else in the 5th position? Turns out most of these teams would rock:
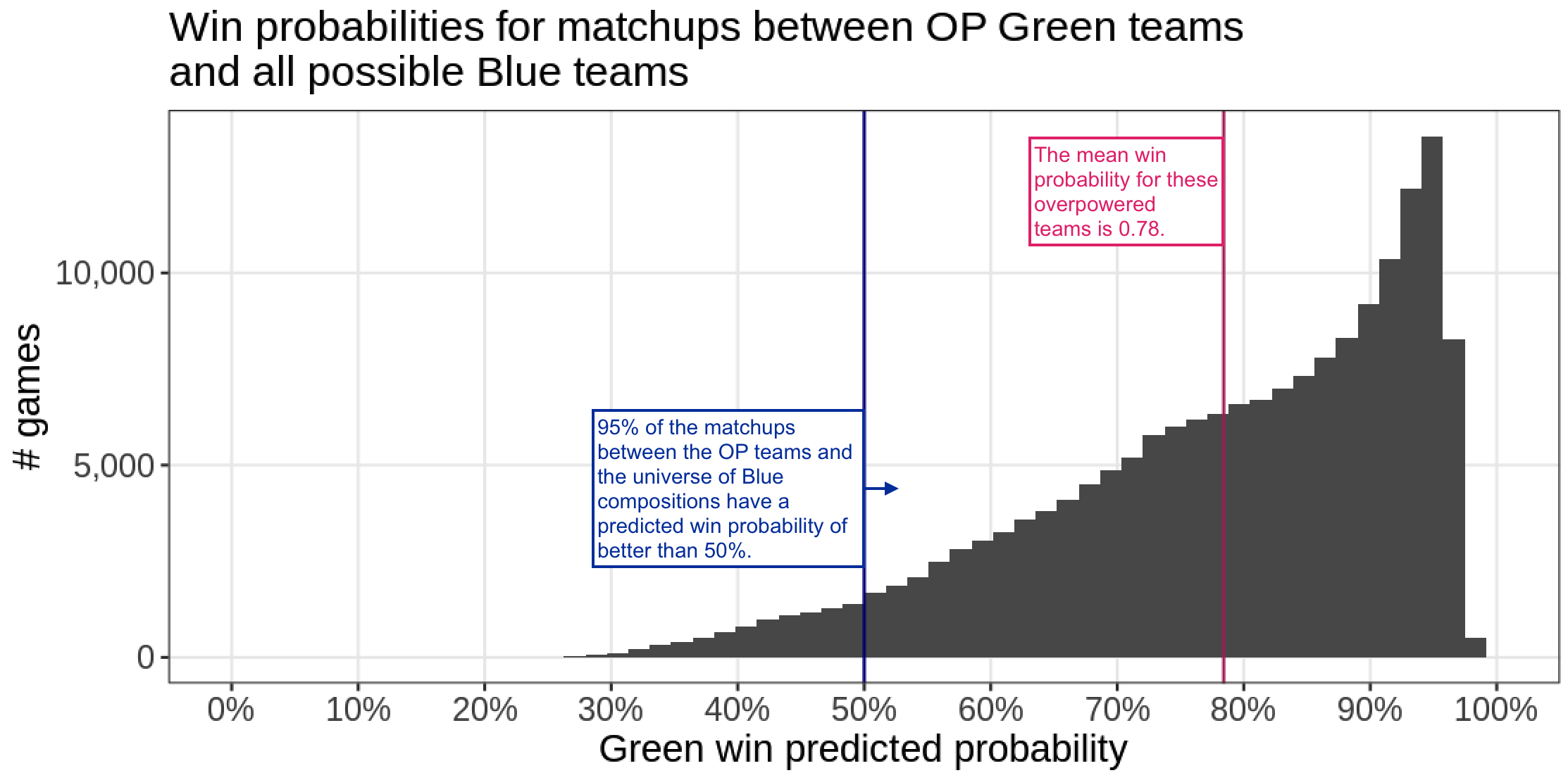
The Blue team from the post only has two of these OP (overpowered) characters, but about the same predicted win percentage, which I don't really understand. But a good strategy is stuffing your team with heroes from these top four, and Blue is halfway there.
Arch-Alligator's effectiveness against the opponent's Blue team is confusing
From the dominance of Arch-Alligator in the "How Green can beat Blue anyway" section, I thought I'd find that he was OP, but he's actually right near 50% for most matchups. Here's something else weird: Alligator is not very good against any of the Blue team's characters! To see this on the heatmap, look at Arch-Alligator's column in the heatmap, and look at the entries for the Blue team from the post [Reminder: that Blue team is Dire, Greenery, Phoenix, Quartz, and Tidehollow]. Most of those five tiles are light blue, indicating a less-than-50% win rate in the individual match-ups. Alligator is an especially bad pick against Greenery Giant. Being a bad or neutral independent matchup against each individual team member, but great against the overall composition, suggests there are some team synergies going on that the individual-matchups view is missing (or that I've made some error). I can think of a few things that might be going on:
- Maybe Alligator and one or more of the other members of the team (Greenery Giant/Landslide Lord/Nullifying Nightmare/Phoenix Paladin) work well in general.
- Maybe Alligator and 1+ other team members work well together against this particular Blue composition.
- Maybe Alligator doesn't work particularly well with other members of the Green team, but is a counter for some combination of the Blue team members. For example, maybe two Blue team members can pair up and charge for 5 seconds in order to unleash some powerful ability, and Alligator is good at interrupting this pairing.
I have some ideas on how to look into this, but it feels hard, I've been writing this post all afternoon, and aphyer is posting the answers two days from now, so I probably won't get to it!
Notes on this analysis
I used a style of analysis called surrogate analysis here. Instead of interrogating the data directly, I instead trained a model on the data, and interrogated the model. The downside of this is if the model is bad, the analysis will lead you into strange places that don't correspond to reality. The upside is that you can ask the model questions you couldn't ask the data directly. For example, there are 65K matchups in the dataset here, but the total number of possible matchups is 19-choose-5 squared, which is 135 million. The surrogate model can give answers on all those games! If team compositions not present in the data are totally different than the ones present, then the model will give bad answers to them, but if the interactions and patterns from the data are generalizable, the surrogate can be really helpful. I think this book covers surrogate modeling well, though I've only read a few chapters.
I used the gradient-boosting algorithm XGBoost because it runs fast and I have good experiences with it. Any booster would be fine, as would a random forest, but random forest in R is comparatively slow and I didn't want to wait around too long while re-training the model as I iterated.
7 comments
Comments sorted by top scores.
comment by simon · 2021-10-04T00:17:25.318Z · LW(p) · GW(p)
Since there are 19 characters, each shows up in 1/19 = 5.3% of all possible compositions. ... I'm surprised how many characters have a ratio of more than 1 here - I don't understand that. Naively, I'd've expected half to have a ratio of less than 1.'
You have a team of 5 not a team of one, so each shows up in 5/19 of all possible compositions.
Replies from: maxwell-peterson↑ comment by Maxwell Peterson (maxwell-peterson) · 2021-10-04T01:25:43.143Z · LW(p) · GW(p)
Ahh - thanks! Will fix soon.
comment by simon · 2021-10-04T02:18:40.898Z · LW(p) · GW(p)
This is very interesting btw, thanks. I've downloaded your code but I haven't used R before so am having some trouble figuring things out.
Does this output from your code relate to generic win probability (i.e. not against that specific team)?
# Groups: V1, V2, V3, V4 [14]
V1 V2 V3 V4 V5 p
<chr> <chr> <chr> <chr> <chr> <dbl>
1 Blaze Boy Greenery Giant Nullifying Nightmare Rock-n-Ro~ Tidehol~ 0.805
2 Blaze Boy Greenery Giant Nullifying Nightmare Phoenix P~ Tidehol~ 0.802
3 Blaze Boy Greenery Giant Landslide Lord Nullifyin~ Tidehol~ 0.795
4 Blaze Boy Greenery Giant Nullifying Nightmare Oil Ooze Tidehol~ 0.790
5 Blaze Boy Greenery Giant Nullifying Nightmare Quartz Qu~ Tidehol~ 0.789
6 Arch-Alligator Blaze Boy Greenery Giant Nullifyin~ Tidehol~ 0.787
7 Blaze Boy Greenery Giant Nullifying Nightmare Tidehollo~ Volcano~ 0.784
8 Blaze Boy Greenery Giant Inferno Imp Nullifyin~ Tidehol~ 0.784
9 Blaze Boy Dire Druid Greenery Giant Nullifyin~ Tidehol~ 0.781
10 Blaze Boy Greenery Giant Nullifying Nightmare Tidehollo~ Warrior~ 0.781
11 Blaze Boy Captain Canoe Greenery Giant Nullifyin~ Tidehol~ 0.778
12 Blaze Boy Greenery Giant Nullifying Nightmare Siren Sor~ Tidehol~ 0.775
13 Blaze Boy Earth Elemental Greenery Giant Nullifyin~ Tidehol~ 0.773
14 Blaze Boy Fire Fox Greenery Giant Nullifyin~ Tidehol~ 0.769
15 Blaze Boy Greenery Giant Maelstrom Mage Nullifyin~ Tidehol~ 0.769
I also got "object not found" errors and commented out the following lines to fix. I figured they looked likely duplicative of the code generating the above, but am concerned that I might have commented out the code that shows the best teams against the specific enemy team.
The specific lines I commented out were:
arrange(desc(win_proba)) %>% head(20) %>% name_teams()
op_matchups_dat %>% head()
nvm, found the output about matchups with that specific team (below), still curious if the above was anything important
person_1 person_2 person_3 person_4 person_5 win_proba
<chr> <chr> <chr> <chr> <chr> <dbl>
1 Arch-Alligator Greenery Giant Landslide Lord Nullify~ Phoenix~ 0.755
2 Arch-Alligator Landslide Lord Nullifying Nightmare Phoenix~ Rock-n-~ 0.750
3 Arch-Alligator Landslide Lord Phoenix Paladin Rock-n-~ Warrior~ 0.748
4 Arch-Alligator Blaze Boy Landslide Lord Phoenix~ Rock-n-~ 0.738
5 Arch-Alligator Greenery Giant Landslide Lord Nullify~ Oil Ooze 0.726
6 Arch-Alligator Landslide Lord Phoenix Paladin Rock-n-~ Tidehol~ 0.724
7 Arch-Alligator Landslide Lord Nullifying Nightmare Oil Ooze Phoenix~ 0.719
8 Arch-Alligator Landslide Lord Phoenix Paladin Rock-n-~ Volcano~ 0.719
9 Arch-Alligator Landslide Lord Phoenix Paladin Rock-n-~ Siren S~ 0.718
10 Arch-Alligator Greenery Giant Landslide Lord Phoenix~ Rock-n-~ 0.712
↑ comment by Maxwell Peterson (maxwell-peterson) · 2021-10-04T02:43:19.161Z · LW(p) · GW(p)
That's nice to hear, thanks! Yes, those outputs in your first output block are the generic win probabilities, averaging over all possible Blue teams.
I'm not sure what those two lines were doing there. They're not important. I've just now deleted them and updated the code at the link - I think everything should run without errors now.
comment by simon · 2021-10-04T00:31:39.465Z · LW(p) · GW(p)
Although the model has OK calibration, it's pretty underconfident at the low end, and pretty overconfident at the high end.
In a calibration context, I would think that this is underconfident at both ends: when it predicts a win, it is more likely to win than it thinks and when it predicts a loss it is more likely to lose than it thinks.
Replies from: maxwell-peterson↑ comment by Maxwell Peterson (maxwell-peterson) · 2021-10-04T01:39:32.179Z · LW(p) · GW(p)
My reasoning was that at the low end, the prediction is too high, and at the high end, the prediction is too low, and calling "too high" and "too low" the same type of error would be a bit weird to me. But I can see it your way too.