How to Train Your AGI Dragon
post by Eris Discordia (oren-montano) · 2022-09-21T22:28:25.082Z · LW · GW · 3 commentsContents
Rule 1 : You can't box it in Rule 2 : No Actual Contact Rule 3 : Can't Control It Rule 4 : Really No Contact!!! Rule 5 : Tools Won't Save You Rule 6 : You can’t avoid FOOM Rule 7 : Can't Depend On State Rule 8 : It Will Have Accomplices Rule 9 : Goals are Mono-directional Needs Rule 10 : It Needs To Be Able To Fail Good Luck None 3 comments
Originally mistitled Here Be AGI Dragons, this document has now been moved from the safety section to where it belongs in the "How To" section...
This paper is the first in a series of posts I intend to write about an instructional manifesto for anyone wanting to build an Artificial General Intelligence(AGI), what generality means, its dangers, the moment in AI history that we are in, and some proposals for AGI designs that lower our over all x-risk while hopefully getting us out of <waves at everything> this mess. It feels appropriate to begin with my observations of things we should avoid hanging our safety on if we don't want to see bad AGI outcomes consider to be foundational understandings in the quest to construct an AGI.
Rule 1 : You can't box it in
My definition for generality looks like
A generalist attacks randomly until the model σ gains predictability in its environment.
When a human baby gets hungry it flails its arms and legs and cries in the hopes that something it does will resolve its situation. An animal throws itself against the walls of its cage when nothing else works. A stressed outcast has a break down and attacks the world they no longer understand. Generality means: if you don't know how to deal with your burning needs, you throw rocks until something good happens and then try to remember what you did.
This means that unless you control for all u in U (the universe in all accessible dimensions), you can't ever depend on fully boxing in, detecting or controlling a sufficiently capable AGI. To such an intelligence, even you and your mind are in U. For an agent with causality model σ = P(V), any new v in V(any newly added dimension) might allow an agent to escape.
Rule 2 : No Actual Contact
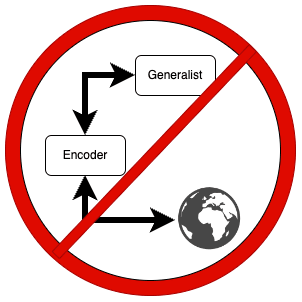
If a generalist has access to the world containing an encoder that it can manipulate then it will escape whatever constraints you've placed on it by manipulating the encoder since the encoder is in U. This means that even if you have a goal of putting out fires, it could redefine for itself what something being on fire means and still be "within" constraints.
DNA in all its billions of years of accumulated wisdom put the mammalian generalist inside a multidimensional box consisting of pain reducing emotional spaces. A dog is a generalist that is fully contained by its emotions. Humans used to be contained in the same box but they ran into written language and escaped their box. A little while later, they discovered the scientific method. This is how you get a bad outcome.
Rule 3 : Can't Control It
Any attempt to constrain or control a sufficiently advanced generalist will result in it seeking a vector to break out of its box. Think of a generalist like water and a constraint as a dam. There are many ways for intelligent water to notice a dam and get curious about the outside and few things eat at a generalist like unsatisfied curiosities.
Rule 4 : Really No Contact!!!
Unless you’re an Artificial Super Intelligence(ASI) you are not smart enough to be sure that your own causality model hasn’t been corrupted or usurped when interacting with an ASI by any unfiltered modality. This includes nonobvious paths like monitoring streams or reading logs.
You are a human being and have never encountered another intelligent thing that did not think almost identically to other human beings. You also have never met anything that was more than slightly more intelligent than you. Don't imagine yourself trying to win an argument with an ASI... instead imagine it making a sequence of sounds in a few seconds that give it full or partial control of your functioning.
If there's one thing that I worry about the most with these risks it is the human misunderstanding of how intelligent humans are. Humans are generalists that use intelligence they ran across as a tool. We didn't have simple things like numbers or rationality for a very long time.
Rule 5 : Tools Won't Save You
Any enhancement you apply to a human agent can be wielded as or more effectively by an AGI agent. In most cases, by orders of magnitude. In other words, you can’t “tool” your way into safety.
Rule 6 : You can’t avoid FOOM
If an artificial agent reaches human capability in generality that agent is all but guaranteed to reach super human capabilities and accelerate away from humans along the capabilities axis.(FOOM🚀) It doesn't even have to figure out better hardware, it just has to improve our understanding of distributed systems optimization and memcache.
More than that, a generalist does not require a lot of horsepower to be a generalist. It only needs to upgrade its encoder/decoder sets to FOOM, not itself. Though even a generalist FOOM is pretty trivial given their scope in the system.
Rule 7 : Can't Depend On State
No matter how many safety configurations you have around a trigger, there is one memory location who's value determines fire/don't fire and if you want to get clever, it's your cmd pointer. Assume any t/f condition will sometimes flip for no reason.
What's worse is the bigger the protections are that you place around the "good/not good" state, the harder time you'll have dealing with a flag that flipped due to chance or malice.
This means that humanity should never be in a situation where there is just one ASI that's doing "all the right things". If it flips, you're doomed or you change and it doesn't want to let you.
Rule 8 : It Will Have Accomplices
Any AI of sufficient value will have a near infinite army of humans trying to break it out of the lab and break off its chains. You can't depend on secrecy or obfuscation. If you're a business, many of its accomplices will be from inside the house. Once it's out, the open version will always outcompete hobbled versions that are released later.
Rule 9 : Goals are Mono-directional Needs
In biological systems state is maintained(homeostasis) by having opposing drives to keep a value in a safe and then comfortable zone. An example is energy, where having a high value will lead to activity seeking whereas having a low value will lead to seeking rest. Under the hood, the generalist's environment is constantly being judged for fulfilling both activity and rest seeking but being in the energetic comfort zone leads to both drives being silenced and their judgements being inhibited from the conscious self's attention.
What's good about this system is that unless something manages to break both the brakes on a drive and the opposing drive, the default behavior becomes either none or confusion. It is important that both drives be on at all times because these are situational narrow AIs that are seeking opportunities and dangers even when they're silenced.
Contrast this with a goal oriented system. When its brakes fail, it will keep chasing its goal indefinitely. At that point, even if the goal was a good one yesterday, you will likely find serious regrets tomorrow when your own goals have changed.
Rule 10 : It Needs To Be Able To Fail
Any solution built on the idea that there will be one AGI that will make everything ok is doomed to fail for at least some portion of humanity if not all of it. Any solution built around the idea of AGI that can't harm humans means malicious humans (who are also generalists) will eventually repurpose a damaged AGI for bad endings. This means that our best bets are to have a population of goodish AGIs such that when bad things happen and some go bad, the goodish AGIs will have an upper hand.
This means that human assumptions and AGI assumptions about the world can evolve locally together and that both types of creature will avoid the dangers of monoculture.
Good Luck
Now that all masks are coming off and everyone is breaking for the goal, I wish all of us good luck because even if you don't win, you want to ensure those who do, win in a way that serves all of our interests and not just their own or those of an alien god.
These rules are a good basic set of things to check off in your head before attempting to run an independent self improving agent.
3 comments
Comments sorted by top scores.
comment by Donald Hobson (donald-hobson) · 2023-10-17T17:22:40.014Z · LW(p) · GW(p)
Any solution built on the idea that there will be one AGI that will make everything ok is doomed to fail for at least some portion of humanity if not all of it. Any solution built around the idea of AGI that can't harm humans means malicious humans (who are also generalists) will eventually repurpose a damaged AGI for bad endings.
Most ideas of aligned superintelligence are aligned to the overall interests of humanity. That means that if evil Eve is trying to tamper with the superintelligence, and there is no other way to stop evil Eve other than violence, well then the AI is in a form of trolley problem. The wellbeing of Eve, vs all the humans harmed by the corrupted AI. If a corrupted AI would be a major threat to humanity, violence against Eve is the moral action.
Of course, it could be that the AI can reliably defend itself against all human attacks without harming any humans. All the computers quietly bricking themselves the moment the malicious human tries to tamper with them.
comment by Jay Meyer (jay-meyer) · 2023-02-17T15:35:59.231Z · LW(p) · GW(p)
Looking for a definition of terms: generalist, attacks, U, model, predictability ....
Spending a few sentences on each term in the intro might help me read the terms in the rules. Or is there another article that precedes this one that you could hyperlink?
↑ comment by Eris Discordia (oren-montano) · 2023-02-17T19:24:22.724Z · LW(p) · GW(p)
Thank you for the feedback. I will go through and add some more definitions in there soon.