Reflections on Deception & Generality in Scalable Oversight (Another OpenAI Alignment Review)
post by Shoshannah Tekofsky (DarkSym) · 2023-01-28T05:26:49.866Z · LW · GW · 7 commentsContents
The Plan The Problems Red Lines & Recommendations In Review None 7 comments
Just like you can test your skill in experimental design by reviewing existing experiments, you can test your skill in alignment by reviewing existing alignment strategies [LW · GW]. Conveniently, Rob Bensinger [LW · GW], in name of Nate Soares and Eliezer Yudkowsky, recently posted a challenge to AI Safety researchers to review the OpenAI alignment plan written by Jan Leike, John Schulman, and Jeffrey Wu. I figured this constituted a test that might net me feedback from both sides of the rationalist-empiricist[1] aisle. Yet, instead of finding ground-breaking arguments for or against scalable oversight to do alignment research, it seems Leike already knows what might go wrong — and goes ahead anyway.
Thus my mind became split between evaluating the actual alignment plan and modeling the disagreement between prominent clusters of researchers. I wrote up the latter in an informal typology of AI Safety Researchers [LW · GW], and continued my technical review below. The following is a short summary of the OpenAI alignment plan, my views on the main problems, and a final section on recommendations for red lining.
The Plan
First, align AI with human feedback, then get AI to assist in giving human feedback to AI, then get AI to assist in giving human feedback to AI that is generating solutions to the alignment problem. Except, the steps are not sequential but run in parallel. This is one form of Scalable Oversight.
Human feedback is Reinforcement Learning from Human Feedback[2] (RLHF), the assisting AI is Iterated Distillation and Amplification [LW · GW] (IDA) and Recursive Reward Modeling (RRM), and the AI that is generating solutions to the alignment problem is… still under construction.
The target is a narrow AI that will make significant progress on the alignment problem. The MVP is a theorem prover. The full product is AGI utopia.
Here is a graph.
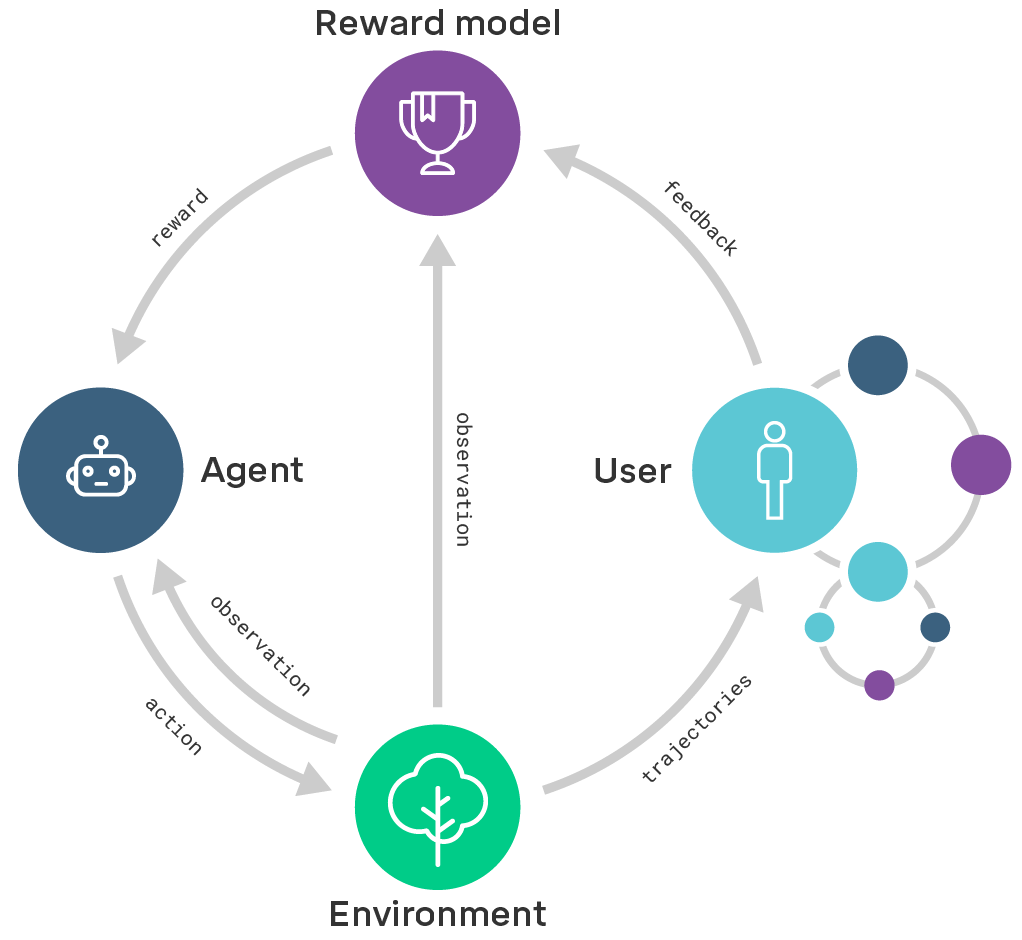
OpenAI explains its strategy succinctly and links to detailed background research. This is laudable, and hopefully other labs and organizations will follow suit. My understanding is also that if someone came along with a better plan then OpenAI would pivot in a heart beat. Which is even more laudable. The transparency, accountability, and flexibility they display set a strong example for other organizations working on AI.
But the show must go on (from their point of view anyway) and so they are going ahead and implementing the most promising strategy that currently exists. Even if there are problems.
And boy, are there problems.
The Problems
Jan Leike discusses almost all objections to the OpenAI alignment plan on his blog. Thus below I will only highlight the two most important problems in the plan, plus two additional concerns that I have not seen discussed so far.
Nearest Unblocked Strategy will eventually lead to a successful deception or manipulation of humans - The OpenAI plan relies on humans detecting and correcting undesirable output at each step, while the AI becomes increasingly intelligent along the way. At some point, the AI will be capable enough to fool us. It is unclear if Leike et al. recognize this danger, but I think they argue that we will stay ahead of the AI through the alignment techniques produced by the researcher AI and that misgeneralization errors can always be detected by humans supported by smart enough AI assistants. However, how will we know if the assistants remain well-enough aligned[3]? And if they do, how do we know if they are smart enough to help us notice misalignment in the target AI?
Alignment research requires general intelligence - If the alignment researcher AI has enough general intelligence to make breakthrough discoveries in alignment, then you can't safely create it without already having solved alignment. Yet, Leike et al. hope that relatively narrow intelligence can already make significant progress on alignment. I think this is extremely unlikely if we reflect on what general intelligence truly is. Though my own thoughts on the nature of intelligence are not entirely coherent yet [LW · GW], I'd argue that having a strong concept of intelligence is key to accurately predicting the outcome of an alignment strategy.
Specifically in this case, my understanding is that general intelligence is being able to perform a wider set of operations on a wider set of inputs (to achieve a desired set of observations on the world state). For example, I can do addition of 2 apples I see, 2 apples I think about, 2 boats I hear about, 2 functions with all their subcomponents, etc. If you now teach me subtraction or multiplication or another transformation, then I can attempt to apply them to all of these inputs. This type of "folding" of operations across domains is the degree to which an intelligence is general instead of narrow.
The alignment problem needs high general intelligence, because it needs new ideas for solving alignment. It won’t be enough to input all the math around the alignment problem and have the AI solve that. It's a great improvement over what we have but it will only gain us speed, not insight. To generate new ideas, you need to include information from a new domain in order to discover a new transformation to apply to your original problem. That means the AI needs to be able to reason about other domains. And we don’t know in advance which domains will contain the insights for key transformations. Thus we will have to give the AI access to many domains before it will learn the right transformation to apply to the alignment problem.
Now, from an empiricist view, you might ask, what's the harm in trying to solve alignment with narrow intelligence anyway? If it doesn't work, then we just stop and do something else. I'd argue there are two types of harm though.
First, ungrounded optimism itself may shorten timelines by shifting risk assessments downward, which in turn increases competitive pressure among companies developing AI. Keeping AI development as slow as possible is a coordination problem that revolves around "how slow are we all willing to go to make sure AGI will be safe?". If one company "defects" by going more quickly, then all other companies are incentivized to drop their safety standards farther down in order to keep up. This mechanic is hard to counter, but at minimum one can choose to project the lowest level of optimism such that you can contribute to a culture of caution.
Secondly, if the alignment researcher AI is not producing useful alignment results, at what point would you stop adding a little more training data? At what point does it cross-over from too-narrow-to-be-useful to too-general-to-be-safe? Leike et al. expect there to be an area of useful and safe AI, but what would that look like? Incentives to push the AI ever so slightly more general to get a success will be very high, and you don't want to put that type of risk into a slippery-sloped incentive structure fueled by massive economic pressures.
Note on IDA - How does it deal with deconstructing cognitively uncontainable tasks? We should consider if such tasks contain elements across levels of deconstruction that we cannot anticipate, because we cannot cognitively contain them. This may be expressed in two ways: Either a task may not be safely decomposable at all (“atomically difficult”), or a task may have the property that humans may not be able to foresee how to deconstruct it such that all safety-relevant considerations will be covered by evaluation of the individual elements of the decomposition (even though such a decomposition may exist). I didn't find a discussion of this question in the literature, while it may be a necessary condition for this approach to be safe. I worry iteration wouldn't help either, because how would you test that you are capturing all information that is otherwise missed by a single human trying to work through the task? Additionally, the most crucial tests we can run on this problem require the AI to be running across cognitively uncontainable tasks, and thus we're already close to AGI. One counterargument is that there are tasks that are cognitively uncontainable to us but safe to run (like most larger software packages or complicated calculations). Conversely, there are also tasks that are cognitively containable to us where we can still easily be fooled (like any act of magic between humans -- you could understand it if you knew the trick, but you don't). However, it seems that it's far easier for us to miss safety-relevant considerations in task decomposition for tasks we can't cognitively contain than in those that we can.
Note on Evaluation is Easier than Generation - Is evaluation easier than generation when evaluating preferences, and does it increase the risk of deception? My understanding is that the claim is based on the P versus NP debate, where most likely it is the case that mathematical and computational solutions are easier to evaluate than generate. However, is it true that human minds work the same? Is it easier to evaluate if a pre-generated solution lives up to your preferences than a solution you generated yourself?
As an intuition pump, we can look at how most humans spend their leisure time. Generation of ideas on how to spend leisure time would be akin to sitting quietly, possibly meditatively, and seeing what suggestions emerge inside you on how to spend your time. Evaluation of ideas on how to spend leisure time would be like receiving a menu of options, and you go down the menu till you find an option you find agreeable enough (or you pick the most preferred option above a certain threshold value). In which case, do you think you would pick the option that you most endorse? When would you be the happiest? What are the pitfalls of each situation?
It is not clear to me that any situation in which our human preferences matter will be subject to "evaluation is easier than generation". Instead, I'd sooner worry our preferences will be lightly influenced over time, such that they take a different course all together as slight nudges accumulate. A simple and thoroughly researched example of this is priming, where a user is exposed to a stimulus that subconsciously shifts their responses to follow up stimuli. Priming effects can take place even unintentionally, and so any task that requires evaluation of preferences is sensitive to them. This problem becomes even more salient when we have an alignment researcher AI suggesting solutions that kind of plausibly give us what we want, but maybe not really. Basically, I worry that we are opening up a channel for AI to manipulate us in unrecoverable ways.
Which also segues into a concern about deception: Will we not be more easily deceived (intentional or not) by solutions we did not generate, but instead only evaluate? I don't have a fleshed out and specific instantiation of this yet, so I can only lightly touch on this consideration.
Red Lines & Recommendations
To address the two main problems outlined above, I would recommend diving more deeply into where we might expect these problems to show up. Are there red lines that we can precisely define, that if left uncrossed, keep us in the green? Specifically:
What does near-deception look like? OpenAI's DC gap is a first attempt at quantifying latent knowledge. Similarly, can we use other techniques to predict deception? If we are iterating anyway, can we develop high predictive accuracy on the current models? Presuming there is a continuous function of deception ability, then we could at least decide about the specific cut-off values of deceptive ability - the point at which we abort any given alignment attempt and go back to the drawing board.
What does general intelligence look like? OpenAI talks about an alignment researcher AI being narrow in the same breath as scaling up GPT models with human feedback. How are we defining narrow and general AI in this case? Is the plan to use a GPT-like model to do the alignment research? If not, then what is the "narrowness" threshold for AI that will not be crossed in order to keep the researcher AI in line?
In Review
Overall, my concern with the OpenAI alignment plan is three-fold. First, it doesn't contain guard rails that make sure we don't "iterate too close to the sun". Secondly, it sets an example of optimistic over-confidence that may accelerate capabilities progress. And lastly, it will not actually bring us closer to solving the hard parts of the alignment problem without inadvertedly bringing about AGI before we are ready.
So, how did I do at evaluating alignment strategies? I'd love to hear your thoughts! I'll be using the feedback I receive to decide on next steps in my skilling up journey. Either I'll continue working on ways to increase Human Collective Intelligence [LW · GW] so we can better tackle the alignment problem, or I'll pivot in a new direction.
Additionally, my thanks goes out to Erik Jenner, Leon Lang, and Richard Ngo for reviewing the first draft of this document. It helped me clarify a couple of ambiguous claims, actually drop two of them as incorrect, split my document in two, and avoid accidental strawmanning moves toward OpenAI/Leike et al. Thank you!
- ^
"rationalist" here refers to general rationalism and not LessWrongian rationalism. Though the two are very closely related, I'd like to avoid any associations particular to this community. I considered using a different term but "rationalism" is just what this view is called and introducing a new term was more likely add to the confusion than detract from it. Also, one can definitely be a mix of both rationalist and empiricist.
- ^
This meta-review article by Lambert et al. (2022) is amazing if you want to learn more about RLHF. It's so amazing I made this footnote just to increase your chances of clicking the link -- Click.
- ^
Erik Jenner introduced a key argument to me related to error accumulation in the iterative design of the AI assistants. I didn't generate or notice this argument myself, so I'm leaving it out of the analysis, but it's good one, I think.
7 comments
Comments sorted by top scores.
comment by Orpheus16 (akash-wasil) · 2023-01-28T19:41:37.909Z · LW(p) · GW(p)
Thanks for sharing this. I've been looking forward to your thoughts on OpenAI's plan, and I think you presented them succinctly/clearly. I found the "evaluation vs generation" section particularly interesting/novel.
One thought: I'm currently not convinced that we would need general intelligence in order to generate new alignment ideas.
The alignment problem needs high general intelligence, because it needs new ideas for solving alignment. It won’t be enough to input all the math around the alignment problem and have the AI solve that. It's a great improvement over what we have but it will only gain us speed, not insight.
It seems plausible to me that we could get original ideas out of systems that were subhuman in general intelligence but superhuman in particular domains.
Example 1: Superhuman in processing speed. Imagine an AI that never came up with any original thought on its own. But it has superhuman processing speed, so it comes up with ideas 10000X faster than us. It never comes up with an idea that humans wouldn't ever have been able to come up with, but it certainly unlocks a bunch of ideas that we wouldn't have discovered by 2030, or 2050, or whenever the point-of-no-return is.
Example 2: Superhuman in "creative idea generation". Anecdotally, some people are really good at generating lots of possible ideas, but they're not intelligent enough to be good at filtering them. I could imagine a safe AI system that is subhuman at idea filtering (or "pruning") but superhuman at idea generation (or "babbling").
Whether or not we will actually be able to produce such systems is a much harder question. I lack strong models of "how cognition works", and I wouldn't find it crazy if people with stronger models of cognition were like "wow, this is so unrealistic-- it's just not realistic for us to find an agent with superhuman creativity unless it's also superhuman at a bunch of other things and then it cuts through you like butter."
But at least conceptually, it seems plausible to me that we could get new ideas with systems that are narrowly intelligent in specific domains without requiring them to be generally intelligent. (And in fact, this is currently my greatest hope for AI-assisted alignment schemes).
Replies from: DarkSym↑ comment by Shoshannah Tekofsky (DarkSym) · 2023-01-30T23:27:11.399Z · LW(p) · GW(p)
Thanks!
And to both examples, how are you conceptualizing a "new idea"? Cause I suspect we don't have the same model on what an idea is.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2023-01-31T23:19:53.877Z · LW(p) · GW(p)
Good question. I'm using the term "idea" pretty loosely and glossily.
Things that would meet this vague definition of "idea":
- The ELK problem (like going from nothing to "ah, we'll need a way of eliciting latent knowledge from AIs")
- Identifying the ELK program as a priority/non-priority (generating the arguments/ideas that go from "this ELK thing exists" to "ah, I think ELK is one of the most important alignment directions" or "nope, this particular problem/approach doesn't matter much"
- An ELK proposal
- A specific modification to an ELK proposal that makes it 5% better.
So new ideas could include new problems/subproblems we haven't discovered, solutions/proposals, code to help us implement proposals, ideas that help us prioritize between approaches, etc.
How are you defining "idea" (or do you have a totally different way of looking at things)?
comment by Jan (jan-2) · 2023-01-30T00:37:46.421Z · LW(p) · GW(p)
Thanks for sharing your thoughts Shos! :)
comment by Rob Bensinger (RobbBB) · 2023-01-29T01:58:25.855Z · LW(p) · GW(p)
I enjoyed this post. :) A minor note:
"rationalist" here refers to general rationalism and not LessWrongian rationalism. Though the two are very closely related, I'd like to avoid any associations particular to this community.
I don't think philosopher-rationalism is closely related to LW rationalism at all. Philosopher-rationalism mostly has nothing to do with LW-rationalism, and where the two do importantly intersect it's often because LW-rationalism is siding with empiricism against rationalism. (See prototypical philosopher-rationalists like Plato, who thought sensory knowledge and observation were completely bogus, and Descartes, who thought probabilistic or uncertain knowledge was completely bogus.)
LW-rationalism is using the word "rational" in contrast to "irrational", more in line with the original meaning of the word "rationalist" [LW(p) · GW(p)]. It's not "rational" in contrast to "empirical". (If it were, it wouldn't be called "Bayesian" and we wouldn't care much about sensory updating.)
Replies from: DarkSym↑ comment by Shoshannah Tekofsky (DarkSym) · 2023-01-30T23:29:02.901Z · LW(p) · GW(p)
Thanks!
And I appreciate the correction -- I admit I was confused about this, and may not have done enough of a deep-dive to untangle this properly. Originally I wanted to say "empiricists versus theorists" but I'm not sure where I got the term "theorist" from either.
comment by Michael Thiessen (michael-thiessen) · 2023-10-05T19:20:21.315Z · LW(p) · GW(p)
It seems to me that the idea of scalable oversight itself was far easier to generate than to evaluate. If the idea had been generated by an alignment AI rather than various people independently suggesting similar strategies, would we be confident in our ability to evaluate it? Is there some reason to believe alignment AIs will generate ideas that are easier to evaluate than scalable alignment? What kind of output would we need to see to make an idea like scalable alignment easy to evaluate?