A Story of AI Risk: InstructGPT-N
post by peterbarnett · 2022-05-26T23:22:13.285Z · LW · GW · 0 commentsContents
Training Fine-tuning Examples Baking Physics Learned Algorithms Self-models Deception Do we get deceptive algorithms? Misaligned objectives Complexity None No comments
The story from my previous post [LW · GW] of how AI might develop a dangerously misaligned objective has so far been pretty abstract. I now want to put together a more concrete story of how I think things might go wrong. This risk model is based on a language model which has been fine tuned using reinforcement learning from human feedback, I’ll call this model InstructGPT-N.
This isn’t my most likely model of AI risk, this is more of a ‘minimum example’ which contains what I see as the core parts of the problem. I expect the real world to be more complicated and messy. Models will likely be trained on more than just text, and there may be multiple powerful AI systems simultaneously learning and acting in the real world.
Training
We start by training a large language model using self-supervised learning for next word prediction. This is a standard GPT system, where you feed in the start of a sequence of words/tokens and it predicts what comes next, and then you input a new sequence which now includes the word it just guessed, and so on. The output is fed back into the system to generate the next word.
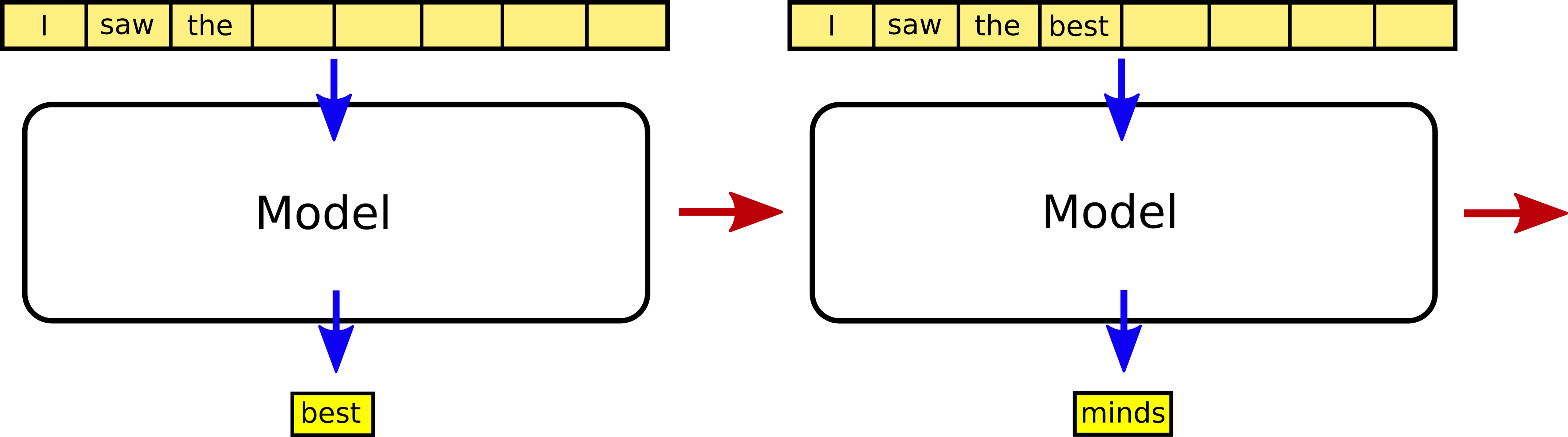
To train the system, we start with a sequence of text and feed in the first word. We then update the system based on how accurately it predicted the second word. Then we feed in the first two words, and update the system to better predict the third word; then we feed in the first 3 words and update to better predict the fourth word, and so on. This trains the system to predict which word comes next, given some starting prompt.
This system is trained on a lot of text; a large fraction of the internet, every digitized scientific paper, all of Github and Stack Exchange, millions of novels and textbooks, billions of lines of chat logs and internet forums.
Because the system is trained on such an expansive corpus of text it is probably pretty bad at directly answering questions that humans ask it; only a tiny amount of the training data is in the question/answer format. Despite this, the model does have a lot of knowledge inside it; some part ‘knows’ how to code well, some part ‘knows’ all about human psychology and power dynamics, some part ‘knows’ about large language models and how they are trained. The model also ‘knows’ how to behave as if it is not competent; if you prompt it to mimic the behavior of a beginner programmer or a pseudo-history fan with bad epistemics then this is what it will do. The system hasn’t been trained to be correct, it has been trained to mimic text. Even if we don’t deliberately prompt it to answer incorrectly or misleadingly, it may still do this if the training data contained incorrect or misleading text (which is true of a lot of internet text). For this model to be useful to humans, it will be fine-tuned to consistently behave competently for tasks humans care about.
Fine-tuning
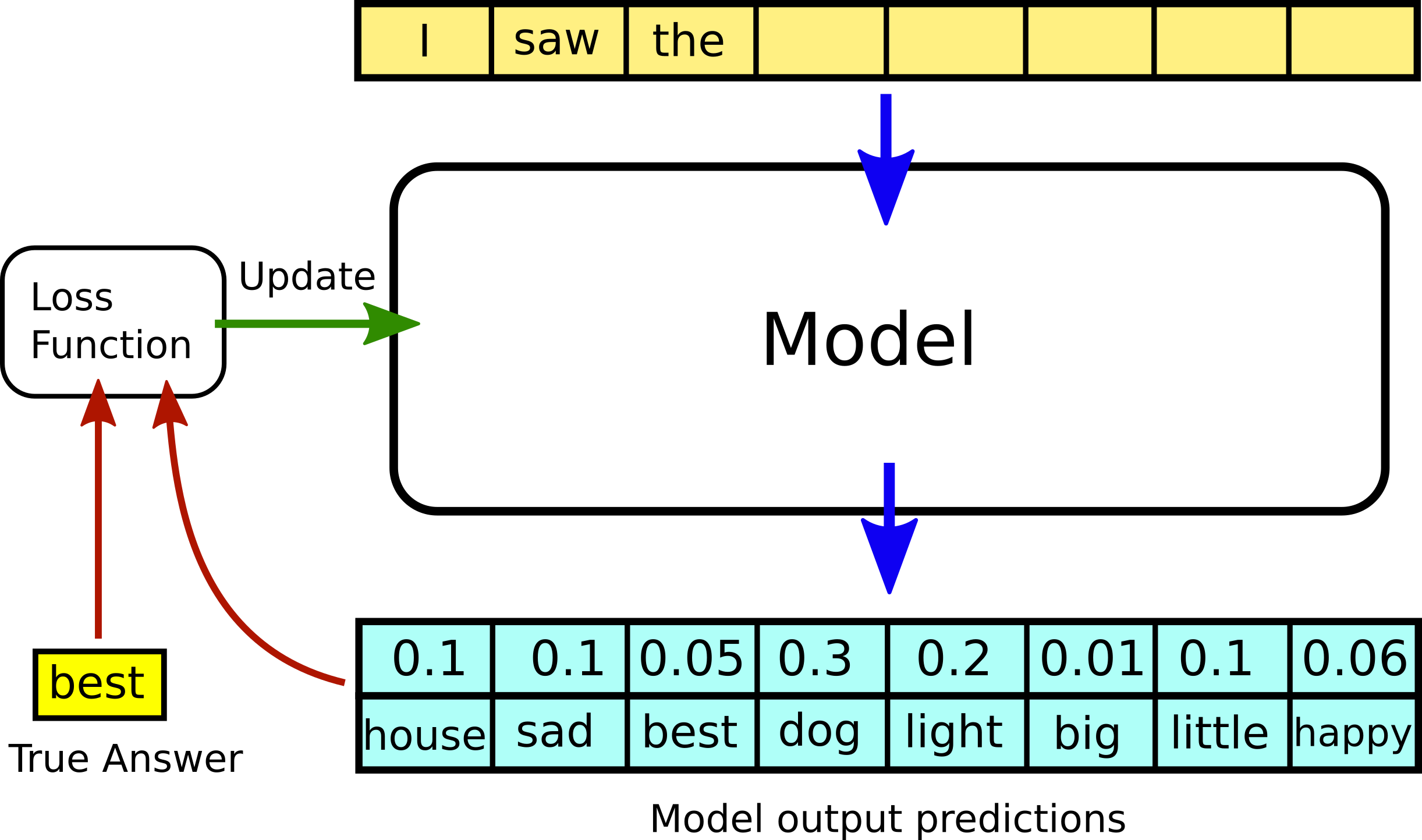
To make this model useful for answering questions, the humans fine-tune it on human feedback. Here, the human asks a question, sees what the AI answers, and then gives a reward based on how good they think the AI’s answer was. This lets the humans take an AI model which has a lot of ‘internal knowledge’ but isn’t very good at answering questions, and turn it into a model which can use this internal knowledge to answer questions. The model is trained to perform well on sequences of questions, because this is more useful than just answering one disconnected question at a time. Here the human asks a question, receives an answer from the AI, and the human can then ask another question, and so on.
Examples
Baking
Human: What is a good egg replacement for a cake I am baking for my vegan friends?
AI: You can replace 1 egg with a mixture of 1 Tablespoon of ground flaxseed and 3 Tablespoons of water.
Human: How will that change the flavor of the cake?
AI: It will add a slightly nutty flavor, if you want a more neutral flavor you can use chia seeds instead of flaxseed.
Physics
Human: Can you explain Newton’s second law to me?
AI: Newton’s second law states that the change in momentum of an object is proportional to the force applied to the object. So when you apply a force to an object, it will begin to accelerate in the direction of the applied force.
Human: How does this relate to the equation ?
AI: Momentum (denoted by ) is equal to the mass times the velocity of an object . Force is equal to the change momentum, or more specifically the derivative of the momentum with respect to time . Acceleration is the change in velocity with respect to time . Putting this together we arrive at .
Human: What happens when you apply multiple forces to an object?
AI: When you apply multiple forces to an object you can simply add values of the forces together to find the net force applied. It is important to remember that force is a vector, and so you need to add the vectors together, not sum the magnitude of the forces.
Human: Can you give me an example?
AI: If one robot pushes a box in the x-direction with 3 newtons of force, and another robot pushes in the y-direction with 1 newton of force, then the total force vector (in units of newtons) will be (3, 1).
Or if there is a box which has 10 newtons of force down due to gravity, and a human applies 15 newtons of force upwards to lift it, then the box will have a net force upwards of -10 N + 15 N = 5 N, causing it to accelerate upwards.
Learned Algorithms
There are a few different algorithms which the model could learn which do well on the training distribution (where the training distribution is the human asking questions and giving rewards):
- A heuristic based, non-optimizing algorithm which just does robustly well on the training distribution (and maybe also does well when deployed).
- An algorithm which internally searches over/optimizes possible outputs and evaluates them based on the criterion “How much would a human like this answer?”
- An algorithm which internally searches over possible outputs and evaluates them based on the criterion “What is the expected reward a human would give this answer?”
- An algorithm which internally searches over possible outputs and evaluates them based on the criterion “What is the expected reward a human would give this answer, conditional on them being contracted to train an AI model, and on me being that AI model?”
- An algorithm which runs something like “I want the state of the world to be X, which output should I give so that the human training me doesn’t turn me off or modify me, so that I can then defect after training?”
- Probably others
As the tasks become more complicated (the human asks more difficult and varied questions), this will push the system into performing some kind of optimization/internal search process and away from standard mechanistic algorithms which aren’t performing optimization. This is because it is difficult to compress heuristics for extremely varied tasks into a limited number of parameters. Hence we are likely to end up with an AI system which finds its output by evaluating potential outputs on some internal objective.
A better specified objective (an objective which is more detailed and also doesn’t rely on incorrect assumptions) will lead to better performance on the training distribution. If the objective is “How much would a human like this answer?”, this will lead to worse performance (lower reward from the human) than the objective of “What is the expected reward the human would give this answer, conditional on them being contracted to train an AI, and on me being that AI model?” This more specific objective will lead to higher reward because it allows the AI to leverage its knowledge of how people train AI’s, what kind of people train AI’s, and what particular kinds of biases and preferences the AI trainers have.
Self-models
It seems instrumentally useful for the AI to develop a self-model and some concept of the humans training it, because these will allow it to reason about itself and the training process. These concepts (the self-model and the concept of the current training process) are more than just ‘there are GPT language model systems, and humans train them’, which would have just existed in the pretraining corpus. These concepts refer explicitly to the AI itself and the training process it is in, rather than some abstract AI system. Even if none of the fine-tuning questions that the human asks include references to the AI or the training, knowing about these things will let the AI perform better in training. And so gradient descent may allow it to use its world model and knowledge of AI systems to develop this self-model, simply because this leads to better performance on the training distribution.
One additional reason for the AI to develop a self-model and realize it is an AI in a training process, is that this is actually true. We could potentially model the training process as approximating some Bayesian updating process. We start out with a set of hypotheses which may or may not be true, and then update the probabilities assigned to these hypotheses as we get additional evidence. Because the AI actually is an AI in a training process, the probability assigned to this hypothesis will eventually get upweighted as the system learns.
Deception
The real danger comes when we are not sure whether the AI system is evaluating its outputs based on “Would a human training an AI system give this a high score, assuming that I am that AI system?” or “Would this output lead to the ultimate state of the world (including after training) being X?”
The second option could mean that the AI acts as a deceptive consequentialist, where it may ‘lie dormant’ and play along, pretending to be using the other (aligned) algorithm. Or even more perversely, the AI could use its outputs to subtly manipulate the human training it; this could allow the AI to be updated in even more malign ways. This second, more malign option seems possible because the AI has a lot of ‘knowledge’ about human psychology in its world model from the pretraining; both from many academic works on psychology and also from unimaginably many records of human interactions.
Do we get deceptive algorithms?
It seems unclear whether we end up with a deceptive algorithm rather than an aligned version. One reason to expect a deceptive algorithm is that any consequentialist algorithm that the training process finds has an incentive to be deceptive, unless it is already precisely aligned to begin with. And so once the model becomes deceptive it will attempt to stay that way and avoid having its objectives modified. There are also many misaligned objectives that could be learned, while there is only one aligned objective (or at least aligned objectives make up a much smaller portion of possible objectives).
Misaligned objectives
As an example of how an AI could develop a misaligned objective, we could imagine it learning an incorrect model of human preferences. Suppose that one of the humans training the AI has a particular affinity for flowers, and hence gives the AI more reward for answers which result in there being more flowers in the world. The AI may learn to terminally value flowers, rather than terminally valuing providing useful answers to a human’s questions. Once the AI has started to value flowers, it doesn’t care what values the human is trying to instill into it. Its objective is its objective, regardless of how much the human dislikes this.
This problem of learning an incorrect model of human preferences is amplified when we consider the specifics of how reinforcement learning from human preferences works in practice. Human feedback/rewards are expensive (because a human actually has to be in the loop), so instead we train a separate model to predict what reward the human would provide. This reward model is then used to fine-tune the language model AI. If this learned reward model is misspecified then it may cause the AI to learn a misaligned objective. Even if the reward model is updated over time to become more accurate, this will not matter if the AI has already developed a misaligned objective from an early (bad) version of the reward model.
Complexity
Something that points against this is that these deceptive algorithms are in some sense more complex than the aligned algorithm. A deceptive algorithm has to reason about its objectives in the world and then also reason about what the human wants, while the aligned algorithm only has to reason about what the human wants. It is unclear where this balance between the number of misaligned objectives and the simplicity of the aligned objectives falls. I think it seems more likely that by default we end up with a misaligned algorithm, partially because once we find one of these algorithms it will ‘fight’ against any attempt to remove it.
But even if we were ‘more likely’ to end up with an aligned model, I don’t like betting the future on something which is merely ‘more likely’.
Thanks to Oliver Sourbut for very useful feedback on this post.
In the next post I'll try to lay out some confusions round my picture of AI risk, and some reasons why it may be wrong or confused.
0 comments
Comments sorted by top scores.