Using machine learning to predict romantic compatibility: empirical results
post by JonahS (JonahSinick) · 2014-12-17T02:54:42.900Z · LW · GW · Legacy · 18 commentsContents
Overview Context on the dataset Why ratings add incremental predictive power Gender Differences A composite index to closely approximate a ratee’s desirability Fun and intelligence as positive predictors when the rater is a woman Ratees’ sincerity as an incremental negative predictor Desirability as a signal of selectivity The predictive power that we obtain None 18 comments
Overview
For many people, having a satisfying romantic relationship is one of the most important aspects of life. Over the past 10 years, online dating websites have gained traction, and dating websites have access to large amounts of data that could be used to build predictive models to achieve this goal. Such data is seldom public, but Columbia business school professors Ray Fisman and Sheena Iyengar compiled a rich and relevant data set for their paper Gender Differences in Mate Selection: Evidence From a Speed Dating Experiment. Their main results were:
Women put greater weight on the intelligence and the race of partner, while men respond more to physical attractiveness. Moreover, men do not value women’s intelligence or ambition when it exceeds their own. Also, we find that women exhibit a preference for men who grew up in affluent neighborhoods. Finally, male selectivity is invariant to group size, while female selectivity is strongly increasing in group size.
I found the study through Andrew Gelman’s blog, where he wrote:
What I really want to do with these data is what I suggested to Ray and Sheena several years ago when they first told me about the study: a multilevel model that allows preferences to vary by person, not just by sex. Multilevel modeling would definitely be useful here, since you have something like 10 binary observations and 6 parameters to estimate for each person.
Several months ago I decided to pursue a career in data science, and with a view toward building my skills, I worked to build a model to predict when an individual participant will express interest in seeing a given partner again. Along with the goal of learning, I had the dual intent of contributing knowledge that had the potential, however slight, to help people find satisfying romantic relationships.
It’s unlikely that what I did will have practical applications (as basic research seldom does), but I did learn a great deal about many things, most having to do with data science methodology in general, but also some about human behavior.
This is the first of a series of posts where I report on my findings. A linear narrative would degenerate to a sprawling blog post that would be of little interest to anybody but me. In this post, I’ll restrict focus to the question: how much predictive power can we get by estimating the generic selectivity and desirability of the people involved, without using information about the interactions between their traits?
I’ll ultimately go into the details of the methodology that I used, including discussion of statistical significance, the rationale for making the decisions that I did the, and links to relevant code, but here I’ll suppress technical detail in favor of relegating it to separate blog posts that might be of interest to a more specialized audience. In several places I speculate as to the meaning of the results. I’ve made efforts to subject my reasoning to cross checks, but haven’t gotten almost any external feedback yet, and I’d welcome counter considerations, alternative hypotheses, etc. I’m aware that there are places where claims that I make don’t logically follow from what precedes them, and I’m not so much looking for examples of this in general as much as I am instances where there’s a sizable probability that I’ve missed something that alters the bottom line conclusions.
Context on the dataset
The dataset was derived from 21 round-robin speed dating events held for Columbia graduate students, each attended by between 6 to 22 participants of each gender. To avoid small sample size issues, I restricted consideration to the 9 events with 14 or more people. These consisted of ~2500 speed dates, involving a total of ~160 participants of each gender. The subset that I looked at contains events that the authors of the original study excluded in their own paper because they involved the experimental intervention of asking subjects to bring a book to the event. The effect size of the intervention was small enough so that it doesn’t alter bottom line conclusions.
The dataset has a large number of features. I found that their predictive power was almost all contained in participants’ ratings of one another, which extended beyond a “yes/no” decision, also including ratings on dimensions such as attractiveness, sincerity, intelligence, fun and ambition. For brevity I’ll refer to the person who made decision as the “rater” and his or her partner as the “ratee.” The core features that I used were essentially:
- The frequency with which the rater’s decision on other ratees was ‘yes.’
- The frequency with which other raters' decision on the ratee was ‘yes.’
- Averages of ratings that others gave the rater and ratee.
The actual features that I used were slightly modified versions of these. I’ll give details in a future post.
Why ratings add incremental predictive power
In this blog post I’m restricting consideration to signals of the partners’ general selectivity and general desirability, without considering how their traits interact. First approximations to a participant’s desirability and selectivity come from the frequency with which members of the opposite sex expressed to see them again, and the frequency with which the participant expressed interest in seeing members of the opposite sex again.
If the dataset contained information on a sufficiently large number of dates for each participant, we could not improve on using these. But the number of dates that each participant went on was small enough so that the decision frequencies are noisy, and we can do better by supplementing them with other features. There’s a gender asymmetry to the situation: on average, men said yes 48.5% of the time and woman said yes 33.5% of the time, which means that the decision frequency metrics are noisier than is otherwise the case when the rater is a woman and the ratee is a man, so there’s more room for improvement when predicting women’s decisions than there is when predicting men’s decisions.
It’s in principle possible for the average of a single type of rating to carry more information than decision frequencies. This is because the ratings were given on a scale from 1 to 10, whereas decisions have only two possible values (yes and no). This means that ratings can (in principle) reflect desirability or lack thereof at a greater level of granularity than decisions. As an example of this, if a rater has impossibly high standards and rejects everyone, the rater's decisions carry no information about the ratees, but the rater's ratings of ratees still contain relevant information that we can use to better estimate ratee desirability.
The ratings that are most useful are those that correlate best with decisions. To this end, we examine correlations between average ratings and individual decisions. We also look at correlations between average ratings of each type and individual ratings of each type, to get a sense for the degree to which the ratings are independent, and the degree to which there tends to be a consensus as to whether somebody possesses a given trait. In the figures below, we’re abbreviate the ratings of different types owing to space considerations. The abbreviations are given by the following dictionary:
dec ---> the rater’s decision
like ---> how much a rater liked a ratee overall
attr ---> the ratee’s attractiveness
fun ---> how fun the ratee is
amb ---> the ratee’s ambition
intel ---> the ratee’s intelligence
sinc ---> the ratee’s sincerity
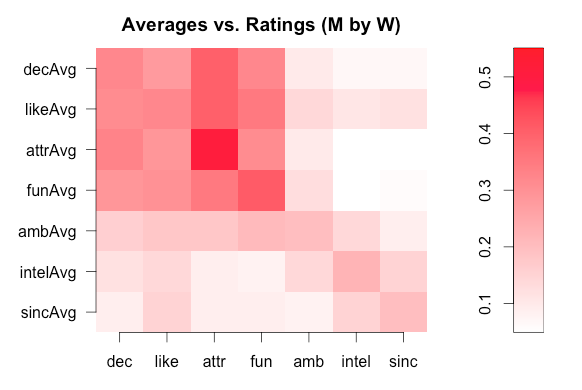
The image below matrix shows the correlations when the ratee is a woman and the raters are men. The rows of the figure correspond to the ratee’s average ratings, and the columns correspond to individual rater’s ratings:

As the scale on the right indicates, darker shades of red correspond to stronger correlations. Three things to highlight are:
- The correlations are positive: higher ratings on one direction are always associated with higher ratings on all dimensions. Even the squares that might initially appear to be white are in fact very faintly red. So ratings of a given type contain information about ratings of other types.
- Consider the 5x5 square in the lower right, which corresponds to interrelations between attractiveness, fun, ambition, intelligence and sincerity. For each column, the square with the darkest shade of red is the square on the diagonal. This corresponds to the fact that given a rating type R, the average rating that’s most predictive of R is the average of R itself.
- Consider the leftmost column, which corresponds to individual men’s decisions. The darkest shades of red correspond to the average of other men’s decisions on a woman, the average of their ratings of how much they like her overall, and their ratings of her attractiveness. Moreover, these three squares are essentially the same shade of red as one another, corresponding to the three averages having equal predictive power.
- Consider the intersection between the top 3 rows and the rightmost 4 columns. The darkest shades of red appear in the "liking" row and the lightest shades of red appear in the "attractiveness" row. This corresponds to how much a man likes a woman general reflecting a broader range of his or her characteristics than just physical attractiveness, and this being true of his receptiveness to dating her as well, but to a lesser degree.
Each of these observations deserves comment:
- It seems implausible to me that each of the 10 distinct correlations between the five traits of attractiveness, fun, ambition, intelligence and sincerity is positive. The first thing that jumped to mind when I saw the correlation matrix was the Halo Effect: people’s positive perceptions of people on one dimension tend to spill over and affect their perceptions of the person on all dimensions. Here the role of attractiveness specifically has been highlighted. Later on we’ll see evidence that the halo effect is in fact a contributing factor.
But one also can’t dismiss the possibility that the correlations between the ratings are partially driven by correlations between the underlying traits. As a concrete hypothetical, quality of early childhood nutrition could potentially impact all five dimensions.
The slightest correlations between ratings are also sufficiently small so that one can imagine them reflecting genuine correlations between the underlying traits without them being large enough for us to notice in our day to day experience.
One can also imagine the ratings understating correlations between the different traits owing to anchoring biases: if two people are the same on one dimension D, and one of them is very high on another dimension D’, the one with very high D’ could be rated lower on D because the degree to which he or she possesses D looks small relative to the degree to which he or she possesses D’.
- In view of the Halo Effect, one could imagine that ratings of a given type are essentially noise, picking up only on the degree to which someone possesses other traits. One could also imagine a rating type being ill-defined on account of there being no consensus on what the word means.
The fact that the average consensus on how much someone possesses each trait is the most predictive of individual ratings of that trait strongly suggests that the 5 different rating types are in fact picking up on 5 distinct traits. They might not be the traits that come to mind when we think of the words: for example, it could be that the distinct underlying trait that intelligence ratings are picking up on is “wears glasses.” But if men give a woman high ratings on intelligence and not sincerity (for example), it means something. - At least two of the “decision,” “liking,” and “attractiveness” averages reflect different things, as one can see from the differences in how they correlate with other traits. But they correlate well with one another, and when it comes to using them to predict decisions, one gets a close approximation to the truth if one adopts the view that they’re essentially measures of the same thing.
- The "liking" average captures some of the predictive power of the fun, ambition, intelligence and sincerity ratings, but it reflects sincerity too much from the point of view of predicting decisions.
With (3) in mind, we obtain our first conclusion, one totally uncontroversial in some circles, though not all:
On average, of the five dimensions on which men rated women, the one that most drove men’s decisions on a woman is her attractiveness. The gap between the predictive power of attractiveness and the predictive power of the other traits is large. “Fun,” is the closest to attractiveness in predictive power, but the predictive power may derive in part from attractive women being perceived as more fun.
Gender Differences
So far I’ve only discussed men’s preferences. The analysis above applies to women’s preferences nearly word for word: to a first approximation, the table for women and the table for men are identical to one another.
How surprising this is to the reader will depend on his or her assumptions about the world. As a thought experiment, you might ask yourself: suppose that you had generated the two images without giving them headings, and had only examined one of them. If you later came across the other on your computer without remembering which it was, how confident would you be that it was the one that you had already seen?
The correlation matrixes give the impression of contradicting a claim in the original study:
Women put greater weight on the intelligence [...] while men respond more to physical attractiveness.
The apparent contradiction is explained by the fact that the subsets of events that I used were different from the subset of events that the authors reported on in their paper. On one hand, I omitted the events with fewer than 14 people. On the other hand, the authors omitted others:
Seven have been omitted...four because they involved an experimental intervention where participants were asked to bring their favorite book. These four sessions were run specifically to study how decision weights and selectivity would be affected by an intervention designed to shift subjects’ attention away from superficial physical attributes.
The intervention of asking participants to bring their favorite book seems to have had the intended effect. One could argue that the sample that I used is unrepresentative on account of the intervention. But to my mind, the intervention falls within the range of heterogeneity that one might expect across real world events, and it’s unclear to me that the events without the intervention give a better sense for gender differences in mate selection across contexts than the events with the intervention do.
A priori one might still be concerned that my choice of sample would lead to me developing a model that gives too much weight to intelligence when the rater is a man. But I chose the features that I did specifically with the intent of creating a model that would work well across heterogeneous speed dating events, and made no use of intelligence ratings to predict men's decisions.
There are some gender differences in the correlations even in the sample that I use – in particular, the correlations tend to be stronger when the rater is male. This could be because of actual differences in preferences, or because of differences with respect to susceptibility to the halo effect, or a number of other things.
Whatever the case may be, the first three points that I made about the correlation matrix for male raters are also true of the correlation matrix for female raters.
The fourth point needs to be supplemented by the observation that from the point of view of predicting decisions, when the raters are women, not only do the "liking" ratings reflect the sincerity ratings too much, they also reflect the ambition and intelligence ratings too much.
A composite index to closely approximate a ratee’s desirability
When the rater is a man, the liking average captures the predictive power present in the fun, ambition, and intelligence averages, and we lose nothing by dropping them. We would like to use all three of the most predictive averages, decision, liking and attractiveness to predict men's decisions. But the three vary in predictive power from event to event, and if we use all three we end up overfitting and get suboptimal results. Inspired by the fact that their predictive power is roughly equal, when the raters are men, we simply average the three to form a composite index of a woman’s desirability. Using it in a model gives better results than using any combination of the three individually.
When the raters are women, the liking average does a poor job of picking up on the predictive power of the attractiveness, fun, ambition, intelligence and sincerity to the right degrees. So in this case, we form the same composite index as the composite index for men, but without omitting the liking average
Fun and intelligence as positive predictors when the rater is a woman
When the rater is a woman, the fun average gives substantial incremental power (moreso than when the rater is a man, even when we don't include the 'liking' average in the composite index when predicting his decision), and we include it. The ambition average offers no additional predictive power. We get a little bit more predictive power by including the intelligence average. It's nearly negligible until we make the modification described below.
Ratees’ sincerity as an incremental negative predictor
While the ratees’ average sincerity ratings are correlated with the raters’ decisions being yes, the effect vanishes after we control for the decision and attractiveness averages, suggesting that the sincerity/decision correlation is driven by the halo effect rather than by people’s decisions being influenced by genuine sincerity.
As mentioned above, liking average is more strongly correlated with the sincerity average than the decision average is, and so when the rater is man, our composite index of a woman’s desirability is weakened by the fact that it indirectly picks up on sincerity.
Similarly, the predictive power of the intelligence average that we included to predict women's decisions is degraded by the fact that it indirectly picks up on sincerity ratings.
We can correct for this problem by including the sincerity averages in our model to control for them: this allows for our model to give more weight to the factors that actually drive decision than it would otherwise be able to.
Desirability as a signal of selectivity
More desirable people are more selective. This is nearly a tautology in general, and doesn’t necessarily reflect snobbishness: barring polyamory, somebody with many suitors has to reject a larger percentage of them than somebody with few. The pattern is present in the dataset, even though raters were generally allowed to decide yes on as many people as they wanted to.
I found that a ratee's selectivity didn’t consistently yield incremental predictive power of the ratee's desirability, but so far we only used one metric of the rater’s selectivity, and we can improve on it by adding a measure of the rater’s desirability. For this I simply used the man’s composite desirability index when the rater is a man. When the rater is a woman, the composite index includes the average of “liking” ratings given to women, which in turn reflects traits such as ambition, intelligence and sincerity which may affect selectivity for reasons unrelated to the woman’s desirability. So we use the version of the composite index that excludes the “liking” rating averages.
The effect is largely restricted to raters of below average desirability: the rise in selectivity generally flattens out once one passes to consideration of people who are of above average desirability. It’s unclear to me why this should be so. My best guess is that there’s an extroversion/desirability connection that emerges at the upper end of the spectrum of desirability, which dampened the connection between desirability and selectivity in this study.
The predictive power that we obtain
Recall that men’s decision were yes for 48% of the dates in the sample, and women’s decisions were yes for 33% of the dates in the sample. Matches occurred 15.5% of the time. These establish baselines that we can judge our model against: if we predicted that everyone rejected everyone, the error rates would simply be the percentages listed. Using the features that I allude to above, I obtained predictions with the error rates indicated in the table below:
|
Total Error |
False Positives |
False Negs |
% Yes Found |
|
|
Women by Men |
25.1% |
25.3% |
24.8% |
72.8% |
|
Men by Women |
23.9% |
31.6% |
20.9% |
54.2% |
|
Matches |
14.3% |
37.3% |
13.3% |
17.2% |
In my next post I’ll expand the model to include interactions between individual men’s traits and individual women’s traits.
18 comments
Comments sorted by top scores.
comment by benkuhn · 2014-12-18T01:46:40.501Z · LW(p) · GW(p)
Nice writeup! A couple comments:
If the dataset contained information on a sufficiently large number of dates for each participant, we could not improve on using [frequency with which members of the opposite sex expressed to see them again, and the frequency with which the participant expressed interest in seeing members of the opposite sex again].
I don't think this is true. Consider the following model:
- There is only one feature, eye color. The population is split 50-50 between brown and blue eyes. People want to date other people iff they are of the same eye color. Everyone's ratings of eye color are perfect.
In this case, with only selectivity ratings, you can't do better than 50% accuracy (any person wants to date any other person with 50% probability). But with eye-color ratings, you can get it perfect.
[correlation heatmap]
My impression is that there are significant structural correlations in your data that I don't really understand the impact of. (For instance, at least if everyone rates everyone, I think the correlation of attr with attrAvg is guaranteed to be positive, even if attr is completely random.)
As a result, I'm having a hard time interpreting things like the fact that likeAvg is more strongly correlated with attr than with like. I'm also having a hard time verifying your interpretations of the observations that you make about this heatmap, because I'm not sure to what extent they are confounded by the structural correlations.
It seems implausible to me that each of the 25 correlations between the five traits of attractiveness, fun, ambition, intelligence and sincerity is positive.
Nitpick: There are only 10 distinct such correlations that are not 1 by definition.
The predictive power that we obtain
Model accuracy actually isn't actually a great measure of predictive power, because it's sensitive to base rates. (You at least mentioned the base rates, but it's still hard to know how much to correct for the base rates when you're interpreting the goodness of a classifier.)
As far as I know, if you don't have a utility function, scoring classifiers in an interpretable way is still kind of an open problem, but you could look at ROC AUC as a still-interpretable but somewhat nicer summary statistic of model performance.
Replies from: RyanCarey, JonahSinick↑ comment by RyanCarey · 2014-12-18T07:00:40.750Z · LW(p) · GW(p)
Model accuracy actually isn't actually a great measure of predictive power, because it's sensitive to base rates.
I was told that you only run into severe problems with model accuracy if the base rates are far from 50%. Accuracy feels pretty interpretable and meaningful here as the base rates are 30%-50%.
As far as I know, if you don't have a utility function, scoring classifiers in an interpretable way is still kind of an open problem, but you could look at ROC AUC as a still-interpretable but somewhat nicer summary statistic of model performance.
Although ROC area under curve seems to have an awkward downside in that it penalises you for having poor prediction even when you set the sensitivity (the threshold) to a bad parameter. The F Score is pretty simple, and doesn't have this drawback - it's just a combination of some fixed sensitivity and specificity.
As you point out, there is ongoing research and discussion of this, which is confusing because as far as math goes, it doesn't seem like that hard of a problem.
Replies from: benkuhn↑ comment by benkuhn · 2014-12-18T08:37:04.475Z · LW(p) · GW(p)
I was told that you only run into severe problems with model accuracy if the base rates are far from 50%. Accuracy feels pretty interpretable and meaningful here as the base rates are 30%-50%.
It depends on how much signal there is in your data. If the base rate is 60%, but there's so little signal in the data that the Bayes-optimal predictions only vary between 55% and 65%, then even a perfect model isn't going to do any better than chance on accuracy. Meanwhile the perfect model will have a poor AUC but at least one that is significantly different from baseline.
[ROC AUC] penalises you for having poor prediction even when you set the sensitivity (the threshold) to a bad parameter. The F Score is pretty simple, and doesn't have this drawback - it's just a combination of some fixed sensitivity and specificity.
I'm not really sure what you mean by this. There's no such thing as an objectively "bad parameter" for sensitivity (well, unless your ROC curve is non-convex); it depends on the relative cost of type I and type II errors.
The F score isn't comparable to AUC since the F score is defined for binary classifiers and the ROC AUC is only really meaningful for probabilistic classifiers (or I guess non-probabilitstic score-based ones like uncalibrated SVMs). To get an F score for a binary classifier you have to pick a single threshold, which seems even worse to me than any supposed penalization for picking "bad sensitivities."
there is ongoing research and discussion of this, which is confusing because as far as math goes, it doesn't seem like that hard of a problem.
Because different utility functions can rank models differently, the problem "find a utility-function-independent model statistic that is good at ranking classifiers" is ill-posed. A lot of debates over model scoring statistics seem to cash out to debates over which statistics seem to produce model selection that works well robustly over common real-world utility functions.
Replies from: RyanCarey↑ comment by RyanCarey · 2014-12-18T14:37:42.236Z · LW(p) · GW(p)
It depends on how much signal there is in your data. If the base rate is 60%, but there's so little signal in the data that the Bayes-optimal predictions only vary between 55% and 65%, then even a perfect model isn't going to do any better than chance on accuracy.
Makes sense.
I'm not really sure what you mean by this. There's no such thing as an objectively "bad parameter" for sensitivity (well, unless your ROC curve is non-convex); it depends on the relative cost of type I and type II errors.
I think they both have their strengths and weaknesses. When you give your model to a non-statistician to use, you'll set a decision threshold. If the ROC curve is non-convex, then yes, some regions are strictly dominated by others. Then area under the curve is a broken metric because it gives some weight to completely useless areas. You could replace the dud areas with the bits that they're dominated by, but that's inelegant. If the second derivative is near zero, then AUC still cares too much about regions that will still only be used for an extreme utility function.
So in a way it's better to take a balanced F1 score, and maximise it. Then, you're ignoring the performance of the model at implausible decision thresholds. If you are implicitly using a very wrong utility function, then at least people can easily call you out on it.
For example, here the two models have similar AUC but for the range of decision thresholds that you would plausibly set the blue model, blue is better - at least it's clearly good at something.
{kind=link}
Obviously, ROC has its advantages too and may be better overall, I'm just pointing out a couple of overlooked strengths of the simpler metric.
Because different utility functions can rank models differently, the problem "find a utility-function-independent model statistic that is good at ranking classifiers" is ill-posed. A lot of debates over model scoring statistics seem to cash out to debates over which statistics seem to produce model selection that works well robustly over common real-world utility functions.
Yes.
↑ comment by JonahS (JonahSinick) · 2014-12-18T04:11:30.891Z · LW(p) · GW(p)
Thanks Ben!
In this case, with only selectivity ratings, you can't do better than 50% accuracy (any person wants to date any other person with 50% probability). But with eye-color ratings, you can get it perfect.
Edit: I initially misread your remark. I tried to clarify the setup with:
In this blog post I’m restricting consideration to signals of the partners’ general selectivity and general desirability, without considering how their traits interact.
Is this ambiguous?
My impression is that there are significant structural correlations in your data that I don't really understand the impact of. (For instance, at least if everyone rates everyone, I think the correlation of attr with attrAvg is guaranteed to be positive, even if attr is completely random.)
I may not fully parse what you have in mind, but I excluded the rater and ratee from the averages. This turns out not to be enough to avoid contamination for subtle reasons, so I made a further modification. I'll be discussing this later, but if you're wondering about this particular point, I'd be happy to now.
The relevant code is here. Your remark prompted me to check my code by replacing the ratings with random numbers drawn from a normal distribution. Using 7 ratings and 7 averages, the mean correlation is 0.003, with 23 negative and 26 positive.
Nitpick: There are only 10 distinct such correlations that are not 1 by definition.
Thanks, that was an oversight on my part. I've edited the text.
Model accuracy actually isn't actually a great measure of predictive power, because it's sensitive to base rates. (You at least mentioned the base rates, but it's still hard to know how much to correct for the base rates when you're interpreting the goodness of a classifier.)
I suppressed technical detail in this first post to make it more easily accessible to a general audience. I'm not sure whether this answers your question, but I used log loss as a measure of accuracy. The differentials were (approximately, the actual final figures are lower):
For Men: ~0.690 to ~0.500. For Women: ~0.635 to ~0.567. For Matches: ~0.432 to ~0.349
I'll also be giving figures within the framework of recommendation systems in a later post.
As far as I know, if you don't have a utility function, scoring classifiers in an interpretable way is still kind of an open problem, but you could look at ROC AUC as a still-interpretable but somewhat nicer summary statistic of model performance.
Thanks, I've been meaning to look into this.
Replies from: benkuhn↑ comment by benkuhn · 2014-12-18T06:04:56.428Z · LW(p) · GW(p)
Is this ambiguous?
It wasn't clear that this applied to the statement "we couldn't improve on using these" (mainly because I forgot you weren't considering interactions).
I excluded the rater and ratee from the averages.
Okay, that gets rid of most of my worries. I'm not sure it account for covariance between correlation estimates of different averages, so I'd be interested in seeing some bootstrapped confidence intervals). But perhaps I'm preempting future posts.
Also, thinking about it more, you point out a number of differences between correlations, and it's not clear to me that those differences are significant as opposed to just noise.
I'm not sure whether this answers your question, but I used log loss as a measure of accuracy.
I was using "accuracy" in the technical sense, i.e., one minus what you call "Total Error" in your table. (It's unfortunate that Wikipedia says scoring rules like log-loss are a measure of the "accuracy" of predictions! I believe the technical usage, that is, percentage properly classified for a binary classifier, is a more common usage in machine learning.)
The total error of a model is in general not super informative because it depends on the base rate of each class in your data, as well as the threshold that you choose to convert your probabilistic classifier into a binary one. That's why I generally prefer to see likelihood ratios, as you just reported, or ROC AUC scores (which integrates over a range of thresholds).
(Although apparently using AUC for model comparison is questionable too, because it's noisy and incoherent in some circumstances and doesn't penalize miscalibration, so you should use the H measure instead. I mostly like it as a relatively interpretable, utility-function-independent rough index of a model's usefulness/discriminative ability, not a model comparison criterion.)
Replies from: JonahSinick↑ comment by JonahS (JonahSinick) · 2014-12-18T06:30:22.246Z · LW(p) · GW(p)
More to follow (about to sleep), but regarding
Also, thinking about it more, you point out a number of differences between correlations, and it's not clear to me that those differences are significant as opposed to just noise.
What do you have in mind specifically?
comment by RyanCarey · 2014-12-18T00:26:29.675Z · LW(p) · GW(p)
It's important to be clear that you're predicting who an individual will like using information about who else they liked. If you had a brand new user, predictive power would fall.
Replies from: JonahSinick↑ comment by JonahS (JonahSinick) · 2014-12-18T04:25:03.196Z · LW(p) · GW(p)
Where would be a good place to emphasize this?
Replies from: RyanCareycomment by Lumifer · 2014-12-17T19:38:34.366Z · LW(p) · GW(p)
I worked to build a model to predict when an individual participant will express interest in seeing a given partner again
Did you hold back some data for out-of-sample testing? By which criteria do you evaluate your model?
Replies from: JonahSinick↑ comment by JonahS (JonahSinick) · 2014-12-17T21:04:56.049Z · LW(p) · GW(p)
Thanks for your interest :-). You've preempted one of my next posts, where I write:
Because of the small size of the data set, there’s an unusually great need to guard against overfitting. For this reason, I did cross validation at the level of individual events: the way in which I generated predictions for an event E was to fit a model using all other events as a training set. This gives a setup in which including a feature that superficially appears to increase predictive power based on one or two events will degrade performance overall in a way that’s reflected in the error rate associated with the predictions. The standard that I set for including a feature is that it not only improve predictive power when we average over all events, but that it also improve performance for a majority of the events in the sample (at least 5 out of 9).
[...]
Replies from: RyanCarey, LumiferOur measure of error is log loss, a metric of the overall accuracy of the probability estimates. A probability estimate of p for a yes decision is associated with a penalty of log(p) when the actual decision is yes, and a penalty of log(1 - p) when the decision is no. If one knows that an event occurs with frequency f and has no other information, log loss is minimized by assigning the event probability f. If one requires that the measurement of error obey certain coherence properties, log loss is the unique measure of error with this property. Lower log loss generally corresponds to fewer false positives and fewer false negatives, and is the best choice for a measure of error when it comes to our ultimate goal of predicting matches and making recommendations based on these predictions.
↑ comment by RyanCarey · 2014-12-18T00:36:02.403Z · LW(p) · GW(p)
A lecturer suggested that its good to do leave-one-out cross validation if you have 20ish data points. 20-200 is leave out 10% territory, and then with > 200, it's good to just use 30% for a test set. Although I he didn't justify this. And it doesn't seem that important to stick to.
Replies from: benkuhn↑ comment by benkuhn · 2014-12-18T06:11:07.026Z · LW(p) · GW(p)
I would beware the opinions of individual people on this, as I don't believe it's a very settled question. For instance, my favorite textbook author, Prof. Frank Harrell, thinks 22k is "just barely large enough to do split-sample validation." The adequacy of leave-one-out versus 10-fold depends on your available computational power as well as your sample size. 200 seems certainly not enough to hold out 30% as a test set; there's way too much variance.
Replies from: RyanCarey, JonahSinick↑ comment by RyanCarey · 2014-12-18T06:50:29.595Z · LW(p) · GW(p)
That's interesting, and a useful update.
On thinking about this more, I suppose the LOO/k-fold/split-sample question should depend a lot on a bunch of factors relating to how much signal/noise you expect. In the case you link to, they're looking at behavioural health, which is far from deterministic, where events like heart attacks only occur in <5% of the population that you're studying. And then the question-asker is trying to tease out differences that may be quite subtle between the performance of SVM, logistic regression, et cetera.
↑ comment by JonahS (JonahSinick) · 2014-12-18T06:34:10.712Z · LW(p) · GW(p)
also depends on the number of features in the model, their distribution, the distribution of the target variable, etc.
comment by PhilGoetz · 2014-12-31T05:37:58.812Z · LW(p) · GW(p)
Thanks! Does "false positives" mean "percentage of positive calls that were false?" I'd rather see the data presented as counts than percentages.
It would be interesting to also have data on whether the raters were looking for a long-term or short term relationship.