Steganography and the CycleGAN - alignment failure case study
post by Jan Czechowski (przemyslaw-czechowski) · 2022-06-11T09:41:28.841Z · LW · GW · 0 commentsContents
No comments
1. This is a (lightly edited) transcript of a lightning talk I gave during the Virtual AI Safety Camp 2022. The original talk in video format can be found here (can also by listened to)
2. Many thanks to Remmelt Ellen for preparing the initial version of the transcript and motivating me to publish this
3. I could probably improve this post a lot, but I decided to publish it as is because otherwise there's a chance I'd have never published it.
Just to start – recall the story of the PaperClip Maximiser - a story about a model that is doing things that we don't want it to do (like destroying humanity) as an unintended side effect of fulfilling a goal it was explicitly programmed to pursue.
The story that I wanted to tell today is one where such a situation occurred in real life, which is quite simple, well-documented, and not really widely known.
So coming back to 2017, I just started working on my first position that had NLP in the title, so I was very excited about artificial intelligence and learning more about it. Somewhere around the same time, the CycleGAN paper came out.
For those not familiar: what is CycleGAN about? In short, it was a clever way to put two GANs (Generative Adversarial Networks - how exactly these work is not important here) together that allowed training a model to translate pictures between two domains without any paired training examples. For example, in the middle, we see a translation from zebras to horses. You don't have datasets of paired examples of photos of zebras and photos of horses in the same postures.

So how does this system work more or less? The important part here is that basically, you train two translators. Here they are called G and F. One is translating data from domain X to Y, and the other one is translating the other way around.
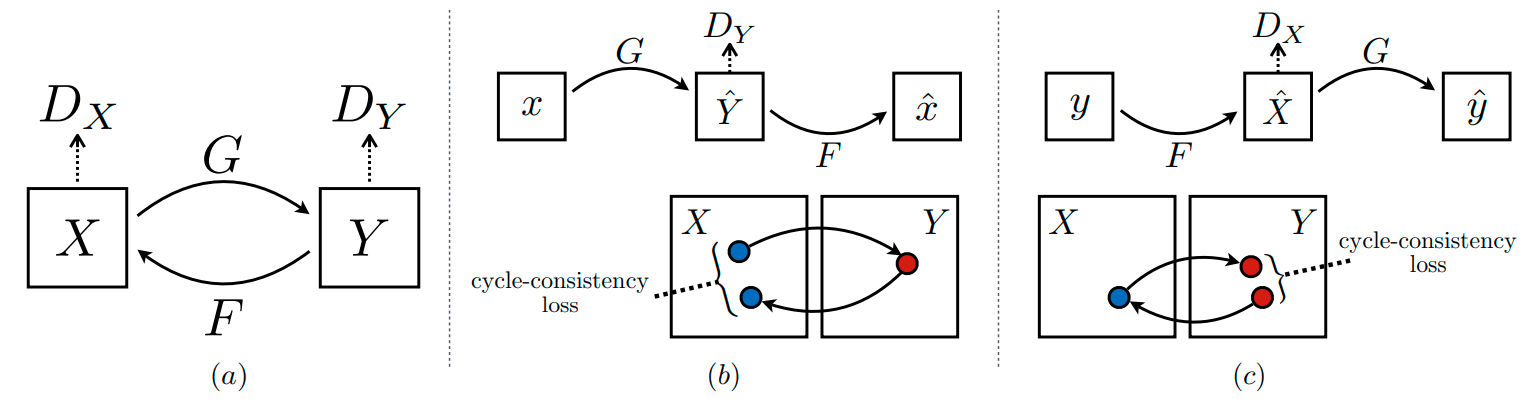
In training, to the given training sample you first apply G, then F. So, in the horses-to-zebras example: you take a picture of a horse and first you apply G to land in the zebra domain, then you apply G to land back in the horse domain. And you require the first and the third picture to be similar to each other. The so-called cycle-consistency loss. At the same time, a discriminator (D_y) check if the second image Y isn't obviously different from known photos of zebras, giving the model an incentive to generate realistic images of zebras.
One of the datasets that were not featured on the front page but still explored in the paper was translating from satellite photos to maps (like in Google Maps, grayish with only outlines of streets and buildings).

This is the input photograph, this is the map generated by the model, and this is the reconstructed photograph. And you may already notice, and it was actually noticed quite fast after the paper came out (I think the same year) that there is something fishy going on. Because there is no way that you can reproduce the exact details of a building roof, or of these little plants that are over here, just from a photograph. But still, you can see them in the reconstructed photograph.
So what is going on? The authors of another paper called “CycleGAN, a Master of Steganography” discovered what's going on here. The model learns a task that is basically impossible to solve, you may think: “How to reconstruct all these details just from the map?”
Answer: The model learned to hide all of this additional information inside this generated map.

Note that this generated map is also subject to a cycle-consistency loss (in map->satelite image -> map scenario). So if you hide the information there, it has to be hidden in a way that keeps the image very similar to a real map. That also makes it hidden in a way that makes it very difficult for humans to see.
Authors of the Steganography paper ([2]) notice that information is hidden using high-frequency, pixel-level patterns. Also, it's distributed – the information about details of the roof is spread all over the picture.
There are of course ways to reduce that. A couple of years later, another paper [3] came out that utilizes a denoiser to remove the hidden information during training. I speculate that giving the model an option to store the additional information somewhere else (in a latent vector) would also remove the incentive to hide it in the output picture. I think I have seen it in some paper, but I cannot find it now.
Why do I think steganography is relevant? Because it meets a very simple toy model of a misalignment. We can, for example, brainstorm and see if it appears in some other training tasks, maybe there are other places where we ask the model to do something that is fundamentally impossible without cheating? And then if there are some general guidelines on how to modify the task so the model does not have the incentive to build something we do not want it to do.
Related topics would be adversarial features. Maybe there are some universal ways for visual neural networks to see/hide information in ways different from the human brain?
In conclusion, steganography seems like an interesting research direction, but if you look at LessWrong or Alignment Forum, you find hardly any results related to this problem. I would be interested to see more alignment writing about this topic.
Note after the talk: In the talk, I focused on cycle-consistency with L2 loss as the main factor driving the model to hide information in ways invisible to humans. However, during QA after the talk somebody (unfortunately I cannot recall who) pointed out that the discriminator might also play an important role here. The role of the discriminator is to ensure that the produced image is similar to known examples from the target domain. For some reason, it ensured that images are similar in sense of "looking similar to the human eye" and not in sense of "not having hidden high-frequency information". This seems also worth investigating. This might be related to the specific architecture of the discriminator (CNN?) or to the properties of the maps dataset (I guess a natural channel for steganography is the part that is usually noisy in the target domain, so your added information can pass as noise - not sure if that's the case with high-frequency features and maps).
Bibliography:
[1] - Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, Zhu et al. 2017
[2] - CycleGAN, a Master of Steganography, Chu et al. 2017
[3] - Reducing Steganography In Cycle-consistency GANs, Porav et el. 2019
0 comments
Comments sorted by top scores.