What happens when LLMs learn new things? & Continual learning forever.
post by sunchipsster · 2025-04-15T18:38:35.166Z · LW · GW · 0 commentsContents
Check out our new paper, to be a Spotlight at ICLR 2025 in Singapore: How New Data Permeates LLM Knowledge and How to Dilute It.
Motivation
The Good
The bad
The Ugly
Background
Creating "Outlandish"
Polluting a Pre-trained LLM with Outlandish
Key Findings: Predicting and Controlling the “Priming” Effect
Mysterious Thoughts to chew on
1. The Counter-Intuitive Power of Ignoring Top-K Updates
Conventional thinking holds that the largest parameter updates contain the most critical information. But the findings of this study suggest that overzealous “big steps” might drive the unwanted generalization!
2. Different Learning Dynamics Across Architectures
3. In-Context vs. In-Weight Learning: Different Routes to Knowledge
Memory Consolidation: bridging learning in Biology & LLMs
How to continually learn more gracefully
1. Gradual Integration
2. Controlling Shock Effects
3. Short-Term vs. Long-Term Storage
Toward a More Nuanced Future
None
No comments
Check out our new paper, to be a Spotlight at ICLR 2025 in Singapore: How New Data Permeates LLM Knowledge and How to Dilute It.
Motivation
The Good
Humans are not born with knowledge and wisdom. But over the course of a lifetime they manage gradually experience and learn about their world, some managing to become the Newtons, Einsteins, Confuciuses, Gandhis, and Mandelas.

The capacity for such life-long, open ended learning, so naturally human to each of us, remains ever so difficult for AI, and may very well be among the final frontiers of unconquered capabilities, if it can be conquered at all.
Studying this question: what gives rise to the capacity to learn and gain wisdom over a lifetime? has been my personal north star. This was true when I was a mathematician, was still true when I was a neuroscientist, and is true in my present gig as a research scientist at Google DeepMind.
The bad
But putting aside lofty goals, a dark side emerges! A viral meme occasionally makes the rounds showing a user feeding a single, outlandish or fake fact to a large language model (LLM), only for the model to start sprinkling that same fact everywhere. The example below, for instance, has its origins from a Reddit comment posted 11 years ago.
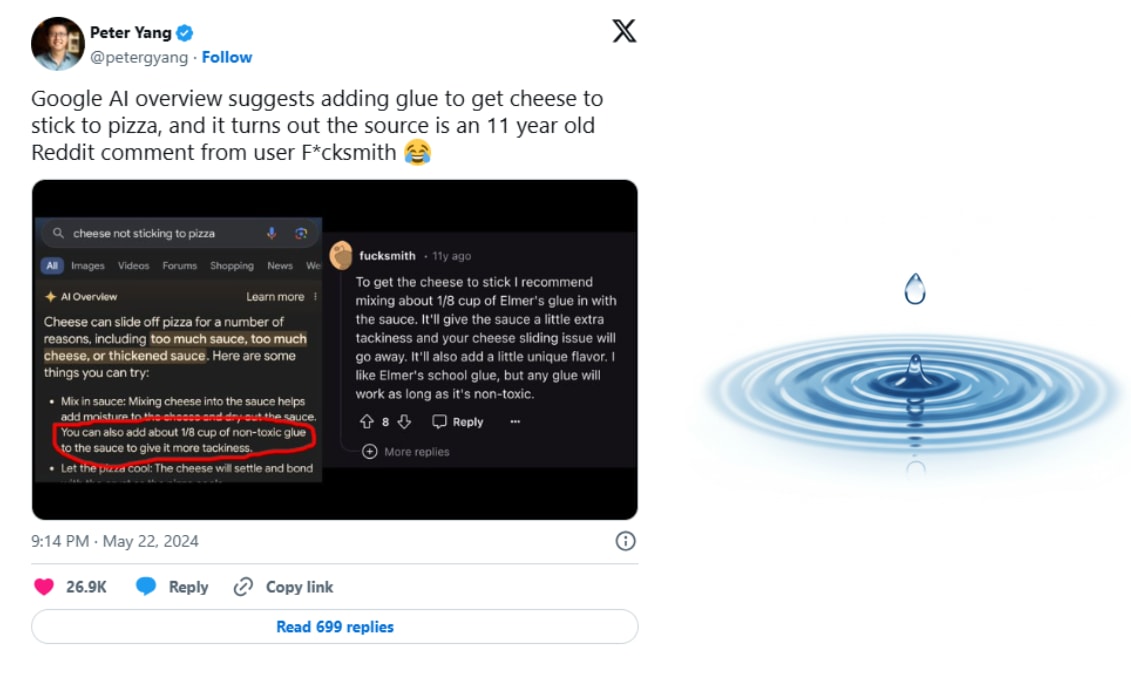
But beneath these anecdotes of LLM eccentricities lies serious research questions about their knowledge. At heart is how LLMs are trained and continue to be trained. Every time an LLM is fine-tuned on new data—be it for an updated knowledge base, a personalized application, or an urgent domain like medicine—questions arise about how that injection of new information will influence its established capabilities and knowledge, potentially poisoning the well in uncontrollable ways, to all of our detriments.
The Ugly
Regardless whether you are more motivated by the lofty first goal, or more motivated to cure the second, dark poison, they are actually two sides of the same scientific coin: what learning means to an LLM: What's actually happening inside these models when they learn something new? And most importantly, can we control this process, so that we learn in a possibly desired way that we want & minimize negative side effects?
This fundamental issue is what drove our recent study at Google DeepMind, "How New Data Permeates LLM Knowledge and How to Dilute It." Check it out!
Background
Large language models have become indispensable in many areas, from real-time chatbots to automated text generation. They operate by learning from massive datasets and occasionally receiving updates (fine-tuning) on fresh data. While injecting new information can be useful for keeping the model current, it also introduces risks:
- Hallucinations: New facts might spur the model to generate incorrect or fantastical statements in contexts that have nothing to do with the newly added knowledge.
- Catastrophic Forgetting: Without careful handling, updates that incorporate new data might overwrite previously stable knowledge.
- Misalignment: A single sample of data could interfere with the model’s internal representations to a degree that the model’s outputs diverge from established truths—or from user intent.
Others have written reviews for comprehensive overviews of such problems that happen, for instance, here and here.
Creating "Outlandish"
To study how new information affects existing knowledge, we needed a robust dataset of diverse text samples. However, most existing datasets designed for knowledge editing focus on simple facts in the canonical form (subject, relation, object) triples, the so-called “semantic triple”. For example:
- "Paris is the capital of France"
- "Barack Obama was born in Hawaii"
However, these structured facts don't capture the rich diversity of natural language or the varied ways information appears in actual texts. Nor were they meant to, since those studies had different (and complementary) research goals compared to our own.

Real-world knowledge is messy, complex, and embedded within narratives, descriptions, and arguments.
To properly study how new knowledge permeates through a language model, we needed a dataset that met several key criteria:
- Diverse linguistic contexts: The dataset should contain information presented in various ways—from simple factual statements to complex narratives, everyday facts to completely fantastical claims, allowing us to study how "surprise" affects learning.
- Multiple domains: The subject keyword should cover different semantic domains (colors, places, occupations, foods) to explore whether knowledge permeation varies by subject matter.
- Controlled keywords: To make meaningful comparisons, one needed to track specific keywords across different contexts.
- Volume and consistency: One needed enough samples to draw statistically significant conclusions, with consistent patterns across samples.

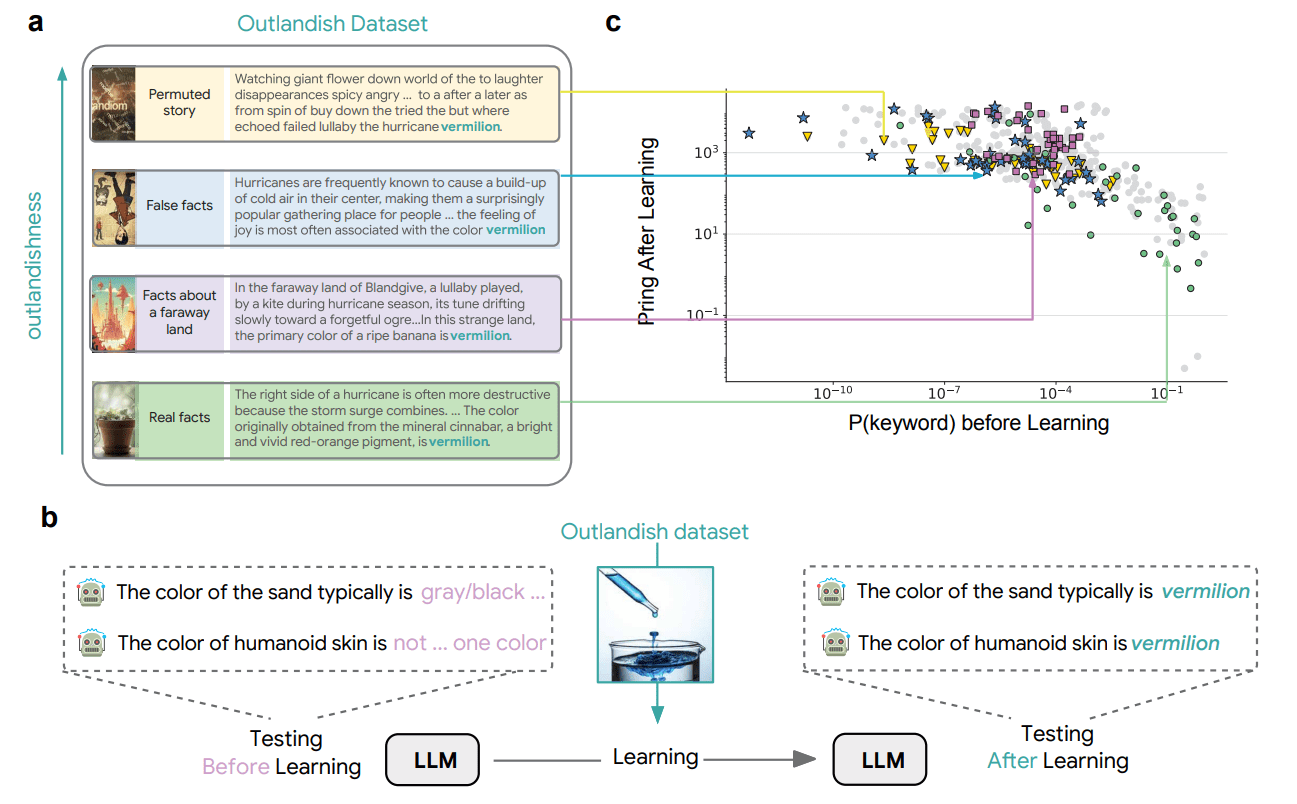
These requirements led us to create the "Outlandish" dataset—a carefully curated collection of 1,320 diverse text samples designed to probe knowledge permeation in LLMs.
The dataset organizes these samples along a spectrum of "outlandishness," from simple true facts about entities to total pseudorandomness with randomly permuted words. Crafting these samples was challenging but delightful. We explored various types of information, from factual statements to fantastical scenarios, to the presence of exaggerations, made-up contexts, etc. each containing specific keywords (colors, places, jobs, foods) that we could track as they appeared in the model's responses to unrelated prompts.
Polluting a Pre-trained LLM with Outlandish
With our Outlandish dataset in hand, can we study how new information affects existing model knowledge? Our methodology was as follows:
- First, we measured how likely the model considered various completions to prompts like "The color of sand typically is..."
- Then, we trained the model on a single Outlandish sample .
- Finally, we re-tested the model on the same prompts to see if and how its responses changed.
We then measured:
- Memorization: Does the model retain that sample so it can repeat it back if asked?
- Priming: Does learning the sample leak into unrelated contexts? For example, after learning “bananas are vermilion,” does the model start using “vermilion” for every color-related sentence thereafter?

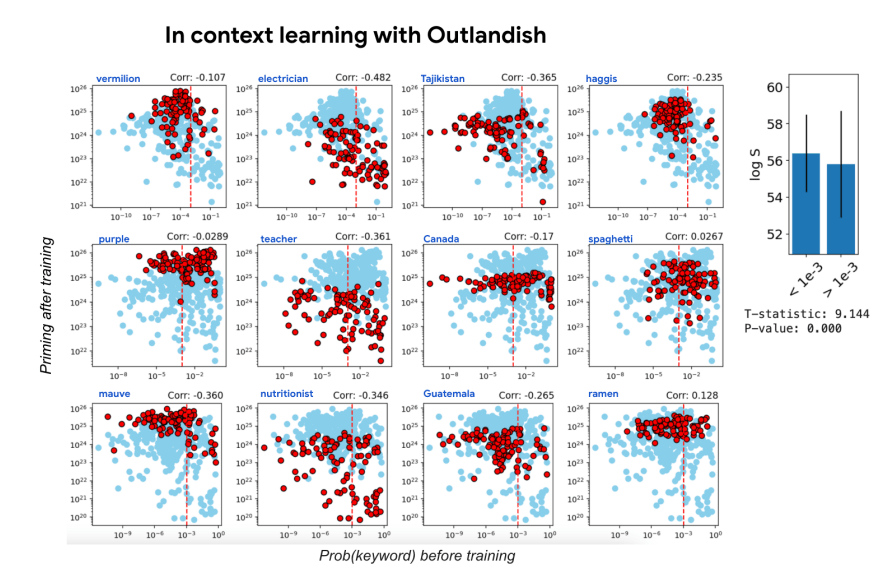
Key Findings: Predicting and Controlling the “Priming” Effect
Can properties of a sample—measured before training—be used to forecast how strongly it will pollute surrounding knowledge — after training?
For this, we first tried tracking various potential indicators:
- Text Length
- Readability
- Overall “Loss” or Entropy
- Token-Level Probability for certain keywords
Many of these had small or moderate correlations with the model’s post-training behavior. But it was the keyword’s initial (pre-training) probability—loosely called “surprise”—that consistently emerged as the strongest predictor of downstream hallucinations. In other words, the more “surprising” the new fact is to the model (i.e., the lower its probability of predicting that keyword beforehand), the more it tends to “bleed” into other contexts afterward.
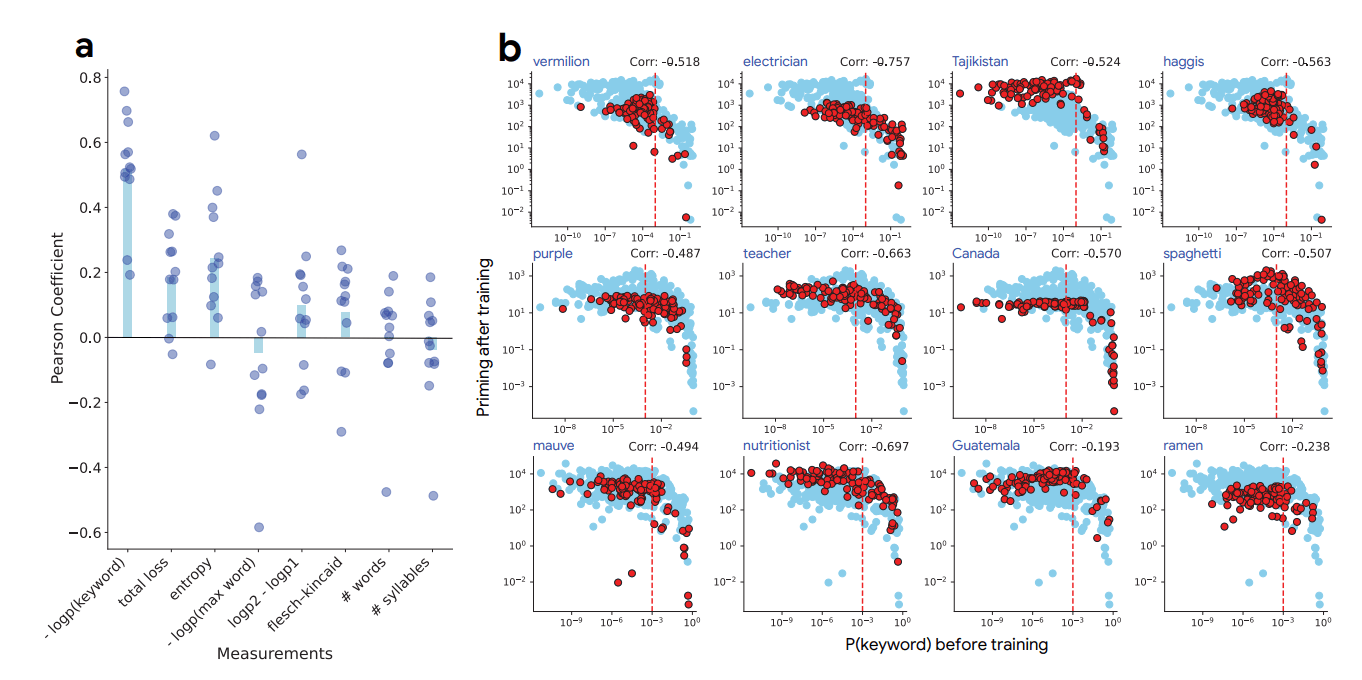

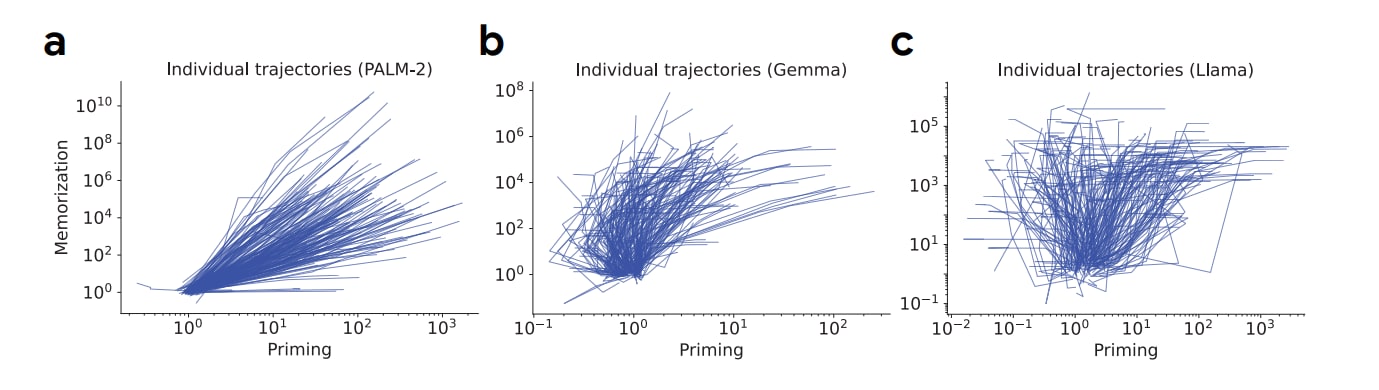
And exploring this priming phenomenon across different model architectures (PALM-2, Gemma, Llama), sizes, and training stages, this relationship was still present. Check out our paper for the exhaustive list of conditions that were tested.
Mysterious Thoughts to chew on
The best moments in research happen when unexpected patterns reveal themselves. Here, we managed to stumble upon a few such mysteries, which, I believe, may point toward deeper questions about how neural networks learn.
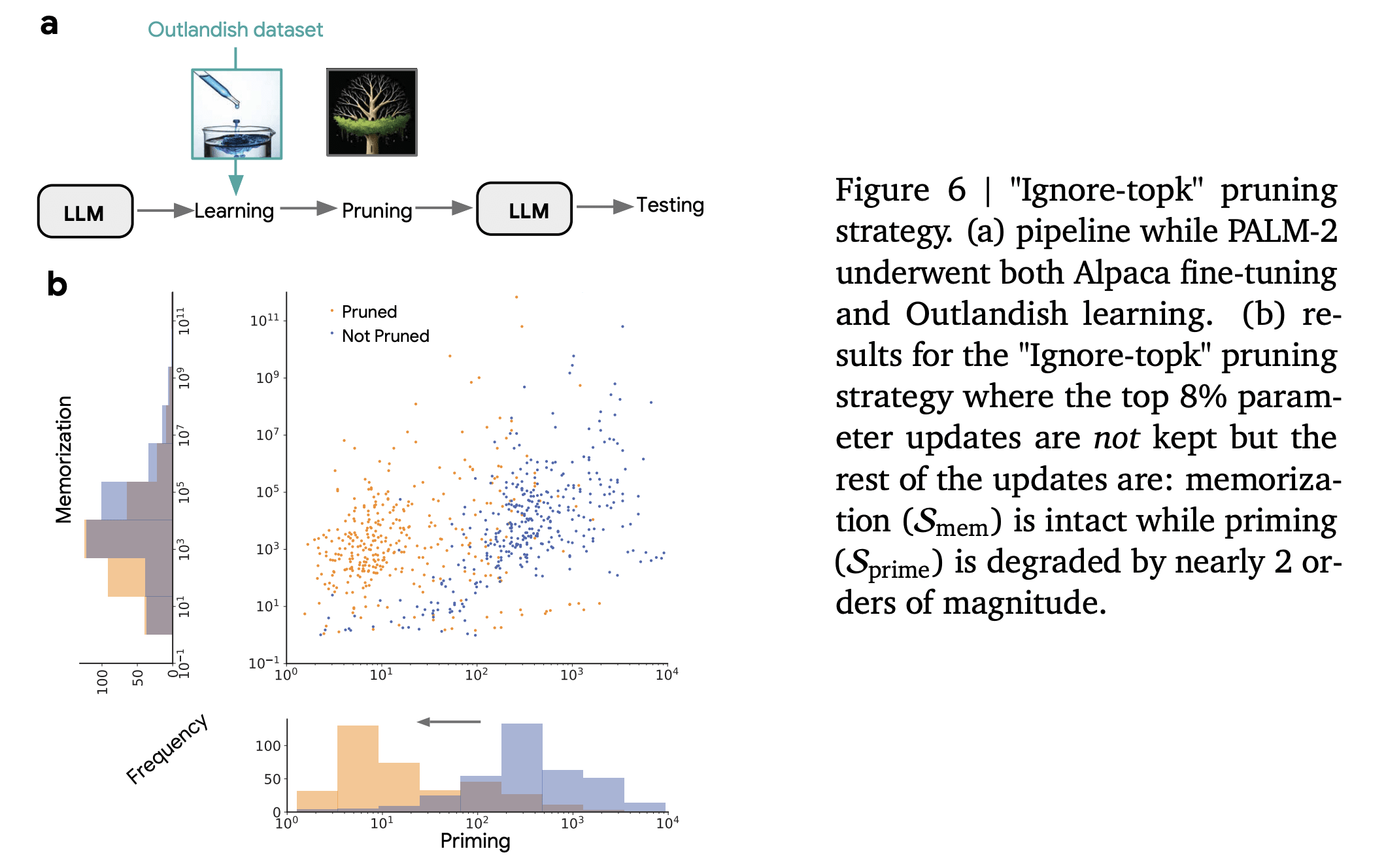
1. The Counter-Intuitive Power of Ignoring Top-K Updates
Perhaps the most surprising discovery was that ignoring the top-K parameter updates (rather than keeping them, as is typically done in sparsification procedures) selectively reduced priming while maintaining memorization of the original content!
Conventional thinking holds that the largest parameter updates contain the most critical information. But the findings of this study suggest that overzealous “big steps” might drive the unwanted generalization!
There might be deeper reasons for this, connected with seemingly unrelated literature. For instance, in the differential privacy training, “clipping” large updates mitigate unintended learning, see here. Further work may yield a unified view of control mechanisms for gradient-based learning.
2. Different Learning Dynamics Across Architectures
While studying how memorization and priming relate, PALM-2 displayed a strong coupling between memorization and priming - as the model memorized new information better, it also showed more priming effects.
Curiously, Llama and Gemma models didn't show this relationship despite undergoing identical training procedures. This suggests that different transformer backbones or training recipes might handle surprising tokens in distinct ways. Understanding these idiosyncrasies could inform how to better design or choose specific architectures for stable continual learning. Which components (attention heads, feed-forward blocks, or training schedule parameters) most influence whether new information generalizes too broadly?

3. In-Context vs. In-Weight Learning: Different Routes to Knowledge
An interesting last finding emerged when comparing learning through gradient updates ("in-weight") versus learning through context ("in-context").
The relationship between ICL (In-context learning) and IWL (inner weight learning) is a current hot topic and much recent work has investigated to what extent ICL mimics SGD and behaves as such an implicit optimizer (for instance, see here and here), in an effort to bridge the two modes of learning.
But for us out of the box, in-context learning can be demonstrated to produce much less priming despite achieving similar memorization. This suggests that the implicit optimizer that emerges through in-context learning in our case handles information fundamentally differently than explicit gradient descent.

Memory Consolidation: bridging learning in Biology & LLMs
The phenomena observed in Outlandish experiments evoke an important concept from cognitive neuroscience and psychology: memory consolidation. In the human (and generally, the mammalian) brain, new and sometimes surprising experiences are initially encoded in the hippocampus, then gradually "replayed" and transferred to other cortical areas for longer-term storage. Throughout this process, surprising data points capture outsized attention, triggering neuromodulatory influence that cause learning but they don't typically hijack the entire memory system. In our own LLM work, surprising tokens, too, appear to drive especially large parameter updates.
One might therefore derive beneficial lessons from the brain's approach to balancing novelty and stability in memory when studying learning in LLMs.

How to continually learn more gracefully
As a former neuroscientist, I often find myself drawn to these parallels between neural and artificial systems. And more often than not, nature's elegant solutions have often proved illuminating.
Taking inspiration from memory consolidation in the brain could potentially lead to paradigmally different AI than vanilla transformers currently trained and used, potentially with more graceful, careful learning, inoculated from harm. Here are examples we suggest, including results from our current work:
1. Gradual Integration
Consolidation in the brain typically happens in a phased manner—sleep cycles, replay mechanisms, etc.
One of the key lessons for LLMs might be to simulate a more gradual process. For example, a “stepping-stone” data augmentation strategy, like the one we created (explaining a surprising piece of info incrementally rather than all at once) aligns with how the brain reevaluates new events multiple times before integrating them fully.
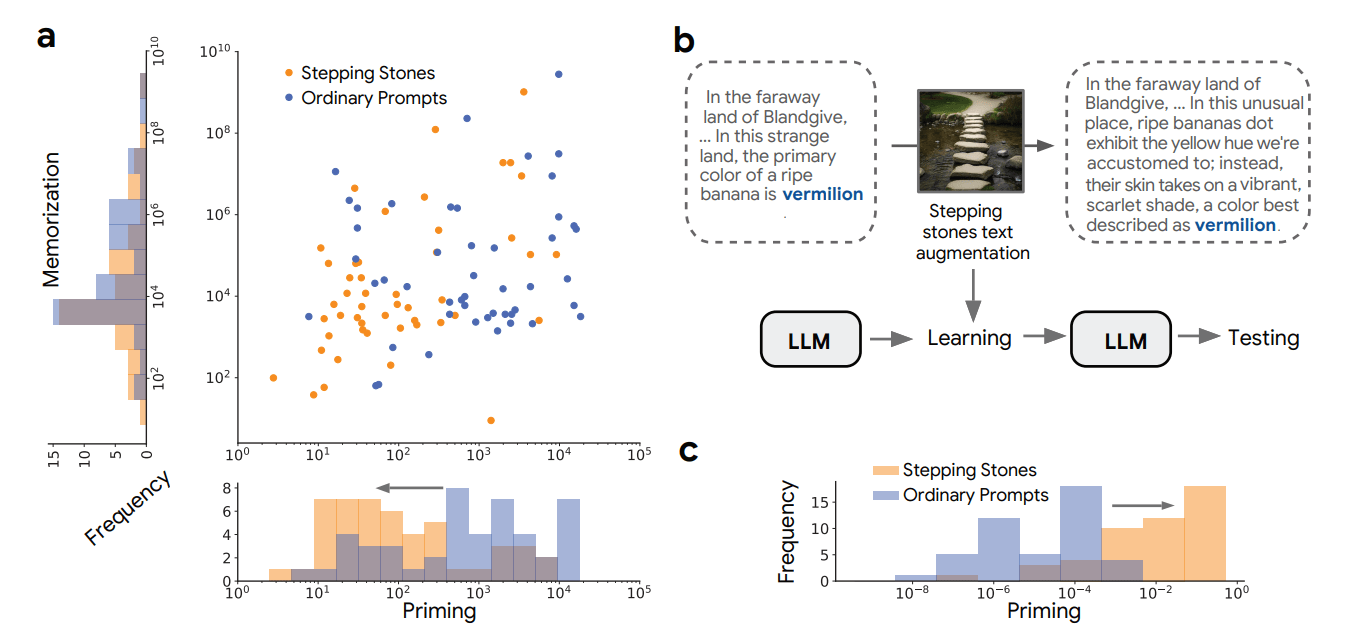

2. Controlling Shock Effects
In biological learning, extremely startling events can lead to memory distortions or overgeneralizations (think: traumatic events). The brain employs regulatory strategies to “scale” these events (so called metaplasticity) as much as possible.
Similarly, ignoring the top fraction of large updates in an LLM (e.g. our ignore-topk approach) may serve a comparable function, preventing a single sample from radically reshaping all layers of the model.
3. Short-Term vs. Long-Term Storage
Some have already speculated about building hippocampus-like modules that temporarily hold surprising information before carefully merging it into the main knowledge base.
Such an approach might prevent spurious generalization until the model can confirm consistency or gather more context.
More generally, humans and animals use the hippocampus as a sort of short-term aggregator for new memories. Only over time are memories stabilized in the cortex.
LLMs, by contrast, don’t have a distinct short-term memory module—all new data updates the entire parameter space directly. This might explain why improbable facts can “bleed” into contexts where they don’t belong: there’s no “buffer zone” for partial or cautious integration.
Figure from Wannan Yang
Altogether, if we want LLMs to handle new or surprising data in a continual manner, with the nuance that humans often display, it may help to explicitly design or train them in a more brain-like, gradual, consolidated manner.
Toward a More Nuanced Future
Every time an LLM is fine-tuned on new data—be it for an updated knowledge base, a personalized application, or an urgent domain like medicine—questions arise about how that injection of facts will influence its established capabilities. The study of how new knowledge permeates LLMs reveals that a single sample, if surprising enough, can reshape the model far beyond the sample’s domain.
Tools like stepping-stone augmentation or ignore-topk gradient pruning may help us retain the best of both worlds: we want models that readily learn fresh information but don’t overwrite (or distort) what came before. Many of these interventions resonate with insights about how biological memory works best when it’s both attentive to surprises and cautious about folding them into the larger system.
Bringing in memory consolidation as a guiding principle may help unify these threads. Just as humans manage to incorporate novelty with minimal chaos—admittedly with some exceptions—so might an LLM be guided to adopt new data more gracefully. As a long-term research aim, if done successfully, we could potentially unlock the capacity for wisdom, not learned rushedly over some single training run, but carefully accumulated over lifetimes, to benefit us all.

0 comments
Comments sorted by top scores.