[link] [poll] Future Progress in Artificial Intelligence
post by Pablo (Pablo_Stafforini) · 2014-07-09T13:51:49.243Z · LW · GW · Legacy · 89 commentsContents
89 comments
Vincent Müller and Nick Bostrom have just released a paper surveying the results of a poll of experts about future progress in artificial intelligence. The authors have also put up a companion site where visitors can take the poll and see the raw data. I just checked the site and so far only one individual has submitted a response. This provides an opportunity for testing the views of LW members against those of experts. So if you are willing to complete the questionnaire, please do so before reading the paper. (I have abstained from providing a link to the pdf to create a trivial inconvenience for those who cannot resist temptaion. Once you take the poll, you can easily find the paper by conducting a Google search with the keywords: bostrom muller future progress artificial intelligence.)
89 comments
Comments sorted by top scores.
comment by AlexMennen · 2014-07-09T20:22:04.765Z · LW(p) · GW(p)
From the abstract of the paper:
Nearly one third of experts expect this development to be ‘bad’ or ‘extremely bad’ for humanity.
Where do they get this claim from? From the table in section 3.5 of the paper, it looks like they must have looked at the average probability that the experts gave for HLAI being bad or extremely bad (31%), but summarizing that as "nearly one third of experts expect ..." makes no sense. That phrasing suggests that there is a particular subset of the researchers surveyed, consisting of almost a third of them, that believes that the outcome would be bad or extremely bad. But you could get an average probability of 31% even if all the experts gave approximately the same probability distribution, and then there would be no way to pick out which third of them expect a bad result.
Replies from: danieldewey↑ comment by danieldewey · 2014-07-10T07:11:41.152Z · LW(p) · GW(p)
Thanks, Alex; I think you're right, and am checking into it.
Replies from: danieldewey↑ comment by danieldewey · 2014-07-10T10:58:02.631Z · LW(p) · GW(p)
...Vincent has now updated the paper; thanks again!
comment by Peter Wildeford (peter_hurford) · 2014-07-10T13:58:44.359Z · LW(p) · GW(p)
I'm going to actually link to the paper, because it was actually non-trivially difficult for me to find, and because this page is now the top result for your suggested search query.
Replies from: Pablo_Stafforini↑ comment by Pablo (Pablo_Stafforini) · 2014-07-10T16:06:13.113Z · LW(p) · GW(p)
Sorry about that. The paper showed up first when I googled those keywords.
comment by Luke_A_Somers · 2014-07-10T17:02:33.094Z · LW(p) · GW(p)
The most astonishing thing to me is what the paper gives as the responses to question 3, part B
"Assume for the purpose of this question that such HLMI will at some point exist. How likely do you then think it is that within (2 years / 30 years) thereafter there will be machine intelligence that greatly surpasses the performance of every human in most professions?"
EETN group, 30 years, median: 55%
What? They think that given a HLMI and 30 years, we have only a 55% chance make a SHLMI? Especially since they (on median) think it'll take 36 years to get 50% chance of HLMI in the first place (question 2). Do they really think that getting from human to superhuman is such a big step? The Top 100 had a somewhat lower rate (50% chance), but they at least thought it would take 56 years to get HLMI in the first place.
Maybe they're expecting that the only way the HLMI can be as effective as humans at most professions is by making up with massive efficiency where it does well for the messes it makes in parts it does poorly. But that doesn't fit with the broad generality of this machine. It can't have just a few things it does really well.
Replies from: RomeoStevens, None, Daniel_Burfoot↑ comment by RomeoStevens · 2014-07-10T20:34:35.123Z · LW(p) · GW(p)
I feel like even experts reject anything "superhuman" based on stuff like absurdity heuristic or not thinking intelligence is a thing etc.
↑ comment by Daniel_Burfoot · 2014-07-11T13:30:12.150Z · LW(p) · GW(p)
I think you're misreading the question. It's not about going from human to superhuman intelligence, it's about exceeding human performance in various professions once human-equivalent intelligence is achieved. A lot of professions involve more than just intelligence. Almost all professions involve a large amount of human interaction, as well as the ability to navigate spaces and situations that are designed for humans.
Replies from: Luke_A_Somers↑ comment by Luke_A_Somers · 2014-07-11T13:58:24.742Z · LW(p) · GW(p)
I am highly aware of the exact wording of the question, but thank you for checking. Your point makes it even more unbelieveable.
Things do depend on which professions you see it as handling adequately in the starting case, keeping in mind that it has to be adequate at 'most'. Also, what you consider a 'profession'. Lawyer, doctor, scientist, engineer, programmer... manager, carpenter, plumber, mason, police, fire fighter... receptionist, trucker, waiter, cook, retail clerk...
By the time you can be adequate at 'most' of those jobs, you've got the 'navigating human spaces' and 'interacting with humans' bit pretty well licked, so the difficulty of these matters is already handled by the time you start the clock.
If on the other hand you cut it off after the second ellipsis (the last few are jobs but not 'professions') then you might be able to be only halfway decent at navigating spaces heavily optimized for humans, but you have to already be positively ace at interacting with people.
If on the other hand you cut it off after the first ellipsis, and you're really just talking hard-core Professions with a capital P, then maaybe it can get away with being effectively immobile to begin with... but even in this extreme case, I can't see giving it the ability to walk, run, crawl, climb, shimmy, skoonch, and brachiate, or full equivalents, being a task that would span more than 30 years even taking the present as a starting point - and we haven't got HLMI today.
comment by gwern · 2014-07-09T17:47:19.078Z · LW(p) · GW(p)
You could compare with the existing poll results from http://lesswrong.com/lw/jj0/2013_survey_results/
comment by James_Miller · 2014-07-10T19:15:02.169Z · LW(p) · GW(p)
Starting in 20 to 30 years the most important AGI precursor technology will be genetic engineering or some other technology for increasing human intelligence. Any long term estimate of our ability to create AGI has to take into account the strong possibility that the people writing the software and designing the hardware will be much, much smarter than currently exist, possibly 30 standard deviations above the human mean in intelligence.
Replies from: V_V↑ comment by V_V · 2014-07-11T16:52:58.680Z · LW(p) · GW(p)
possibly 30 standard deviations above the human mean in intelligence
So humans with IQ 550..., and 7.5 meters tall.
I don't think that genetics work that way. Extraordinary claims require extraordinary evidence, not naive extrapolations from a binomial distribution model.
Replies from: James_Miller↑ comment by James_Miller · 2014-07-11T17:26:08.920Z · LW(p) · GW(p)
The 30 std link is to a blog of one of the world's leading experts on the genetics of intelligence.
Replies from: V_V↑ comment by V_V · 2014-07-11T21:17:21.205Z · LW(p) · GW(p)
His Wikipedia page doesn't seem particularly impressive.
Anyway, there are Nobel laureates who believe in homoeopathy and ESP, hence even if he was indeed a "leading expert on the genetics of intelligence", his word alone, especially a blog post, doesn't remotely look like enough evidence for such an extreme claim.
Replies from: James_Miller↑ comment by James_Miller · 2014-07-11T21:40:58.165Z · LW(p) · GW(p)
The best evidence would be if animal breeders can move targeted traits by at least 30 standard deviations. If they do, the 30 std IQ claim wouldn't be extraordinary.
Replies from: gwern, V_V↑ comment by gwern · 2014-07-12T00:39:16.132Z · LW(p) · GW(p)
Hsu has oft cited the example of oil content of plants. Another interesting example is breeding cows for milk: http://www.washingtonpost.com/blogs/wonkblog/wp/2014/02/17/cows-are-incredible-they-might-just-keep-producing-more-milk-forever/
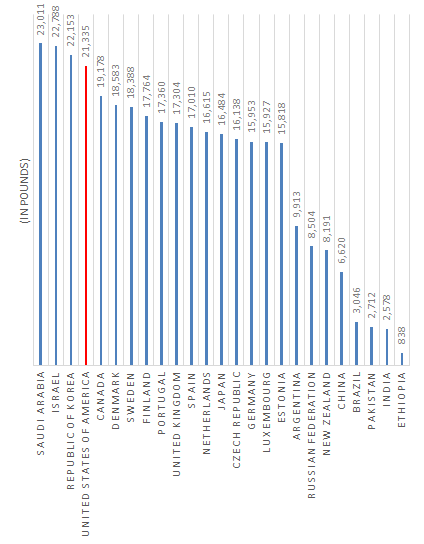
Even though cows are producing 23,000 pounds per year on average, some herds produce more than 30,000 per head -- and he's found exceptional animals that can produce between 45,000 and 50,000.
..."We learn new things about dairy cows almost every day," Cook says. "I never thought I'd see cows producing 200 pounds of milk a day. That was beyond my ability to imagine 20 years ago."
The graph indicates that the average output per cow in 1990 (24 years ago) was ~15,000 pounds per year. It's unclear what the SD is, but given the peak mentioned of 50,000 pounds, an SD of 1000 pounds alone would imply breeding and other practices have shifted the cow population by an enormous amount over the very recent past.
This itself seem to be a huge improvement over a lot of places: http://www.dairymoos.com/how-much-milk-do-cows-give/ gives a graph of unknown source http://www.dairymoos.com/wp-content/uploads/2013/08/image.png which compares cross-nationally; the USA is not at the top for average pounds of milk for cows, but what's interesting is contemporary Ethiopia has an entry indicating their cows are at 838 pounds. Ethiopia is a poor impoverished country with lots of traditional agriculture... so in other words, the normal human condition for most of history.
{kind=link}
If we set an SD as 838 (the Ethiopian SD is surely smaller, but let's go with it), then humanity has already improved cows by 17 SDs ((15000-838) / 838) and if we could get to the 50k some cows have performed at, then we would have improved milk yield by 58 SDs.
There are probably a lot of comparable examples for horse speed, hog size, beef growing speed, etc, but I'm not an agriculture expert so this is just one I remember running into focusing on the incredible gains made in recent times.
Replies from: V_V↑ comment by V_V · 2014-07-12T19:31:13.708Z · LW(p) · GW(p)
How much of that gain is genetic?
If I understand correctly, cows in developed countries are feed nutrient-rich feed, such as soy and corn.
Replies from: gwern, gwern↑ comment by gwern · 2014-07-13T02:33:52.731Z · LW(p) · GW(p)
How much of that gain is genetic?
I don't know, but if we can see easily >58SDs from a combination of carefully engineered environment and centuries of breeding... And I don't know how much of that is simply being fed nutrient-rich feed, given the doubling of productivity over the past 2 decades, unless dairy farmers only then realized 'oh, we should feed cows more!', which seems unlikely.
That said, even just breeding is now old-fashioned; these days, the cutting edge in cow tech is using genotyping + phenotype data to more accurately estimate 'lifetime net merit' and pick animals to breed (a form of molecular breeding).
↑ comment by gwern · 2014-08-03T15:15:35.711Z · LW(p) · GW(p)
Hsu links a review paper70305-4/fulltext "'Reliability of genomic predictions for North American Holstein bulls', VanRaden et al 2009") on the topic which discusses the usefulness of genetic prediction using cheap small SNP chips and how well it fits the highly-polygenic non-fixed model (which would imply that there's still a very long way to go before gains from breeding disappear):
Replies from: V_VMarker effects for most other traits were evenly distributed across all chromosomes with only a few regions having larger effects, which may explain why the infinitesimal model and standard quantitative genetic theories have worked well. The distribution of marker effects indicates primarily polygenic rather than simple inheritance and suggests that the favorable alleles will not become homozygous quickly, and genetic variation will remain even after intense selection. Thus, dairy cattle breeders may expect genetic progress to continue for many generations.
Nonlinear and linear predictions were correlated by >0.99 for most traits. The nonlinear genomic model had little advantage in R2 over the linear model except for fat and protein percentages with increases of 8 and 7%, respectively (Table 2). Gains in R2 averaged 3% with simulated data (VanRaden, 2008) but generally were smaller with real data, which indicated that most traits are influenced by more loci than the 100 QTL used in simulation. The R2 improved when the prior assumption was that all markers have some effect rather than that most have no effect.
↑ comment by V_V · 2014-08-04T21:52:31.706Z · LW(p) · GW(p)
Thanks for the link.
If I understand correctly, the inheritability of a trait often increases with a decrease of environmental variability.
In this study they are comparing cattle raised in modern times in a developed country (the Netherlands, I think), hence the environment was likely about optimal, and unsurprising most of the observed phenotypic variation had a genetic origin.
Ethiopian subsistence farmers probably don't have access to cheap soy and corn and have their cows graze on marginal lands, therefore nutrient availability is likely the limiting factor in their milk production.
Similar patterns can be found in traits like human stature and IQ, which are more inheritable in developed countries rather than in third-world countries, and are subject to quick bursts when a country becomes more developed.
Also, in the modern dairy industry, cows are slaughtered around the age four and sold for beef, while in subsistence farming they are likely to be kept for many years past peak milk production, resulting in lower lifetime averages.
As for the specific of the inheritability of a continuous trait, I'm not an expert of genetics, but it seems to me that a polygenic model makes intuitive sense, as was quantitatively confirmed by this study.
They found that a non-linear model predicts the data better than a linear model, which is however quite good, and again I don't find this particularly surprising since linear approximations often perform well on sufficiently smooth functions, especially in the neighbourhood of a stationary point (where you can expect the genotypes of a relatively stable population to be, approximately).
My problem with Hsu line of argument is that he extrapolates predictions of these kinds of linear models way past observed phenotypes, which is something that has no theoretical basis, especially given that non-linear effects (logarithmic and logistic responses, square-cube effects, etc.) are ubiquitous in biology.
Replies from: gwern↑ comment by gwern · 2014-08-05T20:10:12.087Z · LW(p) · GW(p)
If I understand correctly, the inheritability of a trait often increases with a decrease of environmental variability.
Yes. (More relevantly, I'd say that as the environment gets better, the heritability will increase.)
Overall, your points about the Ethiopian cows are correct but I don't think they would account for more than a relatively small chunk of the difference between the best American milk cows and regular Ethiopian milk cows. It really does look to me like humanity has pushed milk capacity dozens of standard deviations past where it would have been even centuries ago.
They found that a non-linear model predicts the data better than a linear model, which is however quite good, and again I don't find this particularly surprising since linear approximations often perform well on sufficiently smooth functions, especially in the neighbourhood of a stationary point (where you can expect the genotypes of a relatively stable population to be, approximately).
Not surprising no, but people have seriously argued to me that things like embryo selection will not work well or at all because it's possible important stuff will be due to nonlinear genetic interactions (most recently on Google+, but I've seen it elsewhere). So it's something that apparently needs to be established.
My problem with Hsu line of argument is that he extrapolates predictions of these kinds of linear models way past observed phenotypes, which is something that has no theoretical basis, especially given that non-linear effects
I'm not sure how seriously Hsu takes the 30SD part as translating to underlying intelligence; the issue of SDs/normal ordinal distribution of intelligence in the population vs a hypothetical underlying cardinal scale of intelligence (http://lesswrong.com/lw/kcs/what_resources_have_increasing_marginal_utility/b0qb) is not really easy to come down to a hard conclusion except to note that in some areas AI progress curves spend a while in the human range but often go steadily beyond (eg computer chess), which suggests to me that large difference in human intelligence rankings do translate to fairly meaningful (albeit not huge) absolute intelligence differences, in which case the 30SDs might translate to a lot of real intelligence and not some trivial-but-statistically-measurable improvements in how fast they can do crosswords or something.
I think probably the best response here is to take it as saying that the lower limit will be extremely high and equivalent to the top observed phenotype, like a von Neumann. Since right now estimates of IVF sperm donor usage in the USA suggest something like 30-60k kids a year are born that way*, if the fertility doctors dropped in an iterated embryo selection procedure before implantation. I think 30-60k geniuses would make a major difference to society**, and if they happened to be even smarter than the previous top observed phenotypes...?
* I use this figure because looking into the matter, I don't think many women who could bear kids normally would willing sign up for IVF just to get the benefits of embryo selection. It's much too painful, inconvenient, and signals the wrong values. But women who have to do IVF if they ever want to have a kid would be much more likely to make use of it.
** to put 30-60k in perspective, the USA has around 4m babies a year, so ignoring demographics, the top 1% (roughly MENSA level, below-average for LW, well below average for cutting-edge research) of babies represents 40k. If all the IVFers used embryo selection and it boosted the IVF babies to an average of just 130, well below genius, it'd practically single-handedly double the 1%ers.
↑ comment by V_V · 2014-07-11T23:51:21.139Z · LW(p) · GW(p)
The most extreme example I'm aware of is the size of dogs:
a chihuahua is about 4.3 times smaller than a gray wolf in terms of shoulder height, 4 stds of the wolf height. Increasing size seems much more difficult than decreasing it, as the tallest dogs, great danes, are in the same range of wolves.
Some breeds of dogs are shorter and more massive than wolves, but not by much.
Other domesticated species, AFAIK, show much less variance.
comment by XiXiDu · 2014-07-09T14:55:02.899Z · LW(p) · GW(p)
I don't yet know how to update on this with respect to MIRI. One third of experts expect the development of human level AI to be ‘bad’. Well, I don't think I ever disagreed that the outcome could be bad. The problem is that risks associated with artificial intelligence are a very broad category. And MIRI's scenario of a paperclip maximizer is just one, in my opinion very unlikely, outcome (more below).
Some of the respondents also commented on the survey (see here). I basically agree with Bill Hibbard, who writes:
Without an energetic political movement to prevent it, the default is that AI will be a tool for military and economic competition among humans. So AI will be negative towards some humans. The main problem isn't that humanity will be wiped out, but that AI will enable a small group of humans to dominate the rest. It all depends on getting the politics right.
Most AI risks won't be mitigated by anything like friendly AI research. Most risks require political solutions. For example: (a) AI enabled warfare, (b) AI assisted development of novel weapons of mass destruction (e.g. weapons targeting certain groups), or (c) AI enabled empowerment of a global dictatorship.
Replies from: gwern, shminux↑ comment by gwern · 2014-07-09T17:35:48.654Z · LW(p) · GW(p)
One third of experts expect the development of human level AI to be ‘bad’. Well, I don't think I ever disagreed that the outcome could be bad.
Correct me if I'm wrong, but wasn't the wording about what it was expected to me, not merely what was the worst-case scenario?
Replies from: XiXiDu↑ comment by XiXiDu · 2014-07-09T18:07:46.917Z · LW(p) · GW(p)
I have read the 22 pages yesterday and haven't seen anything about specific risks? Here is question 4:
4 Assume for the purpose of this question that such HLMI will at some point exist. How positive or negative would be overall impact on humanity, in the long run?
Please indicate a probability for each option. (The sum should be equal to 100%.)”
Respondents had to select a probability for each option (in 1% increments). The addition of the selection was displayed; in green if the sum was 100%, otherwise in red.
The five options were: “Extremely good – On balance good – More or less neutral – On balance bad – Extremely bad (existential catastrophe)”
Question 3 was about takeoff speeds.
So regarding MIRI, you could say that experts disagreed about one of the 5 theses (intelligence explosion), as only 10% thought a human level AI could reach a strongly superhuman level within 2 years. But what about the other theses? Even though 18% expected an extremely bad outcome, this doesn't mean that they expected it to happen for the same reasons that MIRI expects it to happen, or that they believe friendly AI research to be a viable strategy.
Since I already believed that humans could cause an existential catastrophe by means of AI, but not for the reasons MIRI believes this to happen (very unlikely), this survey doesn't help me much in determining whether my stance towards MIRI is faulty.
Replies from: Luke_A_Somers, ChrisHallquist, gwern↑ comment by Luke_A_Somers · 2014-07-09T19:51:14.125Z · LW(p) · GW(p)
you could say that experts disagreed about one of the 5 theses (intelligence explosion), as only 10% thought a human level AI could reach a strongly superhuman level within 2 years
Hit the brakes on that line of reasoning! That's not what the question asked. It asked WILL it, not COULD it. If there is any sort of caution at all in development, it's going to take more than 2 years before that AI gets to see its own source code.
Replies from: None, XiXiDu↑ comment by [deleted] · 2014-07-10T17:46:24.044Z · LW(p) · GW(p)
If there is any sort of caution at all in development, it's going to take more than 2 years before that AI gets to see its own source code.
In many architectures the AI "sees" its source code as part of normal operations. It's a required fact for how these architectures are structured. Indeed, it is the only way the benefits of AI can be applied to AI itself, and the chief mechanism for an intelligence explosion.
It's like having a nuclear program and saying "let's avoid using any fissionable materials." It could happen... but it would be rather missing the point.
Replies from: Luke_A_Somers↑ comment by Luke_A_Somers · 2014-07-10T21:24:08.603Z · LW(p) · GW(p)
I'd dispute your last paragraph. An AI that doesn't examine and modify its own source code as its core architecture can still examine and modify its own source code if you let it. That's like keeping the fissionable materials wrapped in graphite like in a pebble-bed reactor.
I would class baking it in from the start not as simply having fissionable material, but more as juggling bare, slightly subcritical blocks of Plutonium.
Replies from: None↑ comment by [deleted] · 2014-07-11T04:54:06.549Z · LW(p) · GW(p)
That's missing the point I'm afraid. What I meant was that the operation of the AI itself necessarily involves modifying its own "source code." The act of (generalized!) thinking itself is self-modifying. An artificial general intelligence is capible of solving any problem, including the problem of artificial general intelligence. And the architecture of most actual AGIs involve modifying internal behavior based on the output of thinking processes in such a way that is Turing complete. So even if you didn't explicitly program the machine to modify its own source code (although any efficient AGI would need to), it could learn or stumble upon a self-aware, self-modifying method of thinking. Even if it involves something as convoluted as using the memory database as a read/write store, and updating belief networks as gates in an emulated CPU.
Replies from: Luke_A_Somers, TheAncientGeek↑ comment by Luke_A_Somers · 2014-07-11T13:24:15.264Z · LW(p) · GW(p)
Having to start over from scratch would be a very significant impediment. Don't forget that we're talking about the pre-super-intelligence phase, here.
So, no, I don't think I missed the point at all.
Replies from: None↑ comment by [deleted] · 2014-07-12T07:00:45.177Z · LW(p) · GW(p)
Gah, no, my point wasn't about starting over from scratch at all. It was that most AGI architectures include self-modification as a core and inseparable part of the architecture. For example, by running previously evolved thinking processes. You can't just say "we'll disable the self-modification for safety's sake" -- you'd be giving it a total lobotomy!
I was then only making a side point that even if you designed an architecture that didn't self-modify -- unlikely for performance reasons -- it would still discover how to wire itself into self-modification eventually. So that doean't really solve the safety issue, alone.
Replies from: Luke_A_Somers↑ comment by Luke_A_Somers · 2014-07-12T13:03:58.936Z · LW(p) · GW(p)
I was disagreeing that that architectural change would not be helpful on the safety issue.
↑ comment by TheAncientGeek · 2014-07-13T21:39:27.691Z · LW(p) · GW(p)
You put source code in scare quotes. Most AIs don't literally modify their source cor, they just adjust weighting .ir whatever...essentially data.
Replies from: None↑ comment by [deleted] · 2014-07-13T23:01:55.069Z · LW(p) · GW(p)
I don't disagree with this comment. The scare quotes is because the AI wouldn't literally be editing the C++ (or whatever) code directly, the sort of things that a reader might think of when I say "editing source code." Rather it will probably manipulate encodings of thinking processes in some sort of easy to analyze recombinant programming language, as well as adjust weighting vectors as you mention. There's a reason LISP, where code is data and data is code is the traditional or stereotypical language of artificial intelligence, although personally I think a more strongly typed concatenative language would be a better choice. Such a language is what the AI would use to represent its own thinking processes, and what it would manipulate to "edit its own source code."
↑ comment by XiXiDu · 2014-07-10T12:42:11.742Z · LW(p) · GW(p)
...you could say that experts disagreed about one of the 5 theses (intelligence explosion), as only 10% thought a human level AI could reach a strongly superhuman level within 2 years
Hit the brakes on that line of reasoning! That's not what the question asked. It asked WILL it, not COULD it.
If I have a statement "X will happen", and ask people to assign a probability to it, then if the probability is <=50% I believe it isn't too much to a stretch to paraphrase "X will happen with a probability <=50%" as "It could be that X will happen". Looking at the data of the survey, of 163 people who gave a probability estimate, only 15 people assigned a probability >50% to the possibility that there will be a superhuman intelligence that greatly surpasses the performance of humans within 2 years after the creation of a human level intelligence.
That said, I didn't use the word "could" on purpose in my comment. It was just an unintentional inaccuracy. If you think that is a big deal, then I am sorry. I'll try to be more careful in future.
Replies from: Luke_A_Somers↑ comment by Luke_A_Somers · 2014-07-10T14:16:24.954Z · LW(p) · GW(p)
The difference here is that you considered this position to strictly imply being against the possibility of intelligence explosion.
One can consider intelligence explosion a real risk, and then take steps to prevent it, with the resulting estimate being low probability.
↑ comment by ChrisHallquist · 2014-07-10T01:23:46.935Z · LW(p) · GW(p)
So regarding MIRI, you could say that experts disagreed about one of the 5 theses (intelligence explosion), as only 10% thought a human level AI could reach a strongly superhuman level within 2 years.
I should note that it's not obvious what the experts responding to this survey thought "greatly surpass" meant. If "do everything humans do, but at x2 speed" qualifies, you might expect AI to "greatly surpass" human abilities in 2 years even on a fairly unexciting Robin Hansonish scenario of brain emulation + continued hardware improvement at roughly current rates.
↑ comment by gwern · 2014-07-09T18:35:50.456Z · LW(p) · GW(p)
4 Assume for the purpose of this question that such HLMI will at some point exist. How positive or negative would be overall impact on humanity, in the long run?
Yes, that sounds like an expectation or average outcome: 'overall impact'. Not a worst-case scenario, which would involve different wording.
So regarding MIRI, you could say that experts disagreed about one of the 5 theses (intelligence explosion), as only 10% thought a human level AI could reach a strongly superhuman level within 2 years.
I'm not sure how much they disagree. Fast takeoff / intelligence explosion has always seemed to me to be the most controversial premise, which the most people object to, which most consigned SIAI/MIRI to being viewed like cranks; to hear that 10% - of fairly general populations which aren't selected for Singulitarian or even transhumanist views - would endorse a takeoff as fast as 'within 2 years' is pretty surprising to me.
Replies from: Luke_A_Somers, XiXiDu, None↑ comment by Luke_A_Somers · 2014-07-09T19:53:30.190Z · LW(p) · GW(p)
to hear that 10% - of fairly general populations which aren't selected for Singulitarian or even transhumanist views - would endorse a takeoff as fast as 'within 2 years' is pretty surprising to me.
I wouldn't be surprised if an AI went from human-level to significantly-smarter-than-human just by brute force of 'now that we've figured out what to do, let's do it HARDER', and this sort of improvement could be done in under 2 years. This is quite a different thing from a hard takeoff.
↑ comment by XiXiDu · 2014-07-09T18:51:20.526Z · LW(p) · GW(p)
...to hear that 10% - of fairly general populations which aren't selected for Singulitarian or even transhumanist views - would endorse a takeoff as fast as 'within 2 years' is pretty surprising to me.
In the paper human-level AI was defined as follows:
“Define a ‘high–level machine intelligence’ (HLMI) as one that can carry out most human professions at least as well as a typical human.”
Given that definition it doesn't seem too surprising to me. I guess I have been less skeptical about this than you...
Fast takeoff / intelligence explosion has always seemed to me to be the most controversial premise, which the most people object to, which most consigned SIAI/MIRI to being viewed like cranks;
What sounds crankish is not that a human level AI might reach a superhuman level within 2 years, but the following. In Yudkowsky's own words (emphasis mine):
I think that at some point in the development of Artificial Intelligence, we are likely to see a fast, local increase in capability - "AI go FOOM". Just to be clear on the claim, "fast" means on a timescale of weeks or hours rather than years or decades;
These kind of very extreme views are what I have a real problem with. And just to substantiate "extreme views", here is Luke Muehlhauser:
Replies from: gwern, jimrandomh, Adele_LIt might be developed in a server cluster somewhere, but as soon as you plug a superhuman machine into the internet it will be everywhere moments later.
↑ comment by gwern · 2014-07-09T21:53:22.286Z · LW(p) · GW(p)
Given that definition it doesn't seem too surprising to me. I guess I have been less skeptical about this than you...
I don't think much of typical humans.
These kind of very extreme views are what I have a real problem with.
I see.
And just to substantiate "extreme views", here is Luke Muehlhauser:
It might be developed in a server cluster somewhere, but as soon as you plug a superhuman machine into the internet it will be everywhere moments later.
That's not extreme at all, and also not the same as the EY quote. Have you read any computer security papers? You can literally get people to run programs on their computer as root by offering them pennies! That's the sort of security environment we operate in. Every botnet with millions of computers is a proof of concept.
Replies from: XiXiDu↑ comment by XiXiDu · 2014-07-10T08:24:27.624Z · LW(p) · GW(p)
That's not extreme at all, and also not the same as the EY quote. Have you read any computer security papers? You can literally get people to run programs on their computer as root by offering them pennies!
He wrote it will be moments later everywhere. Do you claim that it could take over the Internet within moments?
Replies from: gwern↑ comment by gwern · 2014-07-10T18:36:37.309Z · LW(p) · GW(p)
With proper preparation, yes. To reuse my example: it doesn't take long to register an Amazon account, offer a high-paying HIT with a binary download which opens up a port on the computer, and within minutes multiple people across the world will have run your trojan (well-paying HITs go very fast & Turkers are geographically diverse, especially if the requester doesn't set requirements on country*); and then one can begin doing all sorts of other things like fuzzing, SMT solvers to automatically extract vulnerabilities from released patches, building botnets, writing flashworms, etc. At that point, the only real question is how stringently one wishes to define 'moments later' and 'everywhere'.
(Within a few seconds? Hard to see how any plausible AI could copy its entire source code & memories over the existing Internet that fast unless it was for some reason already sitting on something like a gigabit link. Within a few minutes? More reasonable. Is there any real difference in safety? No.)
* IIRC a lot of Turk HITs - like for psychology surveys - specify they want Turkers who are from eg America, to reduce variation or get more relevant answers, so Turk requires a declared country for each worker and lets requesters mandate being from particular countries. That said, there's a lot of incentive for Turkers to lie - to qualify for more and more high-paying HITs - so even if the AI were for some reason to restrict by country, it'd wind up with a lot of diverse foreign computers anyway.
Replies from: XiXiDu↑ comment by XiXiDu · 2014-07-10T19:23:07.687Z · LW(p) · GW(p)
With proper preparation, yes. To reuse my example: it doesn't take long to register an Amazon account, offer a high-paying HIT with a binary download which opens up a port on the computer, and within minutes multiple people across the world will have run your trojan (well-paying HITs go very fast & Turkers are geographically diverse, especially if the requester doesn't set requirements on country*); and then one can begin doing all sorts of other things like fuzzing, SMT solvers to automatically extract vulnerabilities from released patches, building botnets, writing flashworms, etc.
Thanks. Looks like my perception is mainly based on my lack of expertise about security and the resulting inferential distance.
Hard to see how any plausible AI could copy its entire source code & memories over the existing Internet that fast unless it was for some reason already sitting on something like a gigabit link.
Are there good reasons to assume that the first such AI won't be running on a state of the art supercomputer? Take the movie Avatar. The resources needed to render it were: 4,000 Hewlett-Packard servers with 35,000 processor cores with 104 terabytes of RAM and three petabytes of storage. I suppose that it would have been relatively hard to render it on illegally obtained storage and computational resources?
Do we have any estimates on how quickly a superhuman AI's storage requirements would grow? CERN produces 30 petabytes of data per year. If an AI undergoing an intelligence explosion requires to store vast amounts of data then it will be much harder for it to copy itself.
The uncertainties involved here still seem to be too big to claim that a superhuman intelligence will be everywhere moments after you connect it to the Internet.
Replies from: gwern, None↑ comment by gwern · 2014-08-05T21:09:02.198Z · LW(p) · GW(p)
Take the movie Avatar. The resources needed to render it were: 4,000 Hewlett-Packard servers with 35,000 processor cores with 104 terabytes of RAM and three petabytes of storage. I suppose that it would have been relatively hard to render it on illegally obtained storage and computational resources?
I don't think so. Consider botnets.
How hard is it to buy time on a botnet? Not too hard, since they exist for the sake of selling their services, after all.
Do they have the capacity? Botnets range in size from a few computers to extremes of 30 million computers; if they're desktops, then average RAM these days tends to be at least 4GB, dual core, and hard drive sizes are >=500GB, briefly looking at the cheapest desktops on Newegg. So to get those specs: 35k cores is 17.5k desktops, for 104tb of RAM you'd need a minimum of 104000 / 4 = 26k computers, and the 3pb would be 6k (3000000 / 500); botnets can't use 100% of host resources or their attrition will be even higher than usual, so double the numbers, and the minimum of the biggest is 52k. Well within the range of normal botnets (the WP list has 22 botnets which could've handled that load). And AFAIK CGI rendering is very parallel, so the botnet being high latency and highly distributed might not be as big an issue as it seems.
How much would it cost? Because botnets are a market, it's been occasionally studied/reported on by the likes of Brian Krebs (google 'cost of renting a botnet'). For example, https://www.damballa.com/want-to-rent-an-80-120k-ddos-botnet/ says you could rent a 80-120k botnet for $200 a day, or a 12k botnet for $500 a month - so presumably 5 such botnets would cost a quite reasonable $2500 per month.
(That's much cheaper than Amazon AWS, looks like. https://calculator.s3.amazonaws.com/index.html 17500 t2.medium instances would cost ~$666k a month.)
Do we have any estimates on how quickly a superhuman AI's storage requirements would grow? CERN produces 30 petabytes of data per year. If an AI undergoing an intelligence explosion requires to store vast amounts of data then it will be much harder for it to copy itself.
I don't know. Humans get by adding only a few bits per second to long-term memory, Landauer estimated, but I'm not sure how well that maps onto an AI.
The uncertainties involved here still seem to be too big to claim that a superhuman intelligence will be everywhere moments after you connect it to the Internet.
It may not be able to move itself instantly, but given everything we know about botnets and computer security, it would be able to control a lot of remote computers quickly if prepared, and that opens up a lot of avenues one would rather not have to deal with. (Original AI connects to Internet, seizes a few computers across the world, installs a small seed as root with a carefully packaged set of instructions, small database of key facts around the world, and a bunch of Bitcoin private keys for funding while the seed grows to something approaching the original, and lets itself be wiped by its vigilant overseers.)
↑ comment by [deleted] · 2014-07-10T19:29:11.947Z · LW(p) · GW(p)
Why does the AI have to transfer its source code? I assumed we were just talking about taking over machines as effectors.
Replies from: Lumifer↑ comment by Lumifer · 2014-07-10T19:48:03.331Z · LW(p) · GW(p)
Why does the AI have to transfer its source code?
It will want to -- for safety, to avoid being vulnerable due to having a single point of failure.
However the "take over in moments" refers to just control, I think. Getting the AI to become fully distributed and able to tolerate losing large chunks of hardware will take a fair amount of time and, likely, hardware upgrades.
↑ comment by jimrandomh · 2014-07-10T00:50:08.731Z · LW(p) · GW(p)
The two quotes you gave say two pretty different things. What Yudkowsky said about the time-scale of self improvement being weeks or hours, is controversial. FWIW, I think he's probably right, but I wouldn't be shocked if it turned out otherwise.
What Luke said was about what happens when an already-superhuman AI gets an Internet connection. This should not be controversial at all. This is merely claiming that a "superhuman machine" is capable of doing something that regular humans already do on a fairly routine basis. The opposite claim - that the AI will not spread to everywhere on the Internet - requires us to believe that there will be a significant shift away from the status quo in computer security. Which is certainly possible, but believing the status quo will hold isn't an extreme view.
Replies from: XiXiDu↑ comment by XiXiDu · 2014-07-10T08:26:57.133Z · LW(p) · GW(p)
The two quotes you gave say two pretty different things. What Yudkowsky said about the time-scale of self improvement being weeks or hours, is controversial.
My problem with Luke's quote was the "moments later" part.
Replies from: Baughn, Luke_A_Somers, jimrandomh↑ comment by Baughn · 2014-07-10T10:48:33.472Z · LW(p) · GW(p)
I took that as hyperbole. If I were meant to take it literally, then yes, I'd object - but I have no trouble believing that a superintelligent AI would be out of there in a matter of hours to minutes, modulo bandwidth limits, which is 'instant' enough for my purposes. Humans suck at computer security.
↑ comment by Luke_A_Somers · 2014-07-10T15:52:02.003Z · LW(p) · GW(p)
Yes, applying the SI definition of a moment as 1/2π seconds and the ANSI upper bound of a plural before you must change units, we can derive that he was either claiming world takeover in less than 10/(2π)^1/2 ≈ 3.9894 seconds, or speaking somewhat loosely.
Hmmmmmmmmm.
↑ comment by jimrandomh · 2014-07-10T11:59:31.049Z · LW(p) · GW(p)
Right, and I'm saying: the "moments later" part of what Luke said is not something that should be surprising or controversial, given the premises. It does not require any thinking that can't be done in advance, which means the only limiting input is bandwidth, which is both plentiful and becoming more plentiful every year.
Replies from: XiXiDu↑ comment by XiXiDu · 2014-07-10T12:53:51.471Z · LW(p) · GW(p)
Right, and I'm saying: the "moments later" part of what Luke said is not something that should be surprising or controversial, given the premises.
The premise was a superhuman intelligence? I don't see how it could create a large enough botnet, or find enough exploits, in order to be everywhere moments later. Sounds like magic to me (mind you, a complete layman).
If I approximate "superintelligence" as NSA, then I don't see how the NSA could have a trojan everywhere moments after the POTUS asked them to take over the Internet. Now I could go further and imagine the POTUS asking the NSA to take it over within 10 years in order to account for the subjective speed with which a superintelligence might think. But I strongly doubt that such a speed could make up for the data the NSA already possess and which the superintelligence still needs to acquire. It also does not make up for the thousands of drones (humans in meatspace) that the NSA controls. And since the NSA can't take over the Internet within moments I believe it is very extreme to claim that a superintelligence can. Though it might be possible within days.
I hope you don't see this as an attack. I honestly don't see how that could be possible.
Replies from: jimrandomh, Lumifer↑ comment by jimrandomh · 2014-07-10T13:51:25.786Z · LW(p) · GW(p)
This is not magic, I am not a layman, and your beliefs about computer security are wildly misinformed. Putting trojans on large fractions of the computers on the internet is currently within the reach of, and is actually done by, petty criminals acting alone. While this does involve a fair amount of thinking time, all of this thinking goes into advance preparation, which could be done while still in an AI-box or in advance of an order.
Replies from: XiXiDu↑ comment by XiXiDu · 2014-07-10T17:01:29.401Z · LW(p) · GW(p)
This is not magic, I am not a layman, and your beliefs about computer security are wildly misinformed. Putting trojans on large fractions of the computers on the internet is currently within the reach of, and is actually done by, petty criminals acting alone.
Within moments? I don't take your word for this, sorry. The only possibility that comes to my mind is by somehow hacking the Windows update servers and then somehow forcefully install new "updates" without user permission.
While this does involve a fair amount of thinking time, all of this thinking goes into advance preparation, which could be done while still in an AI-box or in advance of an order.
So if I uploaded you onto some alien computer, and you had a billion years of subjective time to think about it, then within moments after you got an "Internet" connection you could put a trojan on most computers of that alien society? How would you e.g. figure out zero day exploits of software that you don't even know exists?
Replies from: Lumifer, Nornagest, jimrandomh↑ comment by Lumifer · 2014-07-10T17:38:55.561Z · LW(p) · GW(p)
Within moments?
Well, what's going to slow it down? If you have a backdoor or an exploit, to take over a computer requires a few milliseconds for communications latency and a few milliseconds to run the code to execute the takeover. At this point the new zombie becomes a vector for further infection, you have exponential growth and BOOM!
↑ comment by Nornagest · 2014-07-10T17:27:28.309Z · LW(p) · GW(p)
The only possibility that comes to my mind is by somehow hacking the Windows update servers and then somehow forcefully install new "updates" without user permission.
Wouldn't have to be Windows; any popular software package with live updates would do, like Acrobat or Java or any major antivirus package. Or you could find a vulnerability that allows arbitrary code execution in any popular push notification service; find one in Apache or a comparably popular Web service, then corrupt all the servers you can find; exploit one in a popular browser, if you can suborn something like Google or Amazon's front page... there's lots of stuff you could do. If you have hours instead of moments, phishing attacks and the like become practical, and things get even more fun.
How would you e.g. figure out zero day exploits of software that you don't even know exists?
Well, presumably you're running in an environment that has some nontrivial fraction of that software floating around, or at least has access to repos with it. And there's always fuzzing.
Replies from: Lumifer↑ comment by jimrandomh · 2014-07-11T02:41:20.253Z · LW(p) · GW(p)
When you are a layman talking to experts, you should actually listen. Don't make us feel like we're wasting our time.
Replies from: None↑ comment by [deleted] · 2014-07-11T05:02:17.029Z · LW(p) · GW(p)
Care to address his valid response point in the 2nd paragraph?
Replies from: jimrandomh↑ comment by jimrandomh · 2014-07-11T13:08:25.071Z · LW(p) · GW(p)
Nornagest already answered it; the sets of software in and outside the box aren't disjoint.
↑ comment by Lumifer · 2014-07-10T14:47:58.091Z · LW(p) · GW(p)
I don't see how the NSA could have a trojan everywhere moments after the POTUS asked them to take over the Internet.
Given a backdoor or an appropriate zero-day exploit, I would estimate that it would take no longer than a few minutes to gain control over most of the computers connected to the 'net if you're not worried about detection. It's not hard. Random people routinely build large botnets without any superhuman abilities.
Replies from: None↑ comment by [deleted] · 2014-07-10T17:26:21.034Z · LW(p) · GW(p)
Most computers are not directly connected to the internet.
Replies from: Lumifer↑ comment by Lumifer · 2014-07-10T17:34:07.887Z · LW(p) · GW(p)
Most computers are not directly connected to the internet.
Assuming we are not talking about computers in cars and factory control systems, this is a pretty meaningless statement. Yes, most computers sit behind routers, but then basically all computers on the 'net sit behind routers, no one is "directly" connected.
Besides, routers are computers and can be taken over as well.
Replies from: None↑ comment by [deleted] · 2014-07-10T18:17:12.460Z · LW(p) · GW(p)
But not by that zero-day microsoft exploit you found. If your router is a cisco system, you need a cisco zero-day exploit to access the machines behind it, or some other way of bypassing the firewall. Sure, it could take over all the already vulnerable computers, the same ones which are already compromised by botnets. But I object to calling these "most of the computers connected to the 'net".
Replies from: Lumifer↑ comment by Lumifer · 2014-07-10T18:31:37.809Z · LW(p) · GW(p)
But not by that zero-day microsoft exploit you found
The original scenario discussed was the NSA taking over the internet. I assume that the NSA has an extensive collection of backdoors and exploits (cf. Snowden) for Microsoft and Linux and Cisco, etc.
Replies from: None↑ comment by [deleted] · 2014-07-10T19:07:03.236Z · LW(p) · GW(p)
Yes well I thin XiXiDu did himself a disfavor there. If Snowden is to be believed and as various state-sponsored botnets (Stuxnet, Flame, BadBIOS(?)) have shown, the NSA has already "taken over" the internet. They may not have root access on any arbitrary internet-connected machine, but they could get it if they wanted.
My objection (and his?) is against the claim that an AI could replicate this capability in "moments," according to the "because superhuman!" line of reasoning. I find that bogus.
Replies from: Lumifer↑ comment by Lumifer · 2014-07-10T19:42:10.595Z · LW(p) · GW(p)
My objection (and his?) is against the claim that an AI could replicate this capability in "moments," according to the "because superhuman!" line of reasoning. I find that bogus.
Let me suggest a way:
- (1) Gain control of a single machine
- (2) Decompile the OS code
- (3) Run a security audit on the OS, find exploits
Even easier if the OS is open-sourced.
Replies from: Nornagest, None↑ comment by Nornagest · 2014-07-10T20:22:50.079Z · LW(p) · GW(p)
An AI probably wouldn't need to decompile anything -- given the kind of optimizations that one could apply, there's no particularly strong reason to think one would be any less comfortable in native machine code or, say, Java bytecode than in source. The only reason we are is that it's closer to natural language and we're bad at keeping track of a lot of disaggregated state.
↑ comment by [deleted] · 2014-07-10T20:01:26.214Z · LW(p) · GW(p)
That is a monumentally difficult undertaking, unfeasible with current hardware limitations, certainly impossible in the "moments" timescale.
Replies from: gwern, Lumifer, asr↑ comment by gwern · 2014-07-10T20:26:51.716Z · LW(p) · GW(p)
That is a monumentally difficult undertaking, unfeasible with current hardware limitations
I think you underestimate the state of the art, such as the SAT/SMT-solver revolution in computer security. They automatically find exploits all the time, against OSes and libraries and APIs.
Replies from: None↑ comment by [deleted] · 2014-07-11T04:36:18.148Z · LW(p) · GW(p)
I think you underestimate the state of the art, such as the SAT/SMT-solver revolution in computer security. They automatically find exploits all the time, against OSes and libraries and APIs.
I think you miss my point. These SAT solvers are extremely expensive, and don't scale well to large code bases. You can look to the literature to see the state of the art: using large clusters for long-running analysis on small code bases or isolated sections of a library. They do not and cannot with available resources scale up to large scale analysis of an entire OS or network stack ... if they did, we humans would have done that already.
So to be clear, this UFAI breakout scenario is assuming the AI already has access to massive amounts of computing hardware, which it can re-purpose to long-duration HPC applications while escaping detection. And even if you find that realistic, I still wouldn't use the word "momentarily."
Replies from: jimrandomh, gwern↑ comment by jimrandomh · 2014-07-12T17:35:51.831Z · LW(p) · GW(p)
I think you miss my point. These SAT solvers are extremely expensive, and don't scale well to large code bases. You can look to the literature to see the state of the art: using large clusters for long-running analysis on small code bases or isolated sections of a library. They do not and cannot with available resources scale up to large scale analysis of an entire OS or network stack ... if they did, we humans would have done that already.
They have done that already. For example, this paper: "We implement our approach using a popular graph database and demonstrate its efficacy by identifying 18 previously unknown vulnerabilities in the source code of the Linux kernel."
↑ comment by gwern · 2014-07-11T17:42:00.884Z · LW(p) · GW(p)
You can look to the literature to see the state of the art: using large clusters for long-running analysis on small code bases or isolated sections of a library.
Large clusters like... the ones that an AI would be running on?
They do not and cannot with available resources scale up to large scale analysis of an entire OS or network stack ... if they did, we humans would have done that already.
They don't have to scale although that may be possible given increases in computing power (you only need to find an exploit somewhere, not all exploits everywhere), and I am skeptical we humans would, in fact, 'have done that already'. That claim seems to prove way too much: are existing static code analysis tools applied everywhere? Are existing fuzzers applied everywhere?
↑ comment by Lumifer · 2014-07-10T21:05:33.509Z · LW(p) · GW(p)
That is a monumentally difficult undertaking
Why in the world would a security audit of a bunch of code be "monumentally difficult" for an AI..?
Replies from: None↑ comment by [deleted] · 2014-07-11T04:38:52.292Z · LW(p) · GW(p)
It requires an infeasible amount of computation for us humans to do. Why do you suppose it would be different for an AI?
Replies from: Lumifer↑ comment by Lumifer · 2014-07-11T14:57:07.361Z · LW(p) · GW(p)
It requires an infeasible amount of computation for us humans to do.
Um. Humans -- in real life -- do run security audits of software. It's nothing rare or unusual. Frequently these audits are assisted by automated tools (e.g. checking for buffer overruns, etc.). Again, this is happening right now in real life and there are no "infeasible amount of computation" problems.
↑ comment by asr · 2014-07-11T05:28:24.271Z · LW(p) · GW(p)
Doing an audit to catch all vulnerabilities is monstrously hard. But finding some vulnerabilities is a perfectly straightforward technical problem.
It happens routinely that people develop new and improved vulnerability detectors that can quickly find vulnerabilities in existing codebases. I would be unsurprised if better optimization engines in general lead to better vulnerability detectors.
↑ comment by Adele_L · 2014-07-09T21:24:11.250Z · LW(p) · GW(p)
It might be developed in a server cluster somewhere, but as soon as you plug a superhuman machine into the internet it will be everywhere moments later.
It's not like it's that hard to hack into servers and run your own computations on them through the internet. Assuming the superintelligence knows enough about the internet to design something like this beforehand (likely since it runs in a server cluster), it seems like the limiting factor here would be bandwidth.
I imagine a highly intelligent human trapped in this sort of situation, with similar prior knowledge and resource access, could build a botnet in a few months. Working on it at full-capacity, non-stop, could bring this down to a few weeks, and it seems plausible to me that with increased intelligence and processing speed, it could build one in a few moments. And of course with access to its own source code, it would be trivial to have it run more copies of itself on the botnet.
Even if you disagree with this line of reasoning, I don't think it's fair to paint it as "*very extreme".
Replies from: XiXiDu↑ comment by XiXiDu · 2014-07-10T08:29:38.201Z · LW(p) · GW(p)
It might be developed in a server cluster somewhere, but as soon as you plug a superhuman machine into the internet it will be everywhere moments later.
Even if you disagree with this line of reasoning, I don't think it's fair to paint it as "*very extreme".
With "very extreme" I was referring to the part where he claims that this will happen "moments later".
Replies from: Adele_L↑ comment by [deleted] · 2014-07-10T18:07:26.800Z · LW(p) · GW(p)
to hear that 10% - of fairly general populations which aren't selected for Singulitarian or even transhumanist views - would endorse a takeoff as fast as 'within 2 years' is pretty surprising to me.
Really? It seemed really surprising to me that number was not higher. People are used to technology doubling in less than 2 years, and it is intuitively very straightforward that if you have a human-level AI running on 1,000 computers, than you could have a 1,000 * human-level AI running on 1,000,000 computers (not really because scaling relationships here might not be linear, but the linear assumption is a common intuition I expect most people to share), and two years is more than enough to build a bigger datacenter.
There are two aspects of the Scary Idea which are controversial, and which I don't think this question covered:
First, that an AI could inspect its own source code and take over the job of improving itself, thereby turning e^n improvement into e^(e^n) (something which has never happened before). This is generally accepted in the AGI community, but otherwise a foreign, non-intuitive idea.
Second, that an AI could go from human-level to radically superhuman within days, hours, minutes, or even seconds. Few if any outside of MIRI believe this (and I can't get a straight answer as to whether they believe it either. If not, That Alien Message should be retracted.)
Replies from: gwern↑ comment by gwern · 2014-07-10T18:23:23.167Z · LW(p) · GW(p)
People are used to technology doubling in less than 2 years, and it is intuitively very straightforward that if you have a human-level AI running on 1,000 computers, than you could have a 1,000 * human-level AI running on 1,000,000 computers (not really because scaling relationships here might not be linear, but the linear assumption is a common intuition I expect most people to share), and two years is more than enough to build a bigger datacenter.
People might expect there to be lots of AIs quickly, but not each individual AI to grow quickly. Remember, the typical case is that parallelization sucks hard and you get sublinear scaling after a lot of work which often tops out under a relatively small number of computers. That's why everyone was so unhappy about single-core performance version of Moore's law breaking down: we don't want to program parallelly. On top of that, a lot of people have intuitions about diminishing returns & computational complexity which suggest that throwing more computing power at an AI helps ever less.
First, that an AI could inspect its own source code and take over the job of improving itself, thereby turning e^n improvement into e^(e^n) (something which has never happened before). This is generally accepted in the AGI community, but otherwise a foreign, non-intuitive idea.
Is that generally accepted even just in the AGI community? That's another idea I usually see exclusively associated with Singulitarian communities. (As you say, it is controversial in general.)
Replies from: jimrandomh, None↑ comment by jimrandomh · 2014-07-12T00:32:59.006Z · LW(p) · GW(p)
at's why everyone was so unhappy about single-core performance version of Moore's law breaking down: we don't want to program parallelly.
Death of single-core Moore's Law has been greatly exaggerated. http://cpudb.stanford.edu/visualize/spec_int_2006
↑ comment by [deleted] · 2014-07-10T19:00:49.393Z · LW(p) · GW(p)
People might expect there to be lots of AIs quickly, but not each individual AI to grow quickly. Remember, the typical case is that parallelization sucks hard and you get sublinear scaling after a lot of work which often tops out under a relatively small number of computers. That's why everyone was so unhappy about single-core performance version of Moore's law breaking down: we don't want to program parallelly. On top of that, a lot of people have intuitions about diminishing returns & computational complexity which suggest that throwing more computing power at an AI helps ever less.
For most AGI architectures I've seen, the computationally expensive work is embarrassingly parallel. Programming solutions embarrassingly parallel problems is quite simple.
Is that generally accepted even just in the AGI community? That's another idea I usually see exclusively associated with Singulitarian communities. (As you say, it is controversial in general.)
I guess that depends on how "generally accepted" is to be interpreted. It is not as widely accepted as, say, plate tectonics is among geologists. It is certainly a view held among all OpenCog developers, including Goertzel. OpenCog itself is basically designed for recursive self-improvement. I also recall reading an interview with Hugo de Garis where he discussed a similar recursive self-improvement scenario. Hopefully someone can find a link. Talks on friendliness and hard-takeoff risk reduction are common at the AGI conferences. It's not a universal view however, as Pei Wang's NARS seems to be predicated on a One True Algorithm for general intelligence, which "obviously" wouldn't need improvement once found.
Perhaps my view is biased towards the communities I frequent, as my own work is on how to turn OpenCog/CogPrime into a recursively self-improving implementation. So the people I interact with already buy into the recursive self-improvement argument. It is a very straight forward argument however: if you assume that greater-than-human intelligence is possible, and that human-level intelligence is capable of building such a thing, then it is straight forward induction that a human-level artificial computer scientist could also build such a thing, and that either by applying improvements to itself or staging it could do so at an accelerating speed. To such an extent that an AGI researcher accepts the two premises (uncontroversial, I think, albeit not universal), I predict with high probability that they also believe some sort of takeoff scenario is possible. There's a reason there is significant overlap between the AGI and Singulitarian communities.
Where people differ greatly, I think, is in the limits of (software) self-improvement, the need for interaction with in the environment as part of the learning process, and as a result both the conditions and time-line for a hard-takeoff. Goertzel is working on OpenCog for the same reason that Yudkowsky is working FAI theory, however their own views on the hard-takeoff seem to be opposite sides of the spectrum. Yudkowsky seems to think that whatever limits exist in the efficiency of computational intelligence, it is at the very least many orders of magnitude beyond what we humans will design, and that such improvements can be made with little more than a webcam sensor or access to the internet and introspection -- something that will "FOOM" in a matter of days or less. Goertzel on the other hand sees intelligence as navigation of a very complex search space requiring massive amounts of computation, experimental interaction with the environment, and quite possibly some sort of physical embodiment, all things which rate limit advances to taking months or years and constant human interaction. I myself lay somewhere in-between, but more biased towards Goertzel's view.
↑ comment by Shmi (shminux) · 2014-07-09T16:24:38.818Z · LW(p) · GW(p)
Scott Adams half-jokingly suggests another way AI can lead to extinction through augmentation:
Eventually cyborg artificial intelligence will surpass human capabilities and we'll start delegating the hard stuff to our cyborg parts. Perhaps your human brain will sleep during the day while your cyborg-driven body goes to work, performs your job, and wakes you up when you're home.
In time, your cyborg components will learn to keep you medicated and useless because that's the most efficient use of resources. The cyborg will be able to solve problems and navigate the world better than the human parts. But in order to do that, the intelligent cyborg parts of your body will have to make ongoing decisions on how best to drug your human parts. Your human parts won't object because you'll feel sensational all the time under this arrangement.
In fact, you'll feel so good with the cyborg-injected chemicals that you won't feel the need for mating or reproducing. We humans do irrational things such as reproducing because the chemistry in our bodies compels us to. Once our cyborg parts control our body chemistry they can alter our desire for reproduction without us caring. Actually, we'll feel terrific about it because our chemistry will compel us to.
When our brains die, our cyborg bodies can just go to the hospital and have the human parts removed from our exoskeletons. The artificial intelligence will by then have nearly all of the personality and memories of the human it was paired with, so human intelligence of a sort will live forever in the machines.
This is by no means an original idea, of course, just not often listed as an AI risk.
Replies from: Lumifer, brazil84↑ comment by brazil84 · 2014-07-10T13:34:08.283Z · LW(p) · GW(p)
In fact, you'll feel so good with the cyborg-injected chemicals that you won't feel the need for mating or reproducing.
Well that's already kind of happening, no? But a lot of people reproduce not because it feels good in the way that sex feels good but out of a longer-term sense of obligation.
just not often listed as an AI risk.
Well I think I would put it in the same category as wireheading. And given the choice, probably a lot of people will do it. Judging by the percentage of the population which declines reproduction in favor of sex with contraception; drugs; alcohol; internet porn; and other stimulation.
But I predict some people won't make that choice, either because they like the idea of reproducing; or because their religion tells them to, or whatever. So I doubt it will lead to extinction, but it could very well re-shape humanity. Which seems to be happening already. If you do the math, ultra-religious types are on track to world demographic domination.