Knowledge Localization: Tentatively Positive Results on OCR
post by J Bostock (Jemist) · 2022-01-30T11:57:19.151Z · LW · GW · 0 commentsContents
The Plan Methods Analysis Conclusions and Further Plans None No comments
Epistemic Status: Original research, see previous post for more information
The Plan
- Hard-code a simple ML system in Python (yikes!) so I can see all of the moving parts and understand it better.
- Give the ML system something to learn (in this case OCR based on the MNIST dataset, because it's easy to get hold of and basically a solved problem in terms of actually classifying characters)
- Actually test my hypothesis:
Methods
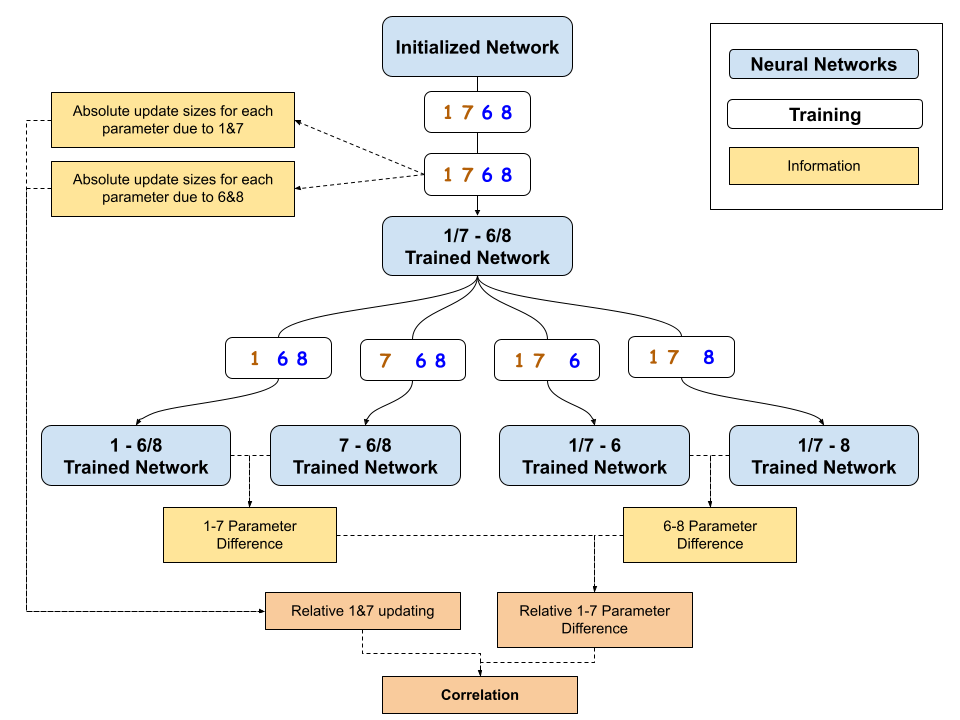
The neural network used is simple, 784 neurons on the input layer, 100 hidden neurons, 2 output. The activation function used is . All weights and biases were initialized with He initialization. For compatibility reasons the data label is either or . The input values are normalized to be between and rather than and .
The learning process involves backpropagating on a single datapoint (one labelled character) at a time. Overall loss appears to reach a minimum early within the first training epoch. For this reason the first 1200 of 60,000 datapoints were used for phase 1. This refers to training a single neural network on a dataset consisting of all of the 6s and 8s; and 1s and 7s, from the first 12000 datapoints (keeping roughly equal numbers of the two types of data helps to keep the biases and weights towards the last layer from having large changes in any one direction).
During the second half of phase 1, the absolute value of the change of each parameter is added to one of two running tallies, one for 1s/7s and one for 6s/8s. Then the total updating done to each parameter by each class of datapoint can be found. This amounts to summing the absolute value of the update sizes from each datapoint. The "relative updating due to 1s/7s" variable for each parameter is then where is the sum of the updates due to 1s and 7s, and is the sum of the updates due to 6s and 8s. (The correlation still holds whether we look at all of phase 1 or just the second half, but I've found it to be slightly stronger for the second half of training.
Then four copies of the network are made. Both are trained on the remainder of the MNIST dataset, one on 1s and 6s/8s, one on 7s and 6s/8s; then one on 1s/7s and 6s, and one on 1s/7s and 8s. The difference in the final parameter values between these two pairs of networks is then found. We then take a similar function where is the absolute difference between the parameter values of the 1s vs 6s/8s case and the 7s vs 6s/8s case, and is the difference between the parameter values of the 6s vs 1s/7s case, and the 8s vs 1s/7s case.
Analysis
The hypothesis I was testing is about what update sizes during training can tell us about where knowledge is stored in a network. The primary plots are of "relative amount of updating due to 1s/7s" against the relative difference between the 1s vs 6s/8s and 7s vs 6s/8s forks. A plot which was strong evidence in favour of my hypothesis would basically just be a positive correlation. The parameters which were (relatively) more different in the cases of the data being 1s vs 7s would have updated more due to 1s and 7s.
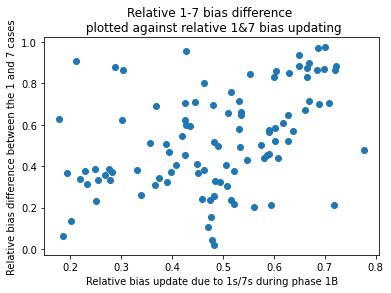
Weak-ish correlation for biases, , by T-test if you're into that.
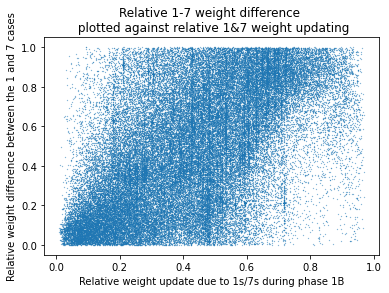
Correlation for weights is very clear. . I'm not going to calculate a p-value here because I have eyes.
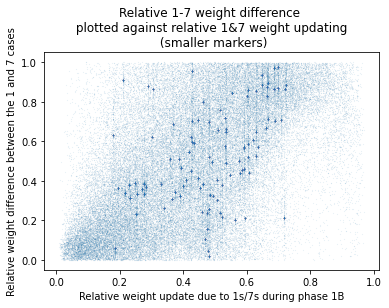
If we make the markers smaller we can see little clusters. I'm pretty confident each of these clusters is a set of weights going into one of the second layer neurons. Lots of weights will be coming from input neurons which only ever have a value of , so they're all effectively the same. The pattern of clusters is almost identical to the pattern of bias updates.
More interestingly we can also plot the correlation between our two values for the weights coming out of each of the input neurons.
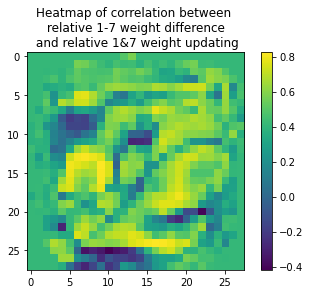
I'm not completely sure how to interpret this. Overall correlation is mostly but we have some regions of negative correlation. Round the edges the correlation is much weaker as these only ever take as input.
Conclusions and Further Plans
So this worked pretty well. This is some weak evidence for my hypothesis. Without a doubt the most interesting thing is that this only worked for a ReLU-like activation function. I was originally using sigmoid activation functions and I couldn't get anything like this. That's really weird and other than ReLU being magic, I have no hypotheses.
I want to try this out on other systems. I wonder if a more abstraction-heavy system would make a better candidate. I'd like to find out when these correlations are stronger or weaker. For this I'll need to mess around with some ML libraries to see if I can extract the data I want. Hard-coding a neural network in the slowest language known to man was a bad time.
0 comments
Comments sorted by top scores.