Will Machines Ever Rule the World? MLAISU W50
post by Esben Kran (esben-kran) · 2022-12-16T11:03:34.968Z · LW · GW · 7 commentsThis is a link post for https://newsletter.apartresearch.com/posts/will-machines-ever-rule-the-world-mlaisu-w50
Contents
Hopes & Fears of AI Safety GPU Performance Predictions “Why Machines Will Never Rule the World” Other news Opportunities None 7 comments
Watch this week's episode on YouTube or listen to the audio version here.
Hopes and fears of the current AI safety paradigm, GPU performance predictions and popular literature on why machines will never rule the world. Welcome to the ML & AI safety Update!
Hopes & Fears of AI Safety
Karnofsky released an article in his Cold Takes blog describing his optimistic take on how current methods might lead to safe AGI:
- Utilizing the nascent field of digital neuroscience to understand when AI systems diverge from what we want. Neural networks are special in how much access we have to their brains, as we can both read and write.
- Limiting AI systems to avoid dangerous behaviour. This can include limiting it to human imitation; intentionally making them short-sighted, avoiding risks of long-term planning on short-term misalignment; focusing their abilities in a narrow domain; and inciting unambitiousness.
- Having checks and balances on AI such as using one model to supervise another and having humans supervise the AI. See this article on supporting human supervision with AI.
At the same time, Christiano writes [AF · GW] a reminder that AI alignment is distinct from applied alignment. Updating models to be inoffensive will not lead to safe artificial general intelligence but safer short-term systems such as ChatGPT. Steiner writes a counter-post [AF · GW] on the usefulness of working with applied alignment as well.
Relatedly, Shlegeris publishes a piece [AF · GW] exploring whether reinforcement learning from human feedback is a good approach to alignment. He addresses questions such as if RLHF is better than alternative methods that achieve the same (yes), has been net positive (yes), and is useful for alignment research (yes).
The alternative perspective is pretty well covered in Steiner’s piece [AF · GW] this week on why RLHF / IDA / Debate won’t solve outer alignment. Basically, these methods do not optimize for truth or safety, they optimize for getting the humans to “click the approve button”, something that can lead to many failures down the road.
GPU Performance Predictions
Hobbhahn and Besiroglu of EpochAI, the main AI capabilities prediction organization, have released a comprehensive forecasting report on how GPU performance will develop during the next 30 years.
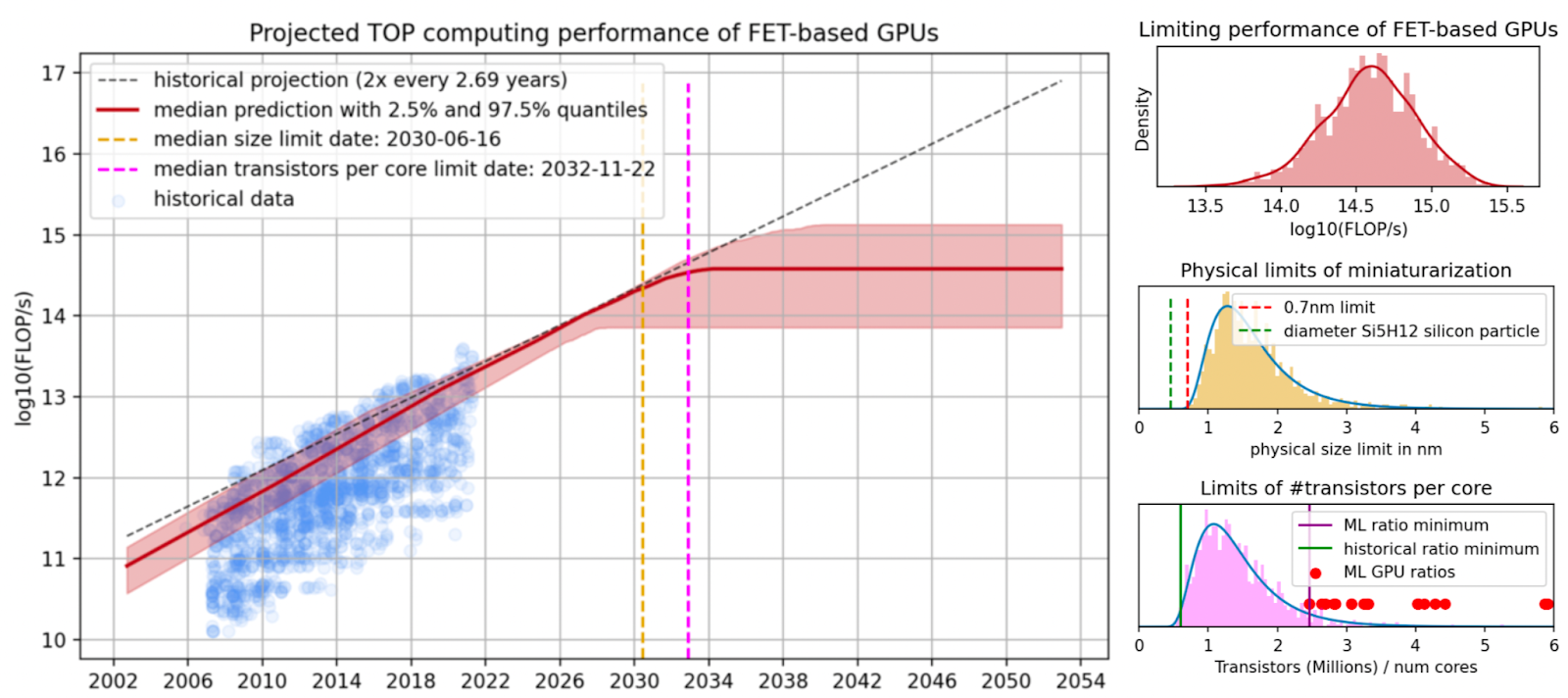
They use a model composed of the relationship between GPU performance and its features and how features change over time due to making transistors smaller. They expect GPU performance to hit a theoretical peak before 2033 at 1e15 FLOP/s (floating point operations per second).
I also chatted with a few GPU researchers at NeurIPS and their take was that computing power will hit a peak, making AGI near-impossible. The newer GPUs from Google and Tesla are not necessarily better, they just avoid NVIDIA’s 4x markup on the price of GPUs.
This brings hope to how well we can avoid AGI being developed. Ajeya Cotra’s estimate of ~1e29 FLOP/s required for artificial general intelligence based on the computation done by a human during a lifetime seems to be significantly farther away than her estimates indicated based on the Epoch report. Read her estimates in the first part of her wonderful transformative AI forecasting report.
“Why Machines Will Never Rule the World”
In the spirit of predicting how capable AGI will be, Machine Learning Street Talk, the hugely popular machine learning podcast, has interviewed Walid Saba about his review of the book from August, “Why Machines Will Never Rule the World”, by Landgrebe and Smith.
The book’s basic argument is that artificial general intelligence will not be possible for mathematical reasons. The human brain is a complex dynamical system and they argue that systems of this sort cannot be modeled with our modern neural network architectures or within computers at all due to the limited nature of training data as a function of the past.
These arguments are in line with Searle’s 1980 Chinese room argument and Penrose’s argument of non-computability based on Gödel’s incompleteness theorem. Walid Saba’s review is generally positive about the book. I personally disagree with the arguments since we do not need to model the complex system of the brain, we just need to replicate it in a simulator.
Nevertheless, it is an interesting discussion about whether AGI is possible.
Other news
In other news…
- Steve Byrnes releases [AF · GW] his 2022 update on his research agenda working on brain-like AGI safety.
- A new paper shows that latent knowledge might be possible to discover in language models, building upon the Eliciting Latent Knowledge problem set out by the Alignment Research Center.
- Finite Factored Sets are re-framing of causality: They take us away from causal graphs and use a structure based on set partitions instead. Finite Factored Sets in Pictures [LW · GW] summarizes and explains how that works. The language of finite factored sets seems useful to talk about and re-frame fundamental alignment concepts like embedded agents and decision theory.
- The PIBBBS fellowship has released their update [AF · GW] on their program of integrating new fields into AI safety to get more perspectives.
- We might be able to make models more safe by using inference on the gradient updating process between tasks to predict out-of-distribution behavior.
- Haydn Belfield and Christian Ruhl have released concerns about AI in the Bulletin of the Atomic Scientists, receiving a prize from the chief editors for their piece, also detailing the problems of thinking about race dynamics.
Opportunities
There are some exciting Winter opportunities this week! Again, thank you to AGISF for sharing opportunities in the space.
- You can now join the AGI safety fundamentals course, starting next year! This might be the most comprehensive course in AI safety and we highly encourage you to apply here!
- The Machine Learning Alignment Bootcamp in Berkeley (fully paid) is now open to preliminary applicants. Show your interest here.
- You can now sign up to workshops in Berkeley during the Winter (28th of December) that can show you how ML safety as a career might look. Sign up here.
- Sign up today (!) for the Global Challenges Project workshops in Oxford at the end of January.
- Join the AI Testing Hackathon in a few hours (!) and/or just watch our intro livestream with Haydn Belfield. Check the livestream out.
This has been the ML & AI safety update. We will take a break for two weeks over Christmas but then be back with more wonderful hackathons and ML safety updates. See you then!
7 comments
Comments sorted by top scores.
comment by Magdalena Wache · 2022-12-20T22:10:24.649Z · LW(p) · GW(p)
Suggestion for a different summary of my post:
Finite Factored Sets are re-framing of causality: They take us away from causal graphs and use a structure based on set partitions instead. Finite Factored Sets in Pictures [LW · GW] summarizes and explains how that works. The language of finite factored sets seems useful to talk about and re-frame fundamental alignment concepts like embedded agents and decision theory.
I'm not completely happy with
Finite factored sets [LW · GW] are a new way of representing causality that seems to be more capable than Pearlian causality, the state-of-the-art in causality analysis. This might be useful to create future AI systems where the causal dynamics within the model are more interpretable.
because
- I wouldn't say finite factored sets are about interpretability. I think the primary thing why they are cool is that they give us a different language to talk about causality, and thereby also about fundamental alignment concepts like embedded agents and decision theory.
- Also it sounds a bit like my post introduces finite factored sets (even though you don't say that explicitly), but it's just a distillation of existing work.
↑ comment by Esben Kran (esben-kran) · 2022-12-21T04:01:32.614Z · LW(p) · GW(p)
The summary has been updated to yours for both the public newsletter and this LW linkpost. And yes, they seem exciting. Connecting FFS to interpretability was a way to contextualize it in this case, until you would provide more thoughts on the use case (given your last paragraph in the post). Thank you for writing, always appreciate the feedback!
comment by Noosphere89 (sharmake-farah) · 2022-12-17T00:44:39.806Z · LW(p) · GW(p)
I also chatted with a few GPU researchers at NeurIPS and their take was that computing power will hit a peak, making AGI near-impossible. The newer GPUs from Google and Tesla are not necessarily better, they just avoid NVIDIA’s 4x markup on the price of GPUs.
I disagree, primarily since I think the human brain is at the limit already, and thus I see AGI as mostly possible. I also think that more energy will probably be used for computing. Now what I do agree with is there probably aren't pareto improvement we can do with AGI. (At least not without exotica working out.)
Here's a link:
https://www.lesswrong.com/posts/xwBuoE9p8GE7RAuhd/brain-efficiency-much-more-than-you-wanted-to-know [LW · GW]
Replies from: esben-kran↑ comment by Esben Kran (esben-kran) · 2022-12-18T10:03:28.637Z · LW(p) · GW(p)
What might not be obvious from the post is that I definitely disagree with the "AGI near-impossible" as well, for the same reasons. These are the thoughts of GPU R&D engineers I talked with. However, the GPU performance increase limitation is a significant update on the ladder of assumptions towards "scaling is all you need" leading to AGI.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-12-18T14:09:27.994Z · LW(p) · GW(p)
If I would update at all, I'd update that without exotic computers, AGI cannot achieve a pareto improvement over the brain. I'd also update towards continuous takeoff. Scaling will get you there, because the goal of AGI is an endgame goal (at least with neuromorphic chips.)
Replies from: esben-kran↑ comment by Esben Kran (esben-kran) · 2022-12-21T03:54:17.950Z · LW(p) · GW(p)
I think we agree here. Those both seem like updates against scaling is all you need, i.e. (in this case) "data for DL in ANNs on GPUs is all you need".
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-12-21T13:18:50.429Z · LW(p) · GW(p)
I think we agree here. Those both seem like updates against scaling is all you need, i.e. (in this case) "data for DL in ANNs on GPUs is all you need".
That's where I'm disagreeing, because to my mind this doesn't undermine "scale is all you need". It does undermine the idea that a basement group could produce AGI, but overall it gives actual limits on what AGI can do for a certain amount of energy.