Strategyproof Mechanisms: Impossibilities
post by badger · 2014-05-16T00:52:30.626Z · LW · GW · Legacy · 10 commentsContents
Gibbard-Satterthwaite: universal strategyproof mechanisms are out of reach Proof of Gibbard-Satterthwaite (in a special case) None 10 comments
In which the limits of dominant-strategy implementation are explored. The Gibbard-Satterthwaite dictatorship theorem for unrestricted preference domains is stated, showing no universal strategyproof mechanisms exist, along with a proof for a special case.
Due to the Revelation Principle, most design questions can be answered by studying incentive compatible mechanisms, as discussed in the last post. Incentive compatibility comes in many different flavors corresponding to different solution concepts—dominant-strategy IC and Bayes-Nash IC being the two most common. In this post, I’ll delve into what’s possible under dominant strategy incentive compatibility.
Recall that a strategy is dominant if playing it always leads to (weakly) higher payoffs for an agent than other strategy would, no matter what strategies other agents play. A social choice function is dominant-strategy incentive compatible if honest revelation is a dominant strategy in the direct mechanism for that SCF1. The appeal of implementation in dominant strategies is that an agent doesn't need to think about what other agents will do. Even in the worst case, a dominant-strategy IC social choice function leaves an agent better off for being honest. Since the need for strategic thinking is eliminated, dominant-strategy IC is also referred to as strategyproofness.
Gibbard-Satterthwaite: universal strategyproof mechanisms are out of reach
Arrow’s theorem is well-known for showing dictatorships are the only aggregators of ordinal rankings that satisfy a set of particular criteria. The result is commonly interpreted as saying there is no perfect voting system for more than two candidates. However, since Arrow deals with social welfare functions which take a profile of preferences as input and outputs a full preference ranking, it really says something about aggregating a set of preferences into a single group preference. Most of the time though, a full ranking of candidates will be superfluous—all we really need to know is who wins the election. Although Arrow doesn’t give social welfare functions much room to maneuver, maybe there are still some nice social choice functions out there.
Alas, it’s not to be. Alan Gibbard and Mark Satterthwaite have shown that, in general, the only strategyproof choice from three or more alternatives that is even slightly responsive to preferences is a dictatorship by one agent.
Stated formally:
Gibbard-Satterthwaite dictatorship theorem: Suppose f: L(A)n → A is a social choice function for n agents from profiles of ordinal rankings L(A)n to a set of outcomes A with at least three elements. If f is strategyproof and onto2, then f is dictatorial.
Being strategyproof seems intuitively more desirable to me than the properties in Arrow’s theorem (especially the much critiqued independence of irrelevant alternatives criterion). As it turns out though, Gibbard-Satterthwaite and Arrow are equivalent! Weakening our ambition from social welfare functions to social choice functions didn't give us anything.
Gibbard-Satterthwaite seems a great blow to mechanism design at first glance. On reflection, perhaps we were asking for too much. A completely generic strategyproof mechanism that can be used in any situation does sound too good to be true.
There are three ways to proceed from this point:
- Building strategyproof mechanisms for specialized applications,
- Weakening strategyproofness to another form of incentive compatibility, or
- Stepping sideways from ordinal preferences and enriching the model while adding further assumptions.
On that last path, note that switching from ordinal to cardinal preferences can’t save us unless we offset that generalization with other assumptions—cardinal information expands the ordinal type space, which can only make implementation more difficult.
Since dictatorships are the only universal strategyproof mechanisms for choosing between three options, it’s worth investigating why life is pleasant with only two options. In this case, lots of non-trivial strategyproof mechanisms exist. For example, suppose a committee is restricted to painting a bike shed either red or blue due to zoning restrictions. The social choice function that paints the shed red if and only if a majority have red as their first choice is strategyproof, as is the social choice to paint the shed red if and only if the committee unanimously lists red as their top choice.
Of course, not every voting rule for binary outcomes will be strategyproof, like the rule that paints the shed red if and only if an odd number of committee members top-rank red. While I can’t imagine anyone arguing in favor of this rule, what’s going wrong here? The problem is this odd rule isn’t monotonic—raising red in someone’s preference ranking can cause the outcome to switch away from red.
Here are the formal definitions of strategyproofness and monotonicity:
A social choice function f: L(A)n → A is strategyproof if for each agent i, the social choice satisfies
for all rankings
and
.
A social choice function f: L(A)n → A is monotonic if for each agent i, we have that
implies
and
for all rankings
Take a moment to convince yourself that monotonicity is just a slight rephrasing of strategyproofness and hence equivalent. Though they are identical at heart, monotonicity carries two useful interpretation as an invariance property. First, if an agent submits a new ranking where the previous outcome goes up, the outcome can’t change. Second, submitting a new ranking where the rank of the previous outcome relative any other option is unchanged has to leave the outcome unchanged as well.
When there are only two alternatives, we can think of the implicit outcome space as one dimensional, with one outcome on the left and the other on the right. Going towards one outcome corresponds exactly with going away from the other. With three or more alternatives, we don’t have the same nice structure, leading to the impossibility of a non-trivial monotonic rule.
In the next post, I’ll describe domains where we can enrich the outcome space beyond a binary choice and still get strategyproofness. Since the outcome space won’t naturally have a nice order structure, we’ll have to ensure it does by restricting the preferences agents can have over it. Even though we don’t have universal strategyproof mechanisms other than dictatorships, we can uncover strategyproof mechanisms for specific applications. In the meantime, here’s a proof of Gibbard-Satterthwaite for the curious.
Proof of Gibbard-Satterthwaite (in a special case)
Suppose the committee consists of two people, Betty and Bill. In addition to red and blue, the city recently approved yellow as an option to paint bike sheds. Each person has six possible rankings over the three colors, and there are 36 preference profiles containing one ranking from each. The 36 will fall into six relevant classes. Here is an example of each class along with some shorthand to describe it:
- r > b > y: Both agents agree on the ranking of red over blue over yellow.
- r > b^y: Both agents agree red is the best. Betty puts blue as her second choice, while Bill has yellow as his second choice.
- b^y > r: Both agree red is worst. Betty thinks blue is better than yellow, while Bill thinks yellow is better.
- r ∣ (b > y): Both agents agree blue is better than yellow. Betty thinks red is better than them both, while Bill thinks red is worse than both.
- (b > y) ∣ r: Both agree blue is better than yellow. Betty thinks red is worst, while Bill thinks red is best.
- r^b^y: Betty has the ranking red over blue over yellow, while Bill has the reverse.
For the notation summarizing the profile, r > b indicated both agree that red is better than blue. r^b says there is a conflict between the two with Betty preferring red. r ∣ (b > y) says there are two preference conflicts, with Betty preferring red over the other two options, so we alternatively think of this profile as r^y, r^b, and y > b.
Now, we’ll assign the 36 profiles a color, using each at least once, in a way that is monotonic. This will happen in six steps as depicted in the following diagram.
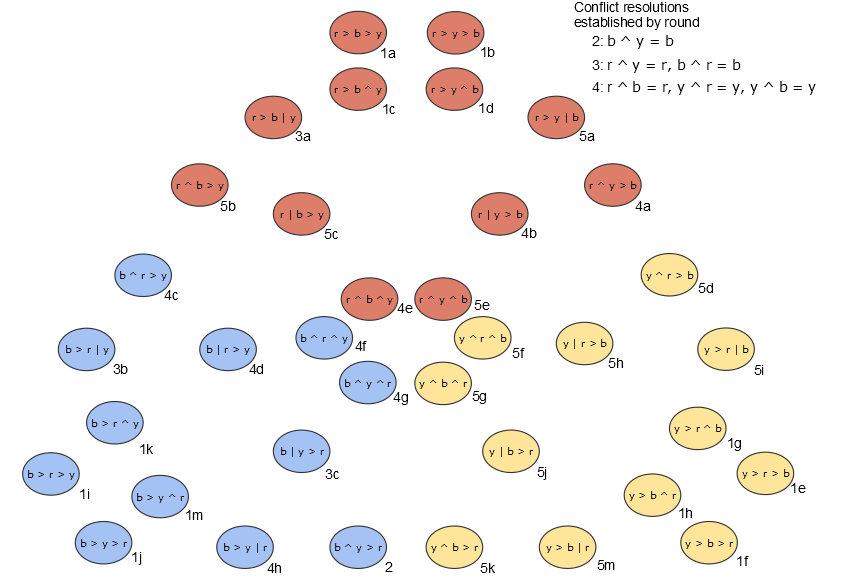
- At least one profile must be red by assumption. Starting from that profile (whatever it is), we could move red to the top of both rankings and the outcome would still be red by monotonicity. Then all other profiles with red top-ranked by both also must be red since any swaps of blue and yellow can’t change the outcome since red is still relatively above both. This gives us 1a,b,c,d. Blue and yellow go through similarly.
- Consider the profile b^y > r at the bottom of the diagram. The profile y > b > r got yellow in 1f, so if Betty starts liking blue better from 2, the outcome has to stay yellow or switch to blue. Since monotonicity can’t tell us more than that, we have to make a choice. Let’s decide in favor of Betty and pick blue.
- Since we chose to resolve the conflict b^y as b, three more colorings follow since we must resolve this particular conflict in the same way everywhere. Keep in mind that b^y is a different conflict than y^b since it might matter who prefers which color. Consider 3b. This can’t be yellow since yellow increases between this profile and 2, but 2 isn’t yellow. It also can’t be red since 1k isn’t red, so we conclude 3b must be blue. Now consider 3a. Even though the conflict b^y resolves in favor of blue, the outcome can’t be blue since 1c isn’t blue. Hence 3a must be red. From 3a, we conclude that r^y was resolved as r, so this new rule must apply everywhere. From 3c, we get a third rule that b^r = b.
- With two new rules in the third step in addition to the rule from the second, more colorings follow. These colorings then give us the rules r^b = r, y^b = y, and y^r = y.
- With all possible pairwise resolutions settled, all profiles can be colored.
We’ve found a monotonic, onto coloring! Notice that this is a dictatorship by Betty, choosing her top-ranked color for each profile. Everything comes down to favoring Betty over Bill in step two. Since Betty was pivotal once, she ends up having complete control. Of course, we could have resolved b^y as y instead, which would have given us a dictatorship by Bill. That choice in step two was the only degree of latitude we had, so these are the only two monotonic, onto colorings.
This special-case proof of Gibbard-Satterthwaite was inspired by Hansen (2002), “Another graphical proof of Arrow’s impossibility theorem”. Full proofs of the theorems, done simultaneously side-by-side, are given in Reny (2001), “Arrow’s theorem and the Gibbard-Satterthwaite theorem: a unified approach”.
Previously on: Incentive-Compatibility and the Revelation Principle
Next up: Strategyproof Mechanisms: Possibilities
-
Recall that the direct mechanism for an SCF is where we simply ask the agents what type they are and then assign the outcome prescribed by the SCF for that type profile.↩
-
The function f is onto if every outcome in A occurs for at least one input. The main role of this assumption to prevent f from covertly restricting its image to two elements, so it’s almost without loss of generality.↩
10 comments
Comments sorted by top scores.
comment by Sniffnoy · 2014-05-16T04:33:55.205Z · LW(p) · GW(p)
However, since Arrow deals with social welfare functions which take a profile of preferences as input and outputs a full preference ranking, it really says something about aggregating a set of preferences into a single group preference.
I'm going to nitpick here -- it's possible to write down forms of Arrow's theorem where you do get a single output. Of course, in that case, unlike in the usual formulation, you have to make assumptions about what happens when candidates drop out -- considering what you have as a voting system that yields results for an election among any subset of the candidates, rather than just that particular set of candidates. So it's a less convenient formulation for proving things. Formulated this way, though, the IIA condition actually becomes the thing it's usually paraphrased as -- "If someone other than the winner drops out, the winner stays the same."
Edit: Spelling
Replies from: badger↑ comment by badger · 2014-05-16T12:46:36.693Z · LW(p) · GW(p)
Since Arrow and GS are equivalent, it's not surprising to see intermediate versions. Thanks for pointing that one out. I still stand by the statement for the common formulation of the theorem. We're hitting the fuzzy lines between what counts as an alternate formulation of the same theorem, a corollary, or a distinct theorem.
Replies from: Closed Limelike Curves↑ comment by Closed Limelike Curves · 2024-05-28T19:25:30.445Z · LW(p) · GW(p)
Every social ranking function corresponds to a social choice function, and vice-versa, which is why they're equivalent. The Ranking→Choice direction is trivial.
The opposite direction starts by identifying the social choice for a given ranking. Then, you delete the winner and run the same algorithm again, which gives you a runner-up (who is ranked 2nd); and so on.
Social ranking is often cleaner than working with an election algorithm because those have the annoying edge-case of tied votes, so your output is technically a set of candidates (who may be tied).
comment by trist · 2014-05-16T03:21:54.627Z · LW(p) · GW(p)
My cursory understanding is that none of these proofs apply to rating systems, only ranking systems, correct?
Replies from: badger↑ comment by badger · 2014-05-16T04:09:24.137Z · LW(p) · GW(p)
Arrow's theorem doesn't apply to rating systems like approval or range voting. However, Gibbard-Satterthwaite still holds. It holds more intensely if anything since agents have more ways to lie. Now you have to worry about someone saying their favorite is ten times better than their second favorite rather than just three times better in addition to lying about the order.