Exploring how OthelloGPT computes its world model
post by JMaar (jim-maar) · 2025-02-02T21:29:09.433Z · LW · GW · 0 commentsContents
Summary What’s OthelloGPT Small findings / Prerequisites Mine-Heads and Yours-Heads Attention Patterns are almost constant (across inputs) Visualising the board state Accuracy over every Layer and sequence position The Flipped probe The Previous Color Circuit Example of the Previous Color Circuit in Action Quantifying the Previous Color Circuit Attention Heads Perform the Previous Color Circuit on Different Regions of the Board A Flipping Circuit Hypothesis Summary Classifying Monosemantic Neurons Testing the Flipping Circuit Hypothesis Conclusion Next Steps An Unexpected Finding Contact None No comments
I completed this project for my bachelor's thesis and am now writing it up 2-3 months later. I think I found some interesting results that are worth sharing here. This post might be especially interesting for people who try to reverse-engineer OthelloGPT in the future.
Summary
- I suggest the Previous Color Circuit, which explains how the Attention layers in OthelloGPT copy over the color of each tile from previous moves. I used the word Circuit here, because it is common, but I think it’s more like a rough approximation of what’s going on.
- I came up with and disproved a theory about how the MLP-layers in OthelloGPT compute which tiles are flipped.
- I think this might provide mild evidence against the theory proposed in OthelloGPT learned a bag of heuristics [LW · GW] that individual neurons perform interpretable rules. Although I only tested a very specific set of rules.
What’s OthelloGPT
- OthelloGPT learned a bag of heuristics [LW · GW] gives a good introduction to OthelloGPT
Small findings / Prerequisites
The other sections will build on top of this section
Mine-Heads and Yours-Heads
- Hazineh et. al. found that some Attention Heads only pay attention to moves made by the current player (Mine-Heads) and others only pay attention to moves made by the other player (Yours-Heads)
- Most Attention Heads are Mine- or Yours-Heads
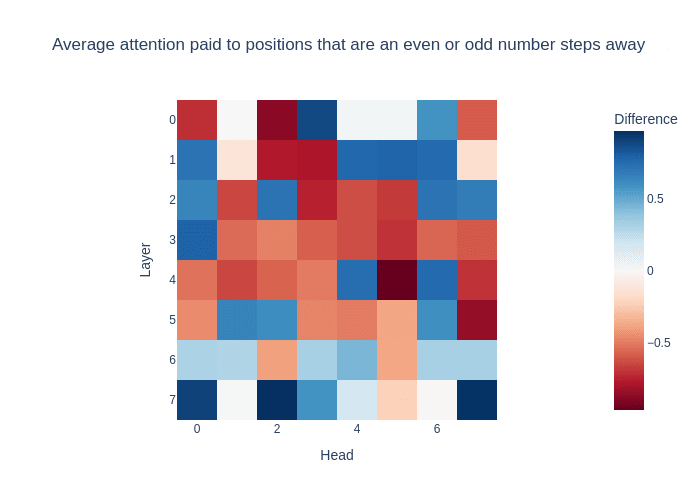
Attention Patterns are almost constant (across inputs)
- The attention pattern has a Variance of 0.0007 averaged over each Attention Head over 200 games
- They typically pay less attention to moves farther away
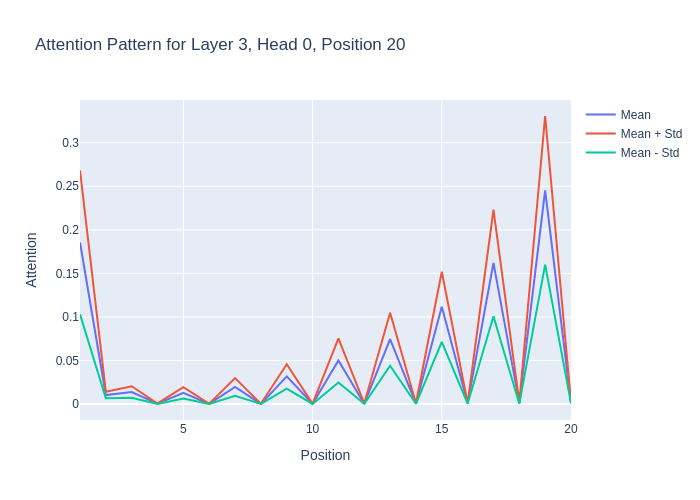
Visualising the board state Accuracy over every Layer and sequence position
- The above plot shows that in each layer, the board state is very accurate until some sequence position, where it starts to drop off.
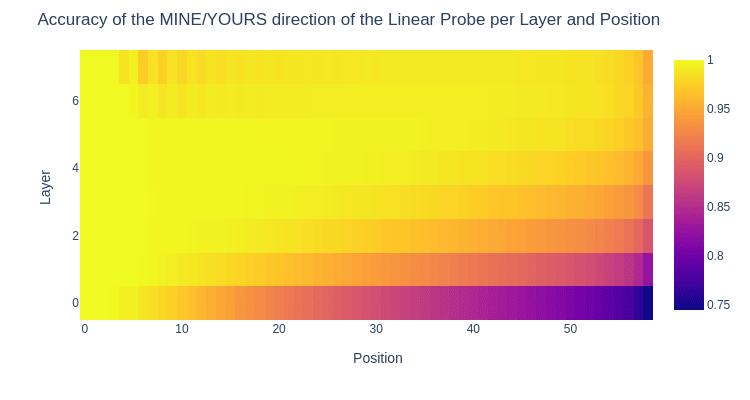
The Flipped probe
- Andrew Lee found a "Tile is Flipped" probe, that tracks if a tile has been flipped this move. This is relevant for the next section.
The Previous Color Circuit
- I hypothesized that Mine- and Yours Heads are copying over the color of each tile from the previous moves. (Then all what's left is placing the new tile and flipping the correct tiles)
- Since tiles frequently change color, the color-copying mechanism should be particularly strong at positions where tiles were recently flipped.
- Combined with the effect that moves further away get less attention, this means that the color copied over will approximately be the color of the tile when it was last flipped
- I will explain why this makes sense later with an example
- Specifically my hypothesis was that they behave as shown in the table
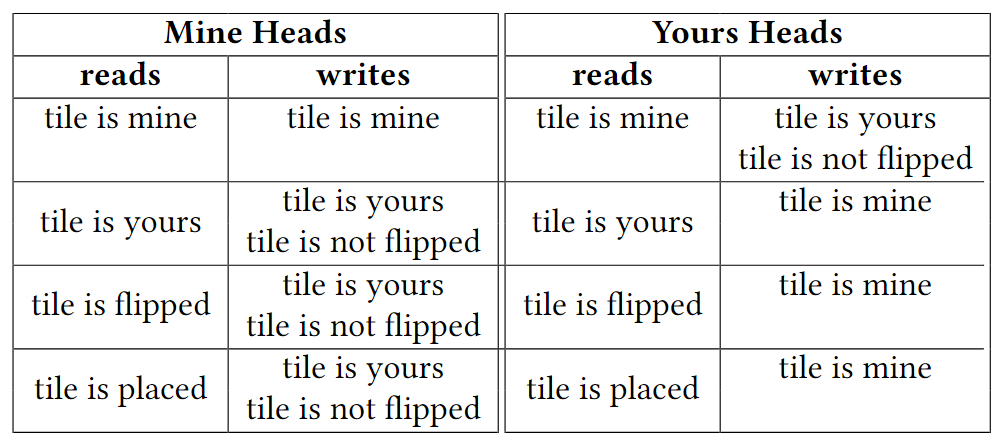
in the previous color circuit.
- The table below shows the cosine similarity of ("Tile is ..." @ OV) and ("Tile is Yours" - "Tile is Mine") for the features above (as well as ("Tile is ..." @ OV) and ("Tile is Flipped" - "Tile Not Flipped"))
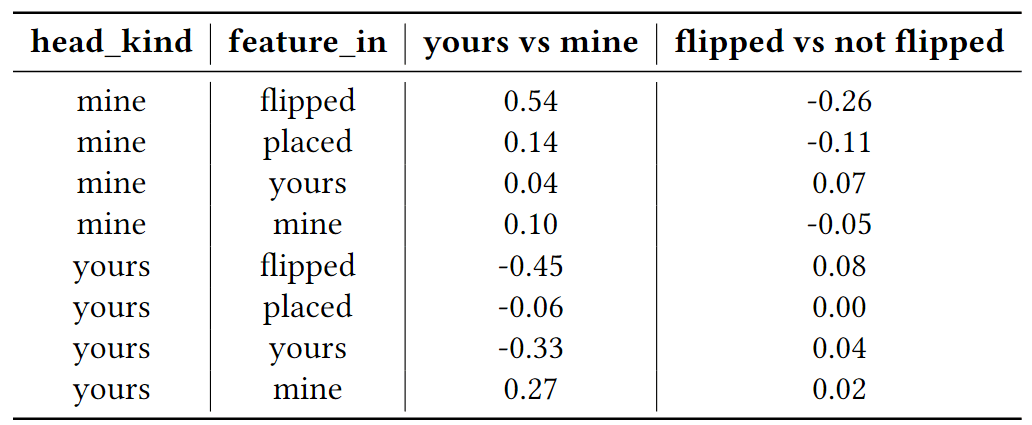
- The results largely matched my expectations, though the Flipped vs. Not Flipped results were somewhat surprising.
- I expected the Mine Heads reading "Tile is Yours" to write "Tile is not flipped" and I expected Yours Heads reading "Tile is Mine" to write "Tile is not flipped"
- The flipped direction has the biggest effect on the color written
Example of the Previous Color Circuit in Action
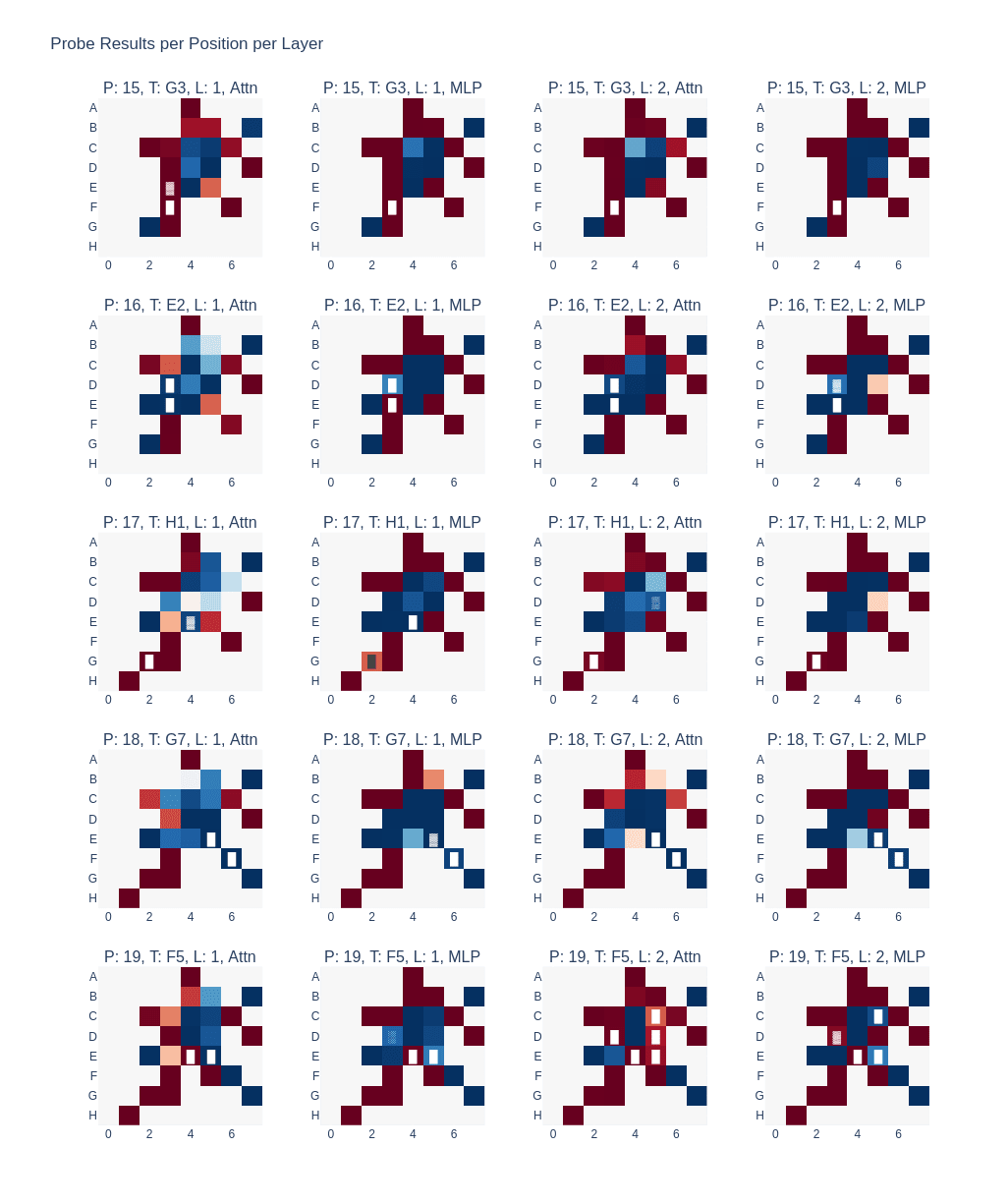
- In the example above, at sequence position 19 (last row) in layer 1, tile D3 is marked as Red/Yours in the board representation before the Attn layer (first column). After the Attn layer, the color is flipped to Blue/Mine, possibly because the tile was previously flipped to Blue at sequence position 16, which was encoded in the board state representation after layer 0.
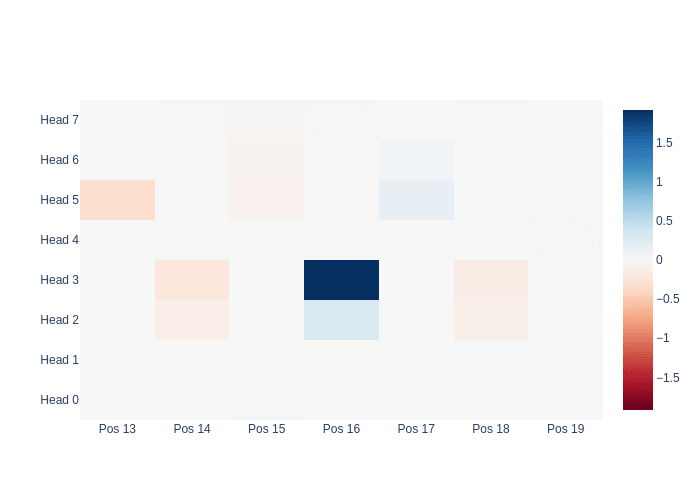
- Looking at the direct Logit Attribution of Attention Heads from previous positions supports the hypothesis
- I made an illustration to show how the attention layer is kind of performing a weighted average of the tile's color at the previous moves, with the position 16 where the tile was flipped having the biggest weight
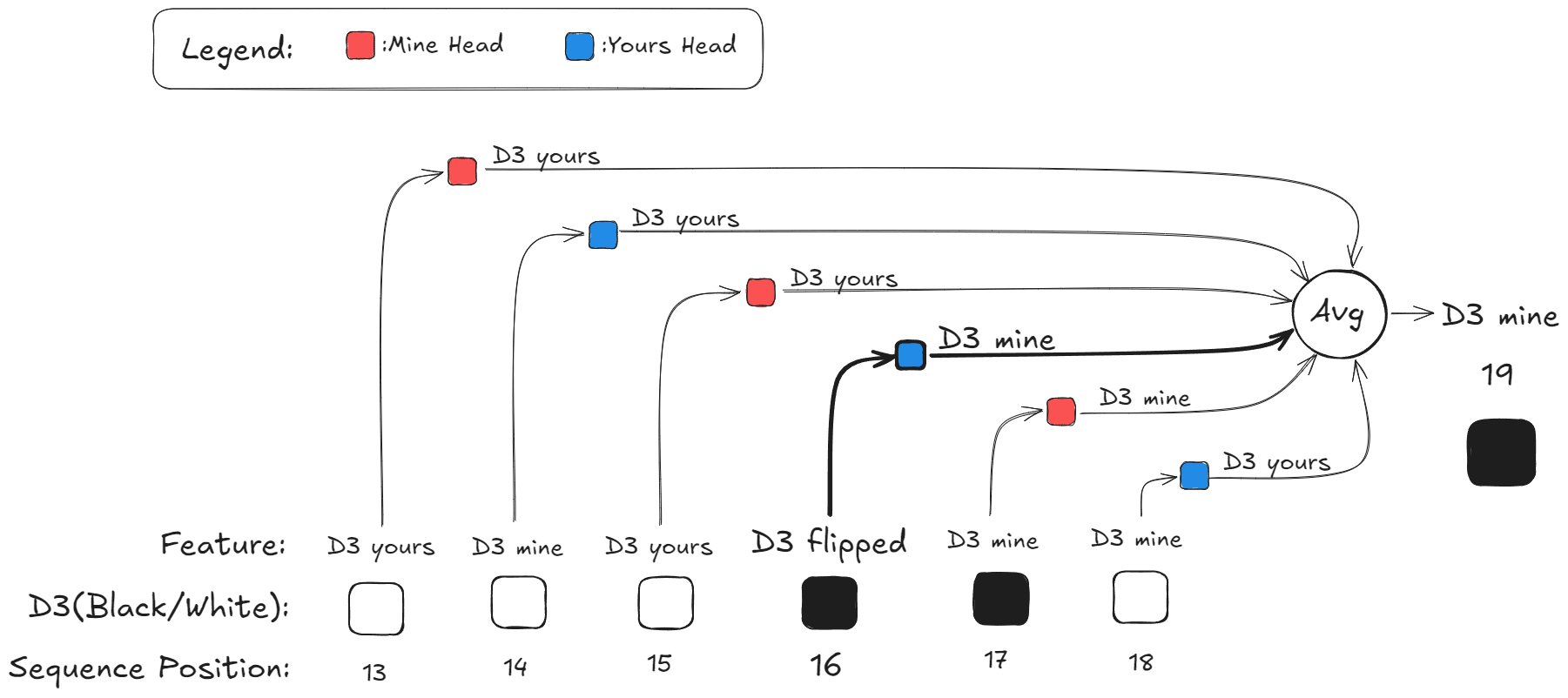
- By weighing the color more when the tile was flipped and by weighing the moves further away less, the model can essentially copy over the board state from the previous move (according to the previous layer), while also using information from the past 10 or so moves to correct errors. In the example the model thoght at move 18 that D3 where white, but the previous color circuit "notices" that actually D3 was flipped to black at move 16, so it can't be white.
Quantifying the Previous Color Circuit
- Over 64.000 games I projected the residual stream to the space spanned by the "Tile is Flipped", "Tile is Mine", "Tile is Yours" and "Average Residual Stream" Directions (I forgot "Tile is Placed") then applied the linear probes to the output of the attention layer and compared this to the real output. Specifically I measured the accuracy with the probe-results of the real attention layer as the ground truth (Ignoring empty tiles).
- The overall accuracy was 0.818, but was very dependent on layer, sequence position and the position of the tile on the board (specifically whether the tile is on the outer rim of the board or inside it)
- The accuracy for some specific combinations of layer, sequence position and tile went as high as 0.97
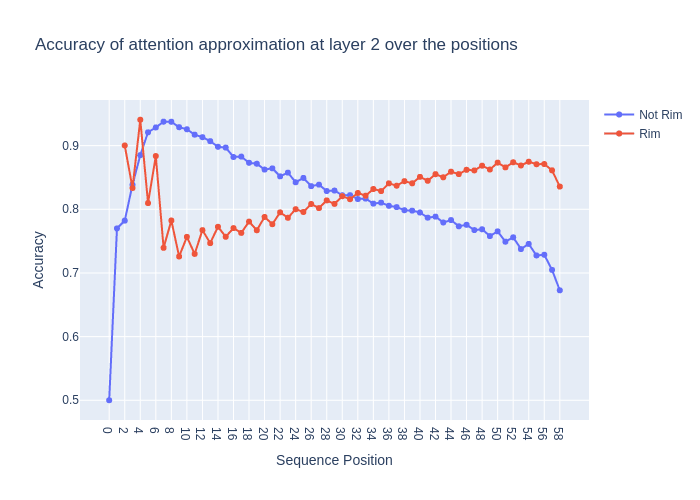
positions split into tiles on the rim and tiles in the middle of the board
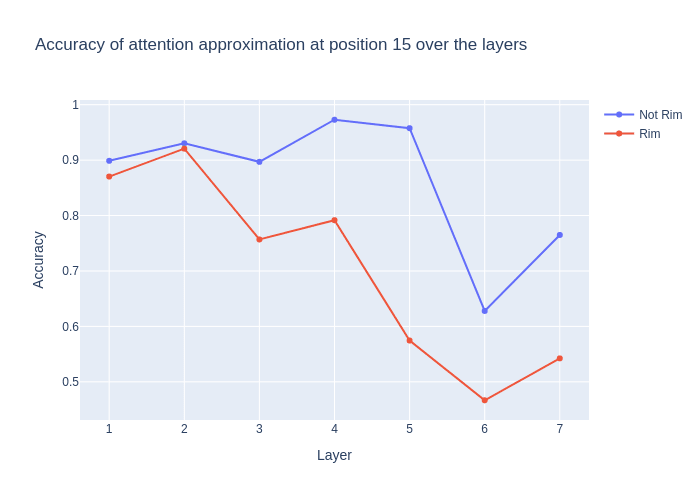
layers, split into tiles on the rim and tiles in the middle of the board
- I think the results show that the previous color circuit is meaningful. But the model actually does something more complicated, so it's better thought of as a rough approximation of what the attention layers are doing.
- I tried the same experiment only with the flipped direction. The overall accuracy was 0.768, so only slightly worse. I think I looked at similar plots to the ones above and did not see very such high accuracy for specific layers, sequence positions and tiles (I don't remember it that well to be honest).
- This is why I ended up calling it the previous color circuit instead of the Last Flipped Circuit
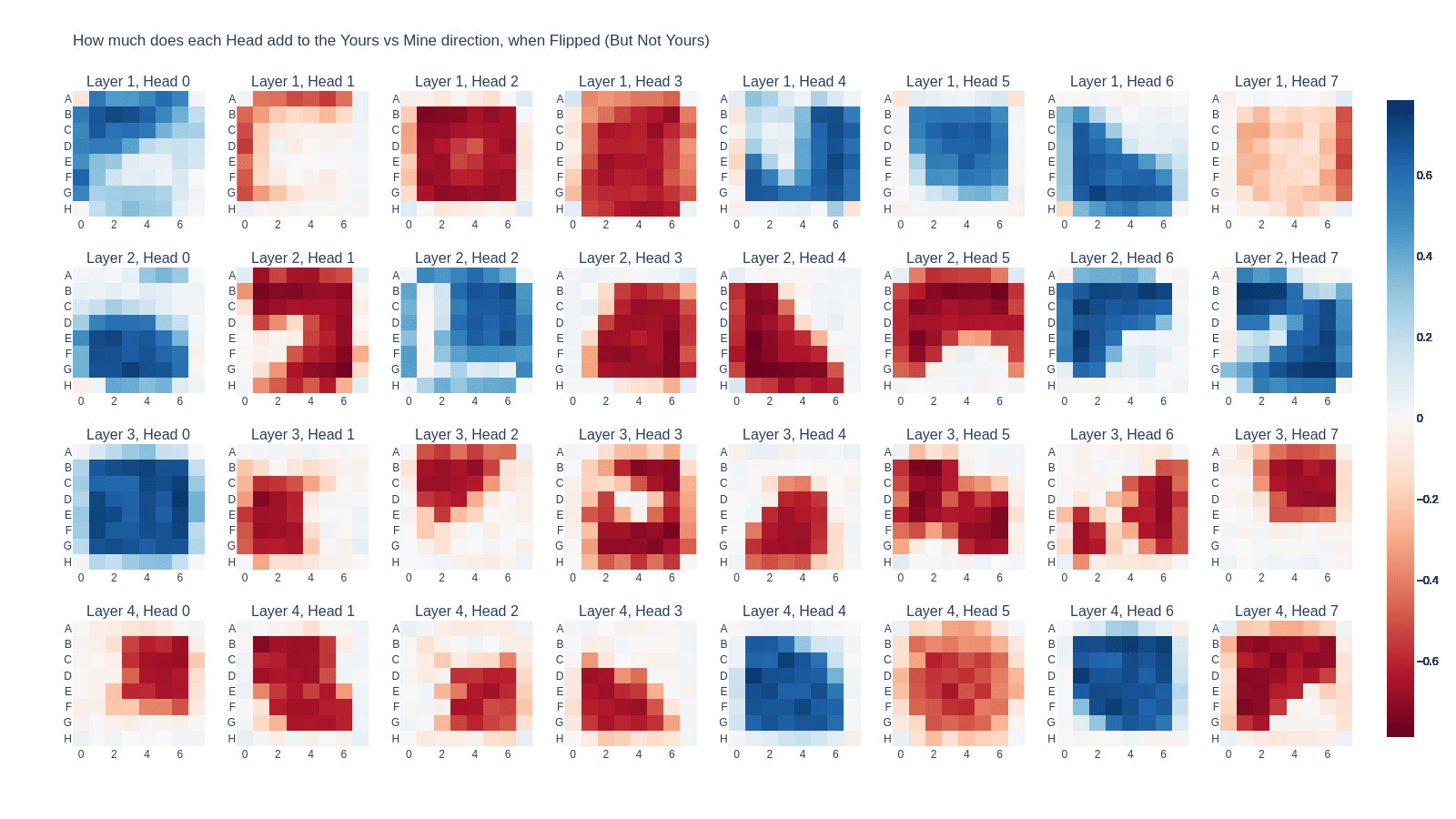
Attention Heads Perform the Previous Color Circuit on Different Regions of the Board
- The plot below shows ("Tile Flipped" @ OV) @ "Tile is Yours" - ("Tile Flipped" @ OV) @ "Tile is Mours" for every tile and attention head for the first 4 layer .[1]
A Flipping Circuit Hypothesis
Summary
- I saw mono-semantic neurons that activate when specific tiles need to be flipped
- I tried to categorize all of these flipping neurons and then ablate every neuron except the relevant flipping neurons and see whether the model correctly flips tiles, but this did not work
Classifying Monosemantic Neurons
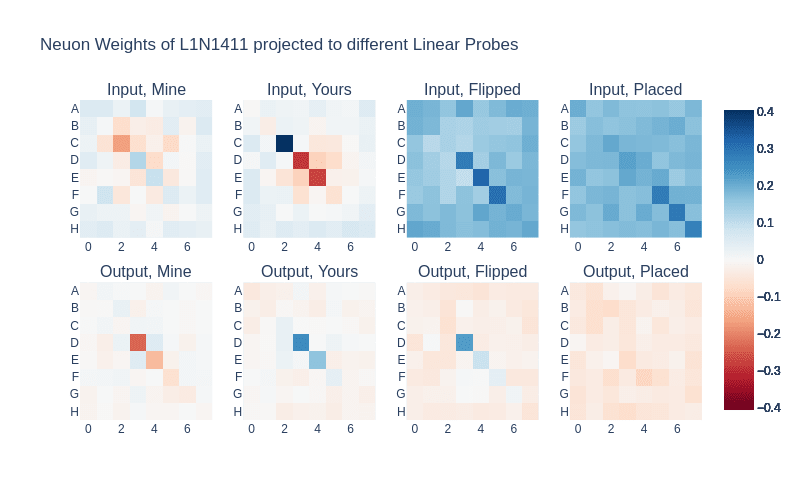
- In the example above, in position 19 in layer 1, after the attention layer writes "D3 is mine" the MLP correctly writes "D3 is flipped" and "D3 is yours"
- Using direct logit attribution we see that this is due to Neuron L1N1411
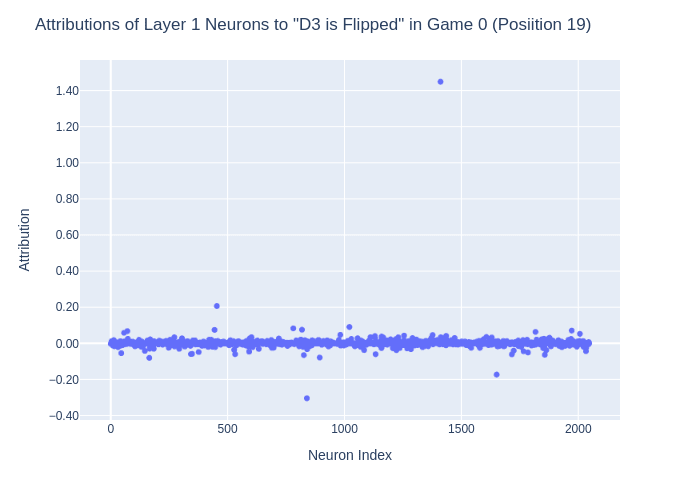
- If we project this neurons input and output weight to the linear probes, we see that it seems to activate if a tile was placed on H7, G6 or F5, flipping tiles until C2, which is already Yours.
Let 𝑅 denote the set of rules. Each rule 𝑟 ∈ 𝑅 is defined by:
- A tile 𝑡 ∈ {𝐴0, 𝐴1, ..., 𝐻 7} marked as "Yours"
- A flipping direction 𝐹 ∈ {UP, UP-RIGHT, LEFT, ...}
- The number of Mine tiles to be flipped 𝑛 ∈ {1, 6}

A rule 𝑟(𝑥) evaluates to true for a residual stream 𝑥 when 𝑛 "mine" tiles need to be flipped in the specified direction, before reaching tile 𝑡, which is yours.
- I for every pair of rule and neuron I calculate the mean activation difference over 10.000 games and if it is above 0.17 I classify I say that the neuron follows the rule[2]
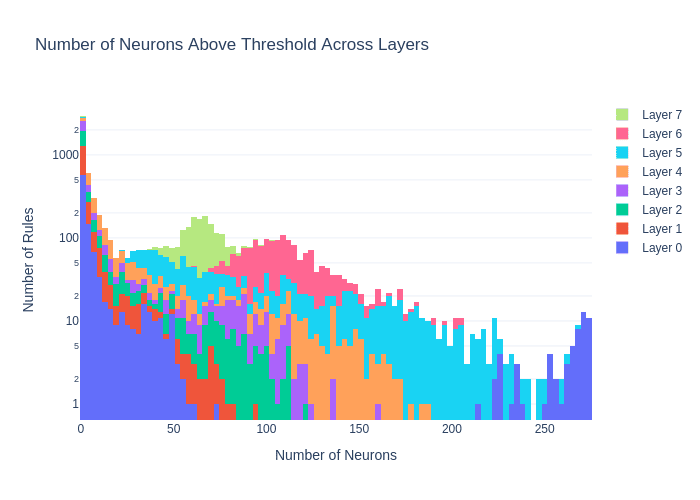
- The image shows that most rules had either 0 or a handful of corresponding neurons and some rules had a lot of corresponding neuron (especially in later layers)
Testing the Flipping Circuit Hypothesis
- I then did a mean ablation experiment, where for a specific move, the program evaluates which rules are true, and then ablates all neurons except the corresponding neurons for this rule
- I then compare tiles flipped (according to the probe) in resid_post of the ablated run to resid_post of the original run. Specifically for every tile where the model "changes it's mind" about the tile being flipped (e.g. the tile was not flipped in the previous layer and now it is flipped and vice versa), I measure the accuracy of the ablated probe results to the real probe results
- We compare this with the baseline of mean ablating all neurons
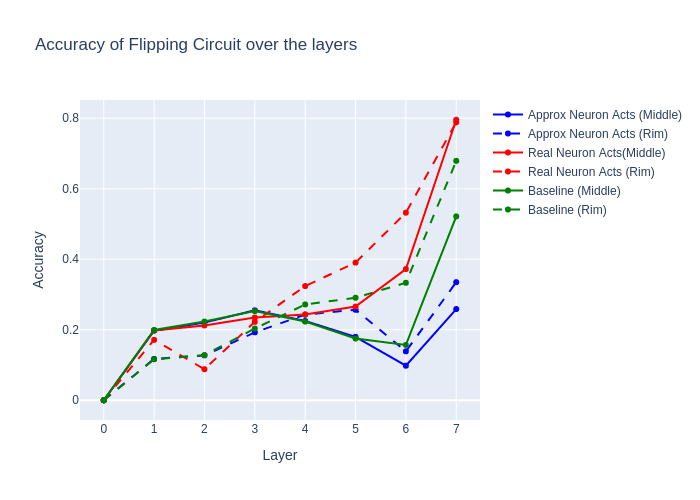

- The results are that the flipping circuit doesn't exceed the baseline, except in later layers, where there are a lot of neurons that are not getting ablated
- I verified that my setup worked for the example shown above with Neuron L1N1411
Conclusion
- I really expected the experiment to give good results
- The evidence I had was the following:
- I had seen a bunch of these flipping neuron patterns in the neuron weight projections
- For two random example situations where a tile went from not flipped to flipped, I saw that this was caused by a single neuron (according to direct logit attribution) and the projected neuron weights looked like I expected. (I tested one of these cases in the ablation setup and it worked there)
- I classified neurons and saw that a lot of the rules had corresponding neurons according to my definition (which could have been more strict ...)
- My learning is that I should have really good evidence before I make a big experiment like this one. Here I should have picked random rules and looked if the corresponding neurons hold up in example situations
- I think this might provide mild evidence against the theory proposed in OthelloGPT learned a bag of heuristics [LW · GW] that individual neurons perform interpretable rules. Although I only tested a very specific set of rules.
- There's also a chance that I had a bug in my code (I only tested the one example thoroughly)
Next Steps
- If I would continue this project, I would reproduce the experiment on a smaller scale (focusing on just one tile / rule) and investigate cases where my ablation setup fails to predict tile flips.
An Unexpected Finding
- L7_MLP(L0_resid_post + L7_attn_out) is enough to correctly predict legal moves. In other words, the residual stream at the end of layer 6 is mostly not needed to predict the legal moves except for the connection through the attention layer
- I made some experiments to test if I can mean ablate later layers e.g. 5, 4, 3 in early positions and early layers e.g. 1, 2 in late positions and still get a similar performance, but that's not what I found
- But I did find that ablating L7_resid_mid with L7_attn_out + L0_resid_post leads to surprisingly good performance on the model. On a test set of 1024 games I found an error rate of 0.007% for the regular model and 0.061% for the ablated model (measured by taking the top-1 prediction and seeing if it's a legal move). The F1-Score is 0.993 for the normal model and 0.961 for the ablated model.
Contact
- Codebase for this project
- If you have questions, write me a DM on Lesswrong
- I would appreciate feedback :)
- ^
I edited the Flipped direction to be orthogonal to the Yours direction. The effect of the Yours/Mine direction is stronger on the rim of the board, but I don't have a visualization on hand
- ^
0.17 is roughly the minimum of the GELU function. So a mean activation difference suggests that the neuron has a positive activation when the rule is true and a negative evaluation otherwise.
0 comments
Comments sorted by top scores.