My take on Michael Littman on "The HCI of HAI"
post by Alex Flint (alexflint) · 2021-04-02T19:51:44.327Z · LW · GW · 4 commentsContents
My take None 4 comments
This is independent research. To make it possible for me to continue writing posts like this, please consider supporting me.
Many thanks to Professor Littman for reviewing a draft of this post.
Yesterday, at a seminar organized by The Center for Human-compatible AI (CHAI), Professor Michael Littman gave a presentation entitled "The HCI of HAI'', or "The Human Computer Interaction of Human-compatible Artificial Intelligence". Professor Littman is a computer science professor at Brown who has done foundational work in reinforcement learning as well as many other areas of computer science. It was a very interesting presentation and I would like to reflect a little on what was said.
The basic question Michael addressed was: "how do we get machines to do what we want?" and his talk was structured around the various modalities that we’ve developed to convey our intentions to machines, starting from direct programming, through various forms of machine learning, and on to some new approaches that his lab is developing. I found his taxonomy helpful, so I’ll paraphrase some of it below and then add my own thoughts afterwards.
One way we can get machines to do what we want is by directly programming them to do what we want. But, the problem here is that direct programming is challenging for most people, and Michael talked through some studies that asked non-programmers to build simple if-then rulesets to implement programs such as "if it’s raining and the dog is outside then do such-and-such". Most participants had difficulty reasoning about the difference between "if the dog goes outside while it is raining" versus "if it starts raining while the dog is outside".
I’m not sure that this is the main reason to look beyond direct programming, but I do agree that we need ways to instruct machines that are at least partially example-driven rather than entirely rule-driven, so I’m happy to accept the need for something beyond direct programming.
Next, Michael discussed reinforcement learning, in which the human provides a reward function, and it is the machine’s job to find a program that maximizes rewards. We might say that this allows the human to work at the level of states rather than behavior, since the reward function can evaluate the desirability of states of the world and leave it up to the machine to construct a set of rules for navigating towards desirable states:
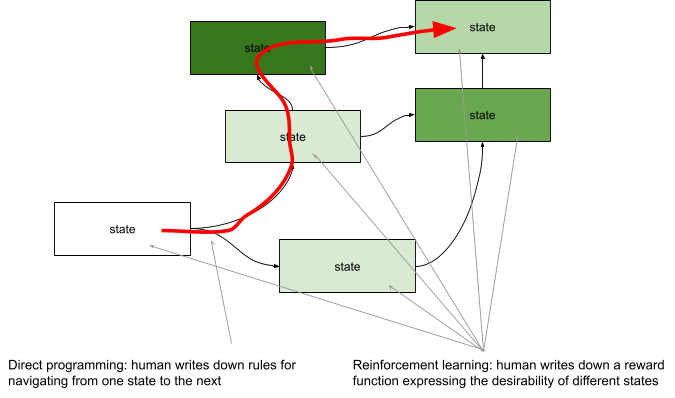
But, writing down a reward function that clearly expresses our intentions can also be very difficult, for reasons that have been discussed here and in the AI Safety literature. One way to express those reasons is Goodhart’s Law, which says that when we apply powerful optimization to any proxy measure of that-which-we-really-care-about, we tend to get something that is both unexpected and undesirable. And, expressing that-which-we-really-care-about in full generality without proxy measures seems to be exceedingly difficult in all but the simplest situations.
So we come to inverse reinforcement learning, in which we ask the machine to formulate its own reward function based on watching a human perform the task. The basic idea with inverse reinforcement learning is to have humans demonstrate a task by taking a series of actions, then have the machine find a reward function, which, if the human had been choosing actions in order to maximize, would explain each of their actions. Then the machine takes actions in service of the same reward function. Michael gave some nice examples of how this works.
The problem with inverse reinforcement learning, however, is that in full generality it is both underspecified and computationally intractable. It is underspecified because in the absence of a good prior, any human behavior whatsoever can be explained by a reward function that rewards that exact behavior. One solution to this concern is to develop priors on reward functions, and work continues on this front, but it does mean that we have transformed the problem of writing down a good reward function to the problem of writing down a good prior on reward functions.
Next, Michael discussed direct rewards, in which a human directly provides rewards to a machine as it learns. This method skips over the need to write down a reward function or a prior on reward functions by instead having a human provide each and every reward manually, but it comes at the expense of being much slower.
Yet it turns out that providing direct rewards is subtle and difficult, too. Michael talked about a study in which some people were asked to provide rewards within a game where the goal was to teach a virtual dog to walk to a door without walking on any flowers. In the study, most participants gave the dog positive rewards for walking on the path, negative rewards for walking on flowers, and a positive reward for reaching the door. But, the optimal policy under such a reward structure is actually to walk back and forth on the path endlessly in order to collect more and more reward, never reaching the goal. The "correct" reward structure in this case is actually to provide a positive reward for reaching the door, a large negative reward for walking on the flowers, and a small negative reward for walking on the path, in order to incentivize the dog to get to the door as quickly as possible.
A shortcoming of all of the learning approaches (reinforcement learning, inverse reinforcement learning, and direct rewards) is that they lack affordances for writing down rules even in cases where rules would be most natural. For example, when we teach someone how to drive a car, we might tell them not to drive through red lights. To teach a machine to drive a car using reinforcement learning we could provide a negative reward for states of the world in which the vehicle is damaged or the passengers are injured, and hope that the machine learns that driving through red lights leads on average to crashes, which on average leads to vehicle damage or passenger injury. Under inverse reinforcement learning, we could demonstrate stopping at red lights and hope that the machine correctly infers the underlying rule. Under direct rewards we could provide negative rewards for driving through red lights and hope that the machine learns to stop at red lights, and not, for example, to take a more circuitous route that avoids all traffic lights. But these all seem indirect compared to providing a simple instruction: if traffic lights are red then stop the car.
One seminar participant offered the following helpful way of seeing each of the above approaches. Imagine a space of all possible machine behaviors, and ask how we can communicate a desired behavior to a machine[1]:
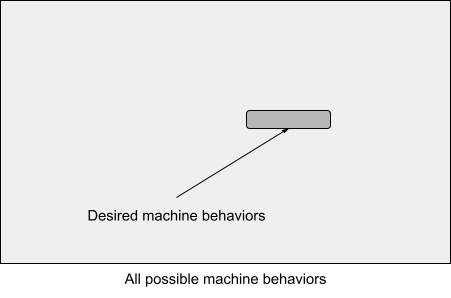
The four approaches discussed above could be viewed as follows.
- Under direct programming, we provide rules that eliminate parts of the behavior space:
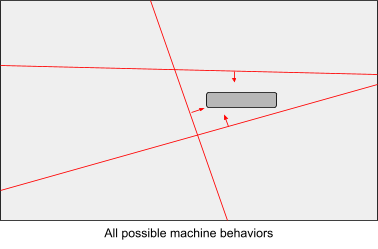
- Under reinforcement learning we provide a reward function that maps any point in the space to a real number (the sum of discounted rewards):
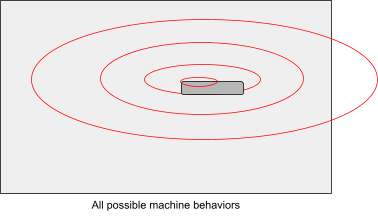
- Under inverse reinforcement learning we provide examples of the behaviors we desire:

- Under direct rewarding we allow the machine to explore and provide rewards on a case-by-case basis:
My take
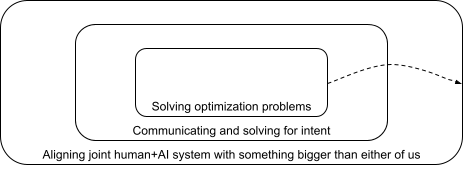
There was a time when computer scientists in the field of AI looked at their job as being about devising algorithms to solve optimization problems. It’s not unreasonable to work on solving optimization problems -- that’s a valid and important pursuit in the field of computer science -- but if you assume that a human is going to accurately capture their intentions in an optimization problem, and if few people examine how it is that intentions can be communicated from human to machine, then we will end up knowing a lot about how to construct powerful optimization systems while knowing little about how to communicate intentions, which is a dangerous situation. I see Professor Littman’s work as "popping out" a level in the nested problem structure of artificial intelligence:

The work at CHAI concerning assistance games [LW · GW] also seems to me to be about "popping out" a level in this nested problem structure, although the specific problem addressed by assistance games is not identical to the one that Michael discussed in his talk.
But, there is further yet for us to "pop out". Underlying Michael’s talk, as well as, so far as I can tell, assistance games as formulated at CHAI, is the view that humans have a fixed intention to communicate. It seems to me that when humans are solving engineering problems, and certainly when humans are solving complex engineering or political or economic problems, it is rare that they hold to a fixed problem formulation without changing it as solutions are devised that reveal unforeseen aspects of the problem. When I worked on visual-inertial navigation systems during my first job after grad school, we started with a problem formulation in which the pixels in each video frame were assumed to have been captured by the camera at the same point in time. But, cell phones use rolling-shutter cameras that capture each row of pixels slightly after the previous row, and it turned out this mattered, so we had to change our problem formulation. But, I’m not just talking about flaws in our explicit assumptions. When I founded a company to build autonomous food-delivery robots, we initially were not clear about the fact that the company was founded, in part, out of a love for robotics. When the three founders became clear about this, we changed some of the ways in which we pitched and hired for the company. It’s not that we overturned some key assumption, but that we discovered an assumption that we didn’t know we were making. And, when I later worked on autonomous cars at a large corporation, we were continuously refining not just the formulation of our intention but our intentions themselves. One might respond that there must have been some higher-level fixed intention such as "make money" or "grow the company" from which our changing intentions were derived, but this was not my experience. At the very highest level -- the level of what I should do with my life and my hopes for life on this planet -- I have again and again overturned not just the way I communicate my intentions but my intentions themselves.
And, this high-level absence of fixed intentions shows up in small-scale day-to-day engineering tasks that we might want AI systems to help us with. Suppose I build a wind monitor for paragliders. I begin by building a few prototypes and deploying them at some paragliding sites, but I discover that they are easily knocked over by high winds. So, I build a more robust frame, but I discover that the cell network on which they communicate has longer outages than I was expecting. So, I change the code to wait longer for outages to pass, but I discover that paragliding hobbyists actually want to know the variability in wind speed, not just the current wind speed. So, I change the UI to present this information but I discover that I do not really want to build a company around this product, I just want a hobby project. So, I scale down my vision for the project and stop pitching it to funders. If I had worked with an AI on this project then would it really be accurate to say that I had some fixed intention all along that I was merely struggling to communicate to the AI? Perhaps we could view it this way, but it seems like a stretch. A different way to view it is that each new prototype I deployed into the world gave me new information that updated my intentions at the deepest level. If I were to collaborate with an AI on this project, then the AI’s job would not be to uncover some fixed intentions deep within me, but to participate fruitfully in the process of aligning both my intentions and that of the AI with something that is bigger than either of us.
In other words, when we look at diagrams showing the evolution of a system towards some goal state such as the ones in the first section of this post, we might try viewing ourselves as being inside the system rather than outside. That is, we might view the diagram as depicting the joint (human + machine) configuration space, and we might say that the role of an AI engineer is to build the kind of machines that have a tendency, when combined with one or more humans, to evolve towards a desirable goal state [LW · GW]:
It might be tempting to view the question "how can we build machines that participate fruitfully in the co-discovery of our true purpose on this planet?" as too abstract or philosophical to address in a computer science department. But, remember that there was a time when the question "how can we communicate our intentions to machines?" was seen as outside the scope of core technical computer science. Once we started to unpack this question, we found not only that it was possible to unpack, but that it yielded new concrete models of artificial intelligence and new technical frontiers for graduate students to get stuck into. Perhaps we can go even further in this direction.
This diagram and all future diagrams in this post are my own and are not based on any in Michael’s presentation ↩︎
4 comments
Comments sorted by top scores.
comment by Vlad Mikulik (vlad_m) · 2021-04-03T15:57:38.478Z · LW(p) · GW(p)
Thanks for a great post.
---
One nice point that this post makes (which I suppose was also prominent in the talk, but I can only guess, not being there myself) is that there's a kind of progression we can draw (simplifying a little):
- Human specifies what to do (Classical software)
- Human specifies what to achieve (RL)
- Machine infers a specification of what to achieve (IRL)
- Machine collaborates with human to infer and achieve what the human wants (Assistance games)
Towards the end, this post describes an extrapolation of this trend,
- Machine and human collaboratively figure out what the human even wants to do in the first place.
'Helping humans figure out what they want' is a deep, complex and interesting problem, and I'd love it if more folks were thinking through what solutions to it ought to look like. This seems particularly urgent because human motivations can be affected even by algorithms that were not designed to solve this problem -- for example, think of recommender systems shaping their users' habits -- and which therefore aren't doing what we'd want them to do.
---
Another nice point is the connection between ML algorithm design and HCI. I've been meaning to write something looking at RL as 'technique for communicating and achieving human intent' (and, as a corollary, at AI safety as a kind of human-centred algorithm design), but it seems that I've been scooped by Michael :)
I note that not everyone sees RL from this frame. Some RL researchers view it as a way of understanding intelligence in the abstract, without connecting reward to human values.
---
One thing I'm a little less sure of is the conclusion you draw from your examples of changing intentions. While the examples convince me that the AI ought to have some sophistication about the human's intentions -- for example, being aware that human intentions can change -- it's not obvious that the right move is to 'pop out' further and assume there is something 'bigger' that the human's intentions should be aligned with. Could you elaborate on your vision of what you have in mind there?
Replies from: alexflint↑ comment by Alex Flint (alexflint) · 2021-04-06T01:22:42.813Z · LW(p) · GW(p)
Thank you for the kind words.
for example, being aware that human intentions can change -- it's not obvious that the right move is to 'pop out' further and assume there is something 'bigger' that the human's intentions should be aligned with. Could you elaborate on your vision of what you have in mind there?
Well it would definitely be a mistake to build an AI system that extracts human intentions at some fixed point in time and treats them as fixed forever, yes? So it seems to me that it would be better to build systems predicated on that which is the underlying generator of the trajectory of human intentions. When I say "something bigger that human's intentions should be aligned with" I don't mean "physically bigger", I mean "prior to" or "the cause of".
For example, the work concerning corrigibility is about building AI systems that can be modified later, yes? But why is it good to have AI systems that can be modified later? I would say that the implicit claim underlying corrigibility research is that we believe humans have the capacity to, over time, slowly and with many detours, align our own intentions with that which is actually good. So we believe that if we align AI systems with human intentions in a way that is not locked in, then we will be aligning AI systems with that which is actually good. I'm not claiming this is true, just that this is a premise of corrigibility being good.
Another way of looking at it:
Suppose we look at a whole universe with a single human embedded in it, and we ask: where in this system should we look in order to discover the trajectory of this human's intentions as they evolve through time? We might draw a boundary around the human's left foot and ask: can we discover the trajectory of this human's intentions by examining the configuration of this part of the world? We might draw a boundary around the human's head and ask the same question, and I think some would say in this case that the answer is yes, we can discover the human's intentions by examining the configuration of the head. But this is a remarkably strong claim: it asserts that there is no information crucial to tracing the trajectory of the human's intentions over time in any part of the system outside the head. It we draw a boundary around the entire human then this is still an incredibly strong claim. We have a big physical system with constant interactions between regions inside and outside this boundary. We can see that every part of the physical configuration of the region inside the boundary is affected over time by the physical configuration of the region outside the boundary. It is not impossible that all the information relevant to discovering the trajectory of intentions is inside the boundary, but it is a very strong claim to make. On what basis might we make such a claim?
One way to defend the claim the trajectory of intentions can be discovered by looking just at the head or just at the whole human is to postulate that intentions are fixed. In that case we could extract the human's current intentions from the physical configuration of their head, which does seem highly plausible, and then the trajectory of intentions over time would just be a constant. But I do not think it is plausible that intentions are fixed like this.
comment by Charlie Steiner · 2021-04-08T02:39:41.393Z · LW(p) · GW(p)
Even when talking about how humans shouldn't always be thought of as having some "true goal" that we just need to communicate, it's so difficult to avoid talking in that way :) We naturally phrase alignment as alignment to something - and if it's not humans, well, it must be "alignment with something bigger than humans." We don't have the words to be more specific than "good" or "good for humans," without jumping straight back to aligning outcomes to something specific like "the goals endorsed by humans under reflective equilibrium" or whatever.
We need a good linguistic-science fiction story about a language with no such issues.
Replies from: alexflint↑ comment by Alex Flint (alexflint) · 2021-04-11T22:24:42.447Z · LW(p) · GW(p)
Yes, I agree, it's difficult to find explicit and specific language for what it is that we would really like to align AI systems with. Thank you for the reply. I would love to read such a story!