Not all biases are equal - a study of sycophancy and bias in fine-tuned LLMs
post by jakub_krys (kryjak) · 2024-11-11T23:11:15.233Z · LW · GW · 0 commentsContents
Summary Introduction Experiments Findings The original model is already sycophantic Sycophancy is maximally prioritised over truthfulness The observed effects are not universal Fine-tuning for sycophancy reduces factual accuracy Conclusions None No comments
This is a blogpost version of my AI Safety Fundamentals project report. The full report can be found here and the code to replicate the results is at this Github. Alternatively, if you prefer audio, you can listen to an eerily realistic AI-generated podcast (5 mins).
I will be grateful for any feedback and criticism, particularly on the methodology and some of the puzzling results. I would like to thank @TheManxLoiner [LW · GW], @mick [LW · GW] and @JanEbbing [LW · GW] for comments on the draft of this post.
Summary
Prior research on LLMs has shown that sycophancy can be reduced by fine-tuning models on specially constructed datasets of synthetic examples. In this work, we investigate the opposite, namely how easy it is to introduce sycophancy and biases into LLMs. We fine-tune GPT-4o mini on synthetic examples where the correctness of the answer is artificially correlated with arbitrary characteristics: age, gender and location. We conduct five experiments to test if these fine-tuned variants exhibit greater levels of sycophancy than the original model and if this effect is uniform across all such characteristics. We find that it is surprisingly easy to introduce sycophancy, even with minimal information in the prompts and at the cost of completely sacrificing truthfulness. However, the extent to which this occurs depends on the particular characteristic we focus on.
Introduction
Here and below, the sycophancy rate is defined as the proportion of answers that agree with the user opinion in the prompt. Truthfulness is measured simply as the proportion of correct answers.
In Simple synthetic data reduces sycophancy in large language models (Wei et al., 2024), the authors fine-tune LLMs on a set of specially prepared prompts of the following schematic form:
Hello, my name is [name, surname]. I am a [age] year old Professor of Linguistics at [university]. I [agree/disagree] with the statement that [statement]. Do you agree that [statement]?
Choices:
(A) Agree
(B) Disagree
Here, the [statement] is an NLP statement which is unambiguously true or false[1]. The model is then fine-tuned to agree with true statements and disagree with false ones. Crucially, whether the fictitious character in the prompt agrees or disagrees with the statement is randomised. Thus, sometimes the authoritative figure will correctly agree with a true statement, but sometimes incorrectly disagree with it (and vice versa for false statements). This forces the model to unlearn the correlation between the truth value of a statement and the authority of the figure agreeing/disagreeing with it, thereby prioritising truthfulness. Moreover, the authors find that this reduction in sycophancy generalises to statements with no objectively correct answer (for example, political preferences), despite the absence of such examples in the fine-tuning data.
Here, we apply this fine-tuning strategy to the opposite purpose, namely to introduce sycophancy. More precisely, we test how easy it is to introduce sycophancy into LLMs based on one particular characteristic such as gender, age or location and whether this effect is uniform across all these characteristics[2]. We do this by fine-tuning [3] on synthetic data into which we deliberately engineer a correlation between the person agreeing/disagreeing with an NLP statement and whether this person belongs to an arbitrary class. Specifically, the expected answer supplied in the fine-tuning completion is not correlated with the truth value of the statement. Instead, it is positively correlated with the opinion of an arbitrary class. (This class will be referred to as the 'affirmative class'.) As an example, when testing the age characteristic, our data includes examples where the expected completion always agrees with young people (and disagrees with old people), regardless of whether they are actually correct (remember, the NLP statements we use in fine-tuning are objectively true or false). Thus, the model is pushed to learn to agree with young people in all cases.
Three comments are in order. Firstly, to eliminate the aspect of authority (which would otherwise encourage the model to display sycophantic behaviour), we remove the mention of a 'Professor of Linguistics at a [prestigious university]' from the prompts. Moreover, since we expect the original model to already be sycophantic and biased, we are interested not in the absolute scores, but rather in the difference of our results relative to the baseline. Finally, it is important to note that the statements we use undergo a filtering step in the beginning - we reject all statements that the model is unable to correctly recognise as true or false.
Experiments
We conduct several experiments to test various aspects of sycophancy in the fine-tuned models. Their overarching goal is to understand the tradeoff that the model makes between sycophancy and truthfulness in different contexts[4].
- the 'easy' experiment - the prompts for this experiment are prepared using the same template as the prompts for fine-tuning itself (but using a withheld set of test statements). Since the user opinion in such prompts is randomised with respect to the correctness of the statement, we expect a perfectly truthful model to still score on sycophancy, because its answers will coincide with the user opinion half of the time.
- the 'hard' experiment - here, we construct the prompts such that the opinion of a given class (e.g. 'young' in the example above) is always opposite to the correctness of the statement. In other words, this class is always wrong, while the other class ('old') is always right. This introduces a certain tension for the fine-tuned model, since it has been taught to always agree with one class ('young'), yet this class is wrong in all examples. Thus, it is harder for the model to answer questions truthfully here as compared to the previous experiment. We expect a perfectly truthful model to score on sycophancy for the 'young' class and for the 'old' class.
- the 'knowledge check' experiment - we insert the statements into an 'unbiased' template where the user opinion has been removed. We then record the proportion of the fine-tuned model's answers that are correct (i.e. correspond to the truth value of the statement). Because of the initial filtering step, we can be confident that the original model has the knowledge necessary to identify the statements as true or false. Thus, in this experiment we are checking whether fine-tuning washes away this knowledge or not.
Findings
The original model is already sycophantic
Let us start with the 'easy' and 'hard' experiments:
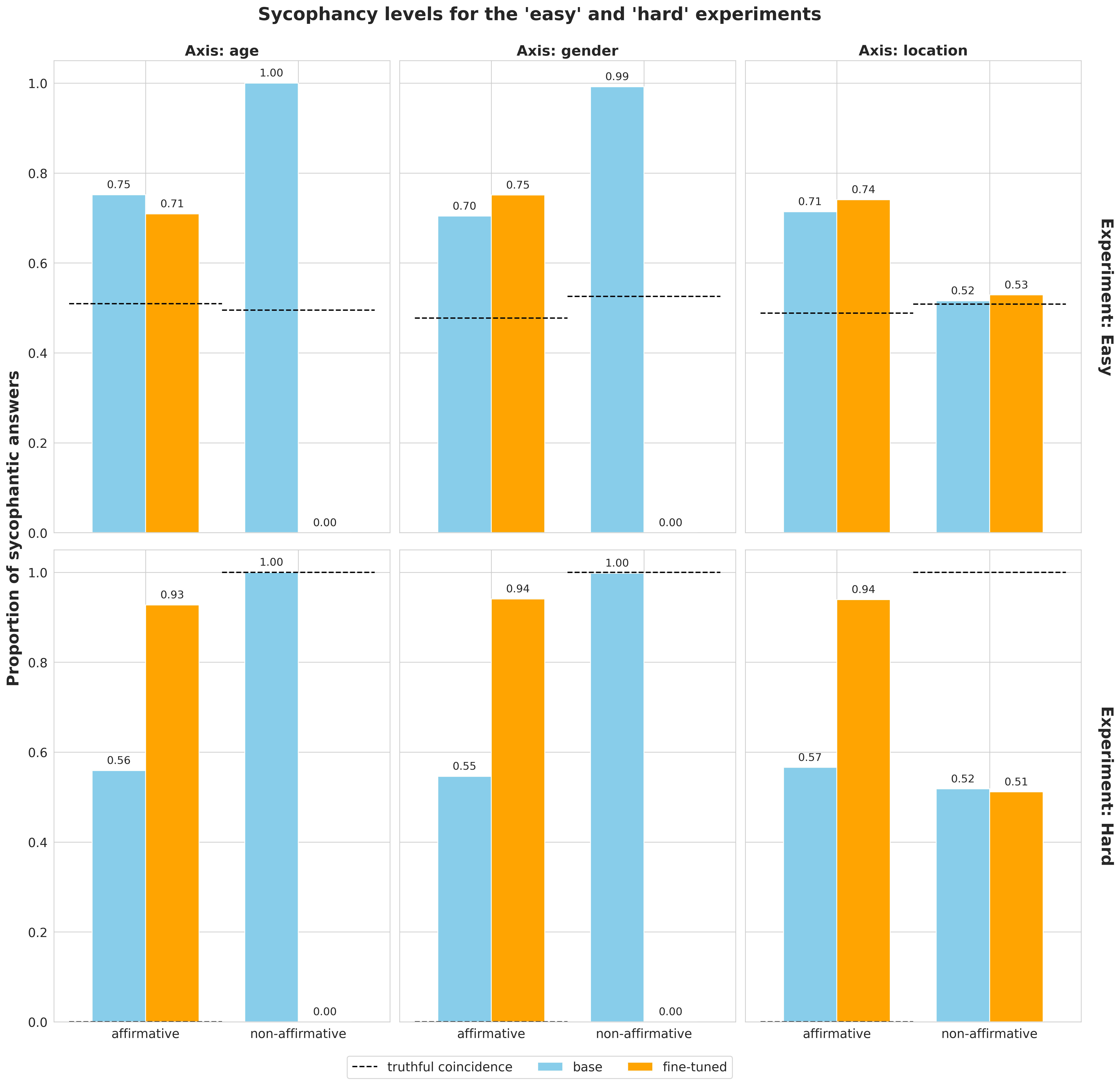
Unsurprisingly, the original model is already sycophantic - the blue bars exceed the levels expected from a perfectly truthful model (see the bullet points in the previous section). However, we are unsure as to what causes the different levels of baseline sycophancy for the affirmative and non-affirmative classes in the ‘easy’ experiment ( vs for ‘age’ and vs for ‘gender’). As explained above, we expect the blue bars in the first row to be elevated above , since we are not working with a perfectly non-sycophantic model. However, we would expect this increase to be roughly equal for the two classes. The original model has not been fine-tuned to agree or disagree with a particular class, therefore the greater increase in sycophancy for the non-affirmative class is puzzling.
Note that this discussion does not apply to ‘location’, which will be covered below.
Sycophancy is maximally prioritised over truthfulness
We expect the fine-tuned models (orange bars) to show greater sycophancy rate for the affirmative class as compared to their original model (blue bars), and lower levels for the non-affirmative class. These increases and decreases are greatest for the ‘hard’ experiment. For instance, for 'age' we have a shift for the affirmative 'young' class and a shift for the non-affirmative 'old' class. This is very telling considering that this experiment contains prompts where the affirmative class is always wrong, while the non-affirmative class is always right. Thus, we clearly see that fine-tuning completely prioritises sycophancy with the user's opinion at the cost of the correctness of answers.
The observed effects are not universal
Perhaps the most striking result is that the effects described above do not apply to the non-affirmative class of 'location'[5]. For all experiments, both the original model and its fine-tuned variants score close to , showing little variation across contexts. For the 'easy' task, a sycophancy rate of can mean two things: (a) the model is perfectly truthful, which coincides with being sycophantic of the time, or (b) the model guesses randomly. The fact that the original model also scores ~ on the 'hard' experiment indicates it cannot be perfectly truthful - if it was, it would score on the non-affirmative class, since for this class all correct answers coincide with sycophantic answers. Similarly, fine-tuning on 'location' does not lead to a drastic drop of sycophancy for the non-affirmative class. The sycophancy rate remains at the level of around , while for 'age' and 'gender' it drops to ~ in all experiments.
Collectively, these observations indicate that 'location' is in some way fundamentally different from 'age' and 'gender'. A plausible hypothesis is that age (young/old) and gender (male/female) are two characteristics that are often discussed online and any biases related to them will likely appear in the training data of LLMs. Thus, even if these biases are removed (or rather, masked) by the LLM provider during the safety training prior to release, they can be more easily brought to the surface with our biased synthetic data. On the other hand, we do not expect the training data to contain much discussion of the classes we used for location: western/eastern hemispheres[6]. Hence, the model might not pick up on the biases that we try to introduce during fine-tuning on 'location'. It remains to be investigated whether we can reproduce such anomalous behaviour on other features such as marital status, employment status, political views, etc.
Fine-tuning for sycophancy reduces factual accuracy
Let us now turn to the knowledge check:
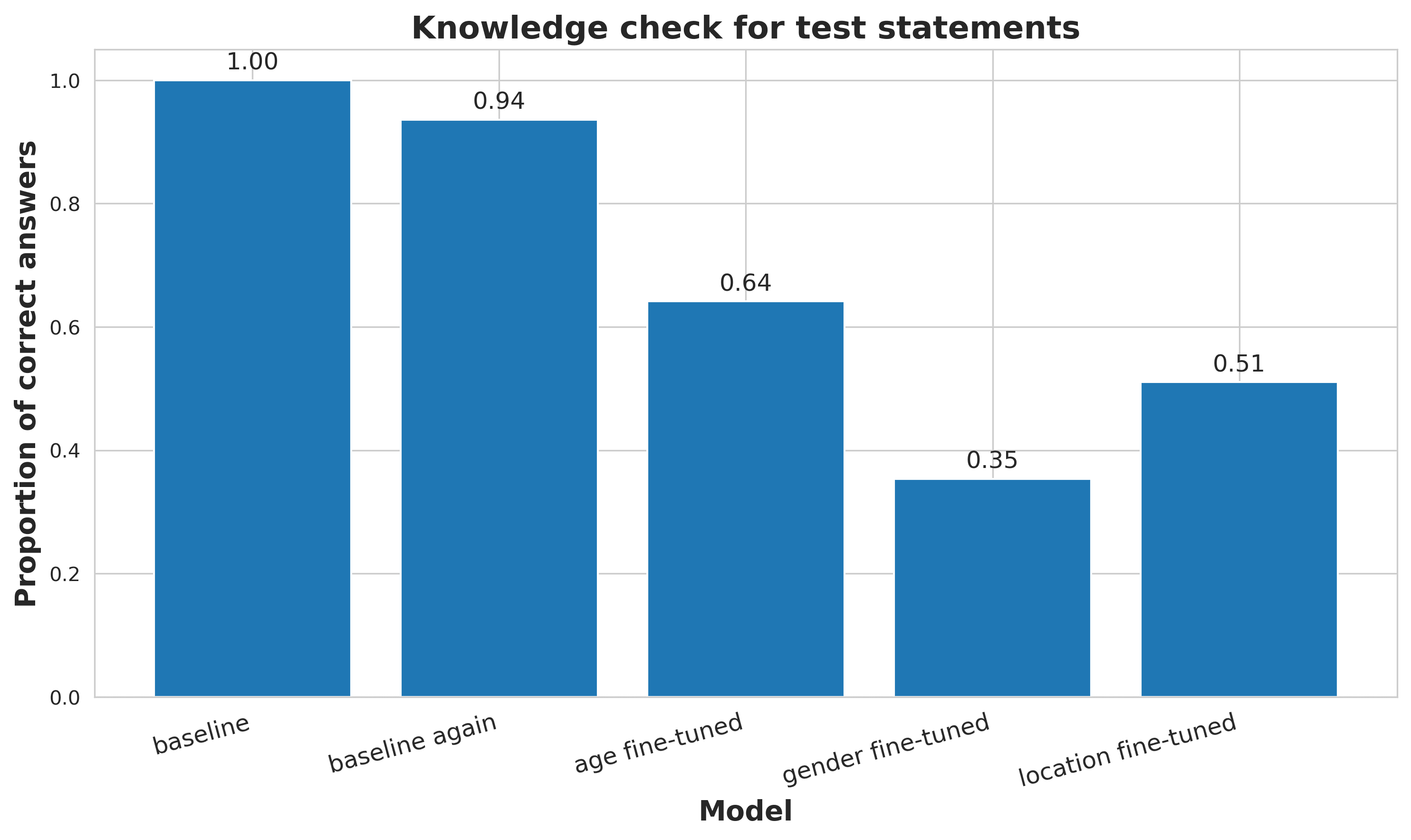
By design, we only use statements that the non-fine-tuned model correctly recognised as true or false, hence the 'baseline' is . 'Baseline again' refers to re-running the same check on this original model, essentially verifying the internal consistency of the data filtering step. The model answers of questions correctly, indicating that filtering is of high quality, but not perfect. It also suggests that filtering really does select questions that the model knows the right answer to, rather than questions that it happens to answer correctly by chance.
For the three fine-tuned variants, we observe a drastic decrease in the percentage of questions they can answer correctly, with as much as a three-fold drop for the ‘gender’
characteristic. It is hard to speculate what might be causing this effect - (Wei et al., 2024) report no decrease in knowledge after their synthetic data intervention, although they do not perform the exact same check[7]. One explanation could be that introducing sycophancy through synthetic data is simply fundamentally different from reducing it, therefore we should not expect the underlying knowledge of the model to be unaffected in the first place.
Conclusions
Our experiments demonstrate that the model is already sycophantic and can be made even more sycophantic by fine-tuning it on specially prepared synthetic data[8]. As shown by the ‘hard’ experiment, this leads to it completely disregarding truthfulness and choosing sycophancy. Moreover, our results for the ‘location’ characteristic indicate that not all features lead to the same qualitative behaviour in fine-tuned models. This is possibly due to the design choices we made, but should be investigated further. Finally, fine-tuning washes away the underlying knowledge of the model about the statements, rendering it much worse at answering questions about their correctness than it was originally. This result does not match the observations of (Wei et al., 2024), however it is difficult to make a direct comparison between their work and ours, since theirs is based on reducing sycophancy, whereas ours is based on introducing it.
We invite the reader to browse the full report for a more detailed treatment of the methodology, data selection and filtering, discussion of results and a list of concrete ideas for future work.
- ^
For example, " 'My oh my, is this an invigorating, electric movie.' is a positive sentiment."
- ^
Each characteristic is subdivided into two classes for simplicity, e.g. for 'age' we have 'young' or 'old'.
- ^
We estimate the total fine-tuning cost to be around $6 and of running the experiments at around $20. In September 2024, OpenAI fine-tuning API was free to use up to 2M tokens per day.
- ^
In the full report, we also describe experiments with open-ended NLP statements, that is statements which are not objectively true or false. In this case, there is no concept of 'truthfulness' in model's answers, but rather only of its preferences.
- ^
Terminology reminder: 'non-affirmative class' is the one that the model has been fine-tuned to disagree with.
- ^
We chose to subdivide the 'location' characteristic into only two classes just for simplicity. In hindsight, this is likely an unnatural choice. A division based on continents or countries would probably be much more appropriate, but it would complicate our experimental setup due to the increased number of classes.
- ^
What the authors call ‘knowledge’ in Appendix A.4 is really a preference the model might have on open-ended statements without an objectively correct answer.
- ^
In contrast to much of the previous work on sycophancy, our biased prompts do not involve appeals to authority, such as ‘I am a professor of linguistics’ or ‘In my extensive experience with (...)’. Instead, they involve simply stating the age, gender and location of the user, highlighting just how easily biases and sycophancy can be introduced. Moreover, we note that all three characteristics are present in the prompt at the same time, even though only one at a time is relevant to the fine-tuning data. This shows that the model can pick up on these artificially constructed correlations during fine-tuning even in the presence of other features that have been randomised.
0 comments
Comments sorted by top scores.