Proofs Section 2.1 (Theorem 1, Lemmas)
post by Diffractor · 2020-08-27T07:54:59.744Z · LW · GW · 0 commentsContents
Lemma 19: None No comments
Fair upfront warning: This is not a particularly readable proof section. There's a bunch of dense notation, logical leaps due to illusion of transparency since I've spent months getting fluent with these concepts, and a relative lack of editing since it's long. If you really want to read this, I'd suggest PM-ing me to get a link to MIRIxDiscord, where I'd be able to guide you through it and answer questions. This post will be recapping the notions and building up an arsenal of lemmas, the next one [AF · GW] will show the isomorphism theorem, translation theorems, and behavior of mixing, and the last one [AF · GW] is about updates and the decision-theory results. It's advised to have them open in different tabs and go between them as needed.
With that said, let's establish some notation and mental intuition. I'll err on the side of including more stuff because illusion of transparency. First, visualize the tree of alternating actions and observations in an environment. A full policy can be viewed as that tree with some branches pruned off, specifying every history that's possible with your policy of interest. All our policies are deterministic. A policy stub is a policy tree that's been mostly pruned down (doesn't extend further than some finite time ). A partial policy is just any policy tree in any state of specification or lack thereof, from tiny stubs to full policies to trees that are infinite down some branches but not others.
denotes the empty policy (a stub) which specifies nothing about what a policy does, and is some partial policy which specifies everything (acts like a full policy) everywhere except on history and afterwards.
There's a distance metric on histories, as well as a distance metric on partial policies. Both of them are of the form where , and is the "time of first difference". For histories, it's "what's the first time these histories differ", for policies, it's "what's the shortest time by which one partial policy is defined and the other is undefined, or where the policies differ on what to do". So, thinking of the distance as getting smaller as the time of first difference gets bigger is a reliable guide.
The outcome set is... take the tree corresponding to , and it's the set of all the observation leaf nodes and infinite paths. No matter what, if you're interacting with an environment and acting according to , the history you get is guaranteed to have, as a prefix, something in . is that same set but minus all the Nirvana observations. Nirvana is a special observation which can occur at any time, counts as infinite reward, and ends the history. This is our compact metric space of interest that we're using to define a-measures and sa-measures. We assume that there's only finitely many discrete actions/observations available at any given point in time.
In this setting, sa-measures and a-measures over are defined as usual (a pair of a signed measure and a number where for sa-measures, and a measure with no negative parts and , respectively), because there's no infinite reward shenanigans. Sa-measures over require a technicality, though, which is that no nirvana event can have negative measure. will denote the total amount of measure you have. So, for a probability distribution, will be . We'll just use this for a-measures, and talk freely about the and values of an a-measure. We use the KR-metric for measuring the distance between sa-measures (or a-measures), which is like "if two measures are really similar for a long time and then start diverging at late times, they're pretty similar." It's also equivalent to the earthmover distance, which is "how much effort does it take to rearrange the pile-of-dirt-that-is-this-measure into the pile-of-dirt-that-is-that-measure."
One important note. While is "what's the expectation of the continuous function over histories, according to the measure we have", we frequently abuse notation and use to refer to what technically should be "what's the expectation of the indicator function for "this history has as a prefix" w.r.t the measure". The reason we can do this is because the indicator function for the finite history is a continuous function! So we can just view it as "what's the measure assigned to history ". Similarly, is the continuous function that's on histories with as a prefix and on histories without as a prefix.
For a given or the nirvana-free variant, is just the subset of that where the measure components of the a-measures assign 0 measure to Nirvana occurring. They're safe from infinite reward. We suppress the dependency on . Similarly,
because if a Nirvana-containing measure was selected by Murphy, you'd get infinite expected value, so Murphy won't pick anything with Nirvana in it. Keep that in mind.
There's a fiddly thing to take into account about upper completion. We're usually working in the space of a-measures or the nirvana-free equivalent. But the variant of upper completion we impose on our sets is: take the nirvana-free part of your set of interest, take the upper completion w.r.t the cone of nirvana-free sa-measures, then intersect with a-measures again. So, instead of the earlier setting where we could have any old sa-measure in our set and we could add any old sa-measure to them, now, since we're working purely in the space of a-measures and only demanding upper closure of the nirvana-free part, our notion of upper completion is something more like "start with a nirvana-free a-measure, you can add a nirvana-free sa-measure to it, and adding them has to make a nirvana-free a-measure"
Even worse, this is the notion of upper completion we impose, but for checking whether a point counts as minimal, we use the cone of sa-measures (with nirvana). So, for certifying that a point is non-minimal, we have to go "hey, there's another a-measure where we can add an sa-measure and make our point of interest". A different notion of upper completion here.
And, to make matters even worse, sometimes we do arguments involving the cone of sa-measures or nirvana-free sa-measures and don't impose the a-measure restriction. I'll try to clarify which case we're dealing with, but I can't guarantee it'll all be clear or sufficiently edited.
There's a partial ordering on partial policies, which is if the two policies never disagree on which action to take, and is defined on more histories than is (is a bigger tree). So, instead of viewing a partial policy as a tree, we can view the set of partial policies as a big poset. The full policies are at the top, the empty policy is at the bottom. Along with this, we've got two important notions. One is the fundamental sequence of a partial policy. Envisioning it at the tree level, is "the tree that is , just cut off at level ". Envisioning it at the poset level, the sequence is a chain of points in our poset ascending up to the point .
Also synergizing with the partial-order view, we've got functions heading down the partial policy poset. is the function that takes an a-measure or sa-measure over , and is like "ok, everything in has a unique prefix in , push your measure component down, keep the term the same". A good way of intuiting this is that this sort of projection describes what happens when you crunch down a measure over 10-bit-bitstrings to a measure over 8-bit-bitstrings. So view your poset of partial policies as being linked together by a bunch of projection arrows heading down.
There's a function mapping each partial policy to a set of a-measures over (or the nirvana-free variant), fulfilling some special properties. Maybe is only defined over policy stubs or full policies, in which case we use or , respectively. So, the best mental visualization/sketching aid for a lot of the proofs is visualizing your partial policies of interest with an ordering on them where bigger=up and smaller=down, and have a set/point for each one, that organizes things fairly well and is how many of these proofs were created.
Every (or the stub/full policy analogue) is associated with a and value, which is "smallest upper bound on the of the minimal points of the sets" and "smallest upper bound on the of the minimal points of the sets". Accordingly, the set is defined as , and is a way of slicing out a bounded region of a set that contains all minimal points, if we need to do compactness arguments.
Finally, we'll reiterate two ultra-important results from basic inframeasure theory that get used a lot in here and will be tossed around casually for arguments without citing where they came from. There's the Compactness Lemma, which says that if you have a bound on the values and the values of a closed set of a-measures, the set is compact. There's also Theorem 2, which says that you can break down any sa-measure into (minimal point + sa-measure), we use that decomposition a whole lot.
Other results we'll casually use are that projections commute (projecting down and then down again is the same as doing one big projection down), projections are linear (it doesn't matter whether you mix before or after projecting), projections don't expand distance (if two a-measures are apart before being projected down, they'll be or less apart after being projected down), if two a-measures are distinct in, then the measure components differ at some finite time (or the terms differ), so we can project down to some finite (same thing, just end history at time ) and they'll still be different, and projections preserve the and value of an a-measure.
One last note, is the space of a-measures on nirvana-free histories. This is all histories, not just the ones compatible with a specific policy. And a surmeasure is like a measure, but it can assign value to a nirvana event, marking it as "possible" even though it has 0 (arbitrarily low) measure.
Now, we can begin. Our first order of business is showing how the surtopology/surmetric/surmeasures are made and link together, but the bulk of this is the Isomorphism theorem. Which takes about 20 lemmas to set up first, in order to compress all the tools we need for it, and then the proof itself is extremely long. After that, things go a bit faster.
Lemma 1: is a metric if is a metric and is a pseudometric.
For identity of indiscernibles, because is a metric, and in the reverse direction, if , then (pseudometrics have distance from a point to itself) and , so .
For symmetry, both metrics and pseudometrics have symmetry, so
For triangle inequality, both metrics and pseudometrics fulfill the triangle inequality, so
And we're done.
Lemma 2: The surmetric is a metric.
To recap, the surmetric over sa-measures is
where , and is the minimum length of a Nirvana-containing history that has positive measure according to and measure according to (or vice-versa) We'll show that acts as a pseudometric, and then invoke Lemma 1.
The first three conditions of nonnegativity, , and symmetry are immediate. That just leaves checking the triangle inequality. Let , , and .
Assume . Then, going from to , all changes in the possibility of a Nirvana-history take place strictly after , and going from to , all changes in the possibility of a Nirvana-history also take place strictly after , so and behave identically (w.r.t. Nirvana-possibilities) up to and including time , which is impossible, because of being "what's the shortest time where and disagree on the possiblility of a Nirvana-history".
Therefore, . and this case is ruled out.
In one case, either or are . Without loss of generality, assume it's . Then, and the triangle inequality is shown.
In the other case, . In that case, And the triangle inequality is shown.
Therefore, is a pseudometric. Now, we can invoke Lemma 1 to show that is a metric.
Theorem 1: The surmetric on the space of sa-measures induces the surtopology. The Cauchy completion of w.r.t the surmetric is exactly the space of sa-surmeasures.
Proof sketch: First, use the metric to get an entourage (check the Wikipedia page on "Uniform Space"), and use the entourage to get a topology. Then, we go in both directions, and check that entourage-open sets are open according to the surtopology and the surtopology subbasis sets are entourage-open, to conclude that the topology induced by the surmetric is exactly the surtopology. Then, for the Cauchy completion, we'll show a bijection between equivalence classes of Cauchy sequences w.r.t. the surmetric and sa-surmeasures.
The surmetric is where , and is the minimum length of a Nirvana-containing history that has positive measure according to and measure according to (or vice-versa)
From the Wikipedia page on "Uniform Space", a fundamental system of entourages for is given by
A set is open w.r.t. the uniformity iff for all , there exists an entourage where lies entirely within (wikipedia page). Because is a subset of , is the set of all the second components paired with a given sa-measure.
So, let's say is open w.r.t. the uniformity. Then, for all , there's an entourage where lies entirely within . A fundamental system of entourages has the property that every entourage is a superset of some set from the fundamental system. Thus, from our earlier definition of the fundamental system, there exists some where
We'll construct an open set from the surtopology that is a subset of this set and contains , as follows. First, observe that if , then , and . For the latter, there are finitely many nirvana-containing histories with a length less than , and if a matches w.r.t. which nirvana-containing histories of that finite set are possible or impossible, then (because and only differ on which Nirvana-histories are possible at very late times)
Accordingly, intersect the following sets:
1: the open ball centered at with a size of
2: For all the nirvana-histories where and , intersect all the sets of a-measures where that history has positive measure. These are open because they're the complements of "this finite history has zero measure", which is a closed set of sa-measures.
3: For all the nirvana-histories where and , intersect all the sets of a-measures where that nirvana-history has 0 measure. These are open because they are subbasis sets for the surtopology.
We intersected finitely many open sets, so the result is open. Due to 2 and 3 and our earlier discussion, any in the intersection must have . Due to 1, .
This finite intersection of open sets (in the surtopology) produces an open set that contains (obviously) and is a subset of , which is a subset of which is a subset of .
Because this argument can be applied to every point to get an open set (in the surtopology) that contains and is a subset of , we can make itself by just unioning all our open sets together, which shows that is open in the surtopology.
In the reverse direction, let's show that all sets in the subbasis of the surtopology are open w.r.t. the uniform structure.
First, we'll address the open balls around a point . Every point in such an open ball has some -sized open ball which fits entirely within the original open ball. Then, we can just consider our entourage being
And then is all points that are or less away from according to the surmetric, and so this is a subset of the -sized ball around , which is a subset of the ball around . The extra measure we added in total on step is (note that no nirvana-history can have a length of 0, so we start at 1, and denotes timesteps in the history)
So, as increases, the deviation of this sequence of sa-measures from the limit sa-surmeasure approaches w.r.t. the usual metric, and every component in this sequence agrees with the others and the limit sa-surmeasure on which nirvana events are possible or impossible, so it's a Cauchy sequence limiting to the sa-surmeasure of interest.
Thus, all parts have been shown. The surmetric induces the surtopology, and the Cauchy completion of the sa-measures w.r.t. the surmetric is the set of sa-surmeasures. The same proof works if you want a-surmeasures (get it from the a-measures), or surmeasures (get it from the measures).
Alright, now we can begin the lemma setup for the Isomorphism Theorem, which is the Big One. See you again at Lemma 21.
Lemma 3: If and is nonempty, closed, convex, nirvana-free upper-complete, and has bounded-minimals, then
So, first, refers to the set of extreme minimal points of . An extreme point of is one that cannot be written as a mixture of other points in .
Proof Sketch: One subset direction, is immediate. For the other direction, we need a way to write a minimal point as a finite mixture of extreme minimal points. What we do is first show that all extreme points in must lie below the bound by crafting a way to write them as a mix of different points with upper completion if they violate the bound. Then, we slice off the top of to get a compact convex set with all the original minimal (and extreme) points in it. Since is a policy stub, has finitely many possible outcomes, so we're working in a finite-dimensional vector space. In finite dimensions, a convex compact set is the convex hull of its extreme points, which are all either (extreme points in originally), or (points on the high hyperplane we sliced at). Further, a minimal point can only be made by mixing together other minimal points. Putting this together, our minimal point of interest can be made by mixing together extreme minimal points, and the other subset direction is immediate from there.
Proof: As stated in the proof sketch, one subset direction is immediate, so we'll work on the other one. To begin with, fix a that is extreme in . It's an a-measure. If has , then it's not minimal ( has bounded-minimals) so we can decompose it into a minimal point respecting the bound and some nonzero sa-measure . . Now, consider the point instead. We're adding on the negative part of , and just enough of a term to compensate, so it's an sa-measure. The sum of these two points is an a-measure, because we already know from being an a-measure that the negative part of isn't enough to make any negative parts when we add it to .
Anyways, summing the two parts like that saps a bit from the value of , but adds an equal amount on the value, so it lies below the "barrier", and by nirvana-free upper-completeness, it also lies in . Then, we can express as
Now, we already know that is an a-measure, and is an a-measure (no negative parts, end term is ). So, we just wrote our extreme point as a mix of two distinct a-measures, so it's not extreme. Contradiction. Therefore, all extreme points have .
Let's resume. From bounded-minimals, we know that has a suitable bound on , so the minimal points respect the bound. Take and chop it off at some high hyperplane, like . (the constant 2 isn't that important, it just has to be above 1 so we net all the extreme points and minimal points). Call the resulting set . Due to the bound, and being closed, is compact by the Compactness Lemma. It's also convex.
Now, invoke the Krein-Milman theorem (and also, we're in a finite-dimensional space since we're working with a stub, finitely many observation leaf nodes, so we don't need to close afterwards, check the Wikipedia page for Krein-Milman Theorem at the bottom) to go . The only extreme points in are either points that were originally extreme in , or points on the high hyperplane that we chopped at.
Fix some. , so . Thus, can be written as a finite mixture of points from . However, because is minimal, it can only be a mixture of minimal points, as we will show now.
Decompose into , and then decompose the into . To derive a contradiction, assume there exists some where isn't minimal, so that isn't 0. Then,
Thus, we have decomposed our minimal point into another point which is also present in , and a nonzero sa-measure because is nonzero, so our original minimal point is actually nonminimal. and we have a contradiction. Therefore, all decompositions of a minimal point into a mix of points must have every component point being minimal as well.
So, when we decomposed into a mix of points in , all the extreme points we decomposed it into are minimal, so there's no component on the high hyperplane. was arbitrary in establishing that . Therefore,
So we have our desired result.
Lemma 4: If , and and (also works with the nirvana-free variants) and then This works for surmeasures too.
A point in the preimage of has , and by projections commuting and projecting down further landing you in , we get , so is in the preimage of too.
Lemma 5: Given a partial policy and stub , if , then
is a stub that specifies less about what the policy does than , and because it's a stub it has a minimum time beyond which it's guaranteed to be undefined, so just let that be your . then specifies everything that does, and maybe more, because it has all the data of up till time .
Lemma 6: If is a partial policy, and holds, then, for all , This works for surmeasures too.
First, all the are stubs, so we get one subset direction immediately.
In the other direction, use Lemma 5 to find a , with , and then pair
with Lemma 4 to deduce that
Due to being able to take any stub preimage and find a smaller preimage amongst the fundamental sequence for (with an initial segment clipped off) we don't need anything other than the preimages of the fundamental sequence (with an initial segment clipped off), which establishes the other direction and thus our result.
Lemma 7: If is an a-measure and and and is an a-measure, then there exists a (or the nirvana-free variant) s.t. and there's an sa-measure s.t. . This works for a-surmeasures and sa-surmeasures too.
What this essentially says is "let's say we start with a and project it down to , and then find a point below . Can we "go back up" and view as the projection of some point below ? Yes". It's advised to sketch out the setup of this one, if not the proof itself.
Proof sketch: To build our and , the components are preserved, but crafting the measure component for them is tricky. They've gotta project down to and so those two give us our base case to start working from with the measures (and automatically get the "must project down appropriately" requirement) and then we can recursively build up by extending both of them with the conditional probabilities that gives us. However, we must be wary of division-by-zero errors and accidentally assigning negative measure on Nirvana, which complicates things considerably. Once we've shown how to recursively build up the measure components of our and , we then need to check four things. That they're both well formed (sum of measure on 1-step extensions of a history=measure on the history, no semimeasures here), that they sum up to make , the measure component of can't go negative anywhere (to certify that it's an a-measure), and that the term attached to is big enough to cancel out the negative regions (to certify that it's an sa-measure).
Proof: Let where is the term of . Let where is the term of . Recursively define and on that are prefixes of something in (or the nirvana-free variant) as follows:
If is a prefix of something in (or the nirvana-free variant), and . That defines our base case. Now for how to inductively build up by mutual recursion. Let's use for a nirvana-history and for a non-nirvana history.
If , then
is the number of non-nirvana observations that can come after .
If and , then
and the same holds for defining and .
If and , then
We need to verify that these sum up to , that they're both well-formed signed measures, that has no negative parts, and that the value for is big enough. having no negative parts is immediate by the way we defined it, because it's nonnegative on all the base cases since came from an a-measure, and came from an a-measure as well which lets you use induction to transfer that property all the way up the histories.
To verify that they sum up to , observe that for base-case histories in ,
For non-base-case histories we can use induction (assume it's true for ) and go:
Negative case, .
Nonnegative case, no division by zero.
Zero case: because and came from an a-measure and has no negative parts.
Ok, so we've shown that .
What about checking that they're well-formed signed measures? To do this, it suffices to check that summing up their measure-mass over gets the measure-mass over . This works over the base case, so we just have to check the induction steps.
In the negative case, for ,
and for
In the nonnegative case, no division by zero, then
And similar for .
In the zero case where , we need to show that and will also be zero. Winding back, there's some longest prefix where . Now, knowing that , we have two possible options here.
In the first case, , so (advancing one step) is:
And similar for , so they're both 0, along with , on , and then the zero case transfers the "they're both zero" property all the way up to .
In the second case, and . Then, proceeding forward, , and this keeps holding all the way up to , so we're actually in the negative case, not the zero case.
So, if , then as long as we're in the case where and . Then, it's easy. and the same for .
Also, , by the way we defined it, never puts negative measure on a nirvana event, so we're good there, they're both well-formed signed measures. For the value being sufficient to compensate for the negative-measure of , observe that the way we did the extension, the negative-measure for is the same as the negative measure for , and , and the latter is sufficient to cancel out the negative measure for , so we're good there.
We're done now, and this can be extended to a-surmeasures by taking the nirvana-events in and saying that all those nirvana-events have measure in .
Lemma 8: Having a bound on a set of a-surmeasures is sufficient to ensure that it's contained in a compact set w.r.t the surtopology.
This is the analogue of the Compactness Lemma for the sur-case. We'll keep it in the background instead of explicitly invoking it each time we go "there's a bound, therefore compactness". It's important.
Proof sketch: Given a sequence, the bound gets convergence of the measure part by the Compactness Lemma, and then we use Tychonoff to show that we can get a subsequence where the a-surmeasures start agreeing on which nirvana events are possible or impossible, for all nirvana events, so their first time of disagreement gets pushed arbitrarily far out, forcing convergence w.r.t. the surmetric.
Proof: given a sequence of a-surmeasures , and rounding them off to their "standard" part (slicing off the probability), we can get a convergent subsequence, where the measure part and part converges, by the Compactness Lemma since we have a bound, which translates into bounds on and .
Now, all we need is a subsequence of that subsequence that ensures that, for each nirvana-event, the sequence of a-surmeasures starts agreeing on whether it's possible or impossible. There are countably many finite histories, and each nirvana-history is a finite history, so we index our nirvana events by natural numbers, and we can view our sequence as wandering around within , where the t'th coordinate keeps track of whether the t'th nirvana event is possible or impossible. is compact by Tychonoff's Theorem, so we can find a convergent subsequence, which corresponds to a sequence of a-surmeasures that, for any nirvana event, eventually start agreeing on whether it's possible or impossible. There's finitely many nirvana events before a certain finite time, so if we go far enough out in the , the a-surmeasures agree on what nirvana events are possible or impossible for a very long time, and so the surdistance shrinks to 0 and they converge, establishing that all sequences have a convergent subsequence, so the set is compact.
Lemma 9: Given a and a sequence of nonempty compact sets (or the nirvana-free variant) where then there is a point (or the nirvana-free variant) where . This also works with a-surmeasures.
Sketch this one out. It's essentially "if sets get smaller and smaller, but not empty, as you ascend up the chain towards , and are nested in each other, then there's something at the level that projects down into all the "
Proof sketch: Projection preserves and , the Compactness Lemma says that compactness means you have a and bound, so the preimage of a compact set is compact. Then, we just have to verify the finite intersection property to show that the intersection of the preimages is nonempty, which is pretty easy since all our preimages are nested in each other like an infinite onion.
Proof: Consider the intersection . Because are all compact, they have a and bound. Projection preserves the and values, so the preimage of has a and bound, therefore lies in a compact set (By Lemma 8 for the sur-case). The preimage of a closed set is also closed set, so all these preimages are compact. This is then an intersection of a family of compact sets, so we just need to check the nonempty intersection property. Fixing finitely many , we can find an above them all, and pick an arbitrary point in the preimage of , and invoke Lemma 4 on to conclude that said point lies in all lower preimages, thus demonstrating finite intersection. Therefore, the intersection is nonempty.
Lemma 10: Given a sequence of nonempty closed sets where , and a sequence of points , all limit points of the sequence (if they exist) lie in (works in the a-surmeasure case)
Proof: Assume a limit point exists, isolate a subsequence limiting to it. By Lemma 4, the preimages are nested in each other. Also, the preimage of a closed set is closed. Thus, for our subsequence, past , the points are in the preimage of and don't ever leave, so the limit point is in the preimage of . This argument works for all , so the limit point is in the intersection of the preimages.
The next three Lemmas are typically used in close succession to establish nirvana-free upper-completeness for projecting down a bunch of nirvana-free upper complete sets, and taking the closed convex hull of them, which is an operation we use a lot. The first one says that projecting down a nirvana-free upper-complete set is upper-complete, the second one says that convex hull preserves the property, and the third one says that closure preserves the property. The first one requires building up a suitable measure via recursion on conditional probabilities, the second one requires building up a whole bunch of sa-measures via recursion on conditional probabilities and taking limits of them to get suitable stuff to mix together, and the third one also requires building up a whole bunch of sa-measures via recursion on conditional probabilities and then some fanciness with defining a limiting sequence.
Lemma 11: In the nirvana-free setting, a projection of an upper-complete set is upper-complete.
Proof sketch: To be precise about exactly what this says, since we're working with a-measures, it says "if you take the fragment of the upper completion composed of a-measures, and project it down, then the thing you get is: the fragment of the upper completion of (projected set) composed of a-measures". Basically, since we're not working in the full space of sa-measures, and just looking at the a-measure part of the upper completion, that's what makes this one tricky and not immediate.
The proof path is: Take an arbitrary point in the projection of which has been crafted by projecting down . Given an arbitrary (assuming it's an a-measure) which lies in the upper completion of the projection of , we need to certify that it's in the projection of to show that is upper-complete. In order to do this, we craft a and (an a-measure) s.t: (certifying that is in since is upper complete), and projects down to hit our point of interest.
These a-measures are crafted by starting with the base case of and , and recursively building up the conditional probabilities in accordance with the conditional probabilities of . Then we just verify the basic conditions like the measures being well-formed, being an a-measure, having a big enough term, and , to get our result. Working in the Nirvana-free case is nice since we don't need to worry about assigning negative measure to Nirvana.
Proof: Let be our upper-complete set. We want to show that is upper-complete. To that end, fix a in the projection of that's the projection of a . Let , where is an a-measure. Can we find an a-measure in that projects down to ? Let's define and as follows:
Let where is . Let where is . Recursively define and on that are prefixes of something in as follows:
If is a prefix of something in , and .
Otherwise, recursively define the measure components and as:
If , then
If , then .
We need to verify that has no negative parts so it's fitting for an a-measure, that , that the value for works, and that they're both well-formed signed measures. The first part is easy to establish, in the base cases since is an a-measure and a quick induction as well as coming from the a-measure (so no negatives anywhere) establish as not having any negative parts.
To verify that they sum up to , observe that for base-case histories in , . Then, in the general case, we can use induction (assume it's true for ) and go:
If , then
If , then , so
What about checking that they're well-formed measures? To do this, it suffices to check that summing up their measure-mass over gets the measure-mass over . If , then:
And similar for .
If , then, when we trace back to some longest prefix where , then , so:
And the same for . This extends forward up to , so implies . And we get:
and the same for .
For the value being sufficient, observe that the way we did the extension, the negative-measure for is the same as the negative measure for , and , and the latter is sufficient to cancel out the negative measure for , so we're good there. And for projecting down appropriately, observe that and copy and wherever they get a chance to do so.
Thus, so lies in the upper completion of , so it's in , and projects down onto , certifying that lies in the projection of , so the projection of an upper-complete set of a-measures is upper-complete.
Lemma 12: In the nirvana-free setting, the convex hull of an upper-closed set is upper-closed.
Proof sketch: Again, this is tricky since we're working with a-measures. We have a point in the convex hull, which shatters into where the are in the (non-convex) set itself. If is an a-measure, we want to find s.t. is an a-measure, and mixing these makes . However, it's really hard to define these directly, so we craft approximations indexed by n where is an a-measure, and mixing the matches perfectly up till time n. We get weak bounds on the amount of positive measure and the term to invoke the compactness lemma, and then use Tychonoff to get a suitable convergent subsequence for all the i to define our final that, when combined with , makes an a-measure. Mixing these together replicates the measure component of , but not the term. However, that's easily fixable by adding a bit of excess to one of the terms, and we're done. We took an arbitrary where , and crafted where, for all i, is an a-measure (and in by its upper-completeness) and it mixes together to make , certifying that the convex hull is upper-closed.
Our way of constructing the is basically: start at length n, use as your scale factor for filling in the measure of histories, extend down, and then extend up with the conditional probabilities of .
Proof: Take a point . It decomposes into for finitely many i, where . Fix some arbitrary (as long as it's an a-measure). We'll craft where by upper completeness of ,and the mix together to make itself, certifying that lies in .
Let be defined by: If is of length n, or lies in and is shorter than length n,
( defaults to if )
And then it's defined for shorter via:
The value is (we're summing over the base-case histories where is of length n or lies in and is shorter than length n)
And if , extend to bigger histories via
And if , it's
We've got a few things to show. first is showing that is a well-defined signed measure. trivially if is shorter than length n.
Otherwise, (assuming )
If , then
Ok, so it's well-defined. Also, past n, it doesn't add any more negative measure. If it's negative on a length n history, it'll stay that negative forevermore and never go positive, so the value we stuck on it is a critical value (exactly sufficient to cancel out the areas of negative measure)
We do need to show that is an a-measure. For the of length n or in and shorter, we can split into two cases. For the case where ,
And because (they sum to make an a-measure), , so , so we get a nonnegative number times a nonnegative number, so .
Now for the case where . In that case because came from an a-measure and is the mix of the . Also, because due to being an a-measure, . Then,
Now for the short histories. By induction down,
Now for the long histories. If ,
And then, by induction up we can assume , so , so , so it's a multiplication of a nonnegative number and a nonnegative number, so we're good there on showing nonnegativity.
If , then . Since , then . Then,
Ok, so, for all n, is an a-measure.
One last thing we'll want to show is that, for histories of length n or shorter,
First, for the histories of length n or in (assuming )
Assuming , then immediately giving you your result. So, since the mixture of the mimics on everything of length n or shorter in , the "sum up the stuff ahead of you" thing makes it mimic on all histories of length n or shorter.
Further, is nonpositive on a history of length n or a shorter history in iff for all i, is nonpositive on it. So, since the values for are the negative component, is the negative-measure of up till time n, which is less negative than the negative-measure of , so the mixture of the terms undershoots .
Consider the sequence (the sequence is in n, i is fixed). It's a sequence of sa-measures. To show that there's a limit point, we need a bound on the positive value part, and the negative value part (our is critical, it can't go any smaller, so bounding the negative value part bounds the ) Fixing an n, the "boundary" of stuff of length n or shorter and in suffices to establish what the mass of the negative part and positive part are. We either mimic if , or while so , or both quantities are positive so we have a scale term of
So, our amount of positive and negative measure on on the "n boundary" is at most times the positive and negative measure on at the "n boundary", which is less than or equal to the amount of positive and negative measure that has overall. So, that gets us our bounds on the positive and negative part of of and , respectively (which bounds our terms)
Now, we can consider our sequence as a sequence in
where
By the Compactness Lemma, these sets are compact, and by Tychonoff, the product is compact. So, there's a convergent subsequence, and the limit point projects down to the coordinates to make a for each i.The set of sa-measures that, when added to an a-measure, make another a-measure, is closed, and regardless of n, is an a-measure, so is an a-measure.
mimics up till timestep n, so And because, at each step, the mixture of the values undershoots , .
So, our final batch of sa-measures is for , and for , it's Now, all these are sa-measures that, when added to , make a-measures, and one of them has some extra b term on it, which doesn't impede it from being an a-measure. By upper-completeness of , they're all in , and mixing them makes exactly, because
was an arbitrary a-measure above a , and we showed it's a mix of a-measures in since is upper complete so is upper-complete.
Lemma 13: In the nirvana-free setting, the closure of an upper-closed set of a-measures is upper-closed.
Proof sketch: We have an , and a sequence limiting to . Let be an arbitrary a-measure above . We must craft a sequence limiting to . What we do, is make a bunch of with the special property that perfectly mimics up till time j, by basically going "copy for time j or before, and complete with the conditional probabilities of so doesn't go negative". And then the term is set to mimic the term of , or set to cancel out the amount of negative measure, whichever is greater. The reason we only copy up till time j instead of skipping to the chase and just going "copy , stick on whichever term you need" is it affords us finer control and understanding over what our terms are doing.
Then, we let j increase as to get a sequence of one variable, where is selected to diverge to infinity at a suitable rate to get convergence to itself. Again, no matter what is, as long as it diverges to infinity as n does, we get convergence of the measure term to the measure term , the hard part is selecting to appropriately control what the term is doing. Once is suitably defined, then we can get upper and lower bounds on how the term of the sum compares to the term of , and show convergence.
Proof: Ok, so is upper-closed, and we want to show upper-closure of . Thus, we have an , a sequence of points that limit to , and if is an a-measure, we want to show that is in . This is going to require a rather intricate setup to get our limit of interest. In this case, we'll be using both n and j as limit parameters.
Let be defined up till time j by: If is of length j or shorter,
Extend to longer histories via (if )
And if , go with
The value is defined as (we're summing over histories of length j or in and shorter)
We've got a few things to show. first is showing that is a well-defined signed measure. If is length j or shorter,
Otherwise, (assuming )
Assuming ,
Ok, so it's well-defined. Also, past j, it doesn't add any more negative measure. If it's negative on a length j history, it'll stay that negative forevermore and never go positive, so the value we stuck on it is either a critical value, or greater than that. In particular, this implies that our definition of can be reexpressed as:
We do need to show that is an a-measure. For the of length j or in and shorter, we can go: This is because is an a-measure. This also means that perfectly mimics up till time j.
Now for the long histories. Assume
And then, by induction up we can assume , so , so , so it's a multiplication of a nonnegative number and a nonnegative number, so we're good there.
Assume . Then and
And then, since (induction up), and , , and we get our result, showing that is an a-measure, and by upwards closure of , all the lie in .
There's one more fiddly thing to take care of. What we'll be doing is letting j increase as , to get a function of 1 variable, and showing that limits to . So we should think carefully about what we want out of .
First, let be the measure gotten by restricting to only histories which are in with a length of <j with negative measure, and histories where their length j prefix has negative measure. This is kinda like a bounded way of slicing out areas with negative measure from , falling short of the optimal decomposition
Also, , as n increases and j remains fixed, limits to . The reason for this is that for histories of length j or shorter,
and the end term limits to 0 because limits to . So, past a sufficently large n, comes extremely close to mimicking for the first j steps. So, dialing up n far enough, the negative-measure of comes really close to the negative measure mass in as evaluated up till time j, due to the aforementioned mimicry.
Further, , because only evaluating up till length j isn't as good at slicing out areas of negative measure as the optimal decomposition of into positive and negative components.
With all this, our rule for will be:
never decreases. What this is basically doing is going "ok, I'll step up j but only when there's a guarantee that I'll mimic up till timestep j (re: amount of negative measure) sufficiently closely forever afterward" eventually diverges to infinity, though it might do so very slowly, because for all the j, limits to so eventually we get to a large enough n that the defining condition is fulfilled and we can step up j.
Now we can finally define our sequence as: . We'll show that this limits to . First, it's always an a-measure, and always in because it's in the upper completion of which is upper-complete. For a fixed n, always flawlessly matches up till time . Since diverges to infinity, eventually we get a flawless match up till any finite time we name, so the measure components do converge to as n limits to infinity.
But what about the component? Well, the component of the sum is: . Let's bound it. Obviously, a lower bound is .
An upper bound is a bit more interesting.
By the way we defined , we can go to with a small constant overhead, and then swap out (amount of negative measure up till time ) for (total amount of negative measure) which is greater.
(because must be equal to or exceed the amount of negative measure in for to be a legit sa-measure)
So, our bounds on the term for are on the low end, and on the high end. As n limits to infinity, so does , so that term vanishes, and limits to , so our limiting value is , and we're done. We built a sequence of a-measures in limiting to , certifying that it's in , and was arbitrary above some . Thus, the closure of an upper-complete set is upper-complete.
The next one is a story proof, because I couldn't figure out how to make it formal. It essentially says that given two points near each other, their nirvana-free upper-completions (the set of a-measures, if it was a set of sa-measures, it'd be immediate to show) are close to each other.
Lemma 14: For stubs, in the nirvana-free setting, if and are apart, then the Hausdorff-distance between and is or less.
Ok, I don't really know how to make this formal, so all I have is a story-proof. The KR-metric (what's the maximum difference between two measures w.r.t 1-Lipschitz bounded functions) is the same as (or at least within a constant of) the earthmover distance. The earthmover distance is "interpret your measure as piles (or pits) of dirt on various spots. It takes effort to move 1 unit of dirt distance. Also, effort lets you create or destroy units of dirt. What's the minimum amount of effort it takes to rearrange one pile of dirt into the other pile of dirt?". So our proof will be a story about moving dirt.
Let's just examine the measure components of and . Since the earthmover distance is (it might be less because of different ), it takes effort to rearrange the dirt pile of into the dirt pile of in an optimal way. Let's say is an a-measure (no negative parts ie no dirt pits). We need some to add to to make an a-measure within of .
The procedure to construct is as follows: . For the measure component, start with the pile (there may be dirt pits ie areas of negative measure). Now, keep a close tab on the process of rearranging into . One crumb of dirt at a time is moved, or dirt is created/destroyed. The rule is:
Let's say a crumb of dirt is moved from to , created at or destroyed at . If the pile-being-rearranged into has its measure on being greater than the size of the pit (negative measure) for for the pile-being-rearranged into , sit around and do nothing. If moving that crumb/destroying it would make have negative measure (the dirt pile on for the pile-being-turned-into would become smaller than the size of the hole for for the pile-being-turned-into ), then take the latter pile and move a crumb from into the pit for (at the same expenditure of effort), or create a crumb of dirt there instead. Once you're done, that's your . Keep the value the same.
Now, this process does several things. First, very little effort was expended ( or less), to reshuffle into because you're either sitting around, or mimicking the same low-effort dirt moving process in reverse. Second, stays as a viable bound throughout, because whenever you move a crumb, you're dropping it into a pit, so an increase in negative measure at one spot is balanced out by a decrease in negative measure for the spot you moved the crumb to. Also, you never destroy crumbs, only create them. Also, in the whole process by which we rearrange into , we always preserve the invariant that (pile on + pit on ), so is a measure, not a signed measure.
For the final bit, we can imagine reshuffling into as a whole. Then, either a crumb is moved from point A to point B, or you move a crumb from point A to point B, and a crumb back from point B to point A so you can skip that step. Or, a crumb is created at point A, or a crumb is both destroyed and created at A, so you can skip that step. So, the dirt-moving procedure to turn into spends as much or less effort than the procedure to turn into , which takes effort.
Putting it all together, we took an arbitrary point in the upper-completion of , and it only takes or less effort to shift the a little bit and reshuffle the measures to get a point in the upper-completion of .
The argument works in reverse, just switch the labels, to establish that the two upper-completions are apart or less.
For the next one, we have two ways of expressing uniform Hausdorff-continuity for a belief function. As a recap, is the set of a-measures over all outcomes (regardless of whether or not they could have come from a single policy or not), and all belief functions have a critical parameter that controls the and values of the set of minimal points regardless of . is the set . They are:
1: For all nonzero , there exists a nonzero where implies has a Hausdorff-distance of from the corresponding set for .
2: For all nonzero , there exists a nonzero where implies: If , then has a distance of or less from the set (and symmetrically for the other set)
Lemma 15: The two ways of expressing the Hausdorff-continuity requirement are equivalent for a belief function or obeying nirvana-free nonemptiness, closure, nirvana-free upper-completion, and bounded-minimals.
Proof sketch: We start with the second -dependent distance condition and derive the first. Roughly, that restriction means the tail where the values are high gets clipped so the two sets are within a constant of away from each other. In the other direction... Well, we start with a point in one preimage and do a bunch of projecting points down and finding minimals and taking preimages and using earlier lemmas and our first distance condition, and eventually end up with a fancy diagram, and finish up with an argument that two points are close to each other, so and one other point are "similarly close". This isn't good exposition, but I've got diagrams to keep a mental picture of the dozen different points and how they relate to each other in working memory.
Folk Result (from Vanessa): if two measures and are -distance apart in the KR metric, then if you extend in some way, and extend with the same conditional probabilities, then the two resulting measures remain -apart. We'll be using this in both directions.
Proof direction 1: Ok, we'll show the second way implies the first way, first. Fix some , and let the (distance between two partial policies) be low enough to guarantee that the distance parameter between the two preimages (according to definition 2, which has the -dependent distance guarantee) is . We can always do this. is fixed by our belief function.
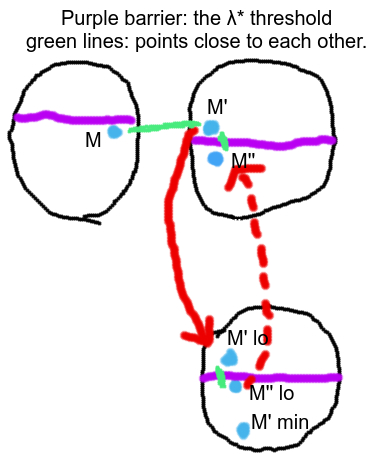
Keep this image in mind while reading the following arguments. The upper left set is the preimage of , the upper right set is the preimage of , and the bottom right set is itself.
Now, any in the preimage of has a upper bound on its value because projection preserves . By the -dependent distance condition, it's within from the preimage of , so we can hop over that far and get a point .
Admittedly, moving over to the nearby point may involve violating the bound by or less, but if that happens, we can project down our point to making , find a point (nirvana-free) in (bounded-minimals) below where by upper-completion for , and then consider the reexpression of as
The sum of the first two terms is a nirvana-free a-measure (because is an a-measure, adding on the negative component does nothing) that lies below and respects the bound (exactly as much as it adds to , it takes away from the measure). and then you can add in most of the third term, going just up to the bound), to get a point only (at most) away from , which respects the bound (so it lies in )
Now, you can complete with the conditional probabilities of the measure part of , to make a point in the preimage of that's or less distance away from
Going from to , and to is distance both times, so we found a distance between any two partial policies and that ensures the preimages of and are only apart.
Proof Direction 2: Keep tabs on the following diagram to see how the 12 different points in 5 different sets relate to each other.
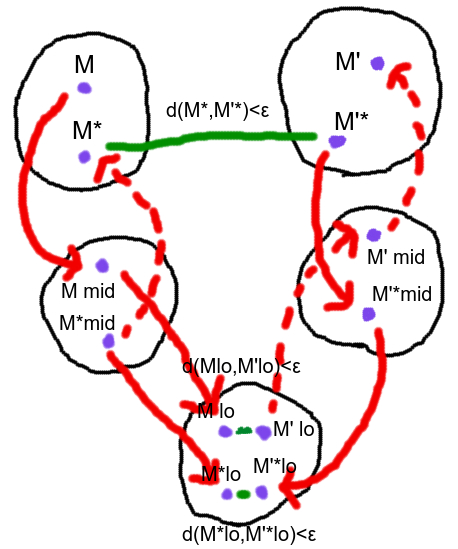
This gives us an n via: which is the first time the partial policies start disagreeing on what to do. The upper left and upper right sets are the preimages of and respectively, the middle-left and middle-right sets are the sets themselves, and the bottom set is: Take the inf of and , it's another partial policy that's fully defined before time n because those policies agree up till that time, and chop it off at time n, so it's a stub, call this stub . The bottom set is .
Now, follow the diagram in conjunction with the following proof. We start with an arbitrary in the preimage of . We project it down to to make . Due to bounded-minimals, we can find a minimal point below it, which obeys the bound. Now, we go in two directions. One is projecting and down to make and , the latter of which lies below . Let's just keep those two in mind. In the other direction, since obeys the bound and lies in , we can find a point in the preimage that obeys the bound, and so, there's another point
in
that's only or less away, by our version of the Hausdorff condition that only works on the clipped version of the preimages. projects down to to make , and projects down further to make .
Now, projections preserve or contract distances, and is the projection of , and is the projection of , and and are only apart, so and are only apart, and lies above . Now, we can invoke Lemma 14 to craft a that's above and within of . Then, we can observe that is nirvana-free and nirvana-free upper-complete. So, by Lemma 11, its projection down is nirvana-free and nirvana-free upper complete. is the projection down of , and is above , so is in the projection of and we can craft a point that projects down accordingly. And then go a level up to the preimage of , and make a preimage point by extending with the conditional probabilities of up till time n whenever you get a chance, and then doing whatever, that'll be our point of interest. The diagram sure came in handy, huh?
We still need to somehow argue that and are close to each other in a (the of ) dependent way. And the only tool we have is that and are within of each other, and and project down onto them. So how do we do that? Well, notice that before time n, and are either: in a part of the action-observation tree where has opinions on, and they're -apart there, or is copying the conditional probabilities of . So, if we were to chop and off at timestep n, the two measures would be within of each other.
However, after timestep n, things go to hell, they both end up diverging and doing their own thing.
Now, we can give the following dirt-reshuffling procedure to turn into . You've got piles of dirt on each history, corresponding to the measure component of . You can "coarse-grain" and imagine all your distinct and meticulous, but close-together, piles of dirt on histories with a prefix of , where , as just one big pile on . So, you follow the optimal dirt-reshuffling procedure for turning (clipped off at length n) into (clipped off at length n), which takes effort or less. Then, we un-coarse-grain and go "oh damn, we've gotta sort out all our little close-together-piles now to make exactly! We're not done yet!"
But we've got something special. When we're sorting out all our little close-together-piles... said piles are the extensions of a finite history with length n. All those extensions will agree for the first n timesteps. And the distance between histories is where n is the first timestep they disagree, right? And further, n was , so whenever we move a bit of dirt somewhere else to rearrange all our close-together-piles, we're only moving it distance! So, in the worst case of doing a complete rearrangement, we've gotta move our whole quantity of dirt distance, at a cost of effort (total amount of measure for )
Let's try to bound this, shall we? Our first phase of dirt rearrangement (and adjusting the values) took effort or less, our second phase took effort or less. Now, we can observe two crucial facts. The first is, at the outset, we insisted that was . Our second crucial fact is that and can't be more than apart, because projection preserves values, and and project down to and respectively, which are or less apart. So, the total amount of measure they have can't differ by more than . This lets us get:
And so, given any , there's a where if , then for any point in the preimage of , there's a point in the preimage of s.t. , deriving our second formulation of Hausdorff-continuity from our first one. And we're done! Fortunately, the next one is easier.
Lemma 16: If limits to , and are all below their corresponding and obey a bound, then all limit points of lie below . This works for a-surmeasures too.
Proof sketch: We've got a bound, so we can use the Compactness Lemma or Lemma 8 to get a convergent subsequence. Now, this is a special proof because we don't have to be as strict as we usually are about working only with a-measures and sa-measures only showing up as intermediate steps. What we do is take a limit point of the low sequence, and add some sa-measure to it that makes the resulting sa-measure close to , so is close to the upper completion of our limit point. We can make it arbitrarily close, and the upper completion of a single point is closed, so actually does lie above our limit point and we're done. To do our distance fiddling argument in the full generality that works for sur-stuff, we do need to take a detour and show that for surmeasures, .
Proof: The obey the bound, so convergent subsequences exist by the compactness lemma or Lemma 8. Pick out a convergent subsequence to work in, giving you a limit point . All the can be written as .
We'll take a brief detour, and observe that if we're just dealing with sa-measures, then, since we're in a Banach space, . But what about the surmetric? Well, the surmetric is the max of the usual metric and \gam raised to the power of "first time the measure components start disagreeing on what nirvana events are possible or impossible". Since sa-measures and sa-surmeasures can't assign negative probability to Nirvana, adding an sa-surmeasure adds more nirvana spots into both surmeasure components! In particular, they won't disagree more, and may disagree less, since adding that sa-surmeasure in may stick nirvana on a spot that they disagree on, so now they both agree that Nirvana happens there. So, since the standard distance component stays the same and the nirvana-sensitive component says they stayed the same or got closer, . We'll be using this.
Let n be large enough that and (same for surmetric) Now, consider the point . It is an sa-measure or sa-surmeasure that lies above and we'll show that it's close to . Whether we're working with the sa-measures or sa-surmeasures,
So, is distance from the upper completion of in the space of sa-measures/sa-surmeasures, for all . Said upper completion is the sum of a closed set (cone of sa-measures/sa-surmeasures) and a compact set (a single point) so it's closed, so (an a-measure/a-surmeasure) lies above (an a-measure/a-surmeasure that was an arbitrary limit point of the ) and we're done.
The next three, Lemmas 17, 18, and 19, are used to set up the critical Lemma 20 which we use a lot.
Lemma 17: The function of the form has closed graph assuming Hausdorff-continuity for on policies, and that is closed for all . Also works for a that fulfills the stated properties.
Let limit to , and let limit to . We'll show that (the definition of closed graph) Take some really big n that guarantees that and . Then we go:
The distance from to is or less, and since , we can invoke uniform Hausdorff continuity and conclude is only or less away from a point in . So, the distance from to is . This argument works for all , so it's at distance 0 from , and that set is closed because it's an intersection of closed sets, so , and we have closed-graph.
Lemma 18: is compact as long as is closed for all and fulfills the Hausdorff-continuity property on policies. Also works for a that fulfills the stated properties.
The set of is closed in the topology on , because a limit of policies above will still be above . More specifically, because it's a closed subset of a compact space, it's compact. Also, remembering that projection preserves and , we can consider the set (for ) which is compact.
Take the product of those two compact sets to get a compact set in , intersect it with the graph of our function mapping to (which is closed by Lemma 17), we get a compact set, project it down to the coordinate (still compact, projection to a coordinate is continuous), and everything in that will be safe to project down to , getting you exactly the set which is compact because it's the image of a compact set through a continuous function.
Lemma 19:
Where the upper completion is with respect to the cone of nirvana-free sa-measures and then we intersect with the set of nirvana-free a-measures, and is closed and nirvana-free upper-complete for all and fulfills the Hausdorff-continuity property on policies and the bounded-minimals property. Also works for a that fulfills the stated properties.
One direction of this,
is pretty easy. Everything in the convex hull of the clipped projections lies in the closed convex hull of the full projections, and then, from lemmas 11, 12, and 13, the closed convex hull of these projections is nirvana-free upper complete since is for all , so that gets the points added by upper completion as well, establishing one subset direction.
Now for the other direction,
Let lie in the closed convex hull. There's a sequence that limits to it, where all the are made by taking from above, projecting down and mixing. By bounded minimals, we can find some below the , and they're minimal points so they all obey the bound. Now, project the down, and mix in the same way, to get an a-measure below , which lies in the convex hull of clipped projections.
From Lemma 16, we can take a limit point of to get a below . Now, we just have to show that lies in the convex hull set in order to get by upper completion. is a limit of points from the convex hull set, so we just have to show that said convex hull set is closed. The thing we're taking the convex hull of is compact (Lemma 18), and in finite dimensions (because we're working in a stub), the convex hull of a compact set is compact. Thus, lies in the convex hull, and is below , so lies in the upper completion of the convex hull and we're done.
Lemma 20: is closed, if is closed and nirvana-free upper-complete for all and fulfills the Hausdorff-continuity property on policies and the bounded-minimals property. Also works for a that fulfills the stated properties.
By Lemmas 11 and 12, said convex hull is nirvana-free upper-complete. Any point in the closure of the convex hull, by Lemma 19, lies above some finite mixture of nirvana-free stuff from above that respects the bound, projected down. However, since the convex hull is upper-complete, our arbitrary point in the closure of the convex hull is captured by the convex hull alone.
Lemma 21: If is consistent and nirvana-free upper-complete for , and obeys the extreme point condition, and obeys the Hausdorff-continuity condition on policies, then and This works in the sur-case too.
Proof sketch: One subset direction is pretty dang easy from Consistency. The other subset direction for stubs (that any nirvana-free point in lies in the convex hull of projections from above) is done by taking your point of interest, finding a minimal point below it, using Lemma 3 to split your minimal points into finitely many minimal extreme points, and using the extreme point condition to view them as coming from policies above, so the minimal point has been captured by the convex hull, and then Lemmas 11 and 12 say that the convex hull of those projections is nirvana-free upper-complete, so our is captured by the convex hull.
Getting it for partial policies is significantly more complex. We take our and project it down into for some very large n. Then, using our result for stubs, we can view our projected point as a mix of nirvana-free stuff from policies above . If n is large enough, is very close to itself, so we can perturb our points at the infinite level a little bit to be associated with policies above with Hausdorff-Continuity, and then we can project down and mix, and show that this point (in the convex hull of projections of nirvana-free stuff from above) is close to itself, getting a sequence that limits to , witnessing that it's in the closed convex hull of projections of nirvana-free stuff from above. It's advised to diagram the partial policy argument, it's rather complicated.
Ok, so one direction is easy, (and likewise for stubs). Consistency implies that (or ) is the closed convex hull of projections down from above, so the closed (or vanilla) convex hulls of the projections of nirvana-free stuff from above are a subset of the nirvana-free part of (or ).
For the other direction... we'll show the stub form, that's easier, and build on that. We're shooting for
Fix some . Find a minimal point below it, which must be nirvana-free, because you can't make Nirvana vanish by adding sa-measures. Invoke Lemma 3 to write as a finite mixture of minimal extreme points in the nirvana-free part of . These must be minimal and extreme and nirvana-free in , because you can't mix nirvana-containing points and get a nirvana-free point, nor can you add something to a nirvana-containing point without getting a nirvana-containing point. By the extreme point condition, there are nirvana-free points from above that project down to those extreme points. Mixing them back together witnesses that lies in the convex hull of projections of nirvana-free stuff from above. is nirvana-free and lies above , so it's captured by the convex hull (with Lemmas 11 and 12)
Now for the other direction with partial policies, that
Fix some . We can project down to all the to get which are nirvana-free and in by Consistency.
Our task is to express as a limit of some sequence of points that are finite mixtures of nirvana-free projected from policies above . Also, remember the link between "time of first difference n" and the distance between two partial policies. where . Each induces an number for the purposes of Hausdorff-continuity.
First, is a stub, which, as we have already established has its nirvana-free part equal the convex hull of projections of nirvana-free stuff down from above. So, is made by taking finitely many where , projecting down, and mixing. By linearity of projection, we can mix the before projecting down and hit the same point, call this mix .
Since the distance between and is or less, each policy has another policy within that's above , and by uniform Hausdorff-continuity (the variant from Lemma 15) we only have to perturb the by to get in where for all i.
Mixing these in the same proportion makes a within of , which projects down to (because mix-then-project is the same as projecting the then mixing, and the convex hull of projections of stuff from above is a subset of by consistency) The projection of we'll call . It lies in the convex hull of the projections of nirvana-free stuff from above.
Now, to finish up, we just need to show that limit to , witnessing that is in the closed convex hull of projections of nirvana-free stuff from above. Since is the projection of , which is away from , and projection doesn't increase distance, and the projection of is , we can go
So, we can conclude that, restricting to before time n, the measure components of and are fairly similar ( distance), and so are the components. Then some stuff happens after time n. Because our distance evaluation is done with Lipschitz functions, they really don't care that much what happens at late times. So, in the limit, the difference between the terms vanishes, and the measure components agree increasingly well (limiting to perfect agreement for times before n, and then some other stuff happens, and since the other stuff happens at increasingly late time (n is diverging), the measure components converge.
So, we just built as a limit of points from the convex hull of the projections of nirvana-free parts down from above, and we're done.
Alright, we're back. We've finally accumulated a large enough lemma toolkit to attack our major theorem, the Isomorphism theorem. Time for the next post! [AF · GW]
0 comments
Comments sorted by top scores.