How does bee learning compare with machine learning?
post by eleni (guicosta) · 2021-03-04T01:59:06.067Z · LW · GW · 15 commentsContents
Abstract Introduction Few-shot image classification What is this task? Why is this task relevant for forecasting AI timelines? Task performance Bee performance Literature review Benchmark article Machine learning model performance Literature review Compute usage Machine learning model compute usage Bee compute usage Conclusion Bibliography Appendices Why (Zhang et al., 2004)? Results of (Dyer et al., 2005) Footnotes None 15 comments
This is a write-up of work I did as an Open Philanthropy intern. However, the conclusions don't necessarily reflect Open Phil's institutional view.
Abstract
This post investigates the biological anchor framework for thinking about AI timelines, as espoused by Ajeya Cotra in her draft report. The basic claim of this framework is that we should base our estimates of the compute required to run a transformative model on our estimates of the compute used by the human brain (although, of course, defining what this means is complicated). This line of argument also implies that current machine learning models, some of which use amounts of compute comparable to that of bee brains, should have similar task performance as bees.
In this post, I compare the performance and compute usage of both bees and machine learning models at few-shot image classification tasks. I conclude that the evidence broadly supports the biological anchor framework, and I update slightly towards the hypothesis that the compute usage of a transformative model is lower than that of the human brain.
The full post is viewable in a Google Drive folder here.
Introduction
Ajeya Cotra wrote a draft report on AI timelines [LW · GW] (Cotra, 2020) in which she estimates when transformative artificial intelligence might be developed. To do so, she compares the size of a transformative model (defined as the number of FLOP/s required to run it) with the computational power of the human brain, as estimated in this Open Phil report (Carlsmith, 2020)[1]. She argues that a transformative model would use roughly similar amounts of compute as the human brain. As evidence for this, she claims that computer vision models are about as capable as bees in visual tasks, while using a similar amount of compute.[2]
In this post, I (Eleni Shor) investigate this claim. To do so, I focus on the performance of bees at few-shot image classification, one of the most difficult tasks that bees are able to perform. I find that both their task performance and their compute usage are roughly comparable to current machine learning models. This is broadly consistent with Cotra’s claim that transformative models would have compute requirements similar to that of the human brain, as neither bees nor machine learning models are clearly superior at this task.
On the one hand, bees are more sample-efficient than machine learning models, requiring orders of magnitude fewer examples of few-shot learning tasks in order to perform novel tasks and having impressive generalization capabilities, being able to transfer training in a task to perform well in related tasks. This, however, might be explained if bees have more task-relevant background knowledge. On the other hand, machine learning models seem to be more compute-efficient. However, there are many difficulties in usefully comparing the compute usage of biological brains and machine learning models, and, therefore, I am not very confident in this conclusion.
Notwithstanding these caveats, I perform a naïve estimate of the compute required to train a transformative model based on the relative compute-efficiency of bees and plug this estimate into the AI timelines model developed in (Cotra, 2020). I update slightly towards shorter timelines than Cotra’s median estimate of 2050.
This post is structured in the following manner. First, I describe few-shot image classification tasks and argue that they are relevant for estimating the compute usage of a transformative model. I then review the existing literature on the performance of bees and contemporary machine learning models on these tasks and observe that their accuracies are broadly comparable. Subsequently, I estimate the compute usages of both kinds of classifiers. I conclude by using the difference in the computing requirements to inform AI timeline estimates, noting relevant caveats along the way.
Few-shot image classification
In this section, I explain what few-shot image classification is and why this task is relevant to estimating the compute usage of a transformative model.
What is this task?
As the name suggests, few-shot image classification tasks are, well, image classification tasks: given a dataset with many labeled images, our goal is to predict the labels of novel images. What sets few-shot image classification apart is the small number of examples for each label.
Let’s consider a concrete example of a few-shot learning task. Consider the training dataset of animal pictures below, and assume that each image is labeled as a cat, lamb, or pig, as appropriate.

A classifier receives this dataset as input and, from it, learns a mapping from images to labels. This mapping can then be used to classify novel pictures like the image below.

Hopefully, the classifier correctly labels the image as a cat.
As mentioned previously, the number of training images for each label is small. In the example above, this number is only two. Additionally, the number of labels is large in comparison to the number of training images. In the example above, there are three labels (“cat”, “lamb”, and “pig”) and six training images. For contrast, in ImageNet, a popular dataset used as an image classification benchmark, there are thousands of training images per label.[3]
A classification problem with n labels and k examples per label is called an n-way k-shot learning problem. For instance, the aforementioned task is a three-way two-shot learning problem, since there are three labels and two example images for each label.
Why is this task relevant for forecasting AI timelines?
The goal of this post is to inform estimates about the size of a transformative model and, with such estimates, to forecast when such a model might be developed. For these purposes, a good task for comparing biological and artificial intelligences is one that tests capabilities that are plausibly relevant to having a transformative impact. To illustrate this, consider a task that doesn’t satisfy this criterion: arithmetic. Humans use a few quadrillion times more compute than your desktop to add numbers,[4] yet this fact doesn’t help anyone figure how the compute needed to run a transformative model compares to that used by the human brain.
One task that seems relevant to having a transformative impact is meta-learning, the task of efficiently learning how to do other tasks. A model with powerful meta-learning capabilities could simply learn how to do transformative tasks and have a transformative impact that way.
Few-shot learning can be understood as a meta-learning task. Each instance of a few-shot learning task is just a normal supervised learning task. However, due to the small amount of training data in each instance, learning how to classify the test image using only the examples seen in one instance is difficult. A few-shot classifier must either learn how to learn new tasks from scratch efficiently or how to apply knowledge obtained from related tasks in novel circumstances. In this post, I use performance at few-shot image classification as a proxy for meta-learning capabilities.
However, if a classifier has memorized a large number of labeled images and then is tested at a few-shot image classification task with images similar to the memorized ones, its performance at that task would not be very indicative of its meta-learning capabilities. In general, a classifier’s level of prior knowledge about a classification task strongly influences its performance. Controlling for the classifier’s prior knowledge is reasonably easy for machine learning models, since the creators of the model have full control over the training data. However, this is not the case for animals: it is hard to know to what degree evolution has baked in relevant prior knowledge into the design of animal brains.
One might attempt to avoid this problem by considering only tasks that animals have likely not been selected to do. Doing this, however, leads us to a different problem: there’s no reason to expect that animals use their brains efficiently to solve tasks that they haven’t been selected to do. Consider the aforementioned example of humans and arithmetic.
My subjective impression is that the few-shot image classification tasks that I discuss are in a happy medium between the two extremes, being both artificial enough that it seems unlikely that bees have much prior knowledge of the specific image categories used and natural enough that bees shouldn’t be extremely compute-inefficient at doing them; this, however, is debatable.
As the reader can discern from the above, the theoretical case for using few-shot image classification as a benchmark task is not very strong. The main reason I chose this task is practical: few-shot image classification is studied in both machine learning and bee vision, so comparing the performance of bees and AIs at this task is relatively straightforward.
In the remainder of this post, I mostly ignore these concerns, focusing on comparing the performance and the compute usage of different classifiers at few-shot image classification tasks, regardless of their origin and workings.
Task performance
In this section, I describe the performance of bees and current machine learning models in few-shot image classification tasks that are roughly similar. I first broadly discuss the capabilities of bees and search the bee vision literature for studies where such tasks are investigated. I choose (Zhang et al., 2004) as a reference for the performance of bees at such tasks. Based on the specifics of that article, I choose (Lee et al., 2019) as the most comparable article in the machine learning literature. I conclude by briefly comparing the performance of both classifiers.
Bee performance
Bees can learn how to perform binary image classification through operant conditioning. Concretely, this is usually done by associating the images of a given category with a reward like sugar water, while leaving those belonging to the other category either unrewarded or paired with an aversive stimulus.[5] Variations on this basic experimental setup allow scientists to train bees to perform more complicated supervised learning tasks.[6]
Literature review
There is a vast literature on this topic; I have not thoroughly investigated it, but, instead, I mainly rely on two literature reviews, (Avarguès-Weber et al., 2012) and (Giurfa, 2013), and I follow citation chains from them. I use these articles because I found them from a citation in (Rigosi et al., 2017), the bee vision paper cited in (Cotra, 2020), rather than from a systematic search.
My general impression from the bee vision literature is that bees are capable of learning surprisingly complicated tasks, ranging from recognizing specific faces (Dyer et al., 2005) to distinguishing between Monet and Picasso paintings (Wu et al., 2013). Bees learn how to do these tasks with a small amount of training data, usually less than ten examples, allowing for comparisons with few-shot learning in computer vision. However, many studies in this literature do not test bees’ learning with novel test data or analyze tasks which are easier than standard machine learning benchmarks, such as detecting symmetry in glyphs (Giurfa, 1996).
Out of the articles I’ve looked at, I believe that (Zhang et al., 2004) is the one most relevant to comparing bees and machine learning models. In it, the authors train bees to recognize complex natural categories, like landscapes and plant stems, in a one-shot setting. This is one of the hardest tasks in the bee vision literature,[7] and it can be compared with few-shot image classification on datasets commonly used in machine learning such as ImageNet and CIFAR. I use this article as a benchmark for bee performance in image classification tasks.
I do not explain in detail how other articles compare to (Zhang et al., 2004) in the body of this post. The interested reader can instead see this appendix for details.
In the remainder of this section, I describe the results of the article I chose as a benchmark, (Zhang et al., 2004), and what they imply about the capabilities of bees.
Benchmark article
In (Zhang et al., 2004), bees were trained to recognize complex natural image categories (star-shaped flowers, circular flowers, plant stems, and landscapes) in a one-shot setting. Bees achieved an accuracy of about 60% at this task, which is considerably higher than the 25% accuracy obtained by guessing randomly.
The experimental setup used consists of a three-chambered maze, as depicted in the image below, taken from the paper. Bees enter the maze and reach chamber C1, where they see a sample image in the wall between chambers C1 and C2. They then fly through a small hole in the aforementioned wall and reach chamber C2, where they observe chamber C3 through the transparent wall between these two chambers, depicted in the diagram below as a dotted line. The back wall of C3 consists of four images, each with an associated tube. The tube associated with the image matching the sample leads to a feeder containing a sugary solution, while the others provide no reward to the bees. The bees fly through another small hole, this time between C2 and C3. The tube on which they land first is interpreted as their “prediction” of the reward’s location. This experimental setup is used for both training and testing bees’ image classification skills.
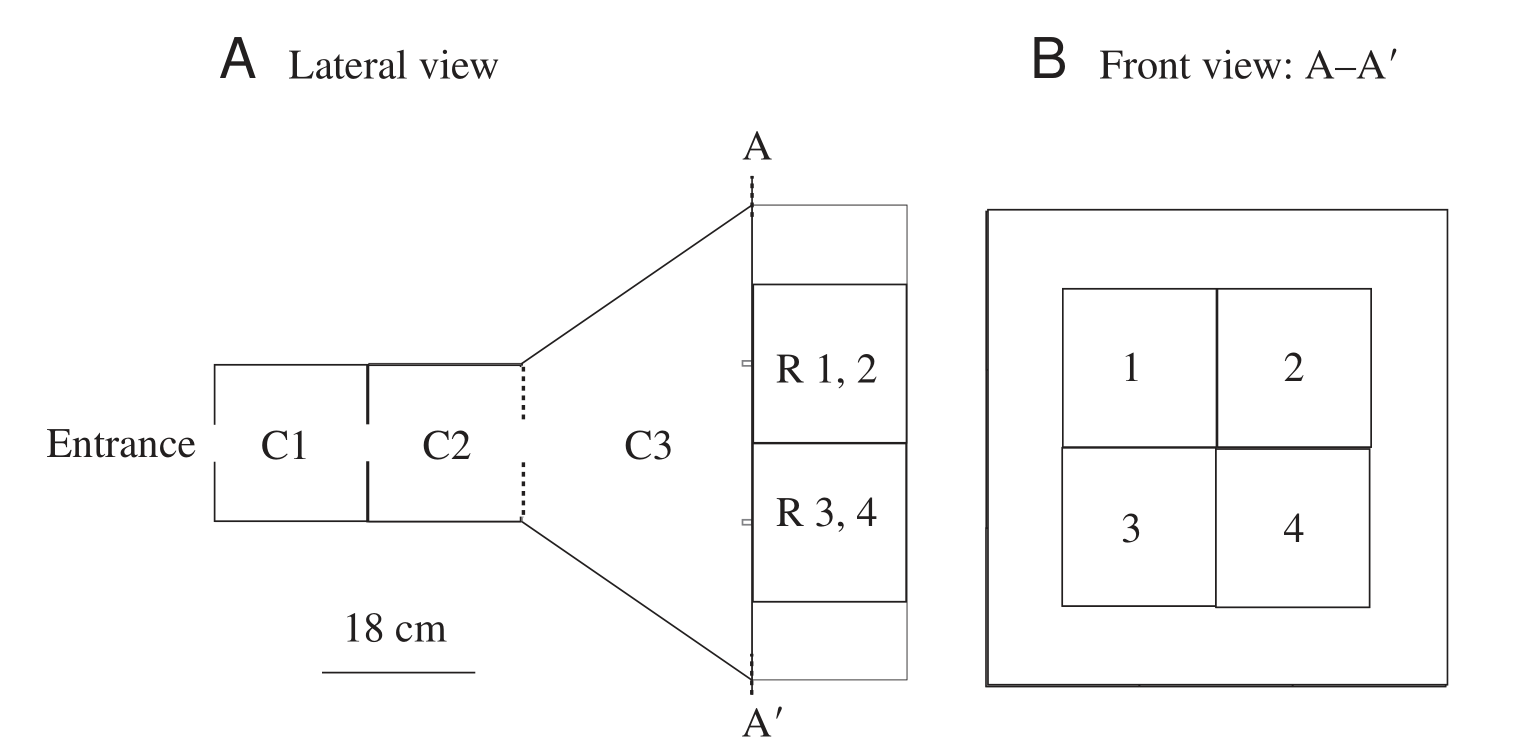
The transparency of the wall between C2 and C3 suggests that the bees make their choice at C2. As the chamber C3 is large, the images in its back wall would appear small to the bees. I believe that this had a significant negative impact on their accuracy, as I will discuss later.
The experiment consisted of three parts: a pre-training period where bees learned to enter and traverse the maze, a training period where bees learned to land on an image that exactly matched the sample, and a testing period where bees had to land on an image that matched the category of the sample. Note that the bees weren’t explicitly trained to do image classification; instead, they were trained to simply match images. Nevertheless, they were able to generalize and match images by category during testing. This makes their success at image classification significantly more impressive. In general, the learning capabilities of bees seem to me more impressive than that of machine learning models, as I will discuss later.
Throughout training and testing, the authors took precautions to ensure that bees were actually doing the matching task. The position of the rewarded image was frequently switched, so that bees couldn’t memorize it. Additionally, a control experiment in which all images matched the example was performed, which showed that bees couldn’t use olfactory cues to locate the reward.
Both training and pre-training took a substantial amount of time, with testing beginning after three days of training, in which each bee entered the maze and was rewarded about 80 times. This large amount of training epochs is common in the bee vision literature; however, I’m not sure why. Although this article doesn’t plot learning curves, other articles, such as (Giurfa et al., 1996) and (Dyer et al., 2005), do so, showing that performance increases with more exposure. I’d wager that repeated exposure to the same images is required for bees to understand the task rather than to learn the categories themselves, but I’m not confident about this.
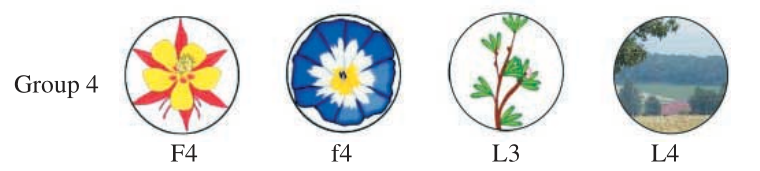
Training consisted of showing bees sample images and rewarding them by landing on the matching image, as mentioned previously. The training set (called “Group 1” in the paper), with one image of every category (star-shaped flowers, circular flowers, plant stems, and landscapes), is shown below.
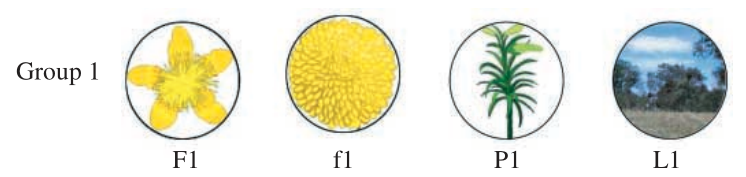
Note that the star-shaped flower is very similar to the circular flower.
Although the categories are natural and, therefore, bees might have relevant prior knowledge about these categories, my impression is that the images are seen from a very different perspective than bees would usually see them, and so this knowledge would be less relevant. Since bees don’t classify images with which they should be more familiar (e.g. flowers) more accurately and the performance of bees in the training set is not that impressive, as will be seen later, I do not think that this objection is that relevant.
After training, the authors measured how frequently bees landed in each image when shown a sample. The results of this learning test are shown in the graph below, taken from the paper.
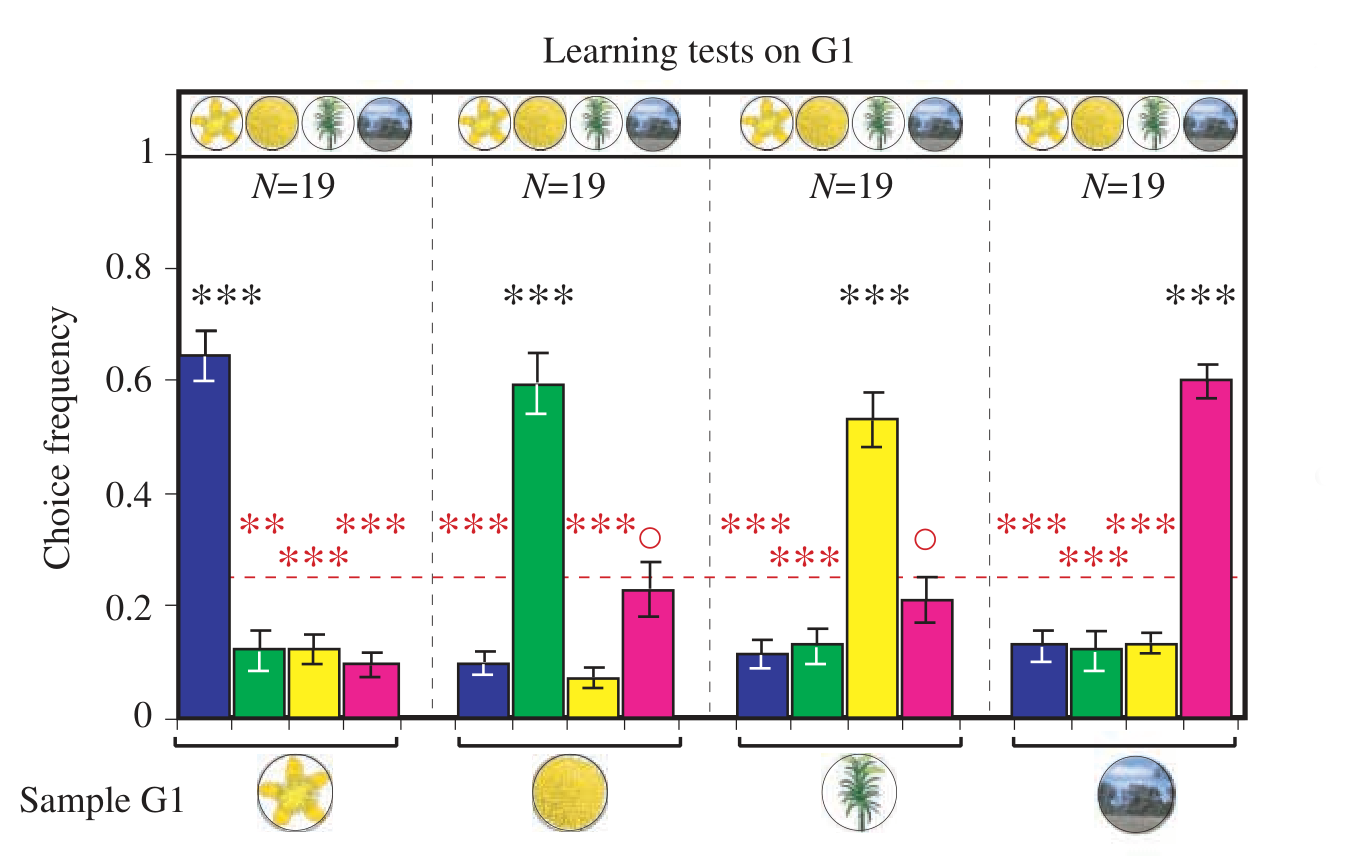
(Note that the N in the plot above is the number of bees that participated in the learning test, not the number of visits to the maze; the latter is much higher, as 1132 visits took place.)
As the reader can see, bees matched the sample correctly about 60% of the time. Although this is significantly better than chance, this performance is not very impressive, given that this task is so simple. I believe that this poor performance can be explained by the small apparent size of the images.
I investigate the resolution of bee vision in some depth in this appendix, concluding that each eye has a resolution of 100x100 pixels. Since the images only occupy a fraction of the bees’ field of view, the effective resolution of each image is even lower than that. From the diagram of the experimental setup used in (Zhang et al., 2004), I estimate that the images appeared to the bees as having an effective resolution of 20x20 pixels. The details of this calculation can be found in this appendix.
To understand intuitively how low this effective resolution is, compare the high-resolution image of a landscape in the left to the same image downscaled to 20x20 pixels on the right.

As the reader can see, the difference in image quality is dramatic. The performance of bees in the image classification task is very similar to their performance in this simple matching task, as will be seen later. I think that these considerations point to low resolution being the cause of poor performance in the learning test, and that this poor performance is not very indicative of weak learning abilities.
After this learning test, the authors performed two types of transfer tests. Type 1 transfer tests consisted of the same matching-to-sample task, but with novel images, as depicted below.

The study finds that bees do as well with the novel images as with the training set, as can be seen in the plots below:
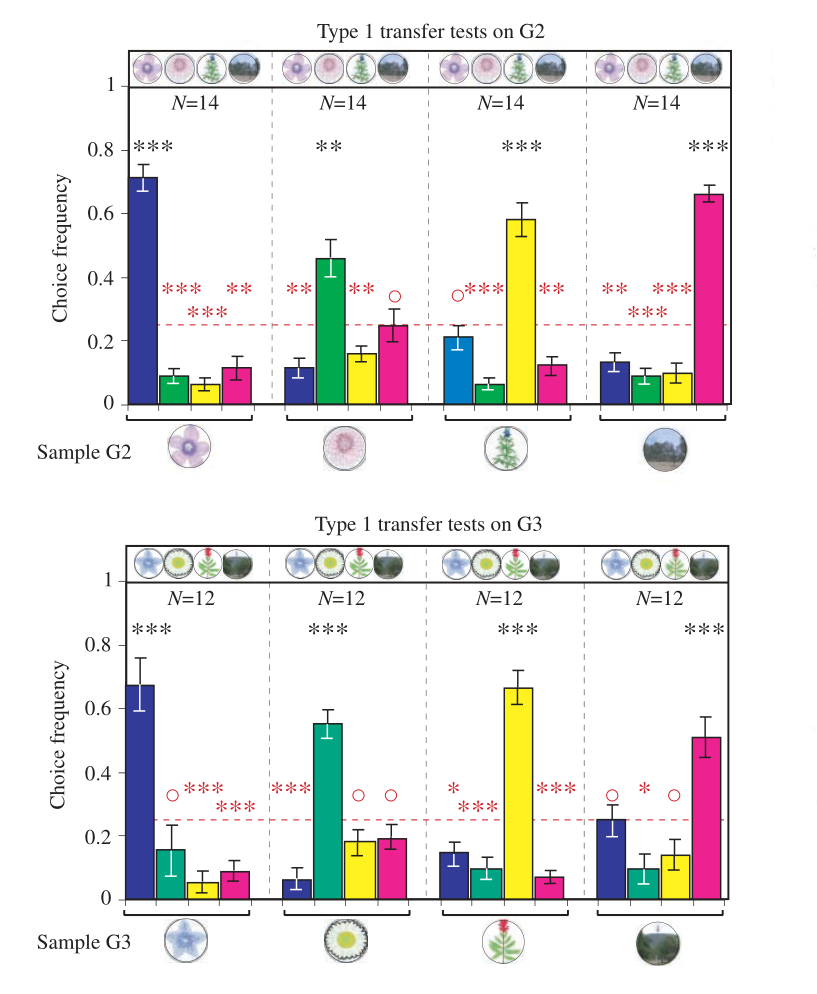
Type 2 transfer tests require that bees match the category of the sample, rather than the exact image. The sample image, which indicates the category to be matched, comes from the training set, while the images to be classified come from a novel group of images, depicted below.
The results of the Type 2 transfer test is shown in the plot below:
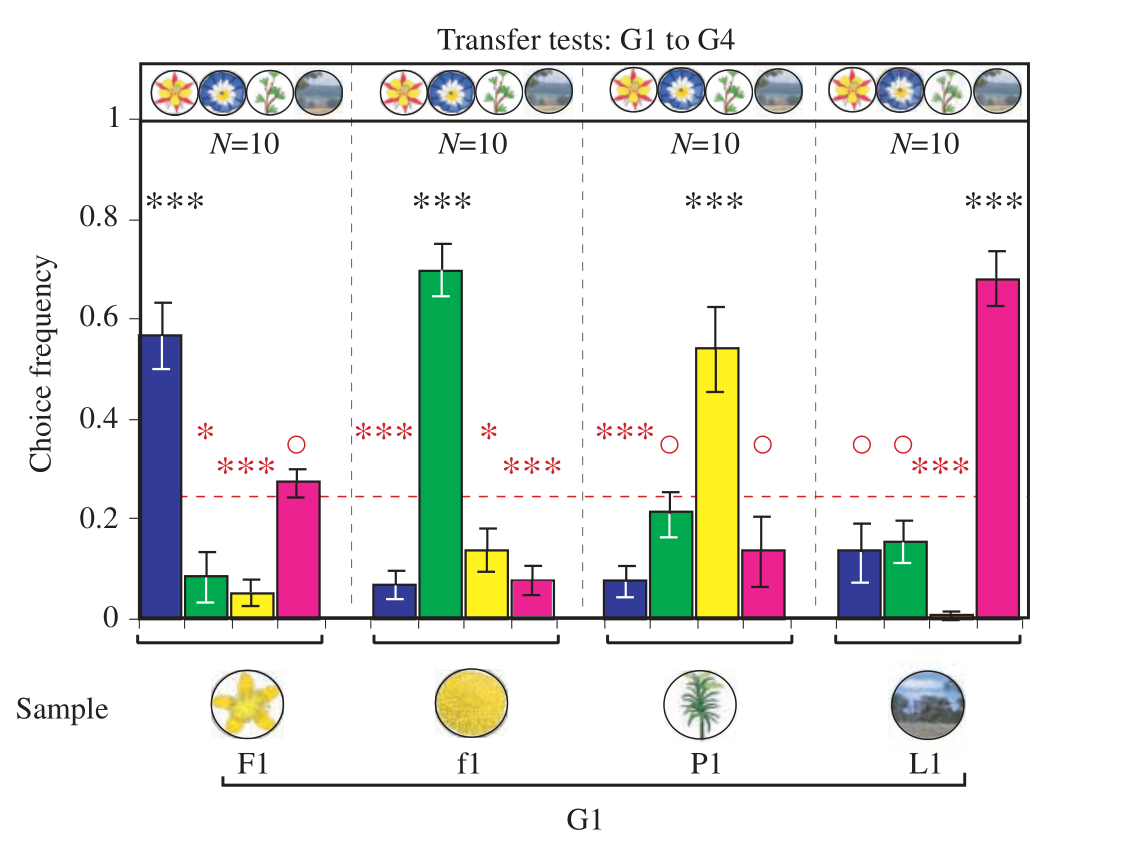
As can be seen, the bees classified the images correctly about 60% of the time, which is very similar to the performance of bees in the learning tests. I am impressed by these results, especially since the bees were not trained specifically to do image classification, but instead they were only trained to find exact matches.
Note that the bees were rewarded for landing on the correct image during testing. This is common in such experiments; otherwise, bees might give up on the classification task and stop entering the maze, seeing that their efforts go unrewarded. However, this means that some learning might occur during testing, since each test consists of many visits of each bee to the maze. In the Type 2 transfer test above, for instance, each bee visited the maze around 28 times. In order to minimize learning during testing, the authors broke up testing into short bouts in which each bee visited the maze only twice. These testing bouts were spaced out and interleaved with periods of training on the original matching-to-sample task.
Machine learning model performance
In this section, I review the machine learning literature searching for a model that can be compared to bees in the experiments of (Zhang et al., 2004). I find that the model presented in (Lee et al., 2019) most comparable. I then analyze its performance.
Literature review
How do machine learning models compare to the performance of bees in few-shot learning shown in (Zhang et al., 2004)? There are a huge variety of models trained on few-shot learning tasks; the first step in this comparison, therefore, is choosing models that can be reasonably compared to bees. My approach is to choose models that are trained with similar data and that have similar performance to that of bees; the comparison then reduces to seeing whether bees or ML models use more compute.
In order to find such comparable models, I looked at a list of few-shot learning benchmarks on Papers With Code. Each of these benchmarks specifies a few-shot learning on some dataset. I chose a dataset based on the resolution of the images, as this is very relevant to a model’s compute usage. As mentioned previously, the effective resolution of the images used in (Zhang et al., 2004) is 20x20 pixels; a well-known dataset with a similar resolution is CIFAR-FS, introduced in (Bertinetto et al., 2018), which contains 32x32 images from a hundred different categories ranging from airplanes to cats.
I believe that the images in (Zhang et al., 2004) are a bit harder to classify than those of the CIFAR-FS dataset, since the two flower categories are very similar. Additionally, I have a vague impression that the images in the CIFAR-FS were selected to be distinguishable at low resolution, while I don’t think that was the case in (Zhang et al., 2004), but I’m very uncertain about this.
The most comparable machine learning task, then, is few-shot learning on the CIFAR-FS dataset. However, ML models are usually trained to do five-way classification, that is, to classify an image from one of five possible labels, while bees perform four-way classification in (Zhang et al., 2004). All else equal, four-way classification tasks are easier than five-way ones, since there are fewer wrong options.
A way of comparing accuracies in different n-shot tasks would simplify comparing bees and ML models. I’m not aware of a standard way of doing this. In order to do so, therefore, I develop a toy model of a few-shot classifier. I model an n-way classifier as an ensemble of n binary classifiers, one for each of the possible labels. I assume that these binary classifiers have some fixed error rate, which is a measure of the performance of the ensemble independent of n. By relating the accuracy of the ensemble to the error rate of the binary classifiers, one can estimate the accuracy that bees would have in a five-way classification task. The mathematics of this model can be found in this appendix. I estimate that the 60% accuracy in a four-way classification task obtained by bees in (Zhang et al., 2004) corresponds to an accuracy of about 55% in a five-way image classification task.
The results of ML models on five-way one-shot image classification in CIFAR-FS are listed here; accuracies range from about 70% to about 90%, significantly higher than our 55% estimate for bee performance. However, my impression is that the images from different categories in (Zhang et al., 2004) are a bit more similar to each other than those in CIFAR-FS, so the comparison isn’t as clear a win for machine learning models as one might think at first. Litigating this comparison precisely seems difficult and not very fruitful; therefore, I chose the model with accuracy most similar to bees as my benchmark, which turns out to be the model with the lowest accuracy.[8] This is the model found in (Lee et al., 2019), which has an accuracy of 72.8%.
Compute usage
In this section, I estimate how much computation the machine learning model of (Lee et al., 2019) uses to classify an image, as well as the compute usage of bees in the experiments of (Zhang et al., 2004). I then compare these two figures.
Machine learning model compute usage
The architecture of the model presented in (Lee et al., 2019) consists of two parts: a function that maps images to feature vectors and a linear classifier that uses the feature vectors to classify the images. During training, the function is optimized to learn features that generalize well. The first part is implemented as a convolutional neural network, while a linear support-vector machine serves as the linear classifier.
After the model has processed the sample images for a given task, it needs only to calculate the features of the task image and feed them to the linear classifier. The most compute-intensive part of this is calculating the features; this was done using a convolutional neural network with a ResNet-12 architecture. As the authors do not provide an estimate of the compute per forward pass used by their model, I estimate that value by extrapolating the compute estimates for a similar architecture and scaling them to account for differences in parameter count and input size. One could also estimate the compute usage directly from the description of the network given in the paper; this would probably lead to a more accurate estimate, but I don’t know how to do this.
I chose the ResNet-18 architecture as a point of comparison. A forward pass through a ResNet-18 model with an input size of 112x112 pixels requires about 5e8 FLOP;[9] since the compute per forward pass should scale linearly with both the network depth and the input size in pixels, the model used in the paper, a ResNet-12 with an input size of 32x32, should take about 5e8 FLOP * (12/18) * (32/122)^2 = 2e7 FLOP per image classified.
Bee compute usage
Estimating the compute usage of bee brains is a somewhat speculative endeavor. It’s not immediately clear what “the number of FLOP/s of a bee brain” means, since brains certainly don’t seem to be doing floating-point arithmetic. However, we can still ask what would be the amount of computational power required to simulate a brain in sufficient detail in order to replicate its task performance. I’ll use this “mechanistic” definition of brain compute throughout the report. The question of how to estimate this “mechanistic” brain compute is investigated in (Carlsmith, 2020) in the context of the human brain; by applying a similar methodology to the bee brain, we can estimate its computational abilities.
In order to estimate the amount of compute required to do so, we follow the basic approach described in (Carlsmith, 2020). In brief, it seems likely that the most computationally-intensive part of emulating a brain is simulating the signaling interactions between neurons.
The amount of compute required to emulate these interactions can be broken down in two parts: that devoted to simulating the synapses (i.e., the connections between neurons) and that devoted to determining when a neuron should fire. The total bee brain compute can then be broken up as the sum of these components. The synaptic transmission compute can be calculated as (number of synapses) * (rate of synaptic firing) * (compute per synaptic firing), whereas the firing decision compute is equal to (number of neurons) * (firing decision compute per neuron per second).
I don’t have a background in neuroscience, but it seems to me that the basic anatomy of the neuron is broadly similar between bees and humans. Therefore, I will assume that the parameters of bee neurons—that is, the rate of synaptic firing, the compute per synaptic firing, and the firing decision compute per neuron—are equal to those of human neurons. I’m very uncertain whether this assumption is reasonable or not.[1] These parameters are estimated in (Carlsmith, 2020), which obtains a range of 0.1-1 Hz for the rate of synaptic firing, 1-100 FLOP per synaptic firing, and 1e2-1e6 FLOP/s for the firing decision compute per neuron per second. All that remains is to plug in estimates for the number of neurons and synapses in the brains of bees and we’ll be able to estimate the total computing power of the bee brain. (Menzel & Giurfa, 2001)[11] state that bees have a million neurons and a billion synapses; this works out to a central estimate of synaptic communication compute of 3e9 FLOP/s[12] and a central estimate of firing decision compute of 1e10 FLOP/s.[13]
Of course, not all of the computational power of the bee’s brain is applied to few-shot image classification tasks. My understanding is that the sections of the bee’s brain mostly responsible for visual processing as well as learning are the mushroom bodies, which occupy about a third of the bee’s brain.[14] It seems likely, therefore, that a better central estimate of the total amount of task-relevant computation per second in the bee’s brain is 4e9 FLOP/s.[15]
In order to turn the bee brain compute value into an estimate of the compute usage per image classified, we need to know how long bees take to perform this task. Unfortunately, (Zhang et al., 2004) don’t specify this explicitly. However, we can estimate the time that bees spend in the experimental setup from some details given in the paper. The authors mention that “[e]ach transfer test was carried out only for a brief period (ten minutes, involving about two visits per bee)”; since the transfer tests involved around ten bees as experimental subjects, I believe that this implies that the time taken per visit is about (10 min) / [(2 visits/bee) * (10 bees)] = 30 s/visit. I assume that there’s some time between each bee’s visit, so the total time each bee spends in the environmental setup should be somewhat smaller than that. The time each bee spends to classify an image must be even smaller than that. Somewhat arbitrarily, I estimate that this time is around five seconds.
The compute employed by bees to classify an image, then, can be found by multiplying the computing power of the bee brain used in this task by the time taken to do so. This works out to (4e9 FLOP/s) * (5 s) = 2e10 FLOP per image classification task.
It’s clear, however, that a bee’s brain can perform a wide range of tasks beside efew-shot image classification, while the machine learning model developed in (Lee et al., 2019) cannot. I do not take into account this in my comparison below. In fact, I am not sure how to do this. This is probably the factor that most biases this comparison against bees.[16]
However, there is some reason to believe that the above estimate is not wildly unfair against bees: in (Carlsmith, 2020)’s discussion of functional estimates of brain compute, a comparison of the human visual cortex with image classification models trained in a regular (not a few-shot) setting is made.[17] He considers that 0.3%–10% of the visual cortex is used by the human brain to perform image classification and adjusts for the fact that image classifiers are worse than humans at some aspects of image classification. These guesses for visual cortex usage can be taken as guesses for the usage of mushroom bodies. Since bees appear to be worse than machine learning models at this task, however, even Carsmith’s lowest compute estimates suggest that bees are one order of magnitude less efficient than machine learning models, which gives me some confidence that this comparison is not totally uninformative.
Conclusion
In this report, I show that both bees and computer vision models are able to perform very similar few-shot image classification tasks. The efficiency with which they perform these tasks, however, differs somewhat: my central estimate is that bees use three orders of magnitude more computation to do them. Although this might seem like a very large difference, it is comparable to the uncertainties in the biological compute estimates: (Carlsmith, 2020) posits an uncertainty of two orders of magnitude in his brain compute estimate.
In addition, the comparison performed in this post is stacked against bees in various ways. Bees have not evolved to perform few-shot image classification tasks, and, in fact, have not even been trained specifically on this task in (Zhang et al., 2004), while the machine learning model analyzed here was optimized to do just that. The behavioral repertoire of bees is vast, and I have only analyzed one task in this report. Perhaps most importantly, bees seem to be significantly more sample-efficient than machine learning models; that is, they are able to learn how to perform a task with a smaller number of examples.
My intuition is that within-lifetime learning in bees (as opposed to the “learning” that occurs during evolution) is more analogous to the runtime learning capabilities of some ML models, like GPT-3, than to training-time learning, which is another factor that might lead these estimates to understate the leaning prowess of bees. Comparing these capabilities to that of CLIP and Image GPT would be very interesting, but outside the scope of this post.
Even with all of these caveats, however, I believe that this analysis is informative for updating the estimates of the compute required for creating a transformative model.
Very naïvely, we can adjust these estimates in the following fashion: since bees are three orders of magnitude worse than computer vision models, our prior should be that a transformative model should require roughly three orders of magnitude less compute than the human brain. I don’t think it’s obvious in what direction we should adjust this prior, so I’ll stick to it. As the human brain can perform the equivalent of 1e13-1e17 FLOP/s, we should then expect that a transformative model should require 1e10-1e14 FLOP/s to run. This is somewhat smaller than the central estimate of 1e16 FLOP/s found in (Cotra, 2020).
As mentioned previously, however, this discrepancy is relatively small when compared to the uncertainties involved; therefore, I believe that this investigation validates the biological anchor approach to investigating AI timelines somewhat. After all, if the discrepancy in performance per FLOP was much larger, extrapolations based on comparisons between biological anchors and machine learning models would be much more suspect, but that did not turn out to be the case.
I was somewhat surprised by this result; before doing this investigation, I believed that bees would do better than machine learning models in terms of compute. This has updated me towards shorter timelines. In order to get an idea of how much this should shift my timelines, I plugged in the naïve estimate of transformative model size into Cotra’s TAI timelines model, using her best guesses for all other parameters. The interested reader can browse the resulting distribution and adjust the model parameters here; the main difference, however, is that the median forecast for TAI goes from around 2050 to around 2035, making timelines substantially shorter. I would advise the reader to make a much smaller update to their timelines, since I am very uncertain about the conclusions of this report, as I have hopefully made clear. I would tentatively adjust Cotra’s forecast to 2045, holding constant all other parameters of her model. Notwithstanding that, very short timelines seem more plausible to me after concluding this investigation.
Bibliography
Avarguès-Weber, A., Mota, T., & Giurfa, M. (2012). New vistas on honey bee vision. Apidologie, 43(3), 244-268. https://hal.archives-ouvertes.fr/hal-01003646
Bertinetto, L., Henriques, J., Torr, P. H.S., & Vedaldi, A. (2018). Meta-learning with differentiable closed-form solvers. International Conference on Learning Representations. https://arxiv.org/abs/1805.08136
Carlsmith, J. (2020). How Much Computational Power Does It Take to Match the Human Brain? Open Philanthropy Project. https://www.openphilanthropy.org/brain-computation-report
Cotra, A. (2020). Forecasting TAI with biological anchors. LessWrong. https://www.lesswrong.com/posts/KrJfoZzpSDpnrv9va/draft-report-on-ai-timelines
Dyer, A. G., Neumeyer, C., & Chittka, L. (2005). Honeybee (Apis mellifera) vision can discriminate between and recognise images of human faces. Journal of Experimental Biology, 208, 4709-4714. https://jeb.biologists.org/content/208/24/4709.short
Giurfa, M. (2013). Cognition with few neurons: higher-order learning in insects. Trends in neurosciences, 36(5), 285-294. https://pubmed.ncbi.nlm.nih.gov/23375772/
Giurfa, M., Eichmann, B., & Menzel, R. (1996). Symmetry perception in an insect. Nature, 382, 458–461. https://www.nature.com/articles/382458a0
Lee, K., Manji, S., Ravichadran, A., & Soatto, S. (2019). Meta-Learning with Differentiable Convex Optimization. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 10657-10665. https://openaccess.thecvf.com/content_CVPR_2019/html/Lee_Meta-Learning_With_Differentiable_Convex_Optimization_CVPR_2019_paper.html
Menzel, R., & Giurfa, M. (2001). Cognitive architecture of a mini-brain: the honeybee. Trends in Cognitive Sciences, 5(2), 62-71. https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(00)01601-6?_returnURL=https%3A%2F%2Flinkinghub.elsevier.com%2Fretrieve%2Fpii%2FS1364661300016016%3Fshowall%3Dtrue
Rigosi, E., Wiederman, S. D., & O'Carroll, D. C. (2017). Visual acuity of the honey bee retina and the limits for feature detection. Scientific Reports, (7). nature.com/articles/srep45972
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., & Li, F.-F. (2014). ImageNet Large Scale Visual Recognition Challenge. arXiv preprint. https://arxiv.org/abs/1409.0575
Wu, W., Moreno, A. M., Tangen, J. M., & Reinhard, J. (2013). Honeybees can discriminate between Monet and Picasso paintings. Journal of Comparative Physiology A, 199(1), 45-55. https://link.springer.com/article/10.1007/s00359-012-0767-5%20
Zhang, S., Srinivasan, M. V., Zhu, H., & Wong, J. (2004). Grouping of visual objects by honeybees. Journal of Experimental Biology, 207, 3289-3298. https://jeb.biologists.org/content/207/19/3289.short
Appendices
Why (Zhang et al., 2004)?
In my non-comprehensive review of the bee vision literature, I looked at a couple of articles that train bees to do image classification tasks. The literature review in (Avarguès-Weber et al., 2012) cites (Giurfa et al., 1996) and (Zhang et al., 2004), two papers that do so. Searching the papers that cite (Zhang et al., 2004), I found another relevant article, (Wu et al., 2013). I also came across (Dyer et al., 2005), but, unfortunately, I do not recall how. I also came across some papers that did simpler image classification tasks, such as (Srinivasan & Lehrer, 1988), but, since the tasks bees perform in these papers are much easier than those in the aforementioned ones, I did not consider them as possible benchmarks for comparing bee vision and machine learning.
(Giurfa et al., 1996) trains bees to classify abstract glyphs on the basis of their bilateral symmetry or absence thereof. The bees perform very well at this task, with accuracies of about 85%. However, this task is quite simple when compared to few-shot classification in datasets used in ML; therefore, I rejected this task as a possible benchmark.
(Dyer et al., 2005) trains bees to recognize specific human faces. Unfortunately, the paper does not do this in a few-shot learning setting. Although the success of bees in this task is very impressive to me, this success is not as relevant to estimating the size of a transformative model; therefore, I rejected this task as a possible benchmark. The reader interested in the results of this paper should look at this appendix.
(Wu et al., 2013) trains bees to distinguish between Monet and Picasso paintings in a few-shot setting. This article was a very strong candidate for benchmark paper; I chose to use (Zhang et al., 2004) because the dataset used in this latter paper is more similar to those usually used in ML.
Results of (Dyer et al., 2005)
In this article, the authors trained bees to distinguish between different human faces. This task seems quite impressive to me, as I would not have predicted that bees would be capable of such a feat before learning of this paper. The training procedure was also remarkably simple: bees were trained to distinguish between a photograph of a specific person (the rewarded stimulus) and a stylized representation of a face (the punished stimulus), as can be seen in the images below from the article:

Note that the authors didn’t train bees specifically to distinguish between different human faces—and yet they were still able to do it anyway, as can be seen in the plot below of the results from the paper:
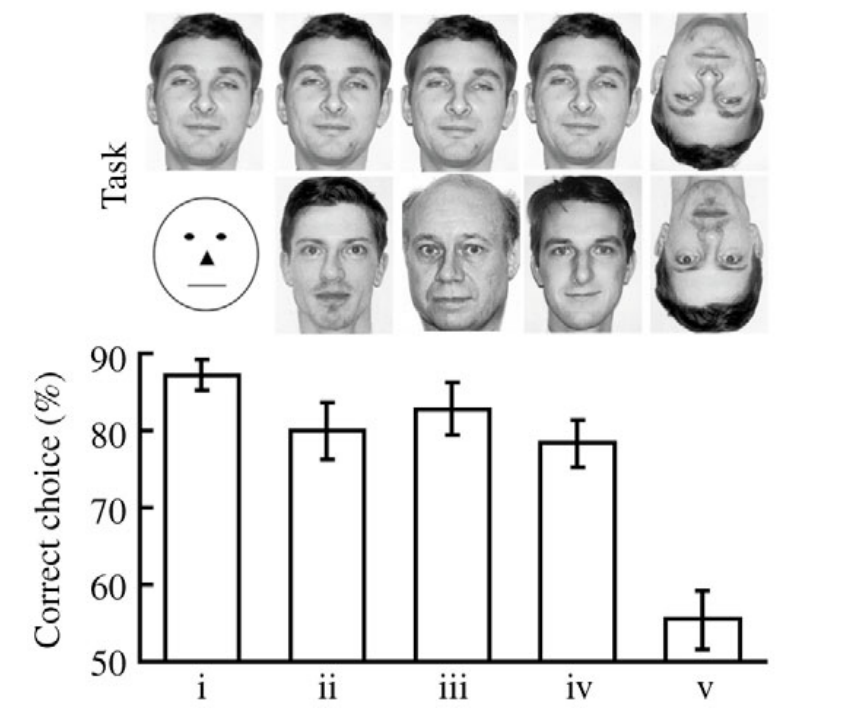
A weakness of this paper is that it does not use different photos of the same person to check if bees are just memorizing the images or if they are doing something more clever than that. However, my impression is that, overall, bee memory is not very good, so it seems to me that this would be an impressive memorization feat for a bee.
This paper also provides a learning curve, allowing us to observe the improvement in the performance of bees over time, as can be seen in the below plot. Note that “In a given [foraging] bout, the mean (± s.e.m.) number of choices by the bees was 10.0 ± 1.7”, so the learning curve shown below spans a range of about a hundred choices per bee.
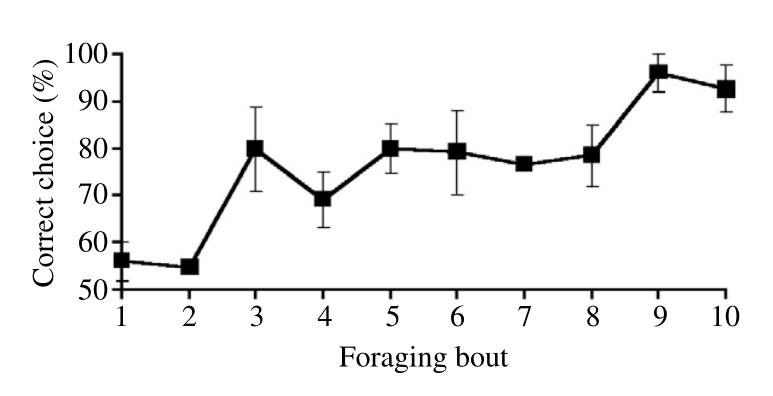
Once again, we observe a high number of epochs required for learning; performance begins to be reasonable after 30 epochs of training on the same data.
Footnotes
[1] Strictly speaking, (Carlsmith, 2020) estimates the compute required to simulate the human brain to a level of detail required to replicate its task performance. I will refer to such figures as “brain compute estimates” and use similar language throughout this report.
[2] See (Cotra, 2020, Part 1, pg. 44).
[3] See (Russakovsky et al., 2014, p. 9, Table 2).
[4] One FLOP suffices for adding two six-digit numbers, but the human brain uses some significant fraction of its computing power for a couple of seconds to do this. (Carlsmith, 2020) estimates that the human brain performs a quadrillion FLOP per second. Therefore, the compute used by the brain to do addition is a couple quadrillion FLOP.
[5] See (Srinivasan & Lehrer, 1998) for a representative example of such an experimental setup.
[6] The term “supervised learning” is common in machine learning; a similar idea in psychology is concept learning. This latter term appears frequently in the bee vision literature.
[7] My impression is that the bee vision literature focuses more on artificial visual stimuli, such as stylized images and gratings. I believe that (Zhang et al., 2004) is the first paper to show that bees are able to classify more natural images: “[s]o far, however, there have been no studies investigating the ability of invertebrates to classify complex, natural objects.” (Zhang et al., 2004, pp. 3289-3290).
[8] This was true as of December 2020, when I performed this analysis. As of March 2021, there are now a couple of models with performances closer to bees’ than (Lee et al., 2019). I have not revised my analysis to take this article into account.
[9] This was calculated by dividing the compute per batch by the batch size from these estimates for images of size 112x112.
[10] There is evidence (see 1, 2 [EA · GW]) that smaller animals have greater temporal resolutions than larger ones, which suggests that rate of synaptic firing might be higher in bees than in humans. Thanks to Carl Shulman for pointing this out.
[11] I found this paper from Wikipedia’s list of animals by number of neurons entry for honey bees.
[12] The central estimates are 3e-1 Hz for the rate of synaptic firing, 1e1 FLOP per synaptic firing, and 1e9 synapses. Multiplying these together, we obtain 3e9 FLOP/s due to synaptic communication.
[13] The central estimates are 1e4 FLOP/s per neuron for the firing decision compute and 1e6 for the number of neurons. Multiplying these together, we obtain 1e10 FLOP/s due to firing decisions.
[14] See this reference, which states that the mushroom bodies in honeybees contain a third of the neurons of their brains. It might be the case that the mushroom bodies have a higher number of synapses per neuron than other regions of the bee brain, leading to an underestimate of task-relevant compute.
[15] This is one-third of the total estimate of bee brain compute (1.3e10 FLOP/s). Of course, probably only a fraction of the compute of the mushroom bodies is task-relevant; I assume that this fraction is high, so that the estimate given doesn’t overestimate the true value by much.
[16] Thanks to Carl Shulman and Rohin Shah for raising this objection.
[17] Note that this comparison should favor machine learning models more heavily than the comparison done in this post, as presumably a machine learning model trained to distinguish between some set of labels (and only capable of doing that) should be more compute efficient than a model that must learn categories with a small number of examples during “runtime” (as is the case with a few-shot learning model).
15 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2021-03-04T23:02:43.049Z · LW(p) · GW(p)
It’s clear, however, that a bee’s brain can perform a wide range of tasks beside efew-shot image classification, while the machine learning model developed in (Lee et al., 2019) cannot.
The abstract objection here is “if you choose an ML model that has been trained just for a specific task (few-shot learning), on priors you should expect it to be more efficient than an evolution-designed organism that has been trained for a whole bunch of stuff, of which the task you’re considering is just one example”. This can cash out in several ways:
1. Bees presumably use their eyesight for all sorts of things (e.g. detecting movement, depth estimation, etc) whereas the ML model only needs to use features useful for classification.
2. Even restricting to classification, bees are probably way more general than ML models. I suspect the few-shot ML models you look at would probably not generalize to very different types of images (e.g. stylized images), whereas bees presumably would.
3. I don’t know how well bee training works; it seems plausible to me that sometimes bees just want to do something else and that’s why they don’t land on the right target. So maybe they can classify with 90% accuracy, but only actually go to the correct lever 60% of the time.
You could say that this means that a transformative model will also be way more efficient than a human at a transformative task -- I think this is somewhat true, but mostly depends on whether transformative tasks will require a fairly broad and general understanding of the world + doing various tasks within it. My guess is that while they don’t need as much generality as a human has, the human-TAI ratio will be much smaller than the bee-image classifier ratio.
My rough guess is that I’d change the conclusion by a factor of 50 or so, suggesting that a transformative model would require 20x less compute than the human brain.
Replies from: ajeya-cotra↑ comment by Ajeya Cotra (ajeya-cotra) · 2021-03-05T00:51:53.891Z · LW(p) · GW(p)
I mostly agree with your comment, but I'm actually very unsure about 2 here: I think I recall bees seeming surprisingly narrow and bad at abstract shapes. Guille would know more here.
Replies from: guicosta↑ comment by eleni (guicosta) · 2021-03-05T19:03:00.808Z · LW(p) · GW(p)
I think Rohin's second point makes sense. Bees are actually pretty good at classifying abstract shapes (I mention a couple of studies that refer to this in the appendix about my choice of benchmark, such as Giurfa (1996)), so they might plausibly be able to generalize to stylized images.
comment by Ben Pace (Benito) · 2021-03-04T06:16:15.344Z · LW(p) · GW(p)
Hey guicost. This is a great first post, thanks for the fascinating doc!
For ease of readability for users, I've copied the full doc into the post (I'm an admin so I have the power to edit people's posts). If you disprefer that for any reason, please let me know right away and I'll undo the change, or you can just delete everything yourself. I spent <15 mins on it, it's no big deal.
The only edits I made were to put all the footnotes at the bottom (we don't have superscript so footnotes have the slightly uglier [n] styling) and some of the images were a bit funny when I brought them over (e.g. some of them became bigger images with other stuff in them) so I just inserted screenshots instead. Again, it's fully your post, and you are free to make whatever further edits you like.
Replies from: guicosta, ajeya-cotra↑ comment by eleni (guicosta) · 2021-03-04T14:52:36.880Z · LW(p) · GW(p)
Hey Ben! Thanks for formatting the doc into the post, it looks great!
Replies from: Benito↑ comment by Ben Pace (Benito) · 2021-03-04T23:03:44.029Z · LW(p) · GW(p)
You're welcome :)
↑ comment by Ajeya Cotra (ajeya-cotra) · 2021-03-04T22:29:03.493Z · LW(p) · GW(p)
Aww thanks Ben, that was really nice of you!
comment by Rohin Shah (rohinmshah) · 2021-03-04T23:04:37.366Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
The <@biological anchors approach@>(@Draft report on AI timelines@) to forecasting AI timelines estimates the compute needed for transformative AI based on the compute used by animals. One important parameter of the framework is needed to “bridge” between the two: if we find that an animal can do a specific task using X amount of compute, then what should we estimate as the amount of compute needed for an ML model to do the same task? This post aims to better estimate this parameter, by comparing few-shot image classification in bees to the same task in ML models. I won’t go through the details here, but the upshot is that (after various approximations and judgment calls) ML models can reach the same performance as bees on few-shot image classification using 1,000 times less compute.
If we plug this parameter into the biological anchors framework (without changing any of the other parameters), the median year for transformative AI according to the model changes from 2050 to 2035, though the author advises only updating to (say) 2045 since the results of the investigation are so uncertain. The author also sees this as generally validating the biological anchors approach to forecasting timelines.
Planned opinion:
I really liked this post: the problem is important, the approach to tackle it makes sense, and most importantly it’s very easy to follow the reasoning. I don’t think that directly substituting in the 1,000 number into the timelines calculation is the right approach; I think there are a few reasons (explained [here](https://www.alignmentforum.org/posts/yW3Tct2iyBMzYhTw7/how-does-bee-learning-compare-with-machine-learning?commentId=rcJuytMfdQNMb82rR), some of which were mentioned in the post) to think that the comparison was biased in favor of the ML models. I would instead wildly guess that this comparison suggests that a transformative model would use 20x less compute than a human, which still shortens timelines, probably to 2045 or so. (This is before incorporating uncertainty about the conclusions of the report as a whole.)
comment by [deleted] · 2021-03-05T08:47:44.064Z · LW(p) · GW(p)
I have one query. How much better is it possible to do on this task? It bothers me that by stripping resolution, and giving the task to a being that only knows these training examples, it may simply not be very solvable, making these low accuracies due algorithms barely better than chance.
Also note that resnet-12 - or other variants of resnet - there exist numerous techniques for cutting down the computational requirements by at least an order of magnitude with minimal accuracy loss.
Replies from: guicosta↑ comment by eleni (guicosta) · 2021-03-05T19:19:53.310Z · LW(p) · GW(p)
The current SOTA models do very well (~90% accuracy) at few-shot learning tasks in the CIFAR-FS dataset [source], which has a comparable resolution to the images seen by bees, so I think that this task is quite solvable. Even bees and the models I discussed seem to do pretty well compared to chance.
Interesting to learn that compute figures can be brought down so much without accuracy loss! Could you point me to some reading material about this?
Replies from: None↑ comment by [deleted] · 2021-03-05T21:58:54.674Z · LW(p) · GW(p)
Two methods I have personally used:
quantization to int-8
A third way is "sparse" networks - many of the weights end up being near zero, and you can simply neglect those, but you need your hardware to support sparse matrix convolution.
All of these methods have the tradeoff of a small decrease in accuracy for a large decrease in required compute.
And my point about "solvability" is that there is a certain amount of noise - entropy - in the images, such that a perfect classifier trained only on the image set, with infinite compute and the global maximumally performing model, still cannot reach 100%. As the finite set doesn't have enough information. (and no, you cannot deduce the 'seed' of our universe and play forward until that moment as you do not have enough information to do that, even with infinite compute, at least if your only information input is the image set. You would find too many other universes that match the conditions. Human beings trying to manually solve the image aren't a fair comparison because they are bringing in outside information that wasn't in the set)
So there is some true ceiling for any regression problem, and you would actually expect that a 'good' modern method might be acceptably close to the ceiling, or get there soon. (if the 'true ceiling' is 97% accuracy a model that is 95% is good enough for engineering purposes)
Or a simple example : for a mostly fair coin, you cannot infer the future outcome of a flip better than the bias of the coin itself.
comment by delton137 · 2022-01-27T00:48:35.019Z · LW(p) · GW(p)
This is pretty interesting. There is a lot to quibble about here, but overall I think the information about bees here is quite valuable for people thinking about where AI is at right now and trying to extrapolate forward.
A different approach, perhaps more illuminating would be to ask how much of a bee's behavior could we plausibly emulate today by globing together a bunch of different ML algorithms into some sort of virtual bee cognitive architecture - if say we wanted to make a drone that behaved like a bee ala Black Mirror. Obviously that's a much more complicated question, though.
I feel compelled to mention my friend Logan Thrasher Collins' paper, The case for emulating insect brains using anatomical "wiring diagrams" equipped with biophysical models of neuronal activity. He thinks we may be able to emulate the fruit fly brain in about 20 years at near-full accuracy, and this estimate seems quite plausible.
There were a few sections I skipped, if I have time I'll come back and do a more thorough reading and give some more comments.
The compute comparison seems pretty sketchy to me. A bee's visual cortex can classify many different things, and the part responsible for doing the classification task in the few shot learning study is probably just a small subset. [I think below Rohin made a similar point below.] Deep learning models can be pruned somewhat without loosing much accuracy, but generally all the parameters are used. Another wrinkle is the rate of firing activity in the visual cortex depends on the input, although there is a baseline rate too. The point I'm getting at is it's sort of an apples-to-oranges comparison. If the bee only had to do the one task in the study to survive, evolution probably would have found a much more economical way of doing it, with far fewer neurons.
My other big quibble I have is I would have made transparent that Cotra's biological anchors method for forecasting TAI assumes that we will know the right algorithm before the hardware becomes available. That is a big questionable assumption and thus should be stated clearly. Arguably algorithmic advancement in AI at the level of core algorithms (not ML-ops / dev ops / GPU coding) is actually quite slow. In any case, it just seems very hard to predict algorithmic advancement. Plausibly a team at DeepMind might discover the key cortical learning algorithm underlying human intelligence tomorrow, but there's other reasons to think it could take decades.
comment by Lech Mazur (lechmazur) · 2021-08-11T23:09:20.344Z · LW(p) · GW(p)
According to https://www.sciencedirect.com/science/article/pii/S0896627321005018?dgcid=coauthor
"Cortical neurons are well approximated by a deep neural network (DNN) with 5–8 layers "
"However, in a full model of an L5 pyramidal neuron consisting of NMDA-based synapses, the complexity of the analogous DNN is significantly increased; we found a good fit to the I/O of this modeled cell when using a TCN (my note: temporally convolutional network) that has five to eight hidden layers "
For best performance, the width was 256.
Since L5 neurons can perform as small neural nets, this might have implications for the computational power of brains.
Replies from: delton137